来自于 Sharethrough 的数据基础设施工程师 Russell Cardullo 和 Michael Ruggiero 最近在 Cloudera 博客上投递了一篇博文,分享了他们是如何使用 Spark Streaming 解决复杂的实时问题的。下面是博文的具体内容,如果您想查看英文原文,可以点击这里。
Sharethrough 是一家从事视频广告业务的初创公司,在过去的三年中(从 Amazon EMR 上迁移出来之后)我们一直运行在 CDH 上面,主要是为了 ETL。随着 2013 年早期交易平台的启动以及对优化实时内容分发的需要,我们需要做出一些改变,但是 CDH 依然是我们基础设施中的一个重要部分。
在 2013 年年中,我们开始尝试使用基于流的方式访问管道中的点击流数据。我们问自己:我们是否能够给自己的开发人员一个针对增量、小批处理任务做过优化的编程模型和框架并继续依赖于 Cloudera 平台,而不是通过更频繁地运行那些更大的批处理任务“加热我们的冷路径”?在理想的情况下,我们的工程师团队关注于数据本身,而不是担心具体细节,例如管道间的状态一致性或者故障恢复。
Spark(和 Spark Streaming)
Apache Spark 是一个快速通用的大数据处理框架,它的编程模型比较适合于构建那些对常规的 MapReduce 而言太过于复杂或者不太可行的应用程序。Cloudera Enterprise 5 已经包含了 Spark,并且已经支持 CDH 4.4 及更新版本。借助于对内存持久化存储的抽象,Spark 支持所有的 MapReduce 功能,但是它执行地更快,因为它不需要进行数据复制、磁盘 I/O 和序列化。
因为 Spark Streaming 与 Spark 批处理和交互模式共享同样的 API,所以我们现在可以使用 Spark Streaming 实时聚合关键的业务数据。一致的 API 意味着我们能够使用较为简单的批处理模式进行本地的开发和测试,同时又能让这些工作无缝地在产品环境中运行。例如,我们现在可以使用与某个活动相关的所有数据集优化实时竞价,不需要等运行频率较低的 ETL 流完成。此外,我们还能执行实时实验并衡量结果。
使用 Spark 之前和之后
之前,我们的批处理系统是这样的:
- Apache Flume 基于最优的 HDFS 块大小(64MB)将文件写入到每小时的桶中
- 每天定时执行 MapReduce (Scalding) 任务 N 次
- Apache Sqoop 将结果移入数据仓库
- 延迟是~1 小时之后,加上 Hadoop 的处理时间

Sharethrough**** 之前的批处理数据流
对我们这个特定用例,尽管那些运算结果依然是有价值的,但是这个批处理流程却无法让我们实时访问绩效数据。例如,一个小时之后我们才能知道用户每天的预算是否花完,这意味着我们的广告商要花一些冤枉钱,我们的内容商无法填满自己的需求。即使是在批处理任务只会花费几分钟的时候,流量峰值也可能会减慢给定的批处理任务,导致它“撞”到新启动的任务。
对于这些用例,流式数据处理是可行的解决方案。
- Flume 将点击流数据写入 HDFS
- Spark 每 5 秒钟从 HDFS 上读取数据
- 输出到一个键—值存储并更新预测模型
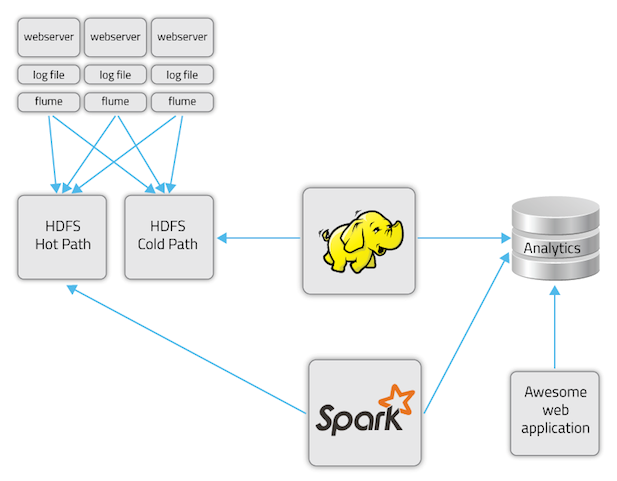
Sharethrough 新的基于 Spark Streaming 的数据流
在新模型中,我们的延迟时间仅仅是 Spark 的处理时间和 Flume 将文件传输到 HDFS 上的时间;在实际情况下,这个工作大约会花费 5 秒钟。
在路上
在开始使用 Spark Streaming 的时候,我们开始的非常快,遇到的麻烦很少。为了更好地利用新的 Streaming 任务,我们很快就调整成了 Spark 编程模型。
下面是我们在这个过程中发现的一些事情:
- 24 x 7 流式应用的结构和按小时的批处理任务是不同的——你可能需要细粒度的警报,并对重复的错误更有耐心。对于流式应用你需要良好的异常处理。准备好回答这样的问题:“如果 Spark 接收端不可用怎么办?应用程序是否应该重试?是否应该忽略丢失的数据?是否应该给你报警?”
- 花时间验证输入对应的输出。例如,验证一个记录点击数的任务在测试时是否会返回符合你期望的结果。
- 确认支持的对象被序列化。Scala DSL 让我们能够容易地封装非可序列化的变量或者引用。在我们的场景中,GeoCoder 对象并没有被序列化,导致我们的应用运行的非常慢;它必须返回到原来的驱动程序,非分布式对象。
- Spark Streaming 任务的输出仅和喂养 Spark 的队列一样可靠。如果生产队列落下了 1% 的消息,那么你可能需要一个定期调整策略,例如将有损耗的“热路径”和“冷路径”持久数据进行合并。对于这种类型的合并,当你确实需要精确可靠的关联计算时(例如计数)monoid 抽象可能是有帮助的。如果你想了解更多与此相关的信息,可以查看可合并的存储,例如 Twitter 的 Storehaus 或者 Oscar Boykin 的 Algebra for Analytics 。
结论
Sharethrough 的工程师打算使用 Spark Streaming 做更多的事情。我们的工程师可以交互式地制作一个应用程序,测试它的批处理,然后将它转移到 Streaming 上并让它正常运行。我们鼓励其他对实时处理感兴趣的人看看 Spark Streaming。由于简洁的 Spark API,熟悉 MapReduce 的工程师现在不需要学习全新的编程模型就能构建 Streaming 应用程序。
Spark Streaming 让你的组织能够攫取那些只能从分钟级的数据中获取的价值,或者以机器学习算法的形式,或者是实时仪表盘:完全取决于你!
感谢辛湜对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ )或者腾讯微博( @InfoQ )关注我们,并与我们的编辑和其他读者朋友交流。




