iOS 客户端应用架构看似简单,但实际上要考虑的事情不少。本文作者将以系列文章的形式来回答 iOS 应用架构中的种种问题,本文是其中的第二篇,主要讲 View 层的组织和调用方案。下篇主要讨论做 View 层架构的设计的一些心法。
本门心法
重剑无锋,大巧不工。 ---- 《神雕侠侣》
这是杨过在挑剑时,玄铁重剑旁边写的一段话。对此我深表认同。提到这段话的目的是想告诉大家,在具体做 View 层架构的设计时,不需要拘泥于 MVC、MVVM、VIPER 等规矩。这些都是招式,告诉你你就知道了,然后怎么玩都可以。但是心法不是这样的,心法是大巧,说出来很简单,但是能不能在实际架构设计时牢记心法,并且按照规矩办事,就都看个人了。
拆分的心法
天下功夫出少林,天下架构出 MVC。 ---- Casa Taloyum
MVC 其实是非常高 Level 的抽象,意思也就是,在 MVC 体系下还可以再衍生无数的架构方式,但万变不离其宗的是,它一定符合 MVC 的规范。这句话不是我说的,是我在某个英文资料上看到的,但时过境迁,我已经找不到出处了,我很赞同这句话。我采用的架构严格来说也是 MVC,但也做了很多的拆分。根据前面几节的洗礼,相信各位也明白了这样的道理:拆分方式的不同诞生了各种不同的衍生架构方案(MVCS 拆胖 Controller,MVVM 拆胖 Model,VIPER 什么都拆),但即便拆分方式再怎么多样,那都只是招式。而拆分的规范,就是心法。这一节我就讲讲我在做 View 架构时,做拆分的心法。
第一心法:保留最重要的任务,拆分其它不重要的任务
在 iOS 开发领域内,UIViewController 承载了非常多的事情,比如 View 的初始化,业务逻辑,事件响应,数据加工等等,当然还有更多我现在也列举不出来,但是我们知道有一件事情 Controller 肯定逃不掉要做:协调 V 和 M。也就是说,不管怎么拆,协调工作是拆不掉的。
那么剩下的事情我们就可以拆了,比如 UITableView 的 DataSource。唐巧的博客有一篇文章提到他和另一个工程师关于是否要拆分 DataSource 争论了好久。拆分 DataSource 这个做法应该也算是通用做法,在不复杂的应用里面,它可能确实看上去只是一个数组而已,但在复杂的情况下,它背后可能涉及了文件内容读取,数据同步等等复杂逻辑,这篇文章的第一节就提倡了这个做法,我其实也蛮提倡的。
前面的文章里面也提了很多能拆的东西,我就不搬运了,大家可以进去看看。除了这篇文章提到的内容以外,任何比较大的,放在 ViewController 里面比较脏的,只要不是 Controller 的核心逻辑,都可以考虑拆出去,然后在架构的时候作为一个独立模块去定义,以及设计实现。
第二心法:拆分后的模块要尽可能提高可复用性,尽量做到 DRY
根据第一心法拆开来的东西,很有可能还是强业务相关的,这种情况有的时候无法避免。但我们拆也要拆得好看,拆出来的部分最好能够归成某一类对象,然后最好能够抽象出一个通用逻辑出来,使他能够复用。即使不能抽出通用逻辑,那也尽量抽象出一个 protocol,来实现 IOP。这里有篇关于 IOP 的文章,大家看了就明白优越性了。
第三心法:要尽可能提高拆分模块后的抽象度
也就是说,拆分的粒度要尽可能大一点,封装得要透明一些。唐巧说一切隐藏都是对代码复杂性的增加,除非它带来了好处,这在一定程度上有点道理,没有好处的隐藏确实都不好(笑)。提高抽象度事实上就是增加封装的力度,将一个负责的业务抽象成只需要很少的输入就能完成,就是高度抽象。嗯,继承很多层,这种做法虽然也提高了抽象程度,但我不建议这么玩。我不确定唐巧在这里说的隐藏跟我说的封装是不是同一个概念,但我在这里想提倡的是尽可能提高抽象程度。
提高抽象程度的好处在于,对于业务方来说,他只需要收集很少的信息(最小充要条件),做很少的调度(Controller 负责大模块调度,大模块里面再去做小模块的调度),就能够完成任务,这才是给 Controller 减负的正确姿势。
如果拆分出来的模块抽象程度不够,模块对外界要求的参数比较多,那么在 Controller 里面,关于收集参数的代码就会多了很多。如果一部分参数的收集逻辑能够由模块来完成,那也可以做到帮 Controller 减轻负担。否则就感觉拆得不太干净,因为 Controller 里面还是多了一些不必要的参数收集逻辑。
