

作为快手内部数据规模和机器规模最大的分布式文件存储系统,HDFS 一直伴随着快手业务的飞速发展而快速成长。
本文主要从以下三个层面,介绍下 HDFS 系统在快手业务场景下的落地实践:
HDFS 架构介绍
快手 HDFS 数据和集群规模介绍
快手 HDFS 挑战与实践
HDFS 架构介绍
HDFS 全名 Hadoop Distributed File System,是 Apache Hadoop 的子项目,也是业界使用最广泛的开源分布式文件系统。
核心思想是:将文件按照固定大小进行分片存储,具备:强一致性、高容错性、高吞吐性等
架构层面是典型的主从结构:
主节点:称为 NameNode,主要存放诸如目录树、文件分片信息、分片存放位置等元数据信息
从节点:称为 DataNode,主要用来存分片数据
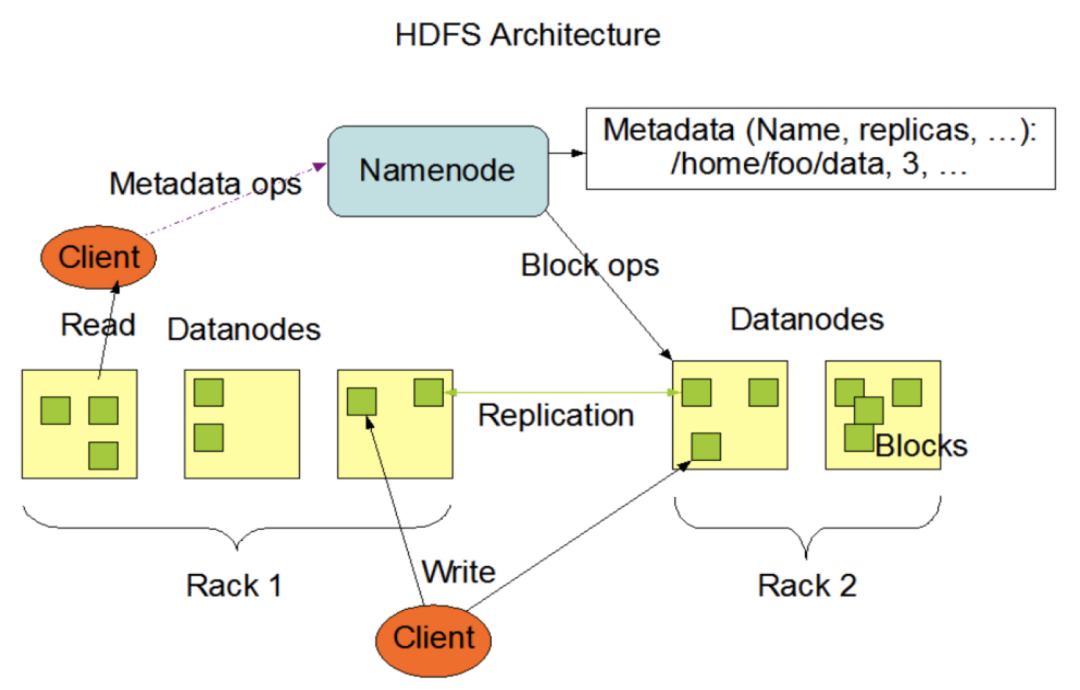
HDFS 官网架构
快手 HDFS 数据规模和集群规模介绍
快手 HDFS 历经 3 年的飞速发展,承载了整个快手几乎全量的数据存储,直接或间接的支持了上百种业务的发展。从最初的千台规模,目前已经发展成拥有几万台服务器、几 EB 数据的超大规模存储系统。
1. 业务类型
在整个数据平台中,HDFS 系统是一个非常底层也是非常重要的存储系统,除了常用的 Hadoop 生态开源组件之外,还承载诸如 kafka、clickhouse 等在线核心组件数据(ps:有兴趣的同学可以私聊)
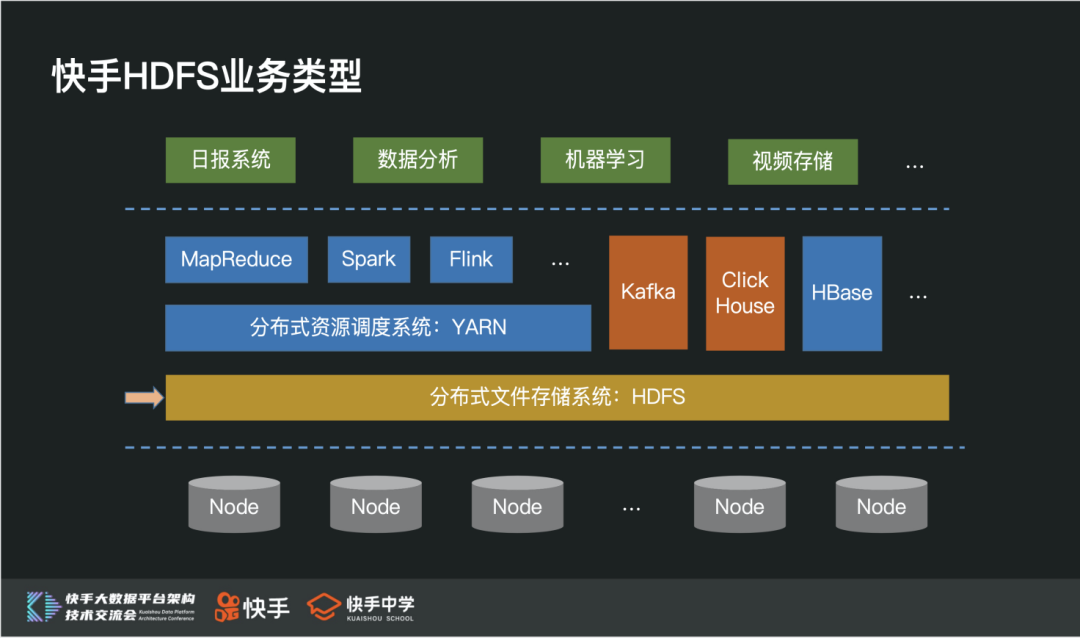
2. 集群规模
作为数据平台中最底层的存储系统,目前也是整个快手中机器规模和数据规模最大的分布式存储系统,单个 HDFS 集群拥有:
几万台服务器
