
云集的全链路压测之路走的还是比较艰辛的,从最初纠结用什么压测工具开始,到压框架、压单接口、压线下环境等一步步摸索,并借鉴其它友商的经验和方案,直至今天,我们才最终在黑暗中摸索出了一条属于云集人自己的全链路压测之路。2017 年的双 12 前夕,整个研发、运维团队处于紧急战备状态,从 10 月份开始,我们利用自研的军演系统 TITAN 总共发起了超过 5 次线上全链路压测,除探测出业务系统的真实容量水位外,还挖掘出业务系统的性能瓶颈近 30 处,成功做到了有指导的在大促前进行容量规划和性能优化,让系统坚如磐石,我们确实就是在不停的试错过程中逐步成长和成熟起来的。
为什么要在线上实施全链路压测
流量不大的时候,开发人员、测试人员随便在线下环境做一把功能测试,只要功能能够正常跑通就行了,但随着用户规模的线性上升,流量会越来越大 (目前我们日均亿级流量、峰值交易额突破 9 位数),我们开始逐渐意识到,光靠常规的功能测试似乎已经不够了,流量上来了,必须重视系统性能了,毕竟谁也不希望自己的系统被流量无情击垮。因此到了这个阶段,大多数企业都会选择在线下对业务系统、中间件、存储层实施压测,明确其吞吐量,但是这样的压测结果数据,离线上还是有较大差距,毕竟绝大多数企业的压测环境并不会与生产环境机器数量 1:1,所以压测环境的压测结果数据基本上仅供参考,并不能够作为线上环境的指导数据,只有直接在线上环境实施压测才是唯一的明道。
直接在线上环境实施压测是一件非常危险的事情,决不能够出现一丝失误。大多数情况下,我们的业务系统都是有用户在正常进行访问的,尤其是峰值流量时绝不能因为压测流量导致系统故障从而影响用户下单,甚至更不能够污染线上数据。试想一下,用户 A 的订单信息中,突然多出来 10 台 IphoneX,你是送还是不送?或者余额突然变少了,都是用户绝对不能够容忍的,并且线上环境往往还会伴随着各种定时任务,统计的时候如果把压测数据也计算进收益中,运营部门的老大估计会请研发同学喝茶。
尽管困难重重,但是要探测出系统的真实容量水位,以及给出合理的限流水位,只有此路通罗马。因此系统需要能够智能化到准确无误的区分哪些数据是真实用户流量,哪些是压测流量,然后将压测流量引流到隔离环境中落盘,后面我会讲到如何区分压测流量。说了这么多,究竟什么是全链路压测呢?简单来说,所谓全链路压测指的其实就是对系统的所有核心链路同时施压,当系统整站流量都被打上来的时候,必定会暴露出性能瓶颈,才能够探测出系统整体的真实容量水位,有指导的在大促前进行容量规划和性能优化,这就是线上实施全链路压测的意义。
业务系统如何区分压测流量
在说道如何区分压测流量之前,我们首先来谈论一个研发同学比较敏感的话题,业务系统是否需要有侵入性的进行改造,明确告诉大家,一定程度上会。因为线上全链路压测任务并不会在业务初期就进行,基本上都是在业务中后期才会实施,尤其是当业务越来越复杂的时候,改造的难度和成本就会越大。但是企业的基础架构团队应该意识到,绝大多数的改造工作都应该是在中间件、组件中完成,应该尽可能的为研发同学提供便捷,让其更专注于业务逻辑本身,当然如果完全对业务没有侵入,这几乎是不现实的。
线上实施全链路压测的重点和难点是:
- 区分压测流量数据;
- 压测流量数据应该落盘到隔离环境中。
最初我们只敢拿线上环境的读接口小试牛刀,并不敢一开始就实施读 / 写并行压测,说到底还是因为心里没底,但当明确如何区分压测流量和隔离压测流量数据后,我们便有信心在线上环境大胆的实施全链路压测。
先来说说如何区分压测流量:
- 压测流量会统一在 URL 上打标;
- 接入层接受到请求后,由 Filter 拦截并识别压测标识,放进 ThreadLocal;
- 接入层调用服务时,调用链埋点端从 ThreadLocal 中获取压测标识,并向当前上下文中进行传递;
- 落盘或存储时依靠中间件、组件从服务上下文中获取出压测标识区分数据走向。
- 有些业务是需要调用外部第三方接口的,比如用户下单时会调用支付接口,这种情况下,需要判断如果是打标流量就直接走 Mock 服务。
线上全链路压测的总体设计
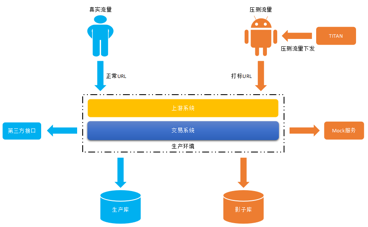
当明确如何区分真实用户流量和压测流量后,接下来需要思考的问题就是如何将压测数据安全的引流到隔离环境中,最终我们选择了从物理隔离和逻辑隔离 2 个维度来落盘和存储压测数据。
物理隔离压测流量数据:
