
Pinterest 是一家提供可视化书签工具的公司,这种工具可以帮助人们发现并保存有创意的想法,目前这家公司正使用实时数据分析来达到以数据驱动决策的目的。实验中使用了 MemSQL 和 Spark 这样的技术,用以分析来自全球的用户实时行为信息。
通过 MemSQL 和 Spark,Pinterest 创建了一条数据管道。这条管道通过 Apache Kafka 使数据流入 MemSQL,并且通过 Spark Streaming API 向 Spark 输入数据(译者注:数据流向是 Kafka -> Spark -> MemSQL ,见图 1)。这个方案对了解全球用户如何使用 Pins(译者注:即可视化书签)提供了实时性的洞察。这有助于 Pinterest 成为一个更好的推荐引擎,它可以显示相关的 Pins,人们会在不同的场景下来使用这种服务,比如为购物、去某个地方和烹饪食谱做个计划。
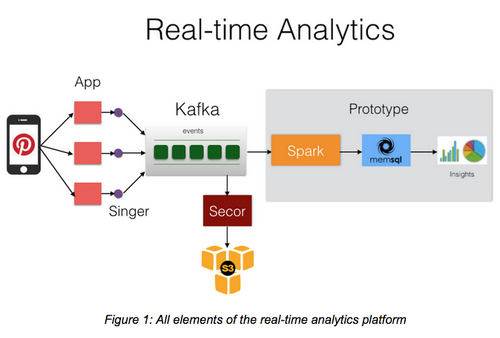
Pin 的行为数据(engagement data)先被送入到 Kafka 主题(Topic)中,接着它被 Spark streaming 作业消耗掉。作业中每个 Pin 会进行过滤,然后加上其地理位置和 Pin 的类别来充实其信息。接着再通过 MemSQL Spark 连接器(MemSQL Spark Connector)将充实后的信息持久化到 MemSQL 数据库中以提供查询服务。MemSQL Spark 连接器提供了 Spark 读写 MemSQL 数据库的工具,它使用 MemSQL RDD(Resilient Distributed Dataset)从 MemSQL 读取数据。
综上所述,这个方案框架可以支持实时地收集、存储和处理用户行为数据。同时,它也可以帮助获得下面这些能力:
- 高性能事件日志:即使用一个叫 Singer 的代理来收集事件日志,然后把它们运送到集中的数据仓库中。
- 可靠的日志传输和存储:即通过 Apache kafka 和一个叫 Secor 的持久化服务来可靠将这些事件写入到长期数据存储 Amazon S3 中。Secor 在设计上克服了 S3 的弱最终一致性模型(weak eventual consistency model)的缺陷,没有数据丢失而且支持水平扩展和可选的基于日期的数据分片。
- 基于实时数据的快速查询:即在实时事件到达时就对它们执行 SQL 查询。
查看英文原文: Real-time Data Analytics at Pinterest using MemSQL and Spark Streaming

中国开发者画像洞察研究报告 2024
分析开发者的行为模式、工作价值、职业发展等内容,帮助整个行业生态更深入地理解开发者,为他们提供更精准...













评论