如果拆分出来的粒度太小,Controller 在完成任务的时候调度代码要写很多,那也不太好。导致拆分粒度小的首要因素就是业务可能本身就比较复杂,拆分粒度小并不是不好,能大就大一点,如果小了,那也没问题。针对这种情况的处理,就需要采用 strategy 模式。
针对拆分粒度小的情况,我来举个实际例子,这个例子来源于我的一个朋友他在做聊天应用的消息发送模块。当消息是文字时,直接发送。当消息是图片时,需要先向服务器申请上传资源,获得资源 ID 之后再上传图片,上传图片完成之后拿到图片 URL,后面带着 URL 再把信息发送出去。
这时候我们拆模块,可以拆成:数据发送(叫 A 模块),上传资源申请(叫 B 模块),内容上传(叫 C 模块)。那么要发送文字消息,Controller 调度 A 就可以了。如果要发送图片消息,Controller 调度 B->C->A,假设将来还有上传别的类型消息的任务,他们又要依赖 D/E/F 模块,那这个事情就很蛋疼,因为逻辑复杂了,Controller 要调度的东西要区分的情况就多了,Controller 就膨胀了。
那么怎么处理呢?可以采用 Strategy 模式。我们再来分析一下,Controller 要完成任务,它初始情况下所具有的条件是什么?它有这条消息的所有数据,也知道这个消息的类型。那么它最终需要的是什么呢?消息发送的结果:发送成功或失败。
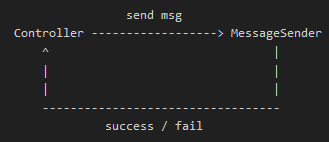
上面就是我们要实现的最终结果,Controller 只要把消息丢给 MessageSender,然后让 MessageSender 去做事情,做完了告诉 Controller 就好了。那么 MessageSender 里面怎么去调度逻辑?MessageSender 里面可以有一个 StrategyList,里面存放了表达各种逻辑的 Block 或者 Invocation(Target-Action)。那么我们先定义一个 Enum,里面规定了每种任务所需要的调度逻辑。
typedef NS_ENUM (NSUInteger, MessageSendStrategy)
{
MessageSendStrategyText = 0,
MessageSendStrategyImage = 1,
MessageSendStrategyVoice = 2,
MessageSendStrategyVideo = 3
}
然后在 MessageSender 里面的 StrategyList 是这样:
@property (nonatomic, strong) NSArray *strategyList;
self.strategyList = @[TextSenderInvocation, ImageSenderInvocation, VoiceSenderInvocation, VideoSenderInvocation];
// 然后对外提供一个这样的接口,同时有一个 delegate 用来回调
- (void)sendMessage:(BaseMessage *)message withStrategy:(MessageSendStrategy)strategy;
@property (nonatomic, weak) id<messagesenderdelegate> delegate;
@protocol MessageSenderDelegate<nsobject>
@required
- (void)messageSender:(MessageSender *)messageSender
didSuccessSendMessage:(BaseMessage *)message
strategy:(MessageSendStrategy)strategy;
- (void)messageSender:(MessageSender *)messageSender
didFailSendMessage:(BaseMessage *)message
strategy:(MessageSendStrategy)strategy
error:(NSError *)error;
@end</nsobject></messagesenderdelegate>
Controller 里面是这样使用的:
[self.messageSender sendMessage:message withStrategy:MessageSendStrategyText];
MessageSender 里面是这样的:
[self.strategyList[strategy] invoke];
