EMC Greenplum 宣布了一个新的 Hadoop 发行版本—— Pivotal HD ,其中包含一个完全运行于 HDFS 之上的 MPP 数据库,兼容 SQL,而且速度“比 Hive 快数百倍”。
Pivotal HD 支持标准 Hadoop 发型版本的常用特性(包括 HDFS、Pig、Hive、Mahout 和 Map-Reduce 等),但又加入了一些其他的组件,具体如下面结构图所示:
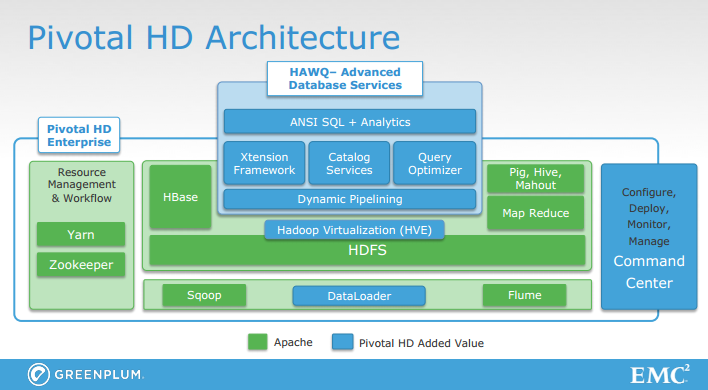
Pivotal 的主要组件是 HAWQ ,这是一个 MPP(Massively Parallel Processing)关系数据库,借助一种动态流水线机制直接运行于 Hadoop 中的 HDFS 之上,其特性包括:
- 兼容 SQL——支持各个版本的 SQL,包括 SQL92、SQL99 和 SQL 2003 OLAP 等。百分之百兼容 PostgreSQL 8.2。
- 面向行或面向列的数据存储。
- 查询优化器——查询可以运行于成千上万个节点上。
- 完全兼容 ODBC/JDBC。
- 交互式查询——大数据集上的复杂查询可以以秒级或次秒级的速度解决。
- 数据管理——提供了表统计和表安全等功能。
- 支持存储在 HDFS、Hive、HBase、Avro、ProtoBuf、分隔的文本和序列化文件中的数据。
- 深度分析——包含了数据挖掘和机器学习算法。
Greenplum 的高级技术总监 Gavin Sherry 做了一个演示(见该视频的42 分42 秒),在60 个节点组成的HDFS 集群上,有总量达几个TB 的10 亿行数据,下列SQL 语句可以在13 秒内执行完,这提供了接近实时的能力:
<p>SELECT gender, count (*)<br></br>FROM retail.order JOIN customers ON retail.order.customer_ID = customers.customer_ID<br></br>GROUP BY gender;</p>据 EMC Greenplum 的解决方案架构师 Donald Miner 介绍,“ HAWQ 比 Hive 快数百倍”,下图是 Greenplum 提供的基准测试结果( PDF ):
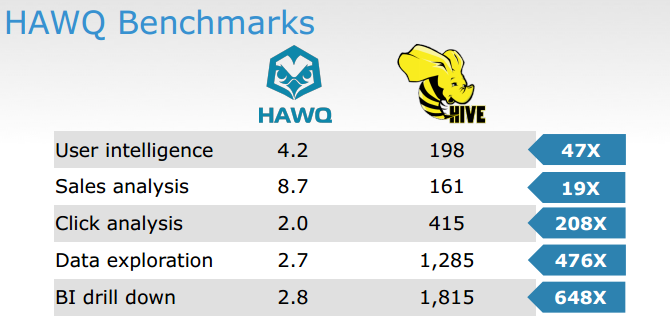
HAWQ 能够在“次秒级别内”解决查询问题,“同时做到了在同一引擎内支持规模更大的数据集和完整的 SQL 表达能力”。Miner 解释了这是如何做到的:
我们有所谓的“分段服务器(segment server)”来管理每个表的一个分片。集群中的每个数据节点上会运行一些分段服务器。不过这种数据分片是完全保存在 HDFS 内的。有一个“主节点”负责存储顶层元数据、构建查询计划并将节点本地的查询推送到分段服务器上。
在查询启动时,数据将从 HDFS 中读出并加载到 HAWQ 执行引擎中。HAWQ 遵循 MPP 架构,不同于将数据溢出到磁盘上和在磁盘上建立检查点(如 MapReduce),它会让数据流过流水线的不同阶段。另外,分段服务器是一直运行的,所以不存在启动时间。
Pivotal HD 有三个版本( PDF ):企业版、数据库服务版和用于评估的社区版。
查看英文原文: Greenplum Pivotal HD Combines the Strengths of SQL and Hadoop




