

本文要点
现代社会开始流行用代码的形式记录和表达传统文化,为此我们需要思考如何在软件中真实地表达来自不同领域的理论和见解。
音乐是很适合用编程技术探索的领域,因为它有很长的符号历史,并具备基于模式的规范体系。
几个世纪以来,音乐理论家一直在努力探索音乐的正确性法则。现在我们得以使用编程语言作曲,进而就有机会探寻音乐与编程语言之间的共性,并利用这些共性创作优美的旋律和优秀的软件。
在本文中,Chris 探讨了如何使用 Mezzo Haskell 库和 Idris 语言的依赖类型来对音乐做类型检查。
引言
我曾在之前做过的许多演讲中探讨用编程语言来作曲这个话题。这个主题很受欢迎,因为它将工程师对机械原理的好奇心与音乐世界的内在规律联系在了一起。
怎样用代码作曲呢?现在很多编程语言都有自己的编程作曲环境。其中比较流行的两种方案分别是使用 Haskell 语言的TidalCycles,和用在树莓派设备上,基于 Ruby 语言的Sonic Pi。下面这个例子则使用了我开发的莱比锡作曲库。因为它是用 Clojure 编写的,所以没有类型检查。
这里旋律时长用整数表示,音调则用比率数字表示,这可能有点麻烦。对乐曲作变换时编程方法真的很好用,比如上面这段代码就给原始旋律加上了伴奏,音高定到 C 大调上,节奏则指定为每分钟 90 拍。
一般来说,程序员看到作曲代码后最常见的一种反应就是思考能否使用类型系统来避免难听的旋律。会有这种想法是很自然的。如果音乐可以被视为代码,那么难听的旋律可以被视为某种编程错误吗?如果答案是肯定的,那么也许我们就能用编写程序时用到的技术来改进我们的作曲软件了。
值得一提的是,类型系统所预防的错误类型与常见的旋律错误之间有着明显的相似之处。如果我的编程语言能发现我没有将 String 传递给需要 Integer 的函数,那么它也应该能够查出我在C大调的谱子里写了一个 F#,但 C 大调的谱子本来不应该有升调(#)或降调(♭)的。
在本文中,我将讨论怎样的音乐才是“正确的”音乐,以及我们如何使用类型系统写出正确的音乐代码。
规范主义
几个世纪以来,音乐理论家一直沉迷于探索音乐的正确性机制。大多数情况下他们是基于音乐规范主义的框架来做判断的,换句话说就是评估音乐是否符合一系列规则。
一直以来,人们通过以下步骤来生成这些规则
研究经典
提取规律
将这些规律制定为规则体系
然后我们就可以作出以下声明:
偏离这些规则的音乐是不正确的。