然后在某个 Invocation 里面,就是这样的:
[A invoke];
[B invoke];
[C invoke];
这样就好啦,即便拆分粒度因为客观原因无法细化,那也能把复杂的判断逻辑和调度逻辑从 Controller 中抽出来,真正为 Controller 做到了减负。总之能够做到大粒度就尽量大粒度,实在做不到那也行,用 Strategy 把它 hold 住。这个例子是小粒度的情况,大粒度的情况太简单,我就不举了。
设计心法
针对 View 层的架构不光是看重如何合理地拆分 MVC 来给 UIViewController 减负,另外一点也要照顾到业务方的使用成本。最好的情况是业务方什么都不知道,然后他把代码放进去就能跑,同时还能获得框架提供的种种功能。
比如天安门广场上的观众看台,就是我觉得最好的设计,因为没人会注意到它。
第一心法:尽可能减少继承层级,涉及苹果原生对象的尽量不要继承
继承是罪恶,尽量不要继承。就我目前了解到的情况看,除了安居客的 Pad App 没有在框架级针对 UIViewController 有继承的设计以外,其它公司或多或少都针对 UIViewController 有继承,包括安居客 iPhone app(那时候我已经对此无能为力,可见 View 的架构在一开始就设计好有多么重要)。甚至有的还对 UITableView 有继承,这是一件多么令人发指,多么惨绝人寰,多么丧心病狂的事情啊。虽然不可避免的是有些情况我们不得不从苹果原生对象中继承,比如 UITableViewCell。但我还是建议尽量不要通过继承的方案来给原生对象添加功能,前面提到的 Aspect 方案和 Category 方案都可以使用。用 Aspect+load 来实现重载函数,用 Category 来实现添加函数,当然,耍点手段用 Category 来添加 property 也是没问题的。这些方案已经覆盖了继承的全部功能,而且非常好维护,对于业务方也更加透明,何乐而不为呢。
不用继承可能在思路上不会那么直观,但是对于不使用继承带来的好处是足够顶得上使用继承的坏处的。顺便在此我要给 Category 正一下名:业界对于 Category 的态度比较暧昧,在多种场合(讲座、资料文档)都宣扬过尽可能不要使用 Category。它们说的都有一定道理,但我认为 Category 是苹果提供的最好的使用集合代替继承的方案,但针对 Category 的设计对架构师的要求也很高,请合理使用。而且苹果也在很多场合使用 Category,来把一个原本可能很大的对象,根据不同场景拆分成不同的 Category,从而提高可维护性。
不使用继承的好处我在这里已经说了,放到iOS 应用架构来看,还能再多额外两个好处:1. 在业务方做业务开发或者做Demo 时,可以脱离App 环境,或花更少的时间搭建环境。2. 对业务方来说功能更加透明,也符合业务方在开发时的第一直觉。
第二心法:做好代码规范,规定好代码在文件中的布局,尤其是ViewController
这主要是为了提高可维护性。在一个文件非常大的对象中,尤其要限制好不同类型的代码在文件中的布局。比如在写ViewController 时,我之前给团队制定的规范就是前面一段全部是getter setter,然后接下来一段是life cycle,viewDidLoad 之类的方法都在这里。然后下面一段是各种要实现的Delegate,再下面一段就是event response,Button 的或者GestureRecognizer 的都在这里。然后后面是private method。一般情况下,如果做好拆分,ViewController 的private method 那一段是没有方法的。后来随着时间的推移,我发现开头放getter 和setter 太影响阅读了,所以后面改成全放在ViewController 的最后。
第三心法:能不放在Controller 做的事情就尽量不要放在Controller 里面去做
Controller 会变得庞大的原因,一方面是因为 Controller 承载了业务逻辑,MVC 的总结者(在正式提出 MVC 之前,或多或少都有人这么设计,所以说 MVC 的设计者不太准确)对 Controller 下的定义也是承载业务逻辑,所以 Controller 就是用来干这事儿的,天经地义。另一方面是因为在 MVC 中,关于 Model 和 View 的定义都非常明确,很少有人会把一个属于 M 或 V 的东西放到其他地方。然后除了 Model 和 View 以外,还会剩下很多模棱两可的东西,这些东西从概念上讲都算 Controller,而且由于 M 和 V 定义得那么明确,所以直觉上看,这些东西放在 M 或 V 是不合适的,于是就往 Controller 里面塞咯。
