
本系列文章专注于 Web API__ 之 “元语言”的三个关键领域:即 API__ 描述、API__ 发现以及 API__ 档案。这些文章将涵盖所有这三个重要的趋势,并包括对这一快速发展的领域的一些关键人物的专访。
来自 InfoQ__ 的这篇文章是“描述、发现以及档案:进入Web API__ 的下一阶段”系列文章中的一篇,你可以在这里进行订阅,以便通过RSS__ 获取新文章的通知。
Web API 的下一阶段
虽然 Web API 的实现正变得越来越普及,但在工具方面还缺乏一些被广泛接受的标准,用以描述、发现,并且理解大量基于 API 的服务的意义。如何围绕着 API 的“元层面”对工具进行定义与实现,这方面仍然存在着大量的机会。
从目前来看,在以下三个领域方面,人们持续地表现出关注的态度以及开展实际的工作。这几个领域分别是:
描述
API 描述指的是以一种让人类与机器都可读的形式对 API 进行描述,包括 API 的实现细节,例如资源与 URL、表述格式(HTML、XML、JSON 等等)、状态码以及输入参数。在这一领域方面,有几个关键的带头者正处于前沿的位置。
发现
API 发现是指按照一些特定的条件(例如上线时间、许可、定价以及性能限制),寻找以及选择能够提供所需服务(例如购物、用户管理等等)的 Web API 的过程。目前来说,这一过程主要还是由人类驱动的,但已经出现了一些工具,试图将这一过程中的某些部分实现自动化。
档案
“档案”一直以来都是图书管理员与信息科学家所关注的内容,它定义了 API 请求与响应中所包含的词汇表术语的含义与使用方式。随着 Web API 的发展,档案也重新获得了技术人员的关注。虽然它依然是一种实验性质的思想,但有迹象显示,API 的提供者与设计者正在开始实现对 Web API 档案的支持。
本文将对 Web API 元数据的这三个方面进行一次简单的回顾,并指出每个领域中的关键性工具与发展趋势。
描述 API 的实现
目前,对于 API 的设计与实现的关注主要集中于它的 _ 描述 _ 格式。如今经常为人提及的格式包括 Swagger 、 RAML 以及 API Blueprint ,但其实现有的格式可以举出长长的一列。这些格式各自采取了一种略有不同的设计方式,但在本质上都提供了相同的基本特性:以多种不同级别的细节对 Web API 进行描述。
API 优先
现如今,大多数设计方式都支持 _API__ 优先 _ 的概念。你首先以某种基于 XML、JSON 或 YAML 的元语言描述你的 API,并通过生成的文档(或文档集)自动生成一些实现方面的元素,例如服务端代码、人类可读的文档、测试 harness、SDK,甚至是包含完整功能的 API 客户端。
API 优先设计方式的一个例子是由 Apiary 所推出的 API Blueprint 格式。它是一种基于 Markdown 的格式,目标是支持人类可读的 API 描述,_ 同时 _ 又保证它的机器可读性。在以下示例中,你可以看到一个单一的资源(/message),它支持 GET 与 PUT 两种方法。你还可以看到其中对人类可读的文本的支持,以描述操作该 API 的方法。
API Blueprint**** 描述示例
FORMAT: 1A # Resource and Actions API This API example demonstrates how to define a resource with multiple actions. # /message This is our resource ## GET Here we define an action using the `GET` HTTP request method. As with every good action it should return a response + Response 200 (text/plain) Hello World! ## PUT OK, let's add an update action and send a response back confirming the posting was a success {1} + Request (text/plain) {1} All your base are belong to us. {1} + Response 204 {1}
RAML 、 Swagger 以及其它一些类似格式的工作方式也是大同小异。
在采用 API 优先方式时,你需要通过工具将设计时创建的元语言转换为可以在运行时起作用的东西。举例来说,Swagger 的 codegen 工具能够解析描述文档,并生成相应的客户端代码。而 RAML-for-JAX-RS 项目则在 RAML 描述与通过 JAX-RS 进行注解的 Java 代码之间提供双向转换的功能。
代码优先
