
从 MapReduce 的兴起,就带来一种思路,就是希望通过大量廉价的机器来处理以前需要耗费昂贵资源的海量数据。这种方式事实上是一种架构的水平伸缩模式——真正的以量取胜。毕竟,以现在的硬件发展来看,CPU 的核数、内存的容量以及海量存储硬盘,都慢慢变得低廉而高效。然而,对于商业应用的海量数据挖掘或分析来看,硬件成本依旧是开发商非常关注的。当然最好的结果是:既要马儿跑得快,还要马儿少吃草。
Spark 相对于 Hadoop 的 MapReduce 而言,确乎要跑得迅捷许多。然而,Spark 这种 In-Memory 的计算模式,是否在硬件资源尤其是内存资源的消耗上,要求更高呢?我既找不到这么多机器,也无法租用多台虚拟 instance,再没法测评的情况下,只要寻求 Spark 的官方网站,又或者通过 Google 搜索。从 Spark 官方网站,Databricks 公司 Patrick Wendell 的演讲以及 Matei Zaharia 的 Spark 论文,找到了一些关于 Spark 硬件配置的支撑数据。
Spark 与存储系统
如果 Spark 使用 HDFS 作为存储系统,则可以有效地运用 Spark 的 standalone mode cluster,让 Spark 与 HDFS 部署在同一台机器上。这种模式的部署非常简单,且读取文件的性能更高。当然,Spark 对内存的使用是有要求的,需要合理分配它与 HDFS 的资源。因此,需要配置 Spark 和 HDFS 的环境变量,为各自的任务分配内存和 CPU 资源,避免相互之间的资源争用。
若 HDFS 的机器足够好,这种部署可以优先考虑。若数据处理的执行效率要求非常高,那么还是需要采用分离的部署模式,例如部署在 Hadoop YARN 集群上。
Spark 对磁盘的要求
Spark 是 in memory 的迭代式运算平台,因此它对磁盘的要求不高。Spark 官方推荐为每个节点配置 4-8 块磁盘,且并不需要配置为 RAID(即将磁盘作为单独的 mount point)。然后,通过配置 spark.local.dir 来指定磁盘列表。
Spark 对内存的要求
Spark 虽然是 in memory 的运算平台,但从官方资料看,似乎本身对内存的要求并不是特别苛刻。官方网站只是要求内存在 8GB 之上即可(Impala 要求机器配置在 128GB)。当然,真正要高效处理,仍然是内存越大越好。若内存超过 200GB,则需要当心,因为 JVM 对超过 200GB 的内存管理存在问题,需要特别的配置。
内存容量足够大,还得真正分给了 Spark 才行。Spark 建议需要提供至少 75% 的内存空间分配给 Spark,至于其余的内存空间,则分配给操作系统与 buffer cache。这就需要部署 Spark 的机器足够干净。
考虑内存消耗问题,倘若我们要处理的数据仅仅是进行一次处理,用完即丢弃,就应该避免使用 cache 或 persist,从而降低对内存的损耗。若确实需要将数据加载到内存中,而内存又不足以加载,则可以设置 Storage Level。0.9 版本的 Spark 提供了三种 Storage Level:MEMORY_ONLY(这是默认值),MEMORY_AND_DISK,以及 DISK_ONLY。
关于数据的持久化,Spark 默认是持久化到内存中。但它也提供了三种持久化 RDD 的存储方式:
- in-memory storage as deserialized Java objects
- in-memory storage as serialised data
- on-disk storage
第一种存储方式性能最优,第二种方式则对 RDD 的展现方式(Representing)提供了扩展,第三种方式则用于内存不足时。
然而,在最新版(V1.0.2)的 Spark 中,提供了更多的 Storage Level 选择。一个值得注意的选项是 OFF_HEAP,它能够将 RDD 以序列化格式存储到 Tachyon 中。相比 MEMORY_ONLY_SER,这一选项能够减少执行垃圾回收,使 Spark 的执行器(executor)更小,并能共享内存池。Tachyon 是一个基于内存的分布式文件系统,性能远超 HDFS。Tachyon 与 Spark 同源同宗,都烙有伯克利 AMPLab 的印记。目前,Tachyon 的版本为 0.5.0,还处于实验阶段。
