
本文翻译自 Stripe.com 技术博客的 Online migrations at scale ,原作者为 Jacqueline Xu ,翻译已获得原网站授权。
技术团队在构建软件时面临的困难总是相似的:到最后他们总是不得不重新设计他们所使用的数据模型,以此来支持更干净的抽象和更复杂的功能。在生产环境里,这可能就要意味着迁移几百万条活跃的数据,以及重构数以千行计的代码。
Stripe 的用户希望我们提供的 API 要具备可用性和一致性。这意味着在做迁移时,我们必须非常小心:存储在我们系统中的数据要有非常准确的值,而且 Stripe 的服务必须时刻保证可用。
在这篇文章中,我们将分享我们是如何安全地完成了一次涉及上亿数据量的大迁移经历。
为什么迁移总是这么难?
规模
Stripe 有上亿规模的订阅数据。对于我们的生产数据库来说,做一次与所有这些数据都相关的大型迁移就意味着非常非常多的工作。
想象一下,假如以一种顺序的方式,每迁移一条订阅数据要一秒钟,那要完成上亿条数据的迁移就要耗时超过三年。
在线时间
Stripe 网站上的服务是一直在运行的。我们的每一次升级操作都是在线进行的,而不能在某个计划好的维护窗口内操作。因为在迁移过程中我们不能简单地中止订阅服务,所以我们必须 100% 地在所有服务都在线的情况下完成迁移操作。
数据准确
我们的代码库中许多地方都用到了订阅服务的数据表。如果我们想要一次改动订阅服务的几千行代码的话,那就可以肯定一定会有某些特殊场景被遗漏掉。我们必须确保每个服务都能持续地操作准确的数据。
在线迁移的模式
把数以百万计的数据从一张数据库表迁移到另一张中,这很困难,但对于许多公司来说这又是不得不做的事。
在做类似的大型迁移时,有种大家非常容易接受的四步双写模式。这里是具体的步骤。
- 向旧表和新表双重写入,以保持它们之间数据的同步;
- 把代码库中所有读数据的操作都指向新表;
- 把代码库中所有写数据的操作都指向新表;
- 把依赖旧数据模型的旧数据删掉。
订阅:我们的迁移例子
首先要讲讲“订阅”是什么,以及为什么我们要做迁移。
Stripe 的订阅功能帮助像 DigitalOcean 和 Squarespace 这样的客户构建和管理他们用户的计费账单。在过去的几年里,我们持续不断地增加了许多功能,来支持他们越来越复杂的计费模型,比如多重订阅、试用、优惠券和发票等。
在最开始时,每个 Customer 对象最多只会有一条订阅数据。所以我们的客户数据都保存成了单条记录。因为用户和订阅之间的映射关系非常直接,所以订阅信息就和用户数据保存在了一起。
class Customer Subscription subscription end
后来,我们发现有些客户希望他们创建的 Customer 对象可以对应多条订阅数据。于是我们决定把服务于单次订阅的单条订阅数据升级一下,换成一个订阅数组,以此来保存多条有效的订阅数据。
class Customer array: Subscription subscriptions end
在继续添加新功能的时候,这样的数据模型就出问题了。每一次对用户的订阅信息的改动都意味着要更新整条用户记录,以及查询用户数据的与订阅相关的检索语句。于是我们决定把这些订阅信息单独保存起来。
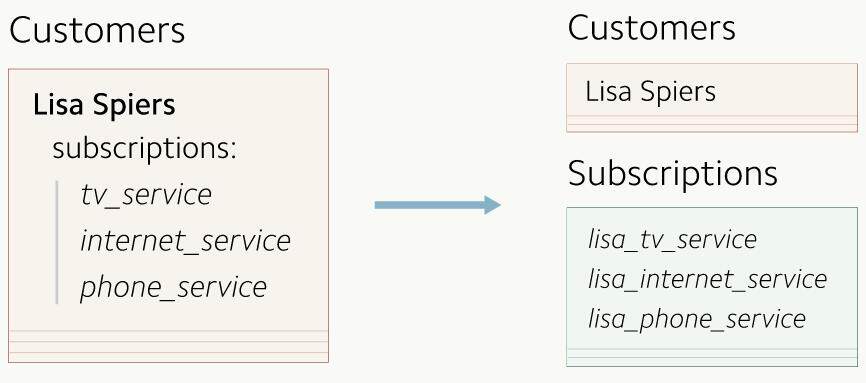
我们重新设计的数据模型把订阅信息移到了它们自己的表里。
复习一下,我们的四步迁移流程为:
- 向旧表和新表双重写入,以保持它们之间数据的同步;
- 把代码库中所有读数据的操作都指向新表;
- 把代码库中所有写数据的操作都指向新表;
- 把依赖旧数据模型的旧数据删掉。
接下来我们看看这理论上的四个阶段在我们的实际项目中是怎样实施的。
第一部分:双重写入
我们在迁移之前先创建了一张新的数据表。第一步就是开启复制新写入的数据,这样它就可以写到新旧两张表里了。然后我们再把新数据表中缺失的数据慢慢地补充过来,这样新旧两张表里的数据就完全一致了。
