
一、什么是定时器
定时器(Timer)是一种在指定时间开始执行某一任务的工具(也有周期性反复执行某一任务的 Timer,我们这里暂不讨论)。它常常与延迟队列这一概念关联。那么在什么场景下我才需要使用定时器呢?
我们先看看以下业务场景:
当订单一直处于未支付状态时,如何及时的关闭订单,并退还库存?
如何定期检查处于退款状态的订单是否已经退款成功?
新创建店铺,N 天内没有上传商品,系统如何知道该信息,并发送激活短信?
为了解决以上问题,最简单直接的办法就是定时去扫表。每个业务都要维护一个自己的扫表逻辑。当业务越来越多时,我们会发现扫表部分的逻辑会非常类似。我们可以考虑将这部分逻辑从具体的业务逻辑里面抽出来,变成一个公共的部分。这个时候定时器就出场了。
二、定时器的本质
一个定时器本质上是这样的一个数据结构:deadline 越近的任务拥有越高优先级,提供以下几种基本操作:
1. Add 新增任务
2. Delete 删除任务
3. Run 执行到期的任务/到期通知对应业务处理
4. Update 更新到期时间 (可选)
Run 通常有两种工作方式:1.轮询,每隔一个时间片就去查找哪些任务已经到期;2.睡眠/唤醒,不停地查找 deadline 最近的任务,如到期则执行;否则 sleep 直到其到期。在 sleep 期间,如果有任务被 Add 或 Delete,则 deadline 最近的任务有可能改变,线程会被唤醒并重新进行 1 的逻辑。
它的设计目标通常包含以下几点要求:
1. 支持任务提交(消息发布)、任务删除、任务通知(消息订阅)等基本功能。
2. 消息传输可靠性:消息进入延迟队列以后,保证至少被消费一次(到期通知保证 At-least-once ,追求 Exactly-once)。
3. 数据可靠性:数据需要持久化,防止丢失。
4. 高可用性:至少得支持多实例部署。挂掉一个实例后,还有后备实例继续提供服务,可横向扩展。
5. 实时性:尽最大努力准时交付信息,允许存在一定的时间误差,误差范围可控。
三、数据结构
下面我们谈谈定时器的数据结构。定时器通常与延迟队列密不可分,延时队列是什么?顾名思义它是一种带有延迟功能的消息队列。而延迟队列底层通常可以采用以下几种数据结构之一来实现:
1. 有序链表,这个最直观,最好理解。
2. 堆,应用实例如 Java JDK 中的 DelayQueue、Go 内置的定时器等。
3. 时间轮/多级时间轮,应用实例如 Linux 内核定时器、Netty 工具类 HashedWheelTimer、Kafka 内部定时器等。
这里重点介绍一下时间轮(TimeWheel)。一个时间轮是一个环形结构,可以想象成时钟,分为很多格子,一个格子代表一段时间(越短 Timer 精度越高),并用一个 List 保存在该格子上到期的所有任务,同时一个指针随着时间流逝一格一格转动,并执行对应 List 中所有到期的任务。任务通过取模决定应该放入哪个格子。示意图如下所示:
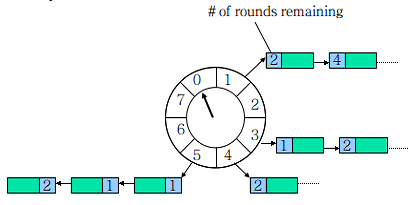
时间轮
如果任务的时间跨度很大,数量也多,传统的单轮时间轮会造成任务的 round 很大,单个格子的任务 List 很长,并会维持很长一段时间。这时可将 Wheel 按时间粒度分级(与水表的思想很像),示意图如下所示:
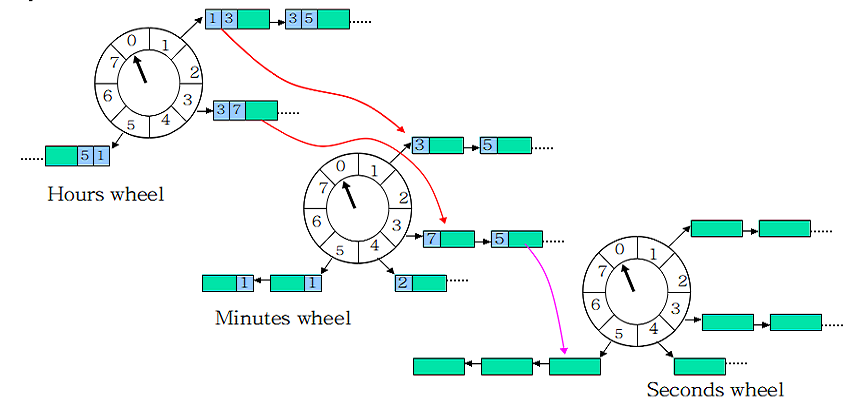
多级时间轮
时间轮是一种比较优雅的实现方式,且如果采用多级时间轮时其效率也是比较高的。
四、业界实现方案
业界对于定时器/延时队列的工程实践,则通常基于以下几种方案来实现:
1. 基于 Redis ZSet 实现。
2. 采用某些自带延时选项的队列实现,如 RabbitMQ、Beanstalkd、腾讯 TDMQ 等。