几 EB 数据规模、几百 PB 的 EC 数据量
每天拥有几百 PB 的数据吞吐
几十组 NameService
几百亿元数据信息
百万级 Qps

快手 HDFS 挑战与实践
在数据爆炸式增长的过程中,HDFS 系统遇见的挑战是非常大的。接下来,主要从 HDFS 架构四个比较核心的问题入手,重点介绍下快手的落地过程。
主节点扩展性问题
单 NS 性能瓶颈问题
节点问题
分级保障问题
1. 主节点扩展性问题
众所周知,主节点扩展性问题是一个非常棘手,也是非常难解决的问题。当主节点压力过大时,没办法通过扩容的手段来快速分担主节点压力。
随着集群规模越来越大,问题也越来越严重。我们认为要解决这个问题,至少需要具备两个能力:
具备快速新增 NameService 的能力
具备新增 NS 能快速分担现存 NS 压力的能力
无论社区 2.0 的 Federation 架构,还是社区最新 3.0 的 Router Based Federation 架构,都不能很好的满足这两个条件。综合讨论了多个方案之后,我们决定在社区最新 3.0 的 RBF 架构基础上,进行深度定制开发,来解决主节点扩展性问题。
首先,我们介绍两个业务场景的扩展性方案:
① 快手 FixedOrder && RbfBalancer 机制
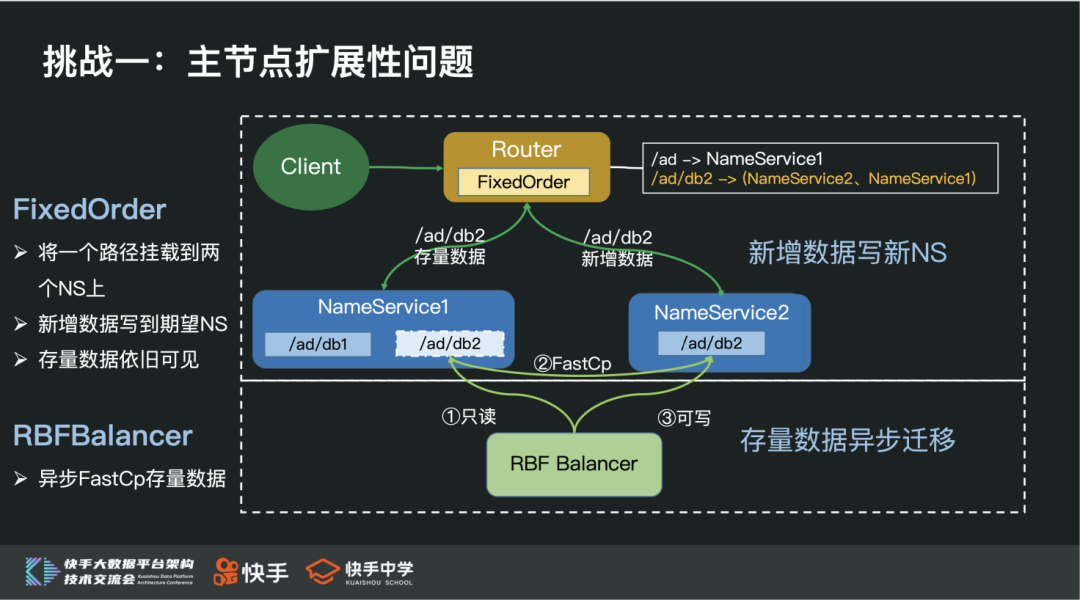
我们支持的第一个扩展性机制:FixedOrder 机制
将一个路径挂载到多个 NS 上,记为 FixedOrderMountPoint
FixedOrderMountPoint 下所有新建目录或文件都写到期望的 NS(比如新增 NS)
FixedOrderMountPoint 下目录或文件的访问,通过探测的方式,可以有效的访问到新老数据(增加 FixedOrderMountPoint 前后的文件或目录)
