

在本文中,我们将跟大家分享开发两个重要软件库Ray Tune和Ray Cluster Launcher 的经验, 这两个库现在支持很多流行的开源 AI 库,很多BAIR研究人员用它们来执行大规模 AI 实验。
随着 AI 研究变得越来越注重计算,很多 AI 研究人员的时间和资源都越来越紧缺。现在,很多研究人员依赖 AWS 或谷歌计算平台等云供应商,以获取训练大型模型所需的大量计算资源。
理解研究基础设施
为了更全面地理解这些内容,我们首先来看看业界的标准机器学习工作流(图 1)。
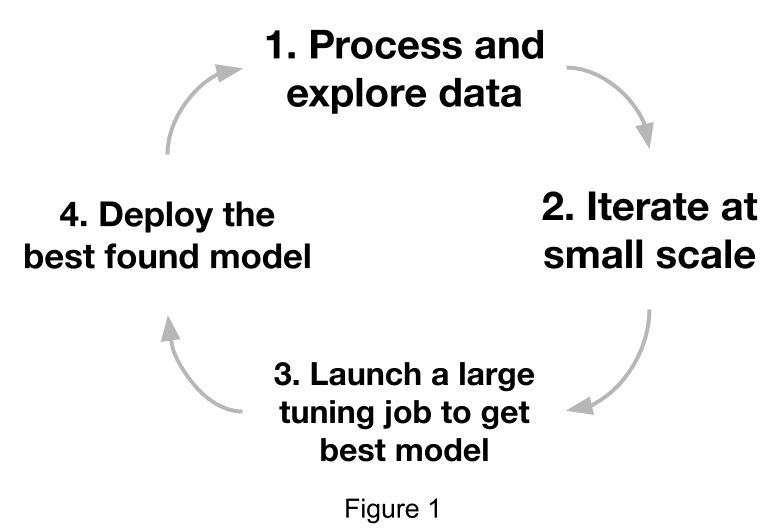
图 1 展示了业界典型的机器学习模型开发工作流
典型的“研究”工作流实际是步骤 2 和 3 之间的紧密循环,大致如图 2 所示。
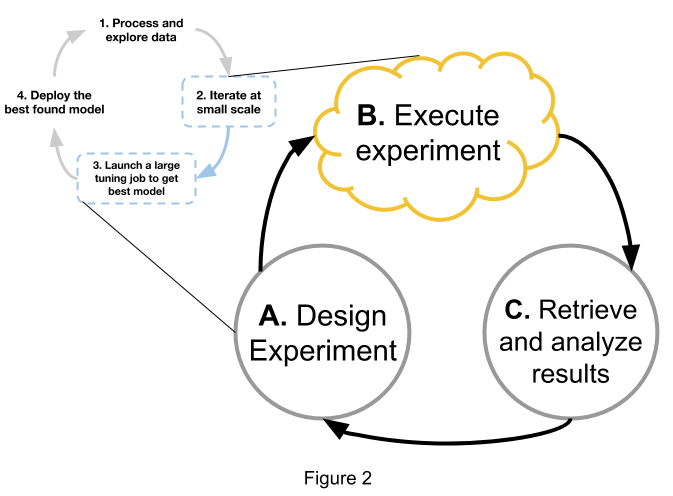
图 2 展示了用于研究的典型机器学习模型开发工作流。该研究工作流通常是业界工作流的一个分支。
该研究工作流在很大程度上是个迭代的过程,通常受到实验执行步骤(如图 2 中的 B 所示)的制约。通常,一个“实验”包括多个训练作业或“试验”,其中每个试验都是训练单个模型的任务。每个试验可能使用一组不同的配置参数(超参数)或不同的种子来训练一个模型。
在伯克利,我们看到转向云的 AI 研究人员花费大量时间来编写自己的实验执行工具,这些工具整理云供应商的 API 以启动实例、设置依赖项和启动实验。
不幸的是,除了开发这些工具所要投入的大量时间以外,这些临时的解决方法还常常在功能上受到限制:
简化的架构:每个试验通常在单独的节点上启动,没有任何集中控制逻辑。这让研究人员难以实施优化技术,如基于群体的训练(Population-based Training)或贝叶斯优化(Bayesian Optimization),这些技术需要在不同的运行之间进行协调。
缺乏故障处理:如果实例失败,那么训练作业的结果会永远丢失。研究人员常常在电子表格上跟踪实时实验来手动管理故障转移,但是,这么做既费时又容易出错。
没有竞价性实例折扣(Spot Instance Discount):缺乏容错能力也意味着放弃云供应商提供的竞价性实例折扣(最高可达90%)。