例如,有一条作曲规则是说一段旋律是不能从 C 调直接上跳大七度跳到 B 调上的。这种方法产生了很多有价值的见解。古典音乐中有一系列有趣的规律,而将我们观察到的规律总结为规则体系后,我们就能更好地讨论音乐艺术了。
更重要的是,学生们学习艺术时有章可循是很好的事情。当孩子们学习小提琴练习 C 大调时,每当他们拉出 F#,老师就会指出他们的错误。区分音乐正确与错误的理念肯定有着自己的用武之地。
然而,这种定义音乐正确性的方式存在两大缺陷。
首先,生成规则的过程在很大程度上依赖理论家眼中的经典音乐。带有偏见的数据集会导致带有偏见的推论,而西方古典音乐并不能代表人类的全部音乐体验。根据巴赫和莫扎特的音乐总结出的规则可能很有吸引力,但它并不能向你展示音乐的全貌。
而且你会意识到音乐类型通常与特定的文化和种族密切相关,这样问题就更大了;拔高某种类型音乐的地位,其实也是在无意中拔高某类人群。尤其是现代学术音乐理论主要基于对欧洲经典传统的研究发展而来,很少关注来自非洲侨民的音乐,如蓝调、爵士乐、摇滚乐和嘻哈音乐等。依靠传统音乐理论作为正确性的基准可能会带来很多问题,就像面部识别算法更容易识别白人,更难认出黑人一样。
从现有规则中提取和推广规律来构建规则体系的做法还有另一大缺点,那就是它总在向后看。往往是冲破规则桎梏的音乐才令人心动不已。例如在Jimmy Page将失真当作一种艺术效果来使用之前,工程师一直认为在放大过程中的信号削波是一种缺陷。因此,即使我们可以用总结到的规律理解已有的音乐,也不应该用它们来批判和约束新的乐曲。
一个优秀的音乐类型系统必须避开规范主义的两大陷阱。它不能建立在对音乐的错误偏见之上。这种系统应该平等地对待所有国家和文化,不能成为音乐创新发展道路上的绊脚石。
描述主义
替代规范主义的一种方案是描述主义。规范主义将音乐规律视为不可违背的准则,而描述主义将它们视为从实践中诞生的模式。描述主义总结音乐规则的步骤大约是:
检查一段音乐
提取乐曲中的倾向
将它们总结为一种模式
然后我们就可以作出如下声明:
偏离这个模式的音乐是不常见的。
要做到这一点,我们需要一个良好的音乐结构模型,可以用它区分常见/不常见的类型,而不仅是区分对错。David Huron 在他的著作“Sweet Anticipation”中给出了一种行之有效的方法。Huron 提出了一套描述主义理论,这里为了便于说明将其概括为三大主张:
人们是通过统计学习来欣赏音乐的。
预测正确会让你很满足。
出人意料的旋律不会让你感到无聊。