利用这个机制,可以通过快速新增 NS,来有效缓解热点 NS Qps 压力过大的问题。
除此之外,我们还研发了 RbfBalancer 机制,通过 FastCp 的方式,在业务完全透明的场景下将存量数据异步搬迁到新的 NS 里,达到缓解老 NS 内存压力的效果。由于老 NS Qps 压力已经被快速分担,所以异步数据迁移的进度,没有强要求。
利用 FixedOrder + RBFBalancer 机制,通过扩容新 NS 并快速分担老 NS 的压力,来解决大多数场景的扩展性问题。
② 快手 DFBH 机制
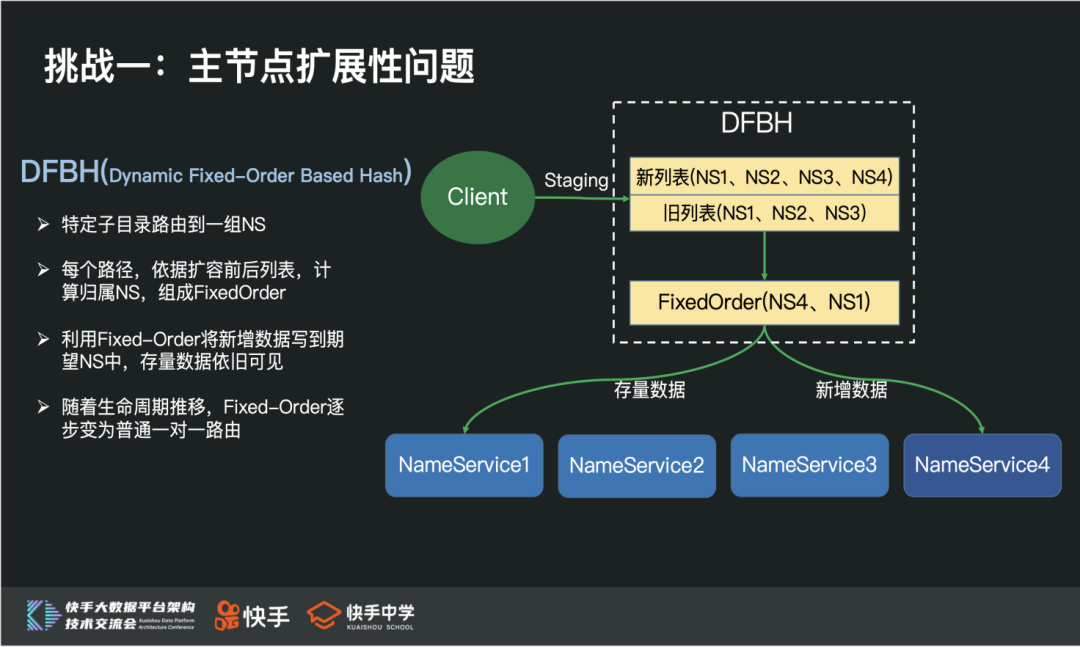
众所周知,分布式开源组件中存在大量 Staing 路径,比如:Yarn Staing 路径、Spark Staing 路径、Hive scratchdir 路径、Kafka Partition 路径等,这一类路径有两个特点:
Qps 非常大,需要多个 NS 承担
具有短暂的生命周期
针对这一类路径 ,我们引入了 DFBH 机制,来解决主节点扩展性问题:
通过一致性 Hash 实现多 NS 间 Qps 负载均衡
利用动态 FixedOrder 机制,在不搬迁数据的场景下,实现透明扩缩容 NS
实现的核心思想是:
每个路径依据多组一致性 Hash 列表计算出归属 NS,组合成 FixedOrder
将增量数据写到期望 NS 中 ,存量数据依旧可见
随着生命周期推移,逐步回退到最普通的一致性 Hash 策略
社区贡献
除了完善多个扩展性方案之外,我们还解决了大量 RBF 正确性、性能、资源隔离等稳定性问题,同时也积极为社区提供大量 BugFix,有兴趣的同学可以参考下:
https://issues.apache.org/jira/browse/HDFS-15300
https://issues.apache.org/jira/browse/HDFS-15238
https://issues.apache.org/jira/browse/HDFS-14543
https://issues.apache.org/jira/browse/HDFS-14685
https://issues.apache.org/jira/browse/HDFS-14583
https://issues.apache.org/jira/browse/HDFS-14812
https://issues.apache.org/jira/browse/HDFS-14721
https://issues.apache.org/jira/browse/HDFS-14710
https://issues.apache.org/jira/browse/HDFS-14728
https://issues.apache.org/jira/browse/HDFS-14722
https://issues.apache.org/jira/browse/HDFS-14747
https://issues.apache.org/jira/browse/HDFS-14741
https://issues.apache.org/jira/browse/HDFS-14565
https://issues.apache.org/jira/browse/HDFS-14661
2. 单 NS 性能瓶颈问题
众所周知,HDFS 架构中 NameNode 的实现中有一把全局锁,很容易就达到处理瓶颈。社区最新 3.0 提出了一个 Observer Read 架构,通过读写分离的架构,尝试提升单个 NameService 的处理能力,但是最新的架构问题比较多。
针对单 NS 性能瓶颈这个问题,我们尝试从两个阶段解决:
快手特色 ObserverRead 架构,从读写分离角度提升 NS 处理能力【重点介绍】
优化 NameNode 全局锁,从提升单 NN 处理能力角度提升 NS 处理能力【进行中】
快手特色 ObserverRead 架构
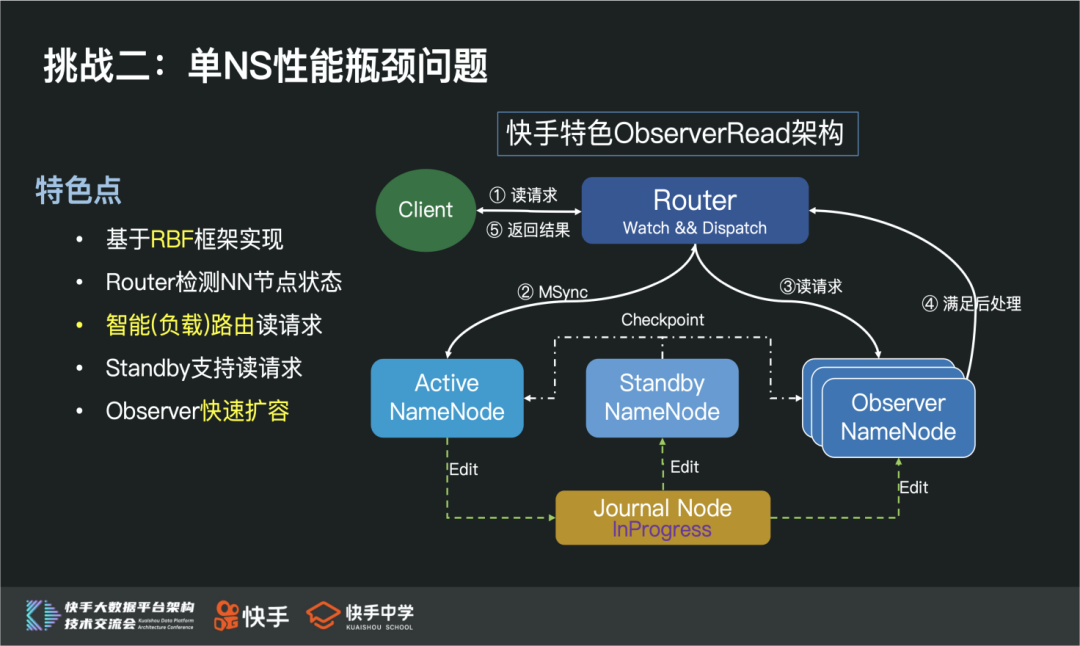
快手特色 ObserverRead 架构是基于最新的 RBF 框架落地的,在客户端完全透明的场景下,实现动态负载路由读请求的功能,提升整个 NS 处理能力。
相比社区的 ObserverRead 架构,快手特色 ObserverRead 架构有几个非常明显的优势:
整个架构,基于 RBF 框架实现,客户端完全透明
Router 检测 NN 节点状态,实现动态负载路由读请求
Standby、Active 节点可以支持读请求
Observer 节点支持快速扩容
在整个最新架构落地过程中,也解决了社区 ObserverRead 架构大量稳定性问题,比如:
MSync RPC 稳定性问题
Observer Reader 卡锁问题
NameNode Bootstrap 失败问题
Client Interrupt 导致无效重试问题(HDFS-13609)
3. 慢节点问题
随着集群规模越来越大,慢节点问题也越来越明显,经常导致作业出现长尾 Task、训练“卡住”等问题。
慢节点问题主要体现在从节点 DataNode 上,主要是因为物理指标负载比较大,比如:网卡流量、磁盘 Util、Tcp 异常等。
针对这个问题,我们从两个大的方向着手解决:
