

最近,AWS 发布了基于最新一代 Intel Xeon Scalable Platinum 处理器的全新计算密集型 Amazon EC2 C5 实例。这些实例专为计算量大的应用程序设计,并且与 C4 实例相比,性能明显改进。它们还为每个 vCPU 提供更多内存,是矢量和浮点工作负载的两倍。
在本博客中,我们将演示 BigDL,适用于 Apache Spark 的开源分布式深度学习框架,它可以利用 AWS C5 实例中提供的新功能,这些功能可以显着改善大型深度学习工作负载。具体来说,我们将展示 BigDL 如何使用 C5 实例来利用低精度和量化,以便最多将模型大小缩小 4 倍,使推理速度提升近 2 倍。
为什么要在 C5 实例上进行深度学习?
新的 AWS C5 实例利用 Intel Xeon Scalable 处理器功能,例如更高的处理器频率下更多的核心数、更快的系统内存、大型每核中级缓存(MLC 或 L2 缓存),以及新的宽 SIMD 指令 (AVX-512)。这些功能旨在提升深度学习中涉及的数学运算,使得新的 C5 实例成为大规模深度学习的绝佳平台。
BigDL 是适用于 Apache Spark 的分布式深度学习框架,由 Intel 开发并开放源代码,它允许用户在现有的 Hadoop/Spark 集群上构建和运行深度学习应用程序。自 2016 年 12 月首次开放源代码以来,业界和开发人员社区已经广泛采用 BigDL(例如:Amazon、Microsoft、Cray、阿里巴巴、京东、MLSlistings 以及 Gigaspaces 等等)。
BigDL 经过优化后,可在大型大数据平台上运行,这些平台通常以基于 Xeon 的分布式 Hadoop/Spark 集群为基础构建。它利用 Intel 数学内核库 (MKL) 和多线程计算实现高性能,并使用底层 Spark 框架进行有效的扩展。因此,它可以有效利用 AWS 提供的新 C5 实例中的功能,而且与前几代实例系列相比,速度明显提升。
利用低精度和量化
除了使用 C5 实例获得的原始性能改进之外,BigDL 0.3.0 版本还引入了模型量化支持,允许使用较低精度的计算进行推理。在 AWS 提供的 C5 实例上运行,可以看到模型大小缩小了 4 倍,推理速度提升了近 2 倍。
什么是模型量化?
量化是一个一般术语,是指使用以比其原始格式(例如,32 位浮点)更紧凑和更低精度的形式存储数字并对其执行计算的技术。BigDL 利用这种低精度计算来量化预先训练的模型以进行推理:它可以采用在各种框架(例如 BigDL、Caffe、Torch 或 TensorFlow)中训练的现有模型,使用更紧凑的 8 位整数格式量化模型参数和输入数据,然后应用 AVX-512 向量指令快速进行 8 位计算。
量化在 BigDL 中如何工作?
BigDL 允许用户直接加载使用 BigDL、Caffe、Torch 或 TensorFlow 训练的现有模型。加载模型后,BigDL 首先可以使用以下公式将某些选定层的参数量化为 8 位整数,以生成量化模型:
Math.round(1.0 * value / Math.max(Math.abs(max), Math.abs(min)) * Byte.MaxValue).toByte
在模型推理期间,每个量化层动态地将输入数据量化为 8 位整数,使用量化参数和数据应用 8 位计算(例如 GEMM),并将结果反量化为 32 位浮点。许多这类运算可以融合在实施中,因此,推理时的量化和反量化开销非常低。