上面介绍规范主义时提到了一个例子,那就是从 C 调跳到 B 调被认为是错误的;但在 Huron 的理论中,这种谱子被看作是“非常罕见”的。听过很多西方音乐的人会知道,当他们听到一个 C 调的音符时,下一个音符最有可能是另一个 C 调,只是升一度或者降一度而已。一下跳到较高的 B 调会让听众感到惊讶,他们可能会感觉这很难听。
Huron 的理论还有一个引人深思的推论,那就是音乐创作既不是最大限度的练习,也不是最小限度的发明。相反,音乐是在秩序和混乱之间的边界上跳舞,听众的感受则取决于音乐家在创新乐符带来的震撼与传统技法带来的满足感之间取得平衡的能力。如果你想作出一段“正确”的乐曲,那么既不能让这段音乐太偏离常规,也不能写得太平淡无奇。
下表是对旋律倾向的统计分析。较暗的方块代表更多的使用几率。读表时,先在垂直轴上选择一个音符,然后从水平轴上查看下一个更有可能是哪个音符。例如该数据集显示,“Re”音符后面跟着“Do”的几率有 33.53%。
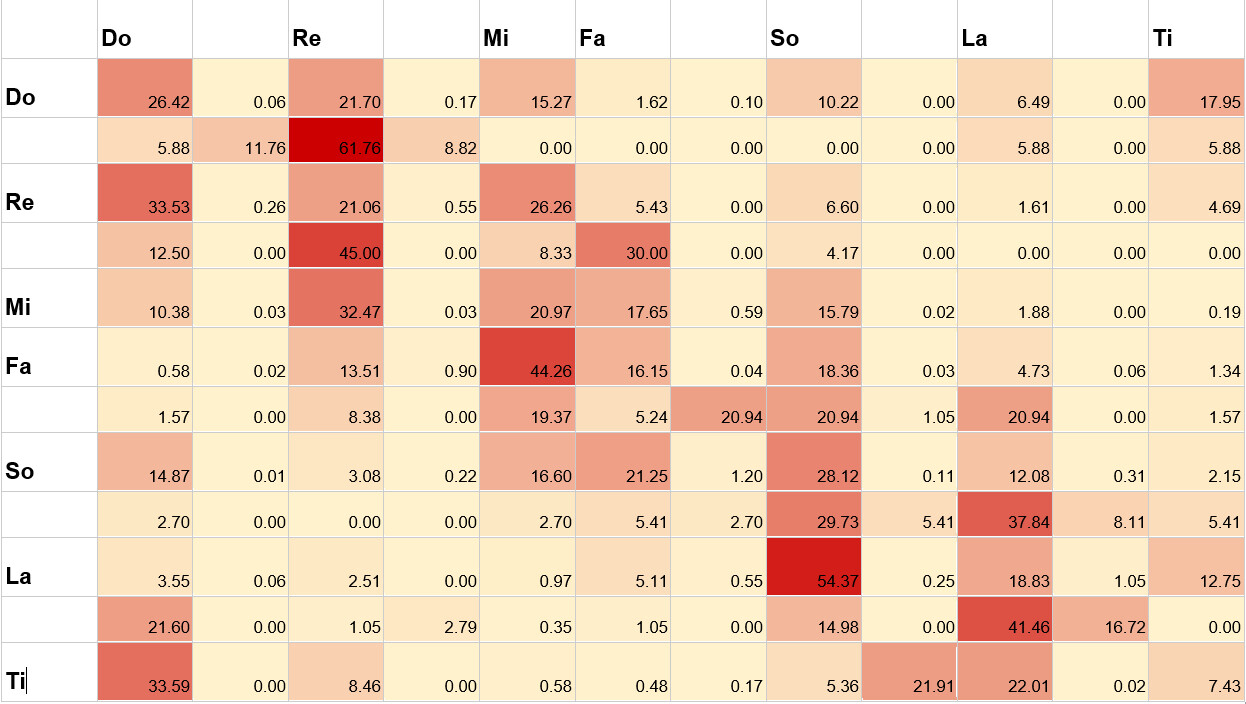
这些数据是根据 Huron 著作中的数据改编而来的,数据来源是对在主大调上的德国民歌中超过 250,000 个音符对所做的分析。其他类型的音乐库(例如嘻哈音乐或摇滚乐)将产生不同的概率分布。
这些概率可以等效地表示为信息熵,50%的概率对应于一位熵,25%的概率对应于两位,等等。为了避免公式被零除,我计算了数据集中没出现过的组合在实践中出现的几率,结果是十万分之一。在下图中,较暗的正方形表示更高的熵成本,或者换句话说是不太常见的组合。例如,“Re”后跟“La”对应于大约 6 位的熵,或者说 1/64 的概率。
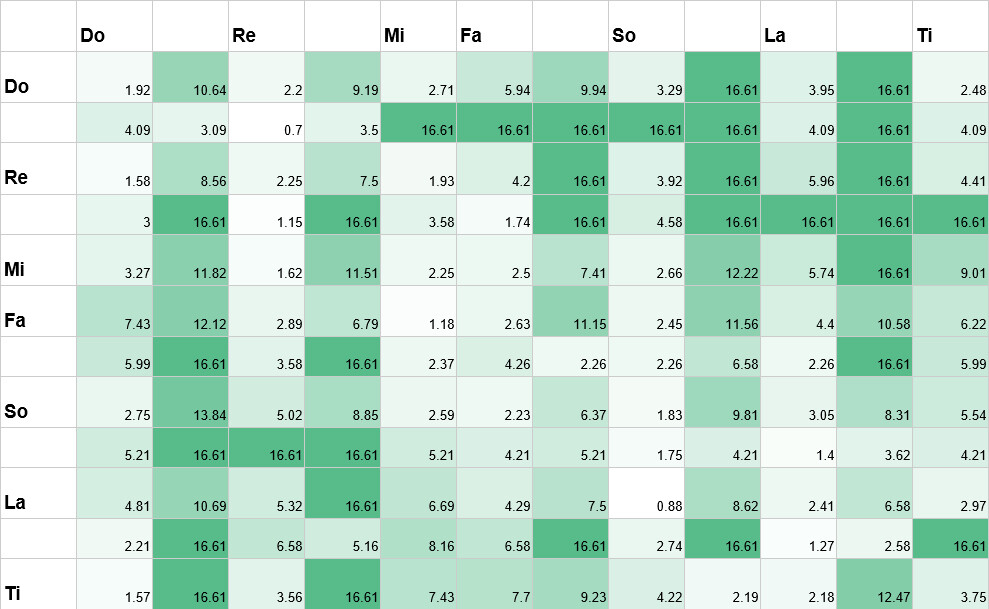
改用熵表示法后,我们就可以自然地将一系列音符给人的惊喜程度加在一起了;从一个音调转到下一个音调的转换用熵来计数,整段旋律的惊喜程度就是所有转换的熵数之和。
这种方法非常像隐藏的马尔可夫模型,但这里不是要生成音符串,而是使用加权概率来测量给定旋律发生的可能性。
你可能会注意到从“Do”到“Ti”的转换熵仅为 2.48 位,可我们之前说从 C 调到 B 调的跳跃是非常不寻常的,好像出现了矛盾——不常见的转换通常会有大约 10 位的熵。之所以会有这种差异,是因为 Huron 的数据并没有区分从“Do”向上跳六度到“Ti”(非常罕见),和从“Do”降一度到较低的“Ti”(非常常见)两种情况。如果我们的数据使我们能区分这两种情况的话,那么我们的模型就能知道“Do”,“Ti”,“Mi”,“Fa”与相当常见的“Do”,“Re”,“Mi”相比要稀奇得多。