慢节点规避
慢节点根因优化
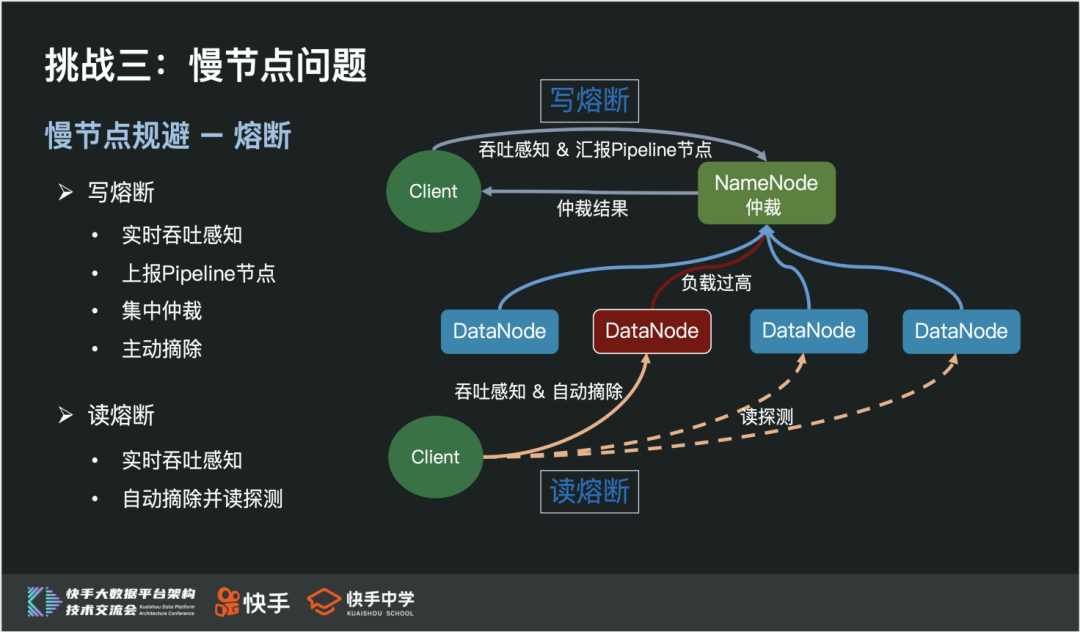
① 慢节点规避
主要从事先规避和事中熔断两个角度来实现 HDFS 层面的慢节点规避机制。
事先规避,即客户端在读写数据前,NameNode 依据 DN 的负载信息进行排序,优先返回低负载的 DN。
其判断依据主要有:负载指标(CPU 使用率、磁盘 Util、网卡流量、读写吞吐量);客户端上报慢节点。
事中熔断,即客户端在读写数据过程中,通过吞吐阈值实时感知慢节点,进行实时慢节点摘除功能。
通过事先规避和事中熔断机制,能有效地解决长尾 Task、训练“卡住”等问题。
② 慢节点根因优化
从资源利用率最大化的角度出发,从节点 DataNode 机器是和 Yarn NodeManager 混布的。
通过硬件指标采集发现:Yarn MapReduce 的 shuffle 功能对硬件繁忙程度贡献度非常大,所以我们从 Yarn Shuffle 优化和 DN 内部机制优化两个角度尝试从根因入手解决慢节点问题。
这里,我主要介绍下 DN 内部优化逻辑,主要包括:
在线目录层级降维
即 DN 在不停读写的场景下,实现 block 存储目录的降维工作,极大地缩减磁盘元数据信息。
DataSet 全局锁优化
将 DN 内部全局锁细粒度化,拆分成 BlockPool + Volume 层级,降低 BlockPool 之间、磁盘之间的相互影响。
Du 操作优化
将定期的 DU 操作,通过内存结构计算单磁盘 BP 使用量。
选盘策略优化
添加负载选盘策略,优先选择负载比较低的磁盘。
4. 分级保障问题
众所周知,快手经常有一些大型活动,比如春节活动、电商活动、拉新活动等,而且整个活动过程中还伴随着无数个例行任务。