支持代码优先方式的描述模型为数极少,这种方式是通过源代码生成服务描述。不过,这一领域中最知名的格式 —— Web Service 描述语言(WSDL)在企业级应用社区中仍然相当流行,并且支持 WSDL 的工具为数众多,像微软的 Visual Studio 与 Eclipse 等常见的编辑平台都提供了对它的支持。
下面是通过 WSDL 对某个简单的 Web API 进行描述的一个示例。
HelloService WSDL**** 示例
<definitions name="HelloService" targetNamespace="http://www.examples.com/wsdl/HelloService.wsdl" xmlns="http://schemas.xmlsoap.org/wsdl/" xmlns:soap="http://schemas.xmlsoap.org/wsdl/soap/" xmlns:tns="http://www.examples.com/wsdl/HelloService.wsdl" xmlns:xsd="http://www.w3.org/2001/XMLSchema"> <message name="SayHelloRequest"> <part name="firstName" type="xsd:string"/> </message> <message name="SayHelloResponse"> <part name="greeting" type="xsd:string"/> </message> <portType name="Hello_PortType"> <operation name="sayHello"> <input message="tns:SayHelloRequest"/> <output message="tns:SayHelloResponse"/> </operation> </portType> <binding name="Hello_Binding" type="tns:Hello_PortType"> <soap:binding style="rpc" transport="http://schemas.xmlsoap.org/soap/http"/> <operation name="sayHello"> <soap:operation soapAction="sayHello"/> <input> <soap:body encodingStyle="http://schemas.xmlsoap.org/soap/encoding/" namespace="urn:examples:helloservice" use="encoded"/> </input> <output> <soap:body encodingStyle="http://schemas.xmlsoap.org/soap/encoding/" namespace="urn:examples:helloservice" use="encoded"/> </output> </operation> </binding> <service name="Hello_Service"> <documentation>WSDL File for HelloService</documentation> <port binding="tns:Hello_Binding" name="Hello_Port"> <soap:address location="http://www.examples.com/SayHello/" /> </port> </service> </definitions>
如果选择了代码优先方式,那么你就需要通过某些工具,将你的 _ 源代码 _ 转换为可重用的 API 描述元数据。Eclipse 与 Visual Studio 都可以一键实现通过代码生成 WSDL 文件。另外还有一些工具能够 _ 读取 _WSDL 文件,并生成各种实现元素。例如 SmartBear 的 SoapUI 工具就能够基于 WSDL 文件生成代码、创建人类可读的文档,甚至是进行构建与运行测试集等任务。
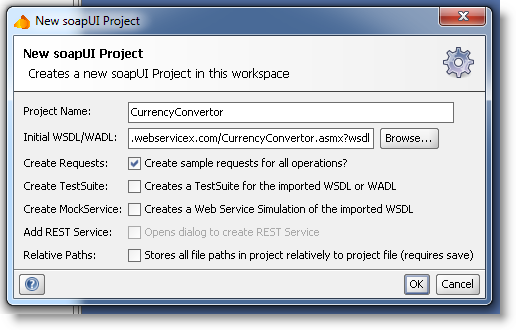
图 1. SoapUI 能够读取 WSDL 文件
将 API 文档化
大多数 API 描述格式同样支持生成人类可读的文档,包括 RAML、Apiary 和 Swagger。实际上,开源的 Swagger-UI 工具就是以文档生成器而闻名的(见下图),甚至让某些人产生了一种误解,认为 Swagger 仅仅是一种用于生成人类可读的 API 文档的工具。
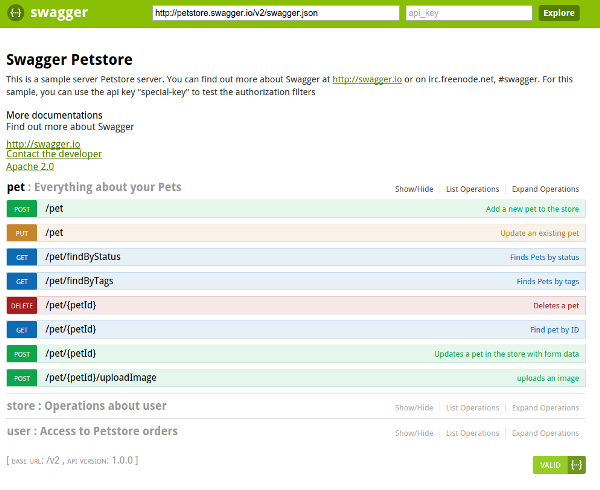