类型化的音符
理想情况下,类型系统能够指导程序员实现有效的编码决策,并消除潜在的错误。在音乐领域,类似的典型例子就是唱名法(solfège)。即使你从未接受过正规的音乐教育,你也可能听过音乐剧“音乐之声”,听过剧中的歌曲“Do-Re-Mi”。八度音阶中的每个音符都有自己的名称,其他音符则都没有命名:
Do(一组音阶中最低的音)
Re
Mi
Fa
So
La
Ti
Do(这个 Do 比上一个高了八度)
这个系统定义了一套迷你语言,引导音乐家使用正确的音符;在这种迷你语言的限制下,其他音符就没法表示出来了。“Do”和“Re”之间有无限多的频率,但在唱名法中它们是难以形容的。
在代码中可以很容易地将其表示为代数数据类型:
这样我们就能给音乐函数作出定义,禁止使用非标准音符;例如下面的代码会重复相同音符 n 次:
按照此定义,repeat 3 Re 的表达式在音乐层面很容易理解,而 repeat 3 F#就是一个类型检查错误,因为 F#不是 Solfege 类型的值。
这样我们就有一定程度的类型安全性了。我们的类型系统可以帮助我们避免无效音符,但它仍然无法让我们免受无效音符组合的影响。如果我们正在 C 大调上作曲,肯定是不会弹 F#的,但是我们可能会弹一个 C 然后跳大七度接一个 B,这是(传统的)组合规则所禁止的。这种上下文类型检查是可行的,但需要更复杂的方法。
类型转换
Mezzo是 Dima Samoz 写的 Haskell 库,它使用依赖类型来检查音乐的正确性。Mezzo 的自述文档将其描述为“非常严格的音乐拼写检查器”,它不仅能检查简单的音符安全性,还能基于各种作曲规则做检查。在 Mezzo 中下面的代码能正常编译,因为旋律 C,D,E,F 是由合法的间隔连接起来的:
但当我们违反规则从 C 跳到 B 时,Mezzo 就会介入。以下代码无法通过编译:
Mezzo 甚至能指出代码中存在的问题,令人印象深刻:
看起来我们将不正确的音乐转化为类型错误的理想已经变为现实了,但它仍然会偶尔出现问题。当 Samoz 将肖邦的前奏曲编入 Mezzo 时,他发现有时候作曲家没有遵循传统的规则:
“这件作品几乎可以全部转译成功——但还是有些音符不能写进代码,因为它们会迈入 Mezzo 定义的禁区。”
有人可能会问是谁在这里划分禁区呢。如果肖邦都没资格决定西方古典音乐中哪些音乐规则才是正确的,那么谁还能有决定权呢?
