

Jellyfish 项目成功地降低了 Uber 的运营费用,并且未来可以节省更多的存储资源。这里介绍的分层概念可以通过多种方式进行扩展,进一步提高效率并降低成本。
问 题
Uber 利用一些存储技术基于其应用模型来存储业务数据。其中一项技术是 Schemaless,它能够对相关条目进行建模,然后存储在一个包含多个列的行中,并对每列进行版本管理。
Schemaless 已经存在了多年,其中积累了 Uber 的大量数据。虽然 Uber 正在整合 Docstore 上的所有用例,但 Schemaless 仍然是先前已经存在的不同客户管道的事实来源。为此,Schemaless 使用快速(但昂贵)的底层存储技术来实现高 QPS 下的毫秒级延迟。此外,Schemaless 还在每个区域都部署了一些副本,以确保不同故障模式下数据的持久性和可用性。
由于积累的数据越来越多,同时又使用了昂贵的存储,所以 Schemaless 已日益成为关键的成本问题,需要特别关注。因此,为了了解数据访问的模式,我们做了一些度量。我们发现,在一段时间内数据会被频繁地访问,之后访问频率会降低。确切的时期段因用例不同而异,不过,旧数据仍然必须根据要求随时可用。
要 求
为了勾勒出问题的恰当解决方案,我们提出了以下 4 个主要要求。
向后兼容
Schemaless 已经存在了很久,它是 Uber 许多服务甚至是服务分层不可或缺的组成部分。因此,改变现有 API 的行为或引入一套新的 API 都不是合适的选项,因为它们需要对 Uber 产品服务做一连串的修改,导致方案落地延期。为此,向后兼容就成了一项必然要求——消费者应该不需要修改代码,就能享受到方案所带来的所有效率提升。
延迟
低延迟对于及时获得数据至关重要,因此,我们与消费者团队合作,调研不同的用例。研究表明,对于使用旧数据的用例,几百毫秒的 P99 延迟是可以接受的,而对于使用新数据的用例,延迟必须保持在几十毫秒之内。
效率
对现有 API 实现的任何改变都应该尽可能保持高效率,这不仅是为了保证低延迟,也是为了防止资源过度使用,如 CPU 和内存。这就需要进行优化,以减少读取 / 写入放大,关于这一点,我们将稍后进行说明。
可配置性
如前所述,Schemaless 在 Uber 有许多用例,这些用例在访问模式和延迟容忍度等方面不尽相同。这就要求我们的解决方案在一些关键点上可参数化,以便可以针对不同的用例进行配置和调整。
解决方案
该解决方案的一个重要理念是,根据数据的访问模式来处理数据,让我们可以获得相称的投资回报率。也就是说,频繁访问的数据成本相对较高,而不频繁访问的数据成本必须相对较低。这正是数据分层所要达到的目的——类似于内存分层的概念。不过,我们需要一种方法来保持向后的兼容性,以确保对我们的消费者可以不做任何更改。这就要求我们把数据放在与复杂操作相同的层级中,这对跨层协同来说是个不小的挑战。