图 2. 由Swagger-UI工具生成人类可读的文档
有一些描述格式在设计时就专注于生成人类可读的文档,Mashery 的 I/O Docs 就是这方面的一个绝佳例子(见下图),它同时还提供测试方面的支持。
Mashery的 I/O Docs示例
{ "name": "Lower Case API", "description": "An example api.", "protocol": "rest", "basePath": "http://api.lowercase.sample.com", "publicPath": "/v1", "auth": { "key": { "param": "key" } }, "headers": { "Accept": "application/json", "Foo": "bar" }, "resources": { "Resource Group A": { "methods": { "MethodA1": { "name": "Method A1", "path": "/a1/grab", "httpMethod": "GET", "description": "Grabs information from the A1 data set.", "parameters": { "param1": { "type": "string", "required": true, "default": "", "description": "Description of the first parameter." } } }, "MethodA1User": { "name": "Method A1 User", "path": "/a1/grab/{userId}", "httpMethod": "GET", "description": "Grabs information from the A1 data set for a specific user", "parameters": { "param1": { "type": "string", "required": true, "default": "", "description": "Description of the first parameter." }, "userId": { "type": "string", "required": true, "default": "", "description": "The userId parameter that is in the URI." } } } } } } }
描述与发现并非一回事
不过,无论你的专注点是通过元语言生成代码,或是由代码生成文档(或者其它任何一种方式),API 描述只是整个创建与部署 Web API 流程中的一个环节而已。这一流程中还包括另一个重要环节,就是了解有哪些“现有”的 API 与服务,以及怎样使用它们。为了实现这一环节,你需要去 _ 发现 _ 这些 API。
发现现实世界中的 API
API 发现是指定位某个能够完成特定任务所必须的 Web API 的能力。举例来说,你可能需要某个 Web API,以实现在线购物、管理用户帐号或处理帮助平台上的请求的功能。在实际应用中,你应当能够以最小的代价发起一次搜索、找到符合你需求的 API、获得访问该 API 的能力、实现对接代码并且开始使用该 API。
可惜,现实情况总是有所差异的。
在讨论 API 发现时,我们通常所指的是 _ 应用程序编程接口 _(API)与一个实际 “运行中”的服务这两者之一。对于前一种情况来说,所讨论的内容只是一个接口,我们将用这个接口设计、实现以及部署属于自己的服务。而对后一种情况来说,我们所指的是某个现有的服务实例本身,你可以远程连接到这个服务中,并立即开始使用。由于这两种情况所面临的困难以及所产生的好处各不相同,因此应当通过示例进行一些考查。
API Commons
如果你所寻找的只是一种已经发布的 API 规范,并且能够自己完成它的实现,那么 API Commons 是一个很好的资源。API Commons 的目的在于“为 API 规范、接口以及数据模型提供一种简单而透明的机制,让用户能够以协作的方式共享无版权归属的设计”。打个比方,如果你已经设计了一种 API,并且乐于将它的设计分享给他人,让他们利用你设计的模型实现自己的服务,你就可以将自己的模型发布在 API Commons 上,并鼓励其他人使用。
另一方面,如果你打算实现某个 API,而又想知道是否已经有人处理了相同的问题,那么你可以 API Commons 中进行一番搜索,看看有没有什么现成的设计可以使用。这种发布 / 订阅模式能够促使相似的服务重用相同的接口,而无需与参与者之间讨论协作的细节。在最理想的情况下,如果某个 API 调用者需要使用 API Commons 上所注册的某个 API 的设计,那么他也应当能够使用实现了相同设计的任何一种服务。