总之,在云资源上测试和管理分布式实验既费力又容易出错。因此,采用易于使用的框架以在执行和研究之间架起桥梁可以大大加快研究过程。来自 BAIR 的几个实验室成员协作构建了两个互补的工具,用于在云中进行 AI 实验:
Ray Tune:用于训练和超函数调优的容错框架。具体来说,Ray Tune(或简称“Tune”):
协调并行作业以支持并行超参数优化。
自动检查点,并在机器有故障时恢复训练作业。
提供了很多最先进的超参数搜索算法,如基于群体的训练( Population-based Training)和HyperBand。
Ray Cluster Launcher:一个实用程序,用于管理 AWS、GCP 和 Kubernetes 之间的资源调配和集群配置。
Ray Tune
为了克服这些临时实验执行工具的缺点,我们构建了 Tune,利用了 Ray Actor API 并添加故障处理来解决问题。
基于 Actor 的训练
很多用于超参数优化的技术需要一个框架来监视所有并发训练作业的指标并控制训练执行。为了解决这个问题,Tune 使用一种 master-worker 架构来集中决策,并使用 Ray Actor API 的分布式 worker 来通信。
什么是 Ray Actor API?Ray 提供一个API从一个 Python 类来创建一个“actor”。这使得类和对象可以在并行和分布式设置中使用 。
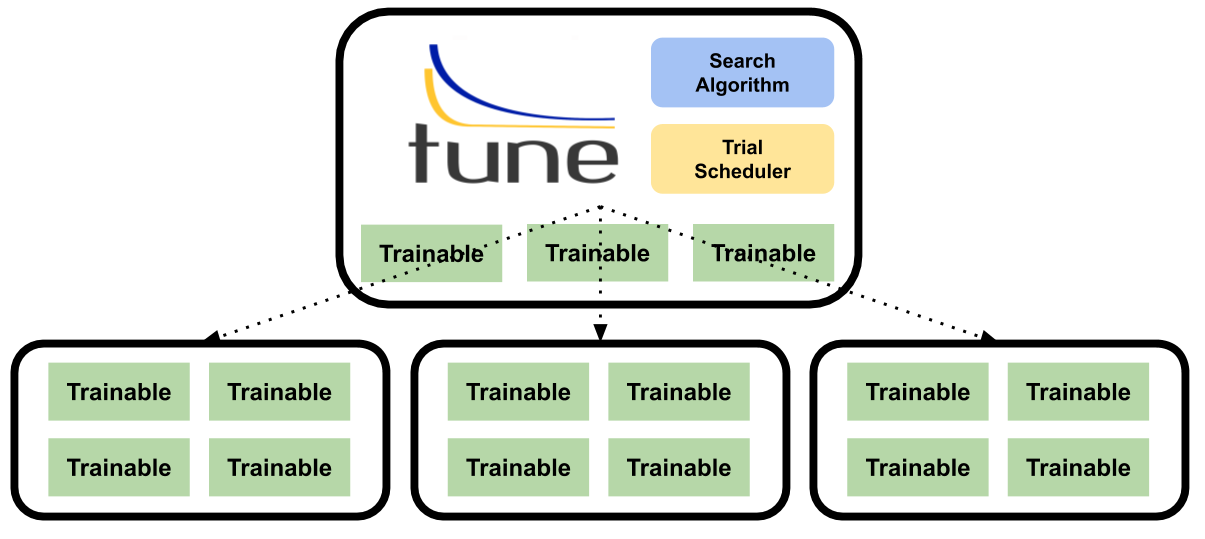
Tune 使用一个可训练的(Trainable)类接口来定义一个 actor 类,这个类专门用于训练模型。该接口公开了如_train、_stop、_save 和_restore 等方法,这些方法允许 Tune 监视中间的训练指标并杀死效果不佳的试验。
更重要的是,通过利用 Actor API,我们可以在 Tune 中实施并行超参数优化模式,如HyperBand和并行贝叶斯优化,而这些是研究人员以前使用的实验执行工具无法做到的。
容错
云供应商常常以很大的折扣提供“可抢占的实例”(如,竞价型实例)。大幅度的折扣使得研究人员可以显著地降低其云计算成本。但是,缺点是云供应商可以在任何时候终止或停止运转我们的机器,导致我们丢失训练进度。
为了可以使用竞价型实例,我们构建了 Tune 以在集群不同的机器中自动地建立检查点并恢复训练作业,这样,实验将对抢占和集群大小的调整具有弹性。
它是如何工作的?