注意,RDDs 是 Lazy 的,在执行 Transformation 操作如 map、filter 时,并不会提交 Job,只有在执行 Action 操作如 count、first 时,才会执行 Job,此时才会进行数据的加载。当然,对于一些 shuffle 操作,例如 reduceByKey,虽然仅是 Transformation 操作,但它在执行时会将一些中间数据进行持久化,而无需显式调用 persist() 函数。这是为了应对当节点出现故障时,能够避免针对大量数据进行重计算。要计算 Spark 加载的 Dataset 大小,可以通过 Spark 提供的 Web UI Monitoring 工具来帮助分析与判断。
Spark 的 RDD 是具有分区(partition)的,Spark 并非是将整个 RDD 一次性加载到内存中。Spark 针对 partition 提供了 eviction policy,这一 Policy 采用了 LRU(Least Recently Used)机制。当一个新的 RDD 分区需要计算时,如果没有合适的空间存储,就会根据 LRU 策略,将最少访问的 RDD 分区弹出,除非这个新分区与最少访问的分区属于同一个 RDD。这也在一定程度上缓和了对内存的消耗。
Spark 对内存的消耗主要分为三部分:
- 数据集中对象的大小;
- 访问这些对象的内存消耗;
- 垃圾回收 GC 的消耗。
一个通常的内存消耗计算方法是:内存消耗大小 = 对象字段中原生数据 * (2~5)。 这是因为 Spark 运行在 JVM 之上,操作的 Java 对象都有定义的“object header”,而数据结构(如 Map,LinkedList)对象自身也需要占用内存空间。此外,对于存储在数据结构中的基本类型,还需要装箱(Boxing)。Spark 也提供了一些内存调优机制,例如执行对象的序列化,可以释放一部分内存空间。还可以通过为 JVM 设置 flag 来标记存放的字节数(选择 4 个字节而非 8 个字节)。在 JDK 7 下,还可以做更多优化,例如对字符编码的设置。这些配置都可以在 spark-env.sh 中设置。
Spark 对网络的要求
Spark 属于网络绑定型系统,因而建议使用 10G 及以上的网络带宽。
Spark 对 CPU 的要求
Spark 可以支持一台机器扩展至数十个 CPU core,它实现的是线程之间最小共享。若内存足够大,则制约运算性能的就是网络带宽与 CPU 数。
Spark 官方利用 Amazon EC2 的环境对 Spark 进行了基准测评。例如,在交互方式下进行数据挖掘(Interative Data Mining),租用 Amazon EC2 的 100 个实例,配置为 8 核、68GB 的内存。对 1TB 的维基百科页面查阅日志(维基百科两年的数据)进行数据挖掘。在查询时,针对整个输入数据进行全扫描,只需要耗费 5-7 秒的时间。如下图所示:
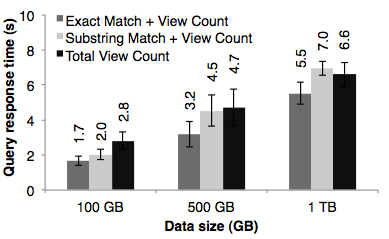
在 Matei Zaharia 的 Spark 论文中还给出了一些使用 Spark 的真实案例。视频处理公司 Conviva,使用 Spark 将数据子集加载到 RDD 中。报道说明,对于 200GB 压缩过的数据进行查询和聚合操作,并运行在两台 Spark 机器上,占用内存为 96GB,执行完全部操作需要耗费 30 分钟左右的时间。同比情况下,Hadoop 需要耗费 20 小时。注意:之所以 200GB 的压缩数据只占用 96GB 内存,是因为 RDD 的处理方式,使得我们可以只加载匹配客户过滤的行和列,而非所有压缩数据。

暂无签名

中国开发者画像洞察报告 2022
本次报告为你深度解读开发者人群背景,分析开发者群体面临的挑战,洞察开发者人群特征,预测开发者生态发展...









评论