API Commons 的运维模式得到了 Creative Commons 的启发,目前由 Kin Lane 与 Steve Willmott 负责维护。
可搜索的服务列表
在多数情况下,当人们谈及 API 发现时,他们所指的其实是发现某个能够利用的 _ 运行实例 _,即某个可用的服务。目前已经出现了一定数量的服务,它们将追踪实际的可用服务,并且大多数这种服务都是设计为人类可读的搜索引擎。其中最著名的一个例子就是 Programming Web 的 API 目录(见下图)
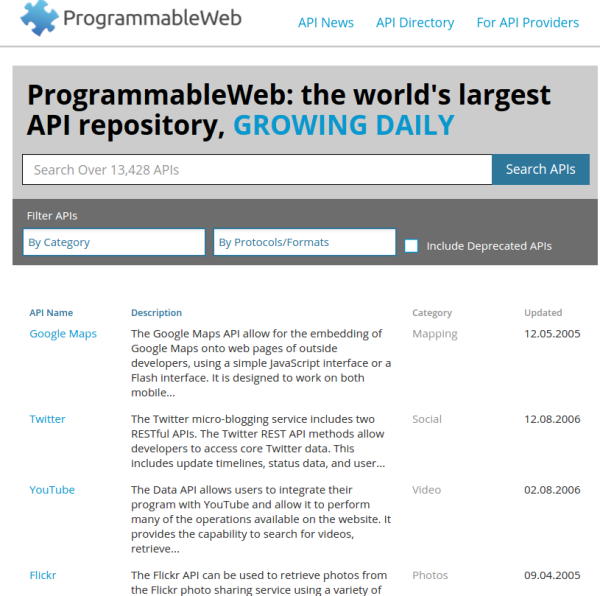
图3. Programmable Web的搜索界面
当你的需求满足下表中的任意一条时,就可以考虑这种解决方案:
- 搜索能够满足你的条件的服务
- 对于看起来能够满足你需求的 API 进行评估
- 参与该服务的接入过程,以及最后一条
- 编写你的 API 调用代码,以匹配你所选择的服务的 API
你所选择的服务有可能会支持一种或多种我们已在上文中涵盖的 API 描述语言,这将简化你创建对应的 API 调用代码的工作。
这种发现服务有一个潜在的缺点,那就是并非所有的服务目录都经过了认真地审查(某些目录要依赖于“手动注册过程”)。你在这一过程中可能会找到一些有问题的 API,它们或许不支持你所需的协议或格式,并且不再更新、或者无法满足你在性能与许可方面的需求,等等。此外,如果你打算使用多个第三方 API,那么整个搜索、评估、接入以及接口生成循环可能会显得相当冗长。
聚合服务
除此之外,还存在着另一种类型的 API 发现方式,即 API 聚合器。这些聚合器就如同一个或多个现有 web service 的某种代理,并提供一个单一的、统一的 API,方便你进行编码。这方面的一个例子是 Intel 的 Mashery API Network 。
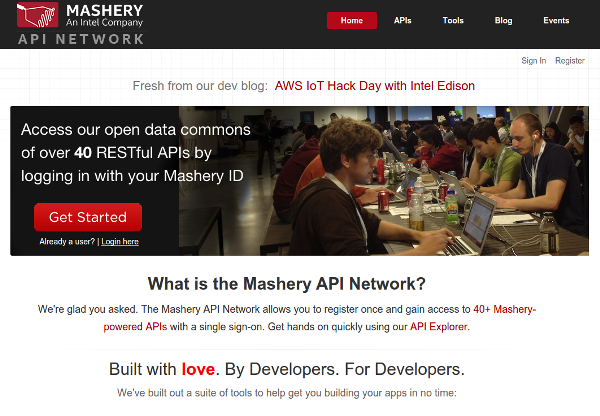
图4. Mashery的 ****API Network
如果你计划调用多个第三方的 Web API,那么聚合器能够让你在接入以及 API 整合方面所需付出的精力大大减少。聚合服务能够调用后端的 API 并进行正规化、管理你的访问密钥、某些服务甚至能够为你提供一个自定义的 API,通过它简化在每个第三方 API 中共享关联数据的任务。
可配置的运行时发现能力
人们还可以以另一种方式来看待这些 API 发现服务,即将其视为一种可配置的本地服务发现引擎。这种发现引擎只存在于某个公司的边界范围之内,并处理寻找以及连接到一或多个运行中的服务实例的工作,例如某个数据存储或业务组件。最近几年来,这种方式正在不断地发展中,这方面的例子包括 Apache Zookeeper 、HashiCorp 的 Consul 、以及 CoreOS 的 etcd 等等。

图 5. Apache Zookeeper**** 以及 HashiCorp的Consul**** 提供了在企业内部进行运行时发现的功能。
这种发现方式的一大优势在于,当你准备连接到组织内部的运行服务时,它提供了一个额外的间接层。你可以在运行代码中移除实际的服务地址与连接参数,并将这部分信息保存在配置文件中。某些服务甚至还允许你对于延迟与响应性进行一些限制,让它自动忽略或跳过运行时间较长的、或是不可用的服务实例,并连接至下一个可用的、健康的实例。
当然,这种抽象也存在着负面的因素。首先,由此产生的复杂性只有在大型服务中才值得一试。其次,对于这种服务的配置模型还没有实现标准化,这意味着你会最终对于某个提供商产生强依赖关系。最后,这种运行时的发现服务目前还无法用于组织之外的、公开的第三方服务。
通过 APIs.io 与 APIs.json 实现 Web 规模的发现功能
与 API 的单一资源集合相对的是 APIs.io 的 _ 分布式搜索 _ 概念,APIs.io 是由 3Scale 与来自 API Evangelist 的 Kin Lane 共同合作的成果。它是一种典型的搜索引擎,它本身并不负责 _ 托管 _API 文档,而是跟踪互联网上找到的所有发现文件,并为这些文件中的数据提供一个搜索界面。
这些发现文件都是以一种名为 APIs.json 的格式所生成的。与 API 描述文档不同,APIs.json 文件并不包含可用的 URL、表述形式以及响应代码的详细信息,而是包含了指向这些描述文档位置的 _ 指针 _,以及指向服务条款、许可、联系方式以及其它相关数据的指针。
这一格式出现的时间很短,但它或许能够提供一种“粘合剂”,将 API 的描述与其它数据连接至一个单一的位置。由于这一格式也是机器可读的,因此它或许能够帮助搜索功能、甚至是 Web API 的上线细节实现自动化。
描述与发现仍停留在细节层面