3. 基于 Timing-Wheel 时间轮算法实现。
五、方案详述
介绍完定时器的背景知识,接下来看下我们系统的实现。我们先看一下需求背景。在我们组的实际业务中,有延迟任务的需求。一种典型的应用场景是:商户发起扣费请求后,立刻为用户下发扣费前通知,24 小时后完成扣费;或者发券给用户,3 天后通知用户券过期。基于这种需求背景,我们引出了定时器的开发需求。
我们首先调研了公司内外的定时器实现,避免重复造轮子。调研了诸如例如公司外部的 Quartz、有赞的延时队列等,以及公司内部的 PCG tikker、TDMQ 等,以及微信支付内部包括营销、代扣、支付分等团队的一些实现方案。最后从可用性、可靠性、易用性、时效性以及代码风格、运维代价等角度考虑,我们决定参考前人的一些优秀的技术方案,并根据我们团队的技术积累和组件情况,设计和实现一套定时器方案。
首先要确定定时器的存储数据结构。这里借鉴了时间轮的思想,基于微信团队最常用的存储组件 tablekv 进行任务的持久化存储。使用到 tablekv 的原因是它天然支持按 uin 分表,分表数可以做到千万级别以上;其次其单表支持的记录数非常高,读写效率也很高,还可以如 mysql 一样按指定的条件筛选任务。
我们的目标是实现秒级时间戳精度,任务到期只需要单次通知业务方。故我们方案主要的思路是基于 tablekv 按任务执行时间分表,也就是使用使用方指定的 start_time(时间戳)作为分表的 uin,也即是时间轮 bucket。为什么不使用多轮时间轮?主要是因为首先 kv 支持单表上亿数据, 其二 kv 分表数可以非常多,例如我们使用 1000 万个分表需要约 115 天的间隔才会被哈希分配到同一分表内。故暂时不需要使用到多轮时间轮。
最终我们采用的分表数为 1000w,uin=时间戳 mod 分表数。这里有一个注意点,通过 mod 分表数进行 Key 收敛, 是为了避免时间戳递增导致的 key 无限扩张的问题。示例图如下所示:
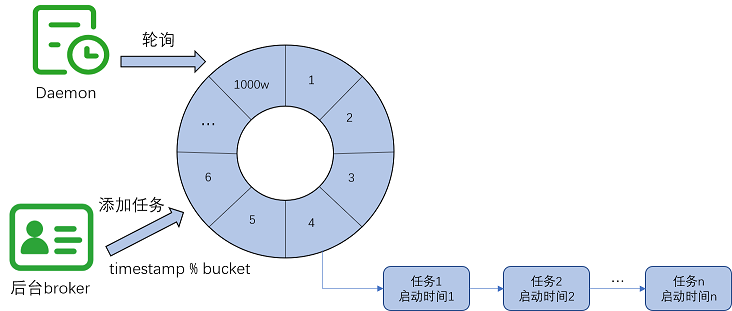
kv 时间轮
任务持久化存储之后,我们采用一个 Daemon 程序执行定期扫表任务,将到期的任务取出,最后将请求中带的业务信息(biz_data 添加任务时带来,定时器透传,不关注其具体内容)回调通知业务方。这么一看流程还是很简单的。
这里扫描的流程类似上面讲的时间轮算法,会有一个指针(我们在这里不妨称之为 time_pointer)不断向后移动,保证不会漏掉任何一个 bucket 的任务。这里我们采用的是 commkv(可以简单理解为可以按照 key-value 形式读写的 kv,其底层仍是基于 tablekv 实现)存储 CurrentTime,也就是当前处理到的时间戳。每次轮询时 Daemon 都会通过 GetByKey 接口获取到 CurrentTime,若大于当前机器时间,则 sleep 一段时间。若小于等于当前机器时间,则取出 tablekv 中以 CurrentTime 为 uin 的分表的 TaskList 进行处理。本次轮询结束,则 CurrentTime 加一,再通过 SetByKey 设置回 commkv。这个部分的工作模式我们可以简称为 Scheduler。
Scheduler 拿到任务后只需要回调通知业务方即可。如果采用同步通知业务方的方式,由于业务方的超时情况是不可控的,则一个任务的投递时间可能会较长,导致拖慢这个时间点的任务整体通知进度。故而这里自然而然想到采用异步解耦的方式。即将任务发布至事件中心(微信内部的高可用、高可靠的消息平台,支持事务和非事务消息。由于一个任务的投递到事件中心的时间仅为几十 ms,理论上任务量级不大时 1s 内都可以处理完。此时 time_pointer 会紧跟当前时间戳。当大量任务需要处理时,需要采用多线程/多协程的方式并发处理,保证任务的准时交付。broker 订阅事件中心的消息,接受到消息后由 broker 回调通知业务方,故 broker 也充当了 Notifier 的角色。整体架构图如下所示:
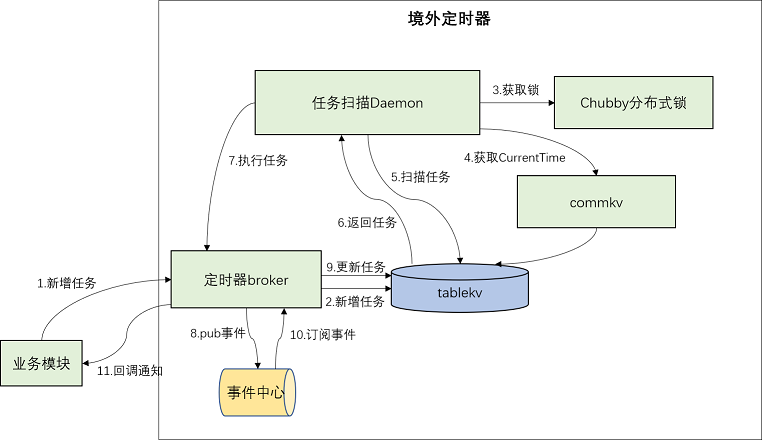
架构图
主要模块包括:
任务扫描 Daemon:充当 Scheduler 的角色。扫描所有到期任务,投递到事件中心,让它通知 broker,由 broker 的 Notifier 通知业务方。
定时器 broker:集业务接入、Notifier 两者功能于一身。
任务状态图如下所示,只有两种状态。当任务插入 kv 成功时即为 pending 状态,当任务成功被取出并通知业务方成功时即为 finish 状态。
状态图
六、实现细节与难点思考
下面就上面的方案涉及的几个技术细节进行进一步的解释。
1. 业务隔离
通过 biz_type 定义不同的业务类型,不同的 biz_type 可以定义不同的优先级(目前暂未支持),任务中保存 biz_type 信息。
业务信息(主键为 biz_type)采用境外配置中心进行配置管理。方便新业务的接入和配置变更。业务接入时,需要在配置中添加诸如回调通知信息、回调重试次数限制、回调限频等参数。业务隔离的目的在于使各个接入业务不受其他业务的影响,这一点由于目前我们的定时器用于支持本团队内部业务的特点,仅采取对不同的业务执行不同业务限频规则的策略,并未做太多优化工作,就不详述了。
2. 时间轮空转问题
由于 1000w 分表,肯定是大部分 Bucket 为空,时间轮的指针推进存在低效问题。联想到在饭店排号时,常有店员来登记现场尚存的号码,就是因为可以跳过一些号码,加快叫号进度。同理,为了减少这种“空推进”,Kafka 引入了 DelayQueue,以 bucket 为单位入队,每当有 bucket 到期,即 queue.poll 能拿到结果时,才进行时间的“推进”,减少了线程空转的开销。在这里类似的,我们也可以做一个优化,维护一个有序队列,保存表不为空的时间戳。大家可以思考一下如何实现,具体方案不再详述。
3. 限频
由于定时器需要写 kv,还需要回调通知业务方。因此需要考虑对调用下游服务做限频,保证下游服务不会雪崩。这是一个分布式限频的问题。这里使用到的是微信支付的限频组件。保证 1.任务插入时不超过定时器管理员配置的频率。2.Notifier 回调通知业务方时不超过业务方申请接入时配置的频率。这里保证了 1.kv 和事件中心不会压力太大。2.下游业务方不会受到超过其处理能力的请求量的冲击。
4. 分布式单实例容灾
出于容灾的目的,我们希望 Daemon 具有容灾能力。换言之若有 Daemon 实例异常挂起或退出,其他机器的实例进程可以继续执行任务。但同时我们又希望同一时刻只需要一个实例运行,即“分布式单实例”。所以我们完整的需求可以归纳为“分布式单实例容灾部署”。
实现这一目标,方式有很多种,例如:
接入“调度中心”,由调度中心来负责调度各个机器;
各节点在执行任务前先分布式抢锁,只有成功占用锁资源的节点才能执行任务;
各节点通过通信选出“master"来执行逻辑,并通过心跳包持续通信,若“master”掉线,则备机取代成为 master 继续执行。
主要从开发成本,运维支撑两方面来考虑,选取了基于 chubby 分布式锁的方案来实现单实例容灾部署。这也使得我们真正执行业务逻辑的机器具有随机性。
5. 可靠交付
这是一个核心问题,如何保证任务的通知满足 At-least-once 的要求?
