
上个月,来自 Twitter 的 Arun Kejariwal 在伦敦 Velocity 大会上做了一场演讲,展示了在主动预测系统资源需求以及业务指标(例如用户数或 tweet 条数等等)时, Twitter 所使用的预测算法。考虑到其数据流的动态特性,他们发现当对数据进行清洗(例如移除异常值)后,经过改善的 ARIMA 模型将会有良好表现。
除了实际预测准确性外(随着时间的推移,通过对预测与实际结果进行对比,来实现后评估),Twitter 使用的其他用于评估预测可用性的重要指标包括:模型在处理周期性(也即容纳每天的递归使用模式)和趋势(例如在重大体育活动过程中出现的井喷式使用)两方面的能力。如果离开适当的预测模型,潜在的周期性将变得更加难以处理:
随着用户基数以及用户使用热情的不断增长,面对潜在的趋势和上面提到的周期性,预测诸如 tweet、喜爱、照片等业务指标已经不再是一项微不足道的任务。在这种情况下,使用线性回归进行预测是一种欠妥当的做法,因为线性回归并不捕捉时间序列中的周期性。为了消解这一限制,我们尝试着使用 ARIMA 模型,它明确地对趋势和给定时间序列中的周期性组成部分进行建模,并由此产出统计意义上可靠的预测。
然而,对某个时间序列盲目地使用 ARIMA 模型,得到的预测并不一定具有统计意义上的可靠性。大部分情形下,这是因为不规则的数据会影响模型的建立以及其后的预测。如果某个异常的时间段没有展现出周期性,那么整体预测的周期性也就将几近消失。此外,如果某个给定时间段的边界数据点恰巧是异常值,那么整体预测也同样会就此产生偏差。因此,需要对最初的预测需求进行分析,并进行一些数据清洗工作,以使预测更加准确也更有用。Arun 还提到,异常值将被报告给开发团队,以便研究这些异常值是否由代码变化所致。
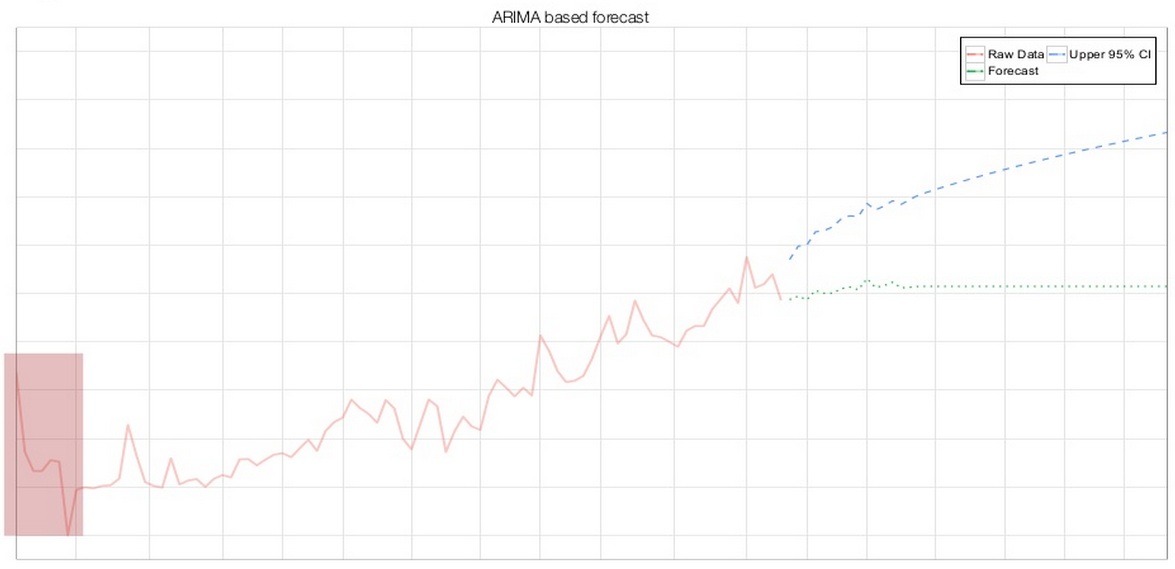
ARIMA__ 预测——在第一个时间段中有一个向下激凸(异常值)(图片由 Arun Kejariwal 提供)
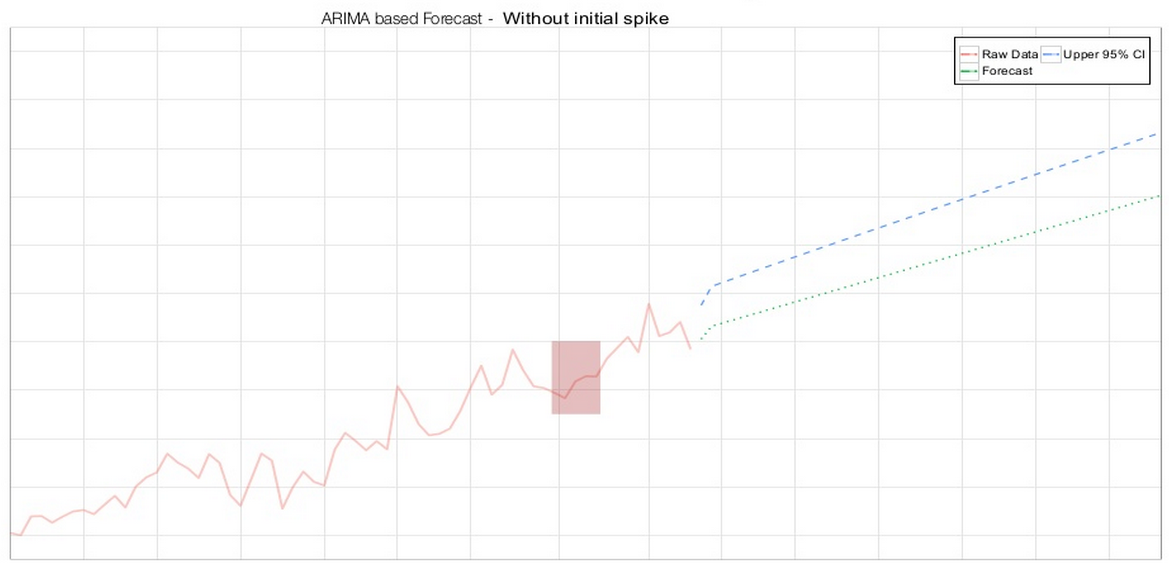
ARIMA__ 预测——第一个时间段内不含异常值(图片由 Arun Kejariwal 提供)
Arun 表示,除 ARIMA 外,Twitter 根据需要预测的资源类型,还使用了其他模型(例如 Holt-Winters 、 Spline 和 linear regression ):
我们已经探索了许多预测模型。具体使用哪一个模型将依据具体情况而定,并与模型选择问题(这是研究中的一个活跃领域)直接相关。
在不存在周期性的时候,我们倾向于使用线性回归,因为与其他模型相比,它的计算成本相对较低。当面对非线性趋势的时候,我们可以使用二次模型或其他类似的东西。然而,当趋势和周期性现身的情况下,预测的选择也将变得复杂起来。
Arun 还透露,Twitter 的预测一般被限定在技术事件(例如内部系统容量升级)之前的几周内。不过有时候也会为了某些业务指标(例如用户数)安排更长时间跨度的预测。此外,他们还计划在不久的将来,将预测应用在弹性扩展上。
查看英文原文: Forecasting at Twitter

暂无签名

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论