API 描述与 API 发现的共同目标是简化构建与定位 Web API 的工作,但它们将大量的精力都专注于低层面的实现细节中,例如如何描述协议方法、返回代码以及响应的格式。对于编写实际代码来说,它们固然非常重要,但有时仍不足以实现 _ 设计 _ 优秀 API 的任务。由于它们的多数设计方式都专注于实现细节,因此往往只能描述某个运行中的服务的 _ 单一实例 _(或镜像集群)的特性。
如果你希望专注于更高层面的设计(例如用例、输入与输出),而不是充斥着协议、表述与资源的细节,那么你还需要别的工具。
通过档案达成共识
在 API 元服务的开发中的一个最新趋势是创建与共享 API_ 档案 _ 信息的想法。与描述文档不同,档案文档提供了一个更高层次的视图,它描述了 API 所支持的功能,在有些情况下还能够描述客户端与服务器如何以一种机器可读的方式暴露它们的特性。
Web 档案的历史简介
Web 档案的出现已经有很长一段时间了,在 1999 年出现的 HTML 4.01 规范中就引入了档案这一属性。元数据档案可以定义为 a) 一个全局唯一的名称 (URI),或 b) 指向一个实际文档的链接(URL)。它的设计理念是让文档的作者得以为响应中的内容提供额外的描述性信息(例如文档的实用索引属性、服务条款等等)。
在2003 年, Tantek Çelik 定义了 XHTML 元数据档案(XMDP)。XMDP 支持定义同时实现人类可读与机器可读的文档档案(是不是听上去有点熟悉?),这种文档实际上看起来与如今的 API 描述格式非常相像(参考以下示例)。
XMDP**** 的一个示例
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" lang="en"> <head><title>sample HTML profile</title></head> <body> <dl class="profile"> <dt id='author'>author</dt> <dd>A person who wrote (at least part of) the document.</dd> <dt id='keywords'>keywords</dt> <dd>A comma and/or space separated list of the keywords or keyphrases of the document.</dd> <dt id='copyright'>copyright</dt> <dd>The name (or names) of the copyright holder(s) for this document, and/or a complete statement of copyright.</dd> <dt id='date'>date</dt> <dd>The last updated date of the document, in ISO8601 date format.</dd> <dt id='identifier'>identifier</dt> <dd>The normative URI for the document.</dd> <dt id='rel'>rel</dt> <dd> <dl> <dt id='script'>script</dt> <dd>A reference to a client-side script. When used with the LINK element, the script is evaluated as the document loads and may modify the contents of the document dynamically.</dd> </dl> </dd> </dl> </body> </html>
遗憾的是,档案属性没有得到广泛的应用,并且在 HTML 5 发布时从规范中被删除了,只能通过其它方式独立地定义档案属性。
在档案属性从HTML 规范中移除之后, Erik Wilde 提出了 RFC6906 规范,定义了 Link Relation Value 这种档案,并注册在互联网号码分配局(IANA)中。Wilde 的想法是将URI 风格的档案进行标准化,通过一种不透明的标识符,“允许资源表述指定它们是否遵循了一种或多种档案”。
由于我们能够将响应的细节以档案的形式进行描述,因此人们开始不仅将档案应用于人类可读的文档,并且也应用在API 的响应中。在最近几年中也出现了一些URL 风格的档案实现。在本文中,我将介绍其中的两种:DCAP 与ALPS。
都柏林核心应用档案(DCAP)
在2009 年,都柏林核心元数据启动计划(DCMI)发布了由他们设计的 DCAP 格式,用于描述档案元数据。DCAP 专注于支持资源描述框架(RDF)文档,它“定义了元数据记录,以此满足特定的应用程序需求。同时在全局定义词汇表与模型的基础上,提供了与其它应用程序在语义上互操作的能力。”