正是由于上述两方面原因导致了 Controller 的膨胀。我们再细细思考一下,Model 膨胀和 View 膨胀,要针对它们来做拆分其实都是相对容易的,Controller 膨胀之后,拆分就显得艰难无比。所以如果能够在一开始就尽量把能不放在 Controller 做的事情放到别的地方去做,这样在第一时间就可以让你的那部分将来可能会被拆分的代码远离业务逻辑。所以我们要稍微转变一下思路:模棱两可的模块,就不要塞到 Controller 去了,塞到 V 或者塞到 M 或者其他什么地方都比塞进 Controller 好,便于将来拆分。
所以关于前面我按下不表的关于胖 Model 和瘦 Model 的选择,我的态度是更倾向于胖 Model。客观地说,业务膨胀之后,代码规模肯定少不了的,不管你技术再好,经验再丰富,代码量最多只能优化,该膨胀还是要膨胀的,而且优化之后代码往往也比较难看,使用各种奇技淫巧也是有代价的。所以,针对代码量优化的结果,往往要么就是牺牲可读性,要么就是牺牲可移植性(通用性),Every magic always needs a pay, you have to make a trade-off.。
那么既然膨胀出来的代码,或者将来有可能膨胀的代码,不管放在 MVC 中的哪一个部分,最后都是要拆分的,既然迟早要拆分,那不如放 Model 里面,这样将来拆分胖 Model 也能比拆分胖 Cotroller 更加容易。在我还在安居客的时候,安居客 Pad app 承载最复杂业务的 ViewController 才不到 600 行,其他多数 Controller 都是在 300-400 行之间,这就为后面接手的人降低了非常多的上手难度和维护复杂度。拆分出来的东西都是可以直接迁移给 iPhone app 使用的。现在看天猫的 ViewControler,动不动就几千行,看不了多久头就晕了,问了一下,大家都表示很习惯这样的代码长度,摊手。
第四心法:架构师是为业务工程师服务的,而不是去使唤业务工程师的
架构师在公司里的职级和地位往往都是要高于业务工程师的,架构师的技术实力和经验往往也都是高于业务工程师的。所以你值得在公司里获得较高的地位,但是在公司里的地位高不代表在软件工程里面的角色地位也高。架构师是要为业务工程师服务的,是他们使唤你而不是你使唤他们。另外,制定规范一方面是起到约束业务工程师的代码,但更重要的一点是,这其实是利用你的能力帮助业务工程师避免他无法预见的危机,所以地位高有一定的好处,毕竟夏虫不可语冰,有的时候不见得能够解释得通,因此高地位随之而来的就是说服力会比较强。但在软件工程里,一定要保持谦卑,一定要多为业务工程师考虑。
一个不懂这个道理的架构师,设计出来的东西往往复杂难用,因为他只愿意做核心的东西,周边不愿意做的都期望交给业务工程师去做,甚至有的时候就只做了个 Demo,然后就交给业务工程师了,业务工程师变成给他打工的了。但是一个懂得这个道理的架构师,设计出来的东西会非常好用,业务方只需要扔很少的参数然后拿结果就好了,这样的架构才叫好的架构。
举一个保存图片到本地的例子,一种做法是提供这样的接口:- (NSString *)saveImageWithData:(NSData *)imageData,另一种是 - (NSString *)saveImage:(UIImage *)image。后者更好,原因自己想。
你的态度越谦卑,就越能设计出好的架构,这是我设计心法里的最后一条,也是最重要的一条。即使你现在技术实力不是业界大牛级别的,但只要保持这个心态去做架构,去做设计,就已经是合格的架构师了,要成为业界大牛也会非常快。
小总结
其实针对 View 层的架构设计,还是要做好三点:代码规范,架构模式,工具集。
代码规范对于 View 层来说意义重大,毕竟 View 层非常重业务,如果代码布局混乱,后来者很难接手,也很难维护。
架构模式具体如何选择,完全取决于业务复杂度。如果业务相当相当复杂,那就可以使用 VIPER,如果相对简单,那就直接 MVC 稍微改改就好了。每一种已经成为定式的架构模式不见得都适合各自公司对应的业务,所以需要各位架构师根据情况去做一些拆分或者改变。拆分一般都不会出现问题,改变的时候,只要别把 MVC 三个角色搞混就好了,M 该做啥做啥,C 该做啥做啥,V 该做啥做啥,不要乱来。关于大部分的架构模式应该是什么样子,这篇文章里都已经说过了,不过我认为最重要的还是后面的心法,模式只是招术,熟悉了心法才能大巧不工。