与许多现有实施不同,BigDL 使用新的本地量化架构进行模型量化。也就是说,它在每个小型本地量化窗口、参数或输入数据的小型子数据块(例如补丁或内核)中执行量化和反量化运算(如前所述)。因此,BigDL 可以在具有极低的模型精度下降率(小于 0.1%)的模型量化中使用非常低位的整数(例如 8 位),并且可以实现超高效率,如下面的图表所示,其中包含博客末尾列出的实际基准配置的详细信息。
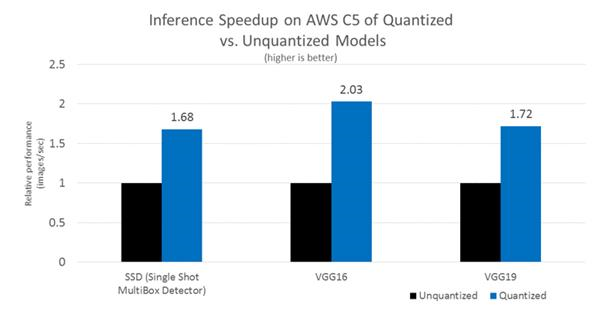
C5 实现推理加速:相对性能(量化与非量化模型)- 在 BigDL 中使用量化可以实现 1.69~2.04 倍的推理加速
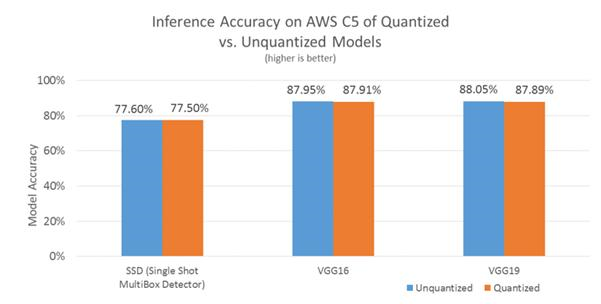
C5 实现的推理精度:(量化与非量化模型)- 在 BigDL 中使用量化时,精度下降率不到 0.1%
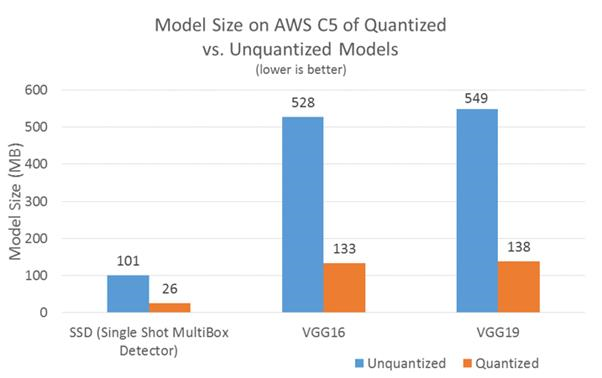
模型大小(量化与非量化模型)- 在 BigDL 中使用量化时,模型大小缩小了大约 3.9 倍
如何在 BigDL 中使用量化?
要在 BigDL 中对模型进行量化,首先要按以下方式加载现有模型(有关 Caffe 支持和 TensorFlow 支持的更多详细信息,请参阅 BigDL 文档):
之后,您只需将模型量化,并按照以下方式将其用于推理即可:
此外,BigDL 还提供命令行工具 (ConvertModel),用于将预先训练的模型转换为量化模型。有关模型量化支持的更多详细信息,请参阅 BigDL 文档。
自己试试吧!
立即通过 AWS Marketplace 在 AWS 上试用 BigDL。
您可以在此处了解有关 BigDL 和模型量化的更多信息。
要在 Amazon EMR 上运行 BigDL,您可以按照我们之前博文 Running BigDL, Deep Learning for Apache Spark, on AWS 中的说明进行操作。
基准配置详细信息:
优化注意事项:Intel 的编译器可能会针对非 Intel 微处理器进行相同程度的优化,以实现并非 Intel 微处理器所独有的优化。这些优化包括 SSE2、SSE3 和 SSSE3 指令集以及其他优化。Intel 不保证非 Intel 制造的微处理器的任何优化的可用性、功能或有效性。本产品中依赖于微处理器的优化适用于 Intel 微处理器。Intel 微处理器保留了某些非 Intel 微架构独有的优化。有关本注意事项所涵盖的特定指令集的更多信息,请参阅适用的产品“用户及参考指南”。
Intel、Intel 徽标、Xeon 是 Intel Corporation 在美国和/或其他国家/地区的商标。
作者介绍:
Jason Dai
Intel 大数据技术部门的高级首席工程师兼首席技术官,领导全球工程团队开发先进的大数据分析(包括分布式机器学习和深度学习)。他是 Apache Spark 的发起者、PMC 成员、北京 O’Reilly AI Conference 的项目联合主席,也是 BigDL 的首席架构师。BigDL (https://github.com/intel-analytics/BigDL/) 是 Apache Spark 上的分布式深度学习框架。
Joseph Spisak
领导 AWS 的合作伙伴生态系统专注于人工智能和机器学习。他在 Amazon、Intel 和 Motorola 等公司从事深度技术工作超过 17 年,主要从事视频,机器学习和人工智能等方面的工作。在业余时间,他喜欢打冰球和阅读科幻小说。
本文转载自 AWS 技术博客。
原文链接:
https://amazonaws-china.com/cn/blogs/china/ec2-c5-bigdl-deep-learning/


腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论