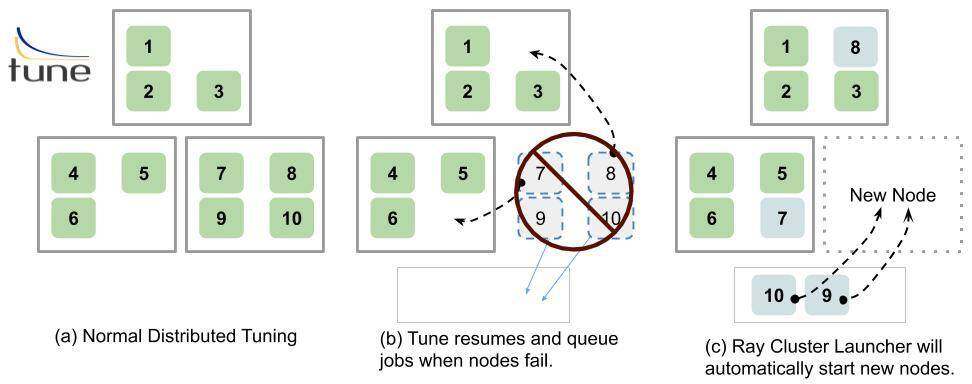
如果在某个节点丢失的时候,有个训练作业仍在其上执行且该训练作业(试验)的检查点存在,那么,Tune 将一直等到有可用资源可用,以再次执行该试验。
如果该试验被放置在一个不同的节点上,那么,Tune 将自动把之前的检查点文件推送到那个节点并恢复状态,即使失败,该试验也可以从最新的检查点恢复。
Ray Cluster Launcher
上面,我们描述了为自动化集群设置过程而整理云供应商 API 的痛苦之处。但是,即使有了用于分解集群的工具,研究人员还是必须经过繁琐的工作流才能进行实验:
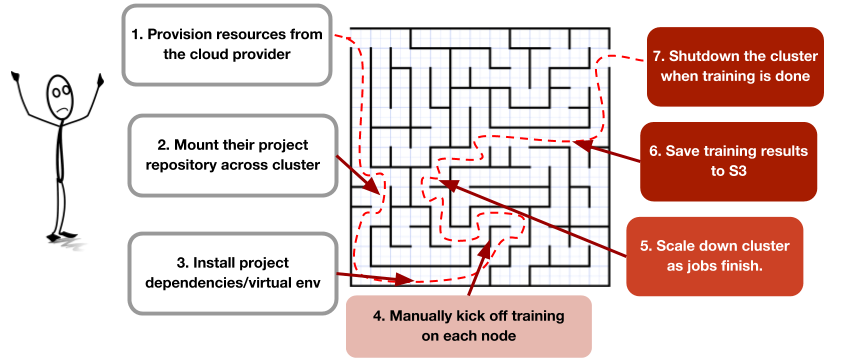
为了简化一下这个过程,我们构建了 Ray Cluster Launcher,这个工具会调配资源并自动调整资源大小,并且在 AWS EC2、GCP 和 Kubernetes 上启动一个 Ray 集群。然后,我们把以上用于进行一个实验的步骤抽象成一个简短的配置文件和一个命令:
下面的命令用来启动一个集群、上传并运行一个用于分布式超参数调整的脚本,然后关闭该集群。
研究人员现在使用 Ray Tune 和 Ray Cluster Launcher 同时在数十台 GPU 机器上启动数百个并行作业。Ray Tune的分布式实验文档页面展示了如何执行该操作。
总结
在过去的一年中,我们一直和 BAIR 不同的团队合作,以更好地让研究人员利用云。我们必须让 Ray Tune 和 Ray Cluster Launcher 变得足够通用,以支持大量研究代码库,与此同时,要把上手门槛降到人人可以在几分钟内尝试一下的程度。
Tune 已经成长为一个流行的超参数调整开源项目。很多其他流行的研究项目也在使用它,从基于群体的数据增强( Population-based Data Augmentation)项目到用于AllenNLP的超参数调整( Hyperparameter Tuning)以及 AnalyticsZoo 的AutoML。
BAIR 的很多开源项目现在都依赖 Ray Tune 和 Ray Cluster Launcher 的组合来编排和执行分布式实验,其中包括 rail-berkeley 的softlearning、HumanCompatibleAI 的对抗策略(adversarial-policies),以及流项目(flow-project)的流。
来,动手尝试一下Ray Tune和 Ray Cluster Launcher 吧!
相关链接
BAIR 以前关于 Ray 项目的博文:
Ray 的文档:
原文链接:
Large Scale Training at BAIR with Ray Tune

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论