View 层的工具集主要还是集中在如何对 View 进行布局,以及一些特定的 View,比如带搜索提示的搜索框这种。这篇文章只提到了 View 布局的工具集,其它的工具集相对而言是更加取决于各自公司的业务的,各自实现或者使用 CocoaPods 里现成的都不是很难。
对于小规模或者中等规模 iOS 开发团队来说,做好以上三点就足够了。在大规模团队中,有一个额外问题要考虑,就是跨业务页面调用方案的设计。
跨业务页面调用方案的设计
跨业务页面调用是指,当一个 App 中存在 A 业务,B 业务等多个业务时,B 业务有可能会需要展示 A 业务的某个页面,A 业务也有可能会调用其他业务的某个页面。在小规模的 App 中,我们直接 import 其他业务的某个 ViewController 然后或者 push 或者 present,是不会产生特别大的问题的。但是如果 App 的规模非常大,涉及业务数量非常多,再这么直接 import 就会出现问题。
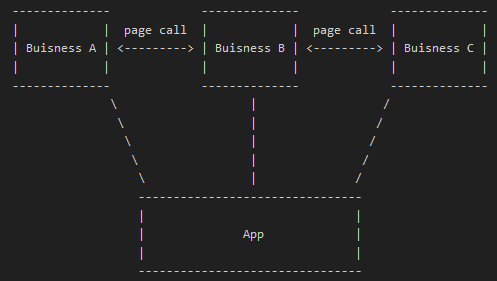
可以看出,跨业务的页面调用在多业务组成的 App 中会导致横向依赖。那么像这样的横向依赖,如果不去设法解决,会导致什么样的结果?
- 当一个需求需要多业务合作开发时,如果直接依赖,会导致某些依赖层上端的业务工程师在前期空转,依赖层下端的工程师任务繁重,而整个需求完成的速度会变慢,影响的是团队开发迭代速度。
- 当要开辟一个新业务时,如果已有各业务间直接依赖,新业务又依赖某个旧业务,就导致新业务的开发环境搭建困难,因为必须要把所有相关业务都塞入开发环境,新业务才能进行开发。影响的是新业务的响应速度。
- 当某一个被其他业务依赖的页面有所修改时,比如改名,涉及到的修改面就会特别大。影响的是造成任务量和维护成本都上升的结果。
当然,如果 App 规模特别小,这三点带来的影响也会特别小,但是在阿里这样大规模的团队中,像天猫/淘宝这样大规模的 App,一旦遇上这里面哪怕其中一件事情,就很坑爹。
那么应该怎样处理这个问题?
让依赖关系下沉。
怎么让依赖关系下沉?引入 Mediator 模式。
所谓引入 Mediator 模式来让依赖关系下沉,实质上就是每次呼唤页面的时候,通过一个中间人来召唤另外一个页面,这样只要每个业务依赖这个中间人就可以了,中间人的角色就可以放在业务层的下面一层,这就是依赖关系下沉。
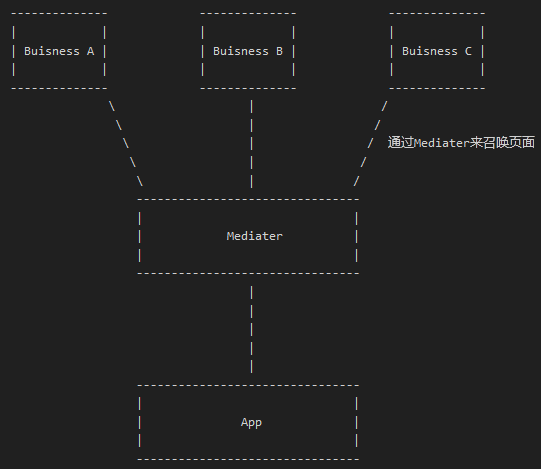
当 A 业务需要调用 B 业务的某个页面的时候,将请求交给 Mediater,然后由 Mediater 通过某种手段获取到 B 业务页面的实例,交还给 A 就行了。在具体实现这个机制的过程中,有以下几个问题需要解决:
- 设计一套通用的请求机制,请求机制需要跟业务剥离,使得不同业务的页面请求都能够被 Mediater 处理
- 设计 Mediater 根据请求如何获取其他业务的机制,Mediater 需要知道如何处理请求,上哪儿去找到需要的页面
这个看起来就非常像我们 web 开发时候的 URL 机制,发送一个 Get 或 Post 请求,CGI 调用脚本把请求分发给某个 Controller 下的某个 Action,然后返回 HTML 字符串到浏览器去解析。苹果本身也实现了一套跨 App 调用机制,它也是基于 URL 机制来运转的,只不过它想要解决的问题是跨 App 的数据交流和页面调用,我们想要解决的问题是降低各业务的耦合度。
不过我们还不能直接使用苹果原生的这套机制,因为这套机制不能够返回对象实例。而我们希望能够拿到对象实例,这样不光可以做跨业务页面调用,也可以做跨业务的功能调用。另外,我们又希望我们的 Mediater 也能够跟苹果原生的跨 App 调用兼容,这样就又能帮业务方省掉一部分开发量。
就我目前所知道的情况,AutoCad 旗下某款 iOS 应用(时间有点久我不记得是哪款应用了,如果你是 AutoCad 的 iOS 开发,可以在评论区补充一下。)就采用了这种页面调用方式。天猫里面目前也在使用这套机制,只是这一块由于历史原因存在新老版本混用的情况,因此暂时还没能够很好地发挥应有的作用。
关于 Getter 和 Setter?