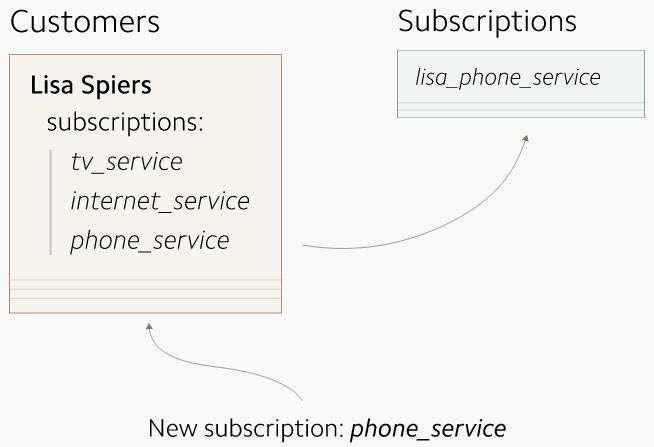
所有新的写入都要更新两张数据表。
在我们的案例里,我们会把所有新生成的订阅信息都同时写入用户表和订阅表。在开始双重写入两张表之前,一定要认真考虑一下这一份额外的写入操作给生产库的性能带来的影响。有种减轻性能影响的方法就是慢慢地增大开启复制的数据量,这同时一定要仔细地盯着各项运营指标。
到了这一步,所有新写入的数据就都同时存在于新旧两张表里了,而比较旧的数据则只保存在旧表中。于是我们可以以一种缓慢的模式开始拷贝已有的订阅信息:每当有数据被更新的时候,就自动地把它们也复制到新的表中。这种方法让我们可以开始增量地迁移已有的订阅数据。
最终,我们会把所有已有的用户订阅数据都补充到新的订阅表中去。
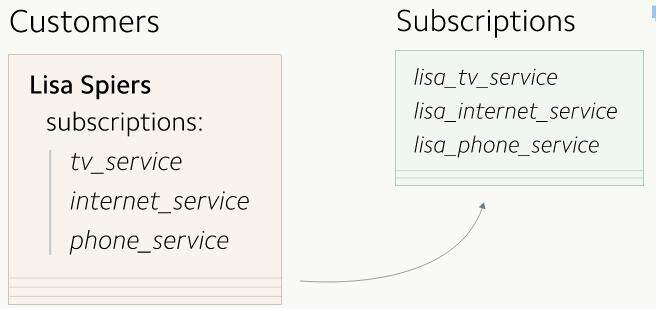
我们会把所有已有的用户订阅数据都补充到新的订阅表中去。
在生产数据库里补充新表数据的操作,代价最大的部分其实就是要找出所有需要迁移的数据而已。通过检索数据库来找出所有这样的数据需要检索生产库很多次,这会花费很大代价。幸运的是,我们可以把这个代价转用一个离线的方式完成,因此对生产库就毫无影响了。我们会为数据生成快照,并上传到 Hadoop 集群中,然后就可以用 MapReduce 的方法来快速地以离线、并行、分布式的方式处理数据了。
我们用 Scalding 来管理我们的 MapReduce 任务。Scalding 是一个用 Scala 写成的非常有用的库,用它来写 MapReduce 任务非常容易(写一个简单任务的话连 10 行代码都不用)。在这个案例中,我们用 Scalding 来找出所有的订阅数据。具体步骤如下:
- 写个 Scalding 任务来生成所有需要迁移的订阅数据的 ID 列表;
- 做一次大型的、多线程的迁移操作,来并行地把所有需要迁移的订阅数据快速拷贝复制过去;
- 当迁移结束之后,再运行一次 Scalding 任务,确保所有旧订阅表中的订阅数据都迁移到了新表里,没有遗漏;
第二部分:切换所有的读操作
现在新旧两张数据表中的数据都处于同步状态了,下一步就是把所有的读操作都迁移到新数据表上来。
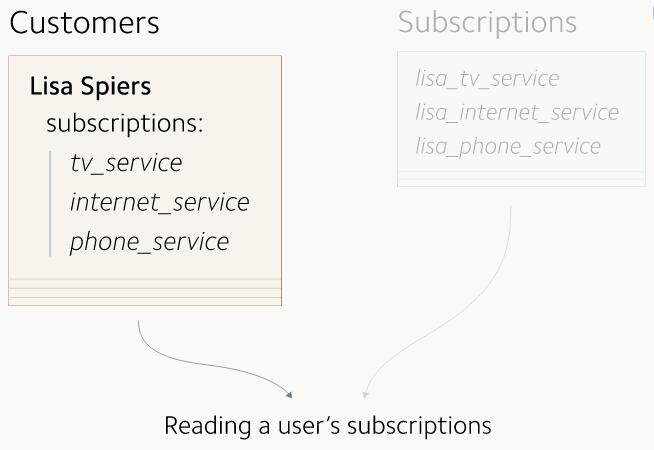
到这一步时,所有的读操作都仍然在使用旧的用户表:我们要切换到新的订阅表上来。
我们要很确信可以从新的订阅表中正常读出数据,这也意味着我们的订阅数据必须是一致的。我们用 GitHub 的 Scientist 来帮我们做验证。Scientist 是一个 Ruby 库,可以让我们执行测试,比较两段不同的代码的执行结果,如果在生产环境中两段逻辑会产生不同的结果,它就会发出警告。有了 Scientist,我们就可以实时地为不同的结果产生告警和获得指标。万一测试用的代码产生了错误也没有关系,我们的程序的其它部分并不会受到影响。
我们会做下面的验证:
- 用 Scientist 去分别从订阅表和用户表中读出数据;
- 如果结果不同,就抛出错误,提醒技术人员数据不一致;
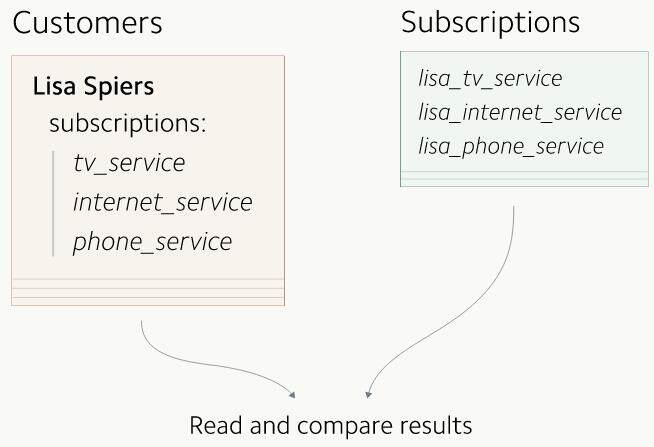
GitHub 的 Scientist 让我们可以同时从两张表中读出数据,并且比较结果。
如果验证通过,所有数据都能对得上,我们就可以从新表中读入数据了。
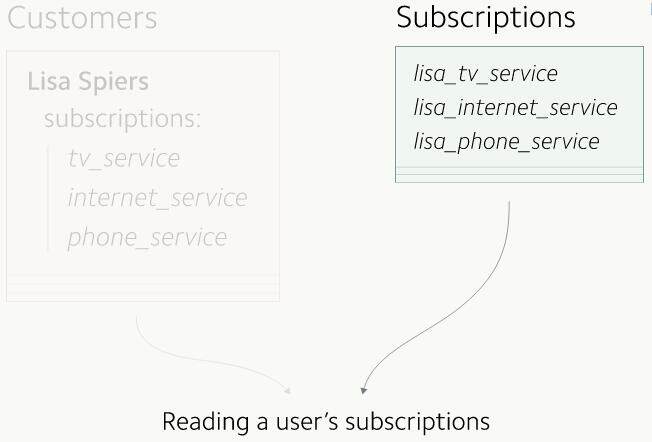
我们的验证很成功:所有的读操作都使用新的订阅表了。
第三部分:切换所有写操作
接下来,我们要把所有写操作都切换到新的数据表上来。我们的目标是渐进式地推进这些变动,因此我们要采用非常细致的战术。
到目前为止,我们一直在向旧数据表中写入数据,并复制到新表中:

