

编者按:本文节选自图灵程序设计丛书 《Flink 基础教程》一书中的部分章节。
分开处理连续的实时数据和有限批次的数据,可以使系统构建工作变得更加简单,但是这种做法将管理两套系统的复杂性留给了系统用户:应用程序的开发团队和 DevOps 团队需要自己使用并管理这两套系统。
为了处理这种情况,有些用户开发出了自己的流处理系统。在开源世界里,Apache Storm 项目(以下简称 Storm)是流处理先锋。Storm 最早由 Nathan Marz 和创业公司 BackType(后来被 Twitter 收购)的一个团队开发,后来才被 Apache 软件基金会接纳。Storm 提供了低延迟的流处理,但是它为实时性付出了一些代价:很难实现高吞吐,并且其正确性没能达到通常所需的水平。换句话说,它并不能保证 exactly-once;即便是它能够保证的正确性级别,其开销也相当大。
Lambda 架构概述:优势和局限性
对低成本规模化的需求促使人们开始使用分布式文件系统,例如 HDFS 和基于批量数据的计算系统(MapReduce 作业)。但是这种系统很难做到低延迟。用 Storm 开发的实时流处理技术可以帮助解决延迟性的问题,但并不完美。其中的一个原因是,Storm 不支持 exactly-once 语义,因此不能保证状态数据的正确性,另外它也不支持基于事件时间的处理。有以上需求的用户不得不在自己的应用程序代码中加入这些功能。
后来出现了一种混合分析的方法,它将上述两个方案结合起来,既保证低延迟,又保障正确性。这个方法被称作 Lambda 架构,它通过批量 MapReduce 作业提供了虽有些延迟但是结果准确的计算,同时通过 Storm 将最新数据的计算结果初步展示出来。
Lambda 架构是构建大数据应用程序的一种很有效的框架,但它还不够好。举例来说,基于 MapReduce 和 HDFS 的 Lambda 系统有一个长达数小时的时间窗口,在这个窗口内,由于实时任务失败而产生的不准确的结果会一直存在。Lambda 架构需要在两个不同的 API(application programming interface,应用程序编程接口)中对同样的业务逻辑进行两次编程:一次为批量计算的系统,一次为流式计算的系统。针对同一个业务问题产生了两个代码库,各有不同的漏洞。这种系统实际上非常难维护。
若要依靠多个流事件来计算结果,必须将数据从一个事件保留到下一个事件。这些保存下来的数据叫作计算的状态。准确处理状态对于计算结果的一致性至关重要。在故障或中断之后能够继续准确地更新状态是容错的关键。
在低延迟和高吞吐的流处理系统中维持良好的容错性是非常困难的,但是为了得到有保障的准确状态,人们想出了一种替代方法:将连续事件中的流数据分割成一系列微小的批量作业。如果分割得足够小(即所谓的微批处理作业),计算就几乎可以实现真正的流处理。因为存在延迟,所以不可能做到完全实时,但是每个简单的应用程序都可以实现仅有几秒甚至几亚秒的延迟。这就是在 Spark 批处理引擎上运行的 Apache Spark Streaming(以下简称 Spark Streaming)所使用的方法。