我比较习惯一个对象的"私有"属性写在 extension 里面,然后这些属性的初始化全部放在 getter 里面做,在 init 和 dealloc 之外,是不会出现任何类似 _property 这样的写法的。就是这样:
@interface CustomObject()
@property (nonatomic, strong) UILabel *label;
@end
@implement
#pragma mark - life cycle
- (void)viewDidLoad
{
[super viewDidLoad];
[self.view addSubview:self.label];
}
- (void)viewWillAppear:(BOOL)animated
{
[super viewWillAppear:animated];
self.label.frame = CGRectMake(1, 2, 3, 4);
}
#pragma mark - getters and setters
- (UILabel *)label
{
if (_label == nil) {
_label = [[UILabel alloc] init];
_label.text = @"1234";
_label.font = [UIFont systemFontOfSize:12];
... ...
}
return label;
}
@end
唐巧说他喜欢的做法是用 _property 这种,然后关于 _property 的初始化通过 [self setupProperty] 这种做法去做。从刚才上面的代码来看,就是要在 viewDidLoad 里面多调用一个 setup 方法而已,然后我推荐的方法就是不用多调一个 setup 方法,直接走 getter。
嗯,怎么说呢,其实两种做法都能完成需求。但是从另一个角度看,苹果之所以选择让 [self getProperty] 和 self.property 可以互相通用,这种做法已经很明显地表达了苹果的倾向:希望每个 property 都是通过 getter 方法来获得。
早在 2003 年,Allen Holub 就发了篇文章《 Why getter and setter methods are evil 》,自此之后,业界就对此产生了各种争议,虽然是从 Java 开始说的,但是发展到后面各种语言也参与了进来。然后虽然现在关于这个问题讨论得少了,但是依旧属于没有定论的状态。setter 的情况比较复杂,也不是我这一节的重点,我这边还是主要说 getter。我们从 objc 的设计来看,苹果的设计者更加倾向于 getter is not evil。
认为 getter is evil 的原因有非常之多,或大或小,随着争论的进行,大家慢慢就聚焦到这样的一个原因:Getter 和 Setter 提供了一个能让外部修改对象内部数据的方式,这是 evil 的,正常情况下,一个对象自己私有的变量应该是只有自己关心。
然后我们回到 iOS 领域来,objc 也同样面临了这样的问题,甚至更加严重:objc 并没有像 Java 那么严格的私有概念。但在实际工作中,我们不太会去操作头文件里面没有的变量,这是从规范上就被禁止的。
认为 getter is not evil 的原因也可以聚焦到一个:高度的封装性。getter 事实上是工厂方法,有了 getter 之后,业务逻辑可以更加专注于调用,而不必担心当前变量是否可用。我们可以想一下,假设一个 ViewController 有 20 个 subview 要加入 view 中,这 20 个 subview 的初始化代码是肯定逃不掉的,放在哪里比较好?放在哪里都比放在 addsubview 的地方好,我个人认为最好的地方还是放在 getter 里面,结合单例模式之后,代码会非常整齐,生产的地方和使用的地方得到了很好的区分。
所以放到 iOS 来说,我还是觉得使用 getter 会比较好,因为 evil 的地方在 iOS 这边基本都避免了,not evil 的地方都能享受到,还是不错的。
总结
要做一个 View 层架构,主要就是从以下三方面入手:
- 制定良好的规范
- 选择好合适的模式(MVC、MVCS、MVVM、VIPER)
- 根据业务情况针对 ViewController 做好拆分,提供一些小工具方便开发
当然,你还会遇到其他的很多问题,这时候你可以参考这篇文章里提出的心法,在后面提到的跨业务页面调用方案的设计中,你也能够看到我的一些心法的影子。
对于 iOS 客户端来说,它并不像其他语言诸如 Python、PHP 他们有那么多的非官方通用框架。客观原因在于,苹果已经为我们做了非常多的事情,做了很多的努力。在苹果已经做了这么多事情的基础上,架构师要做针对 View 层的方案时,最好还是尽量遵守苹果已有的规范和设计思想,然后根据自己过去开发 iOS 时的经验,尽可能给业务方在开发业务时减负,提高业务代码的可维护性,就是 View 层架构方案的最大目标。
关于 AOP
AOP(Aspect Oriented Programming),面向切片编程,这也是面向 XX 编程系列术语之一哈,但它跟我们熟知的面向对象编程没什么关系。
什么是切片?