瞬间的洪峰流量,可能会导致 HDFS 系统满载,甚至过载。
为了在 HDFS 系统满载的场景下尽可能的保障高优先级任务正常运行,所以我们将所有任务抽象成高优先级、中优先级和低优先级任务,同时 HDFS 系统支持分级保障功能,来满足这个需求。
我们主要从 NameNode 和 DataNode 两个角色入手,支持分级保障功能。
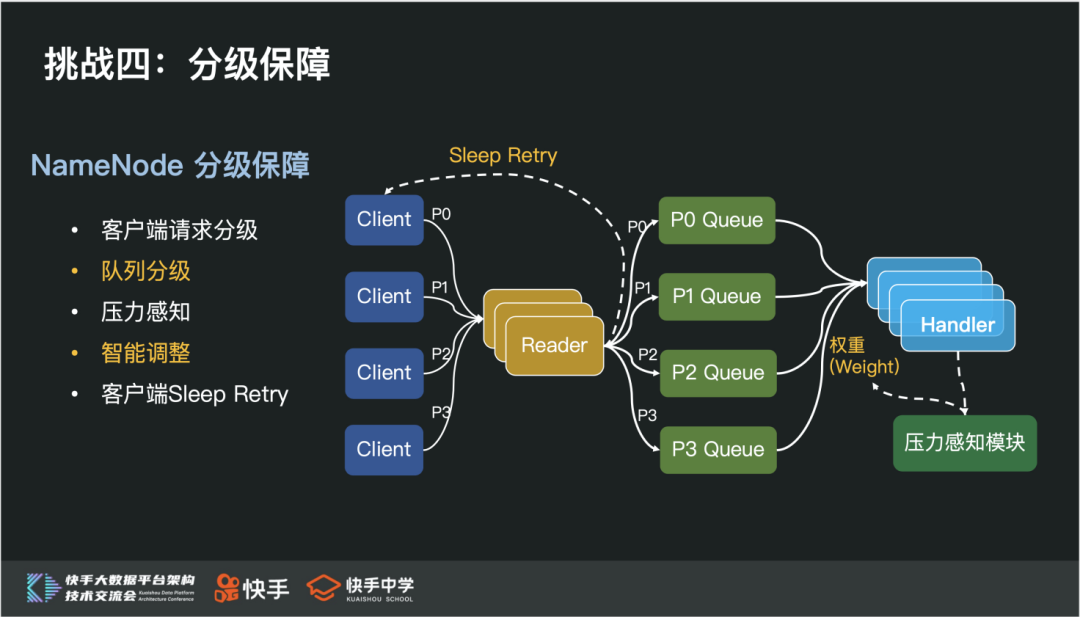
NameNode 分级保障功能
我们深度定制了 NameNode Rpc 框架,将队列拆分成优先级队列,Handler 依据资源配比依次处理不同优先级队列请求。与此同时,通过压力感知模块,实时感知各个优先级请求的压力,并动态调整资源配比,从而实现:
未满载时,按照资源配配比处理请求
满载时,资源倾向高优,优先处理高优请求
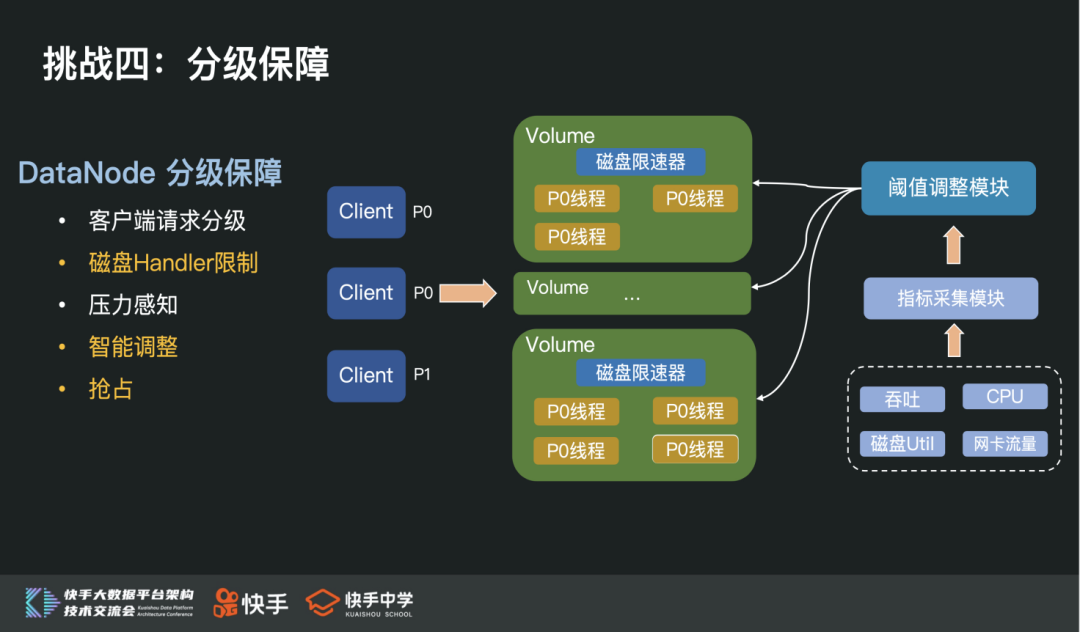
DataNode 分级保障功能
由于 DataNode 内部是通过独占线程方式与客户端进行数据 IO 的,所以我们在每个磁盘上添加了磁盘限速器。
当磁盘资源达到上限后,高优先级请求到来时,会强占低优先级资源。除此之外,我们还添加了阈值调整模块,实时感知相关指标,动态调整磁盘限速器阈值,来控制单盘压力。
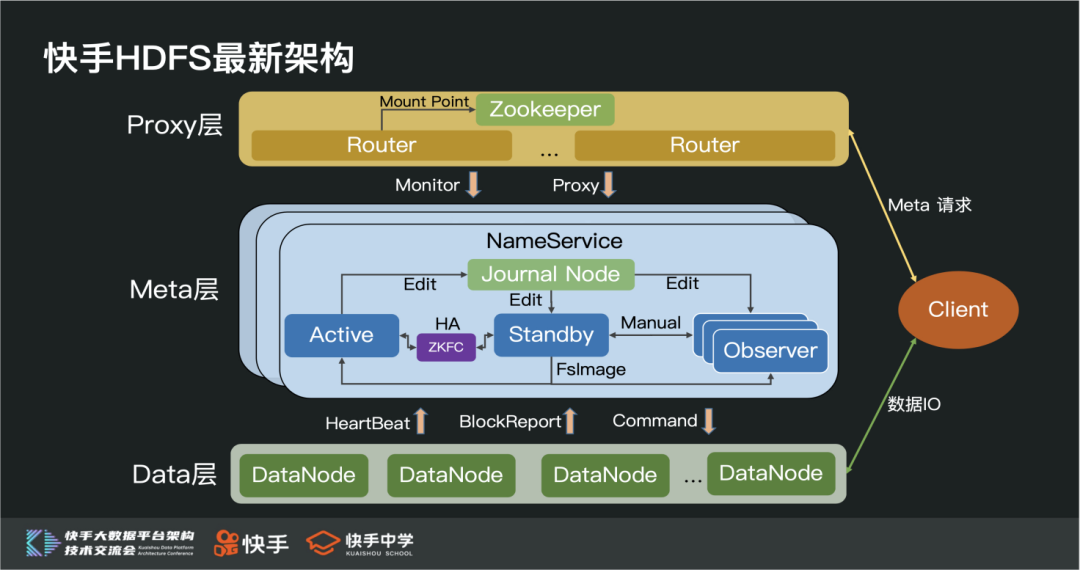
5. 快手 HDFS 架构图
最后,我们介绍下目前快手 HDFS 系统的最新架构。
整个架构整体分为三层,分别是:路由层、元信息层和数据层。
① 路由层
由一组无状态的 Router 服务组成,Router 间通过 ZK 来共享挂载点信息等,主要用于转发客户端的元信息请求。
② 元信息层