这里的问题是,即使 Mezzo 能够考虑上下文,类型判断仍然是二元选择。这些音符要么都是正确的,然后作品编译成功;要么某一个音符不通过,则该作品无法通过编译。因此,虽然 Mezzo 可以控制哪些组合规则生效,但是生效的规则必须是全局应用的。如果你为了让某些特例通过编译而关闭某项规则,那么乐曲的其他部分也就不能用这项规则来检查了。
类型化的熵
为了将乐曲对规则的破坏或扭曲纳入类型模型,一种方法就是按照 Huron 的理论,用概率建模来表示音符之间的变化关系。不是简单粗暴地允许或阻止某种转换,而是给予这种组合一个熵分值,用熵分值表示这对音符给听众带来的惊喜程度。
以下代码是使用依赖类型的函数编程语言Idris编写的。它检查了一段名为 conventional 的旋律,以“Do”开头并以“So”结束,计算出这些音符之间的路径产生 8 到 16 位的熵分值。首先我们需要定义一个 Melody 类型,它根据我们的乐谱计算出一定的概率或熵。这种类型有三个构造函数:
Pure,表示只有单个音符的旋律,其熵的上下边界为零。
(>> =),作出两段旋律,将第一段旋律结尾音符到第二段旋律开头音符的转换成本加到熵边界值上。
Relax,选取一段旋律并加大其熵边界。
这种类型定义有点复杂,但有了它之后我们就可以使用 Idris 的 do 记号来对旋律排序,而 Idris 编译器将跟踪我们的熵边界。下面是一段较传统的旋律,所有转换的成本都很低:
下一首旋律不太常见,因为它有大七度的跳跃,在 Mezzo 中要么禁止这种行为,要么完全关闭规则。但现在我们只是扩展旋律的复杂性边界,使其具有 8 到 24 位的熵:
这段旋律按 Melody (Do,So) (8,24) 的设置才能通过编译,因为它很少见,用 Melody (Do,So) (8,16) 的设置是不会通过编译的!
这种方法的新颖之处在于它还能找出太过无聊的旋律。如果旋律的熵满足不了下限也会产生类型错误。因此,如果传统的旋律被赋予类型 Melody (Do,So) (16,24) 也不会通过编译,因为该旋律的熵低于下限。这样我们就能遵循 Huron 发现的规律来作曲了——听众不愿意听到过于令人惊讶或太平淡无奇的音乐。
这种方法有一个极端情况,音符向限界内其他音符的转换被赋予零熵值,向限界之外的音符的转换则被赋予极大的熵值。这样一来我们就得到了一种二元类型判断方法,音符要么是有效的要么是无效的,没有灰色区域。
重要但很难检查
用类型检查音乐是很困难的,因为我们很难定义音乐的正确性。如果我们无法精确地用数学形式表达音乐的正确性概念就无法将其编码为类型系统。即使我们能准确地将我们的理解形式化为具体的模型,它也需要与强大的类型系统相结合才能让编译器为我们的曲谱作出合理的评判。不过虽然事事艰难,但通过一些努力和一些简化的假设也可能达成这个目标。
这项工作仅仅是好奇心使然吗?或许是吧。音乐产业不太可能那么快就引入类型系统来检查作曲错误。但是如果在探索音乐的计算化理念的过程中,我们能通过一种新的方式来欣赏在所有人的生活中都意义重大的事物,那么这本身就证明了这项工作的合理性。
也许同样重要的是,正确性概念既重要又难以定义的领域有很多,音乐只是其中之一。在社会与文化领域,编程技术与传统事物结合的案例越来越多,这种正确答案难以断言,但对人类来说判断正误又至关重要的情况也会频繁出现。我们可能会用计算机程序来决定将一个人关押多久。判决的正确性涉及成本和概率的复杂权衡,如果我们没有系统的推理手段,如何能知道计算结果是公正的?
一旦要将模糊的推理过程交给计算机完成,我们就需要问自己如何知道这个系统就是正确的?
作者介绍
Chris Ford开始用代码创作音乐是为了弥补他糟糕的钢琴技术。直到后来他才意识到编程技术能帮助人们深入洞察音乐结构。在过去的几年里,克里斯曾多次向程序员介绍音乐理论,涵盖欧洲古典音乐、复杂性理论、爵士乐、中非多音节奏和调音系统等主题。他是ThoughtWorks Spain的技术主管,在巴塞罗那生活和工作。
原文链接:
It Ain’t Necessarily So: Exploring Type Systems for Verifying Musical Correctness

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论