以下是 DCAP 文档的一个示例:
DCAP**** 文档示例
Description template: Person id=person minimum = 0; maximum = unlimited Statement template: givenName Property: http://xmlns.com/foaf/0.1/givenname minimum = 0; maximum = 1 Type of Value = "literal" Statement template: familyName Property: http://xmlns.com/foaf/0.1/family_name minimum = 0; maximum = 1 Type of Value = "literal" Statement template: email Property: http://xmlns.com/foaf/0.1/mbox minimum = 0; maximum = unlimited Type of Value = "non-literal" value URI = mandatory
创建 DCAP 的原因是因为如今的表述格式(RDF)非常受限,并且过于泛用(例如元组),在这种情况下,DCAP 能够改进共享数据语义的能力。DCAP 的一个关键优势在于,它并不是直接指出在响应中使用了哪些术语(例如 givenName、familyName、customer、user 等等),而是指出这些术语是 _ 如何 _ 进行通信的。这种方式为创建可共享的在线词汇表铺平了道路。
目前已经出现了一部分与 DCAP 相关的工具,包括在线编辑器、验证功能以及 HTML 的生成器。但 DCAP 的使用主要限制于图书馆、信息科学与学术社区等领域,很少看到将 DCAP 用于业务相关的 Web API 中。
应用级别的档案语义(ALPS)
在 2013 年,Leonard Richardson、Mark Foster 与我共同发布了 ALPS 互联网草案的第一个版本。与 DCAP 类似,ALPS 同样借用了 XDMP 的思想,它为数据元素(例如 userName、userStatus 等等)与用例元素(例如 find-user 等等)都提供了元数据。
以下是通过一个 ALPS 文档描述一个简单的搜索 API 的示例:
由 ALPS**** 文档所描述的搜索 API
{ "alps" : { "version" : "1.0", "doc" : { "href" : "http://example.org/samples/full/doc.html" }, "descriptor" : [ { "id" : "find-user", "type" : "safe", "doc" : {"value" : "User search form" }, "descriptor" : [ { "id" : "userName", "type" : "descriptor", "doc" : { "value" : "input for search" } }, { "href" : "#userStatus" } ] }, { "id" : "userStatus", "type" : "descriptor", "description" : {"value" : "results filter"}, "ext" : [ { "href" : "http://alps.io/ext/range", "value" : "active,inactive" } ] } ] } }
ALPS 文档专注于接口层面的互动,按 Eric Evans 的话来说也就是边界上下文。ALPS 并不会处理一些实现方面的细节,例如协议(HTTP、XMPP 等等)、格式(HTML、JSON 等等)甚至是资源的URL。由于它无需关注实现细节,因此ALPS 文档能够作为API 设计工具的原始资料,以生成人类可读的文档,甚至可作为发现过程中的一个环节,帮助你选择一个合用的API。
目前,对于ALPS 最佳的描述是将其视为一个“不稳定的”规范,并且在网上关于如何使用它的示例也非常罕见。 Ronnie Mitra 设计了一个实验性质的 Rapido API 设计器(见下图)能够使用 ALPS 文档作为输入,而 Pivotal 的 Spring-Data 工具能够将 ALPS 文档的生成作为 API 构建过程中的一环。
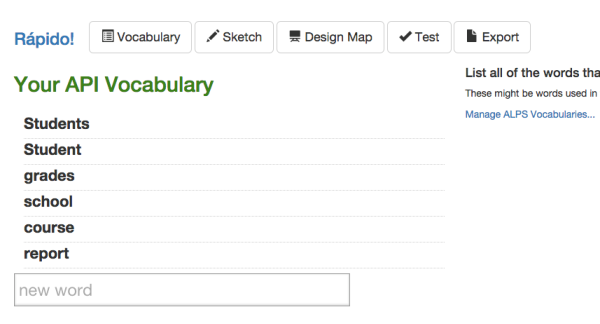
图 6. 通过Rapido API设计器管理档案的词汇表
只是一种尝试,还是将领导新的潮流?