对于那些真正需要落盘的数据 (比如:买 / 卖家订单数据),我们会将压测数据写入到影子库中,与生产库完全隔离,这是最安全的,虽然成本相对较高 (有些友商选择落盘到影子表中,但因为数据库实例是同一个,必然会影响生产库的连接数),但为了安全起见还是非常有必要的,这就是物理隔离。
逻辑隔离压测流量数据:
而对于一些中间数据,比如需要写入到 RocketMQ、Redis 等的压测数据,我们采用的做法是逻辑隔离 (如果中间件、外围系统也采用物理隔离方案,将会导致成本开销太大,无法 Hold 得住),写入 Redis 时,压测数据的 Key 后面统一加上压测标识;写入 RocketMQ 时,我们会写入到不同的 Topic 中 (由于业务特点和介于 RocketMQ 本身的实现机制,我们选择了由 NameServer 路由到固定的几台压测 MQ 机器上)。
全链路压测军演系统 TITAN 的前世今生
最初研发和测试同学们使用的压测工具几乎是百花齐放的,比如:Jmeter、Apache AB 等常规压测工具,但是这类工具均无法瞬间发起超大规模的压测流量 (难以做到分布式压测),后来我们也考虑过 Ngrinder,无奈最后还是选择了放弃,因为 Ngrinder 也很难胜任我们的业务场景,Ngrinder 的 Controller 功能耦合过重,能够管理的 Agent 数量是极其有限的,关于这一点京东已经验证过了,我们自然也没必要再继续绕弯路,所以直接催生出了我们想要自研全链路压测军演系统的构想。
在着手研发 TITAN 之前,我们参考了京东 ForceBot 的整体架构,并进行了适当的提炼以便满足于我们自身的业务场景。而且在交互体验上,我们也是绞尽脑汁去较劲每一个细节 (这里要给基础架构组的刘亮同学 (花名:无邪),以及被我折磨得“死去活来”的前端组同学一个大大的赞),尽可能做到让研发和测试不需要参考使用手册就能够快速上手。
在云集内部 TITAN 一共经历了 2 个大版本的迭代。在最初 1.0 的时候,成型得比较简单粗暴,基本上贯彻的是能用就行的目标,虽然能用,但是 1.0 版本存在的问题确实也比较多,比如界面丑陋、功能流程上的不合理、技术实现上压测引擎的不稳定、统计的压测结果数据不准确等问题着实刺痛了我们。随着 2.0 的到来,我们在原有的基础之上等进行了大规模的重构,让其更加成熟、稳定和易用,并且对压测引擎和目标机器的性能监控也逐渐完善了起来,一切的初衷都是为了让性能问题无处遁形。
TITAN 的功能界面
TITAN 的功能特点:
- 天生为分布式系统而生,具备超高的并发压测能力,支持对 Agent(压测引擎)节点的无限水平扩容;
- 操作极其简单,上手快速,并且具备友好的交互式体验;
- 能够适配任何复杂的业务场景,支持多链路组装压测,无惧任何业务场景挑战;
- 支持对压测引擎、目标机器的可视化 CPU、内存、磁盘 IOPS 等监控,让问题浮出水面;
- 支持定时自动化压测任务,更好的实现线上压测常态化;
- 便捷的压测引擎管理,无需运维手工介入(启 / 停);
- 永久开源、不阉割功能,并且保证和云集内部版本保持一致,持续更新维护中;
- 完全采用 Java 语言编写,方便二次开发实现功能扩展。
技术实现细节
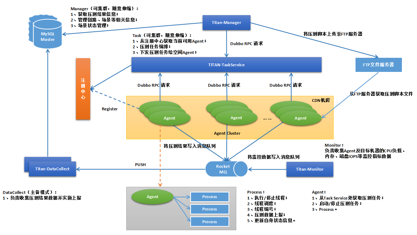
除了所依赖的外围系统外,TITAN 的整体架构由 5 部分构成:
- TITAN-Manager:管理控制台,负责链路、场景等相关信息管理,以及获取压测的业务指标数据与监控指标数据;
- TITAN-TaskService:负责具体的压测任务编排工作,并将压测任务信息下发给空闲 Agent;
- TITAN-Agent:压测引擎,向 ZK 注册心跳、获取压测任务并执行;
- TITAN-Monitor:负责收集压测引擎、目标机器的 CPU、内存、磁盘 IOPS 等监控指标数据;
- TITAN-DataCollect:负责收集压测数据并实施上报。
全链路压测军演系统 TITAN 整体的架构
任务编排与流量下发:
压测编排和任务下发都是由 TaskService 负责,由于云集内部的 RPC 框架使用的是 Dubbo,所以 TaskService 和 Agent 之间的通信采用的也是基于 Dubbo 的 RPC 调用。假设 Manager 请求 TaskService 需要对某个场景实施压测,TaskService 首先会执行任务编排,比如:空闲 Agent 调度、任务 ID 分配、动态参数分配、并发用户数分配、并发任务数分配等。计算完任务编排后,TaskService 会更改被选定的空闲 Agent 在注册中心内的当前状态信息,当 Agent 感知到变化后,会主动向 TaskService 发起 PULL,考虑到压测脚本容量可能会较大,Agent 从 TaskService 中获取的仅仅只是存放在 FTPServer 中的脚本路径,由 Agent 自行去 FTPServer 下载压测脚本,这也可以称之为被动的任务下发模式,可以很好的为 TaskService 减压。
被动的任务下发模式
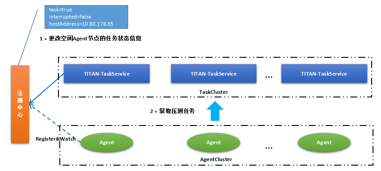
由于 Agent 通过 RPC 请求压测任务信息时,不同的 Agent 节点会由客户端路由到不同的 TaskService 上,换句话说,TaskService 节点部署得越多,这些压测前的预热工作就会处理的越快。
压测脚本文件的存储和下载:
FTP 协议本身就适合大文件的存储和下载,并且 Apache 提供有简单、易用的 FTP 组件,因此我们并没有使用 GIT 作为资源库来存放压测脚本文件,而是直接搭建了一个 FTP 服务器作为存放压测脚本文件的容器。
用户在创建链路的时候,如果上传了压测脚本,那么当 TaskService 在执行任务编排时,会将压测脚本进一步分解,因为在某些特定场景下,动态参数只能够被使用一次 (比如:优惠券),因此为每一个 Agent 分配的动态参数都是不同的。
压测引擎实现:
Agent 在启动时,首先会在注册中心内进行注册,并且维系着自身的各种状态。Agent 的状态分为空闲、忙碌和暂停 3 种。当执行压测时,TaskService 会从注册中心获取当前状态为空闲的 Agent,并更改其状态为忙碌,压测结束后再重置为空闲状态。Agent 的底层实现是基于 Apache 的 HttpClient 组件,每一个 Agent 进程最大允许开启的并行线程数为 2000,当然如果物理机器的 CPU 够好,可以适当进行微调。可以明确的是,如果一个 Agent 集群环境中的可用节点数越多,那么可以下发的压测流量就会越大 (假设 1W 个 Agent 节点,那么所支持的最大的并发用户数将会达到 1W*2K=2000W)。
假设用户触发了停止压测,那么 Agent 进程内部的线程池将会接受到 interrupted 指令,一般来说,可以控制在秒级别停止一个场景的压测任务。
数据收集与上报:
DataCollect 负责收集的指标数据有 2 种,一种是由 Agent 提交的性能指标数据,另一种是由 Monitor 提交的监控指标数据。无论哪一种指标数据 ,都不会直接落盘到 DB 中,而是优先写入 RocketMQ 进行消峰后再落盘,这么做的目的是为了不对 DB 造成太大的负载压力。
假设一个场景使用了 5 个 Agent 节点进行压测,那么 DataCollect 会等待这 5 个同一批次的压测指标数据全都提交完成后,再合并计算 (合并计算后将会产生 TPS、用户 / 服务器平均请求等待时间、HTTP200/ 业务成功率、峰值持续时间等业务指标数据),最后再将压测结果数据上报到 DB 中落盘。
压测结果数据合并:

开源以及对未来的展望
TITAN 预计会在元旦后于 Github 上正式开放其源码,目前正处于紧张的代码优化工作中,但相关文档(使用手册、安装部署手册) 已经准备完成。我们也希望更多的技术大牛能够参与其中,共同来打造一个强大的开源全链路压测系统。
目前 TITAN 还有很多的不足,关于未来的规划我们希望是这样的:
- 能够与数据工厂相结合,完成压测数据的准备工作,而不需要由人工提供压测动参;
- 存储系统逐步替换为 Elasticsearch;
- 支持更多的协议。
作者介绍
高翔龙,云集微店研发中心基础架构组负责人,架构师,2016 年年初加入云集,2 年时间里有幸见证并亲身经历了云集从小到大的架构演变过程,目前主要负责基础技术平台的架构设计和中间件研发等工作,主导了 2017 年双 11、双 12 线上全链路压测。著有技术书籍《Java 虚拟机精讲》、《人人都是架构师—分布式系统架构落地与瓶颈突破》,长年游走在 GIthub 上。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论 1 条评论