Apache 已经发布了 Kafka 0.8,也是自从成为 Apache 软件基金会的顶级项目后 Kafka 的第一个主版本。 Apache Kafka 是发布—订阅消息传递,实现了分布式提交日志,适用于离线和在线消息消费。它最初由 LinkedIn 开发的消息系统,用于低延迟的收集和发送大量的事件和日志数据。最新版本包括群集内复制和多数据目录支持。目前请求处理也是异步的,使用请求处理线程的附属线程池来实现。日志文件可以按年龄进行覆盖,并且日志级别可通过 JMX 进行动态设置。性能测试工具已提供,帮助解决存在的性能问题,并寻找潜在的性能优化点。
Kafka 是一个分布式,分区化,可复制的提交日志服务。生产者将消息发布到 Kafka 主题,消费者订阅这些主题并消费这些消息。在 Kafka 集群上一个服务器称为一个 Broker。对于每一个主题,Kafka 群集保留一个用于缩放,并行化和容错性的分区。每个分区是一个有序,不可变的消息序列,并不断追加到提交日志文件。分区的消息每个也被赋值一个称为偏移顺序的序列化编号。
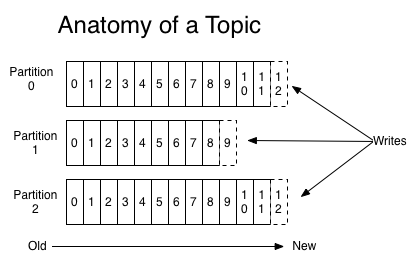
偏移是由消费者来控制。典型的消费者将处理列表中的下一条消息,它可以以任何顺序接收消息,因为 Kafka 集群为所有发布的消息保留一段可配置的时间。这让消费者很灵活,他们可以来去自由而不影响群集,并适合像 Hadoop 集群这样的脱机消费者。生产者能够选择那一个主题,主题的那一个分区,来发布该消息。消费者自己也可以分配一个消费者组名,每个消息将发送给每个订阅消费者组的消费者。如果所有的消费者有不同的消费组,那么消息将被广播到每一个消费者。
Kafka 可以像一个传统的消息 Broker 使用。它具有高吞吐量,内置分区,可复制和容错等特性,这使得它成为大型消息处理应用的理想解决方案。Kafka 也可以用于高访问量的网站活动的跟踪机制。网站活动可以被发布,并且可以被实时处理,或加载到 Hadoop 或离线的数据仓库系统。Kafka 也可以用来作为一种日志整合方案。代替工作于日志文件,日志可以作为消息流处理。
Kafka 目前用于 LinkedIn,它每天处理超过 100 亿消息,持续负载平均每秒 172,000 消息。目前,无论从内部和外部的使用数据的应用程序大量使用多订阅者支持。每个消息发布出来后,基本上会有 5.5 个消息消费者使用,这导致的结果是每一天将有 550 亿的消息发送给实时消费者。367 个主题涵盖用户活动的主题和运营数据,其中最大将每天增加的平均 92GB 批量压缩消息。信息保存时间为 7 天,这些平均约 9.5 TB 压缩消息跨越主题。除了在线消费者,还有众多的大型 Hadoop 集群,它们消费频繁,高吞吐量,并行矩阵,作为离线数据负载的一部分。
作为入门,访问官方的 Apache Kafka 文档页,你可以学习更多和下载 Kafka。也有一篇来自 LinkedIn 的论文,标题为《构建LinkedIn 的实时活动数据管道》 , 该论文讨论Kafka 建立原因和Kafka 设计上的特性。
查看英文原文: Apache Kafka - A Different Kind of Messaging System
感谢张龙对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ )或者腾讯微博( @InfoQ )关注我们,并与我们的编辑和其他读者朋友交流。