更重要的是,使用微批处理方法,可以实现 exactly-once 语义,从而保障状态的一致性。如果一个微批处理作业失败了,它可以重新运行。这比连续的流处理方法更容易。Storm Trident 是对 Storm 的延伸,它的底层流处理引擎就是基于微批处理方法来进行计算的,从而实现了 exactly-once 语义,但是在延迟性方面付出了很大的代价。
然而,通过间歇性的批处理作业来模拟流处理,会导致开发和运维相互交错。完成间歇性的批处理作业所需的时间和数据到达的时间紧密耦合,任何延迟都可能导致不一致(或者说错误)的结果。这种技术的潜在问题是,时间由系统中生成小批量作业的那一部分全权控制。Spark Streaming 等一些流处理框架在一定程度上弱化了这一弊端,但还是不能完全避免。另外,使用这种方法的计算有着糟糕的用户体验,尤其是那些对延迟比较敏感的作业,而且人们需要在写业务代码时花费大量精力来提升性能。
为了实现理想的功能,人们继续改进已有的处理器(比如 Storm Trident 的开发初衷就是试图克服 Storm 的局限性)。当已有的处理器不能满足需求时,产生的各种后果则必须由应用程序开发人员面对和解决。以微批处理方法为例,人们往往期望根据实际情况分割事件数据,而处理器只能根据批量作业时间(恢复间隔)的倍数进行分割。当灵活性和表现力都缺乏的时候,开发速度变慢,运维成本变高。
于是,Flink 出现了。这一数据处理器可以避免上述弊端,并且拥有所需的诸多功能,还能按照连续事件高效地处理数据。Flink 的一些功能如图 1 所示。
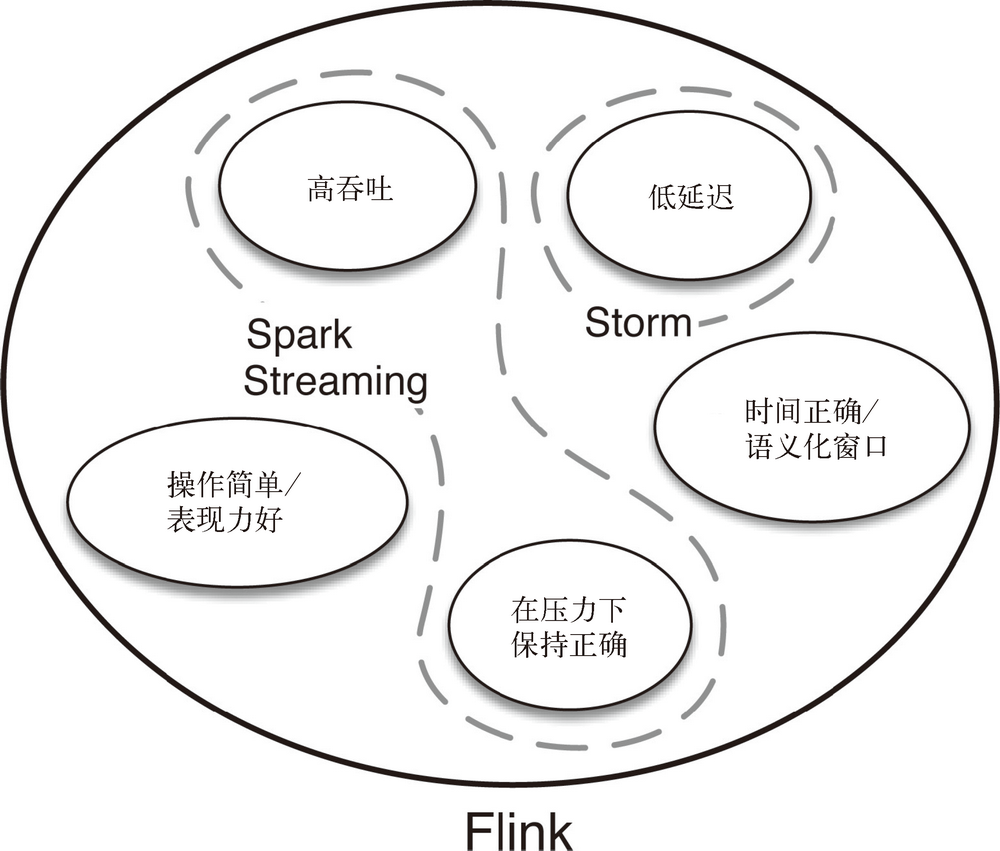
图 1:Flink 的一个优势是,它拥有诸多重要的流式计算功能。其他项目为了实现这些功能,都不得不付出代价。比如,Storm 实现了低延迟,但是在作者撰写本书时还做不到高吞吐,也不能在故障发生时准确地处理计算状态;Spark Streaming 通过采用微批处理方法实现了高吞吐和容错性,但是牺牲了低延迟和实时处理能力,也不能使窗口与自然时间相匹配,并且表现力欠佳
与 Storm 和 Spark Streaming 类似,其他流处理技术同样可以提供一些有用的功能,但是没有一个像 Flink 那样功能如此齐全。举例来说,Apache Samza(以下简称 Samza)是早期的一个开源流处理器,它不仅没能实现 exactly-once 语义,而且只能提供底层的 API;同样,Apache Apex 提供了与 Flink 相同的一些功能,但不全面(比如只提供底层的 API,不支持事件时间,也不支持批量计算)。这些项目没有一个能和 Flink 在开源社区的规模上相提并论。
下面来了解 Flink 是什么,以及它是如何诞生的。
图书简介:https://www.ituring.com.cn/book/2036


分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论