程序要完成一件事情,一定会有一些步骤,1,2,3,4 这样。这里分解出来的每一个步骤我们可以认为是一个切片。
什么是面向切片编程?
你针对每一个切片的间隙,塞一些代码进去,在程序正常进行 1,2,3,4 步的间隙可以跑到你塞进去的代码,那么你写这些代码就是面向切片编程。
为什么会出现面向切片编程?
你要想做到在每一个步骤中间做你自己的事情,不用 AOP 也一样可以达到目的,直接往步骤之间塞代码就好了。但是事实情况往往很复杂,直接把代码塞进去,主要问题就在于:塞进去的代码很有可能是跟原业务无关的代码,在同一份代码文件里面掺杂多种业务,这会带来业务间耦合。为了降低这种耦合度,我们引入了 AOP。
如何实现 AOP?
AOP 一般都是需要有一个拦截器,然后在每一个切片运行之前和运行之后(或者任何你希望的地方),通过调用拦截器的方法来把这个 jointpoint 扔到外面,在外面获得这个 jointpoint 的时候,执行相应的代码。
在 iOS 开发领域,objective-C 的 runtime 有提供了一系列的方法,能够让我们拦截到某个方法的调用,来实现拦截器的功能,这种手段我们称为 Method Swizzling。Aspects 通过这个手段实现了针对某个类和某个实例中方法的拦截。
另外,也可以使用 protocol 的方式来实现拦截器的功能,具体实现方案就是这样:
@protocol RTAPIManagerInterceptor <nsobject>
@optional
- (void)manager:(RTAPIBaseManager *)manager beforePerformSuccessWithResponse:(AIFURLResponse *)response;
- (void)manager:(RTAPIBaseManager *)manager afterPerformSuccessWithResponse:(AIFURLResponse *)response;
- (void)manager:(RTAPIBaseManager *)manager beforePerformFailWithResponse:(AIFURLResponse *)response;
- (void)manager:(RTAPIBaseManager *)manager afterPerformFailWithResponse:(AIFURLResponse *)response;
- (BOOL)manager:(RTAPIBaseManager *)manager shouldCallAPIWithParams:(NSDictionary *)params;
- (void)manager:(RTAPIBaseManager *)manager afterCallingAPIWithParams:(NSDictionary *)params;
@end
@interface RTAPIBaseManager : NSObject
@property (nonatomic, weak) id<rtapimanagerinterceptor> interceptor;
@end</rtapimanagerinterceptor></nsobject>
这么做对比 Method Swizzling 有个额外好处就是,你可以通过拦截器来给拦截器的实现者提供更多的信息,便于外部实现更加了解当前切片的情况。另外,你还可以更精细地对切片进行划分。Method Swizzling 的切片粒度是函数粒度的,自己实现的拦截器的切片粒度可以比函数更小,更加精细。
缺点就是,你得自己在每一个插入点把调用拦截器方法的代码写上(笑),通过 Aspects(本质上就是 Mehtod Swizzling)来实现的 AOP,就能轻松一些。
编后语
为了更好地向读者输出更优质的内容,InfoQ 将精选来自国内外的优秀文章,经过整理审校后,发布到网站。本篇文章作者为田伟宇,原文链接为 Casa Taloyum 。本文已由原作者授权 InfoQ 中文站转载。
感谢徐川对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们,并与我们的编辑和其他读者朋友交流(欢迎加入 InfoQ 读者交流群 )。
)。