虽然在 Web API 中使用档案的做法重新吸引了人们的注意,但这种技术到底是一种会逐渐消失的实验?还是会由此开创一个新的趋势,以专注于独立地定义 Web API 的数据与行为语义?现在下判断还为时过早。
所面临的挑战
在本文中,你对于 Web API 元数据的三个关键领域,即描述、发现及档案有了一个初步的了解。Swagger、RAML 以及 Apiary 等技术目前掌握着主动权,它们控制了 API 描述这一领域,而在这个发展良好的生态系统中还存在着一些其它技术。有一些工具能够通过描述格式实现代码与文档生成的自动化,并且围绕着几个关键的格式,出现了许多功能强大的工具集。
API 发现这一领域依然由以人类驱动的搜索与选择方式作为主导,而像 Intel 的 Mashery 这种关键的 API 聚合器依然是通过提供一种聚合的方式订阅远程的 API。而自动化的、基于配置的定位服务也正在逐渐兴起,以支持连接到企业级服务实例的功能。其中有部分方式或许将提供对基于互联网的 API 进行自动化服务发现的功能。
最后是 API 档案,它常用于图书馆与信息科学领域中,而它在与业务相关的 Web API 领域中也逐渐引起了人们的关注。目前出现的一些首创概念要么还属于实验性质,要么很少为人所知,但已经开始有一些 API 提供商开始支持 API 档案了。
Web 是一个充满活力的、飞速发展的领域,为了即时到来的时刻,不妨关注一下 API 生态系统中的这种“元层面”的思想,这一过程应当是充满趣味的。
关于作者
 Mike Amundsen是一位国际知名作者与讲师,他经常在全球各地旅行,就分布式网络架构、Web 应用开发以及其它主题进行顾问工作与演讲。Amundsen 在 API Academy 担任架构总监的角色,负责为全球范围内的公司提供服务,帮助客户与企业了解如何最好地利用由 API 带来的无数机遇。在过去 15 年间,Amundsen 编写了大量与编程相关的书籍与论文。他目前正在撰写一本名为《学习客户端超媒体》的新书,其中涵盖了构建能够充分利用超媒体 API 服务的客户端应用的常见方式。他最近出版的一本书是与 Leonard Richardson 合著的《RESTful Web APIs》,于 2013 年出版。Amundsen 在 2011 年出版的书籍《通过 HTML5 与 Node 创建超媒体 API》是在构建具有可适应性的 Web 应用时经常被引用的一本著作。他目前正在为 O’Reilly 创作一本新书《学习客户端超媒体》,在 2015 年秋季应当能够看到它的身影。
Mike Amundsen是一位国际知名作者与讲师,他经常在全球各地旅行,就分布式网络架构、Web 应用开发以及其它主题进行顾问工作与演讲。Amundsen 在 API Academy 担任架构总监的角色,负责为全球范围内的公司提供服务,帮助客户与企业了解如何最好地利用由 API 带来的无数机遇。在过去 15 年间,Amundsen 编写了大量与编程相关的书籍与论文。他目前正在撰写一本名为《学习客户端超媒体》的新书,其中涵盖了构建能够充分利用超媒体 API 服务的客户端应用的常见方式。他最近出版的一本书是与 Leonard Richardson 合著的《RESTful Web APIs》,于 2013 年出版。Amundsen 在 2011 年出版的书籍《通过 HTML5 与 Node 创建超媒体 API》是在构建具有可适应性的 Web 应用时经常被引用的一本著作。他目前正在为 O’Reilly 创作一本新书《学习客户端超媒体》,在 2015 年秋季应当能够看到它的身影。
本系列文章专注于 Web API__ 之 “元语言”的三个关键领域:即 API__ 描述、API__ 发现以及 API__ 档案。这些文章将涵盖所有这三个重要的趋势,并包括对这一快速发展的领域的一些关键人物的专访。
来自 InfoQ__ 的这篇文章是“描述、发现以及档案:进入Web API__ 的下一阶段”系列文章中的一篇,你可以在这里进行订阅,以便通过RSS__ 获取新文章的通知。

暂无签名

中国开发者画像洞察研究报告 2024
分析开发者的行为模式、工作价值、职业发展等内容,帮助整个行业生态更深入地理解开发者,为他们提供更精准...













评论