现在我们要调换这个顺序:向新数据表中写入数据,并且同步到旧数据表中去。通过保持这两张数据表之间的数据一致,我们就可以不断地做增量更新,并且细致地观察每次改动的影响。
把所有处理订阅数据的代码都重构掉,这一块应该是整个迁移过程中最有挑战性的了。Stripe 处理订阅操作的逻辑分布在若干个服务的几千行代码中。
成功重构的关键就在于我们的渐进式流程:我们会尽可能地把数据处理逻辑限制到最小的范围内,这样我们就可以很小心地应用每一次改动。在每个阶段里,我们的新旧两张表中的数据都会保持一致。
对于每一处代码逻辑,我们都会用全面的方法来保证我们的改动是安全的。我们不能简单地用新数据替换旧数据:每一块逻辑都必须经过审重地考虑。不管我们漏掉了哪种特殊情况,都有可能会导致最终的数据不一致。幸运的是,我们可以在整个过程中不断地运行 Scientist 测试来提醒我们哪里可能会有不一致的情况发生。
我们简化了的新写入方式大概是这样的:

到最后我们加入逻辑,如果有任何调用这样过期的订阅数据的情况发生,我们就会强制抛出一个错误。这样我们就可以保证再也没有代码会用到它了。
class Customer def subscriptions hard_assertion_failed("Accessing subscriptions array on customer") end end
第四部分:删除旧数据
我们最后也是最有成就感的一步,就是把写入旧数据表的代码删掉,最后再把旧数据表删掉。
当我们确认再也没有代码依赖已被淘汰的旧订阅数据模型时,我们就再也不用写入旧数据表中了:

做了这些改动之后,我们的代码就再也不用使用旧数据表了,新的数据表就成了唯一的数据来源。
然后我们就可以删除掉我们的用户对象中的所有订阅数据了,并且我们会慢慢地渐进式地做删除操作。首先每当加载订阅数据的时候,我们都会自动地清空数据,最后会再运行一次 Scalding 任务以及迁移操作,来找出所有遗漏的未被删除的数据。最终我们会得到期望的数据模型:

结论
在迁移的同时还要保证 Stripe 的 API 是一致的,这事很复杂。我们有下面这些经验可以和大家分享:
- 我们总结出了四阶段迁移策略,这让我们可以在生产环境中不需要任何停机时间就可以完成数据切换操作。
- 我们采用了 Hadoop,用离线的方式进行了数据处理,这让我们可以用 MapReduce 并行地处理大量数据,而不是依靠对生产库进行代价昂贵的检索操作。
- 我们所有的改动都是渐进式的。每一次我们改动的代码量都绝对不会超过几百行。
- 我们所有的改动都是高度透明和可观测的。哪怕生产环境中有一条数据不一致,Scientist 测试都会立刻向我们告警。通过这种办法,我们可以确信我们的迁移操作是安全的。
我们在 Stripe 已经做过许多次在线迁移了,经过实践检验这些经验非常有效。希望别的团队在做大规模数据迁移时,我们的这些经验也可以对他们有所帮助。
感谢郭蕾对本文的策划和审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。

暂无签名

中国开发者画像洞察研究报告 2024
分析开发者的行为模式、工作价值、职业发展等内容,帮助整个行业生态更深入地理解开发者,为他们提供更精准...













评论