由多组相互独立的 NameService 组成,每组 NameService 内主要有一台 Active NameNode 服务、一台 Standby NameNode 服务、N 台 Observer NameNode 服务组成。
其中:
Active 和 Standby 通过 ZKFC 实现动态 HA 切换的功能
Active 主要承担写请求压力
Standby 除了承担定期 Checkpoint 功能外,还支持部分读请求
Observer 主要分担读请求压力
③ 数据层
由一组无状态的从节点(DataNode)组成,主要用来存在数据;通过心跳、块汇报等 Rpc 与主节点保持最新状态。
结尾
快手 HDFS 经历了 3 年的发展,从最初的几百台节点支持 PB 级数据量的小规模集群,到现在的拥有几万台节点支持 EB 级数据量的超大规模集群。我们团队用无数个黑夜,经历了数据爆炸式增长的过程,抗住了巨大压力,踩了无数的坑,同时也积累大量经验。
当然,快手依旧处于飞速发展过程中,我们团队依旧不忘初心,怀着敬畏之心,继续匠心前行。
PS:快手-数据平台火热招聘中,包括数据架构研发工程师、数据产品 Java 后端开发、数据产品经理等热门岗位,联系方式:hesiyuan@kuaishou.com”
分享嘉宾:
徐增强,快手分布式存储高级研发工程师。主要负责 HDFS 系统 的运维和研发工作,Hadoop、Kafka 活跃 Contributor,主要关注分布式存储技术领域。
本文转载自:DataFunTalk(ID:dataFunTalk)
原文链接:快手EB级HDFS挑战与实践

腾讯大规模云原生技术实践案例集
本案例集详细阐释了 QQ、腾讯会议、和平精英、小红书、斗鱼、微盟等十多个亿级用户产品背后的大规模云原生...










评论