我们系统主要通过以下两种方式来保证。
1.任务达到时即存入 tablekv 持久化存储,任务成功通知业务方才设置过期(保留一段时间后删除),故而所有任务都是落地数据,保证事后可以对账。
2.引入可靠事件中心。在这里使用的是事件中心的普通消息,而非事务消息。实质是当做一个高可用性的消息队列。
这里引入消息队列的意义在于:
将任务调度和任务执行解耦(调度服务并不需要关心任务执行结果)。
异步化,保证调度服务的高效执行,调度服务的执行是以 ms 为单位。
借助消息队列实现任务的可靠消费。
事件中心相比普通的消息队列还具有哪些优点呢?
某些消息队列可能丢消息(由其实现机制决定),而事件中心本身底层的分布式架构,使得事件中心保证极高的可用性和可靠性,基本可以忽略丢消息的情况。
事件中心支持按照配置的不同事件梯度进行多次重试(回调时间可以配置)。
事件中心可以根据自定义业务 ID 进行消息去重。
事件中心的引入,基本保证了任务从 Scheduler 到 Notifier 的可靠性。
当然,最为完备的方式,是增加另一个异步 Daemon 作为兜底策略,扫出所有超时还未交付的任务进行投递。这里思路较为简单,不再详述。
6. 及时交付
若同一时间点有大量任务需要处理,如果采用串行发布至事件中心,则仍可能导致任务的回调通知不及时。这里自然而然想到采用多线程/多协程的方式并发处理。在本系统中,我们使用到了微信的 BatchTask 库,BatchTask 是这样一个库,它把每一个需要并发执行的 RPC 任务封装成一个函数闭包(返回值+执行函数+参数),然后调度协程(BatchTask 的底层协程为 libco)去执行这些任务。对于已有的同步函数,可以很方便的通过 BatchTask 的 Api 去实现任务的批量执行。Daemon 将发布事件的任务提交到 BatchTask 创建的线程池+协程池(线程和协程数可以根据参数调整)中,充分利用流水线和并发,可以将任务 List 处理的整体时延大大缩短,尽最大努力及时通知业务方。
7. 任务过期删除
从节省存储资源考虑,任务通知业务成功后应当删除。但删除应该是一个异步的过程,因为还需要保留一段时间方便查询日志等。这种情况,通常的实现方式是启动一个 Daemon 异步删除已完成的任务。我们系统中,是利用了 tablekv 的自动删除机制,回调通知业务完成后,除了设置任务状态为完成外,同时通过 tablekv 的 update 接口设置 kv 的过期时间为 1 个月,避免了异步 Daemon 扫表删除任务,简化了实现。
8. 其他风险项
1.由于 time_pointer 的 CurrentTime 初始值置为首次运行的 Daemon 实例的机器时间,而每次轮询时都会对比当前 Daemon 实例的机器时间与 CurrentTime 的差别,故机器时间出错可能会影响任务的正常调度。这里考虑到现网机器均有时间校正脚本在跑,这个问题基本可以忽略。
2.本系统的架构对事件中心构成了强依赖。定时器的可用性和可靠性依赖于事件中心的可用性和可靠性。虽然目前事件中心的可用性和可靠性都非常高,但如果要考虑所有异常情况,则事件中心的短暂不可用、或者对于订阅者消息出队的延迟和堆积,都是需要正视的问题。一个解决方案是使用 MQ 做双链路的消息投递,解决对于事件中心单点依赖的问题。
结语
这里的定时器服务目前仅用于支持境外的定时器需求,调用量级尚不大,已可满足业务基本要求。如果要支撑更高的任务量级,还需要做更多的思考和优化。随时欢迎大家和我交流探讨。
最后打个广告,境外支付团队在不断追求卓越的路上寻找同路人,欢迎加入我们的团队(点击下方链接加入~)