我们研究了减少旧数据空间占用的方法。我们尝试对数据单元(如一个行程)进行批处理,并在应用层面应用不同的压缩方法,这样我们就可以根据应用的预期性能来调整压缩系数。这同时也降低了回填作业的读取 / 写入放大率,我们将在后面讨论。我们探索了不同的压缩方法,针对不同的用例做了不同的配置。我们发现,当我们批量压缩若干单元时,ZSTD 压缩算法整体可以节省高达 40% 的存储空间。
在这一点上,我们意识到,借助压缩和批处理,我们可以在同一层中对数据进行内部分层,进一步减少旧数据的空间占用。这使我们能够把延迟控制在所要求的几百毫秒之内。由于批次大小和 ZSTD 是可配置的,我们可以针对目前由 Schemaless 提供服务的不同用例调整我们的解决方案。通过恰当的实现,我们也可以满足效率要求,达成上面讨论的所有 4 个要求。
我们把这个项目称为 Jellyfish,因为它是海洋中最高效的游泳选手,它在一定距离内消耗的能量比其他任何水生动物都少,包括强大的鲑鱼。
概念验证
现在,解决方案的大框架已经有了,我们需要快速评估其价值。为此,我们进行了一系列的实验,并做了一个快速的概念验证。我们的目标是评估总体能节省多少空间。
Jellyfish 主要使用 2 个参数来控制总体的空间节省,以及对 CPU 利用率的影响:
批次大小:控制批处理的行数
压缩等级:控制速度 vs. ZSTD 压缩
根据概念验证的度量结果,我们将批次大小设为 100 行,ZSTD 等级设为 7,这对 CPU 来说压力应该不大。
在这种设置下,总体压缩率约为 40%,如下图所示。该图还显示了我们尝试过的其他配置,这些配置出现了收益递减或空间节省降低的情况。
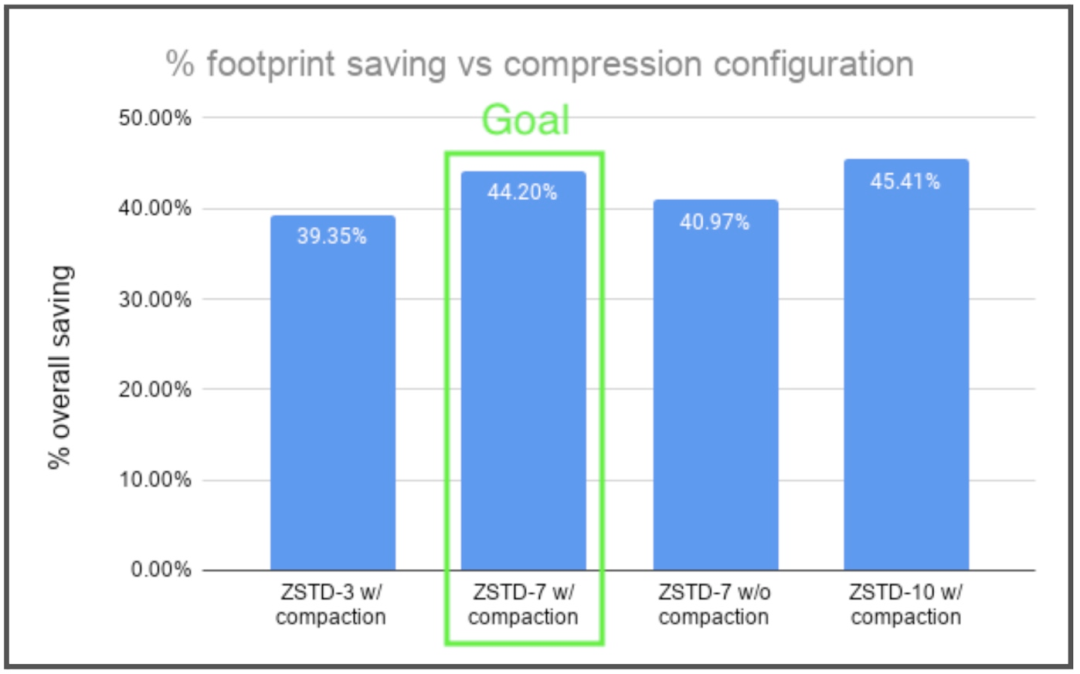
我们还没有在大规模情况下观察的一个关键指标是“批处理”请求的延迟。在实现的早期,我们通过一些压力测试跟踪过,确定可以满足延迟 SLA,即数百毫秒。
架 构
虽然我们考虑了几个备选方案,但在这里我们只讨论最终设计。整体架构如下图所示。后端有批处理表和实时表。批处理后端存储从实时后端迁移过来的旧数据。实时后端与旧的后端完全一样,但只用来存储最近的数据。也就是说,新数据总是被写进实时后端,就像以前一样。一旦数据在一段时间后变冷,就会被迁移出来。
下图是一个高级视图,显示了在实现 Jellyfish 之后前端(查询层)和后端(存储引擎)组件的新架构。简单起见,我们将主要关注新增部分,即以绿色显示的部分。新架构的核心是 2 个表:(1)标准的“实时”表和(2)新增的批处理表。还是和以前一样,客户数据首先会被写入实时表。经过一定的时间后(可根据用例进行配置),数据在经过分批和压缩后被移到批处理表中。分批是由单元格完成的,它是 Schemaless 的基本单位。
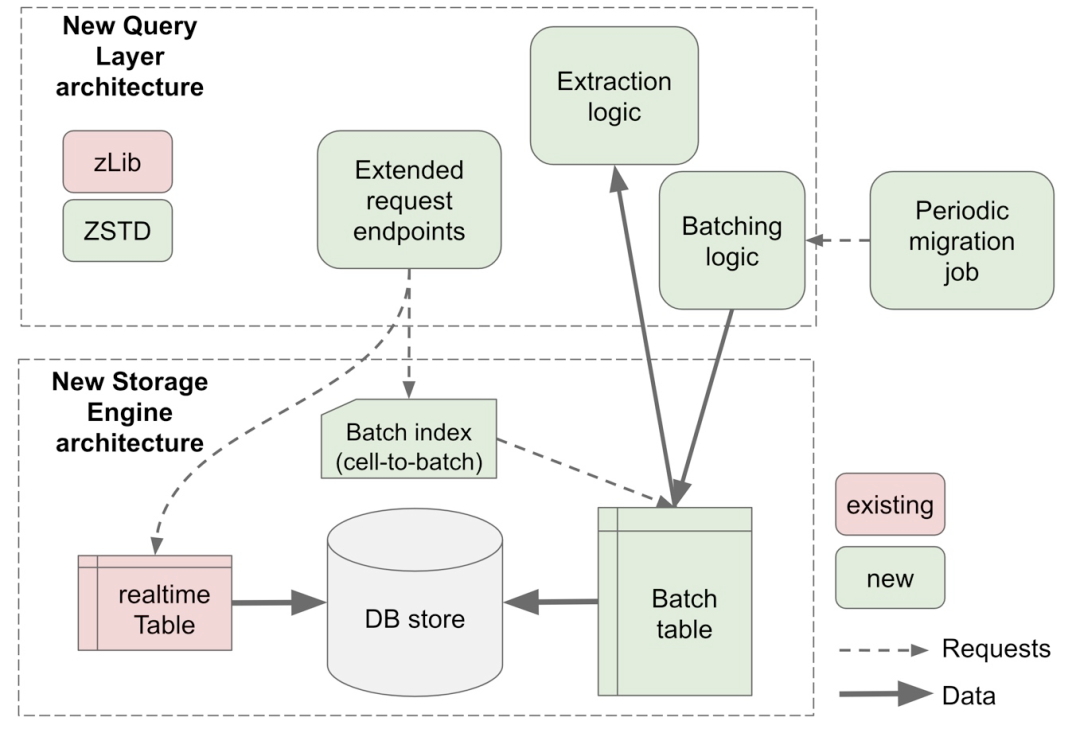
如图所示,Schemaless 用了一个批处理索引,它从单格元的 UUID 映射到相应的批次 UUID(UUID 到 BID)。在读取旧数据的过程中,批处理索引用来快速检索出正确的批次,解压,并对其进行索引以提取所请求的单元格。
请 求 流
新架构对用户请求流产生了一些影响,我们将从读取和写入两个方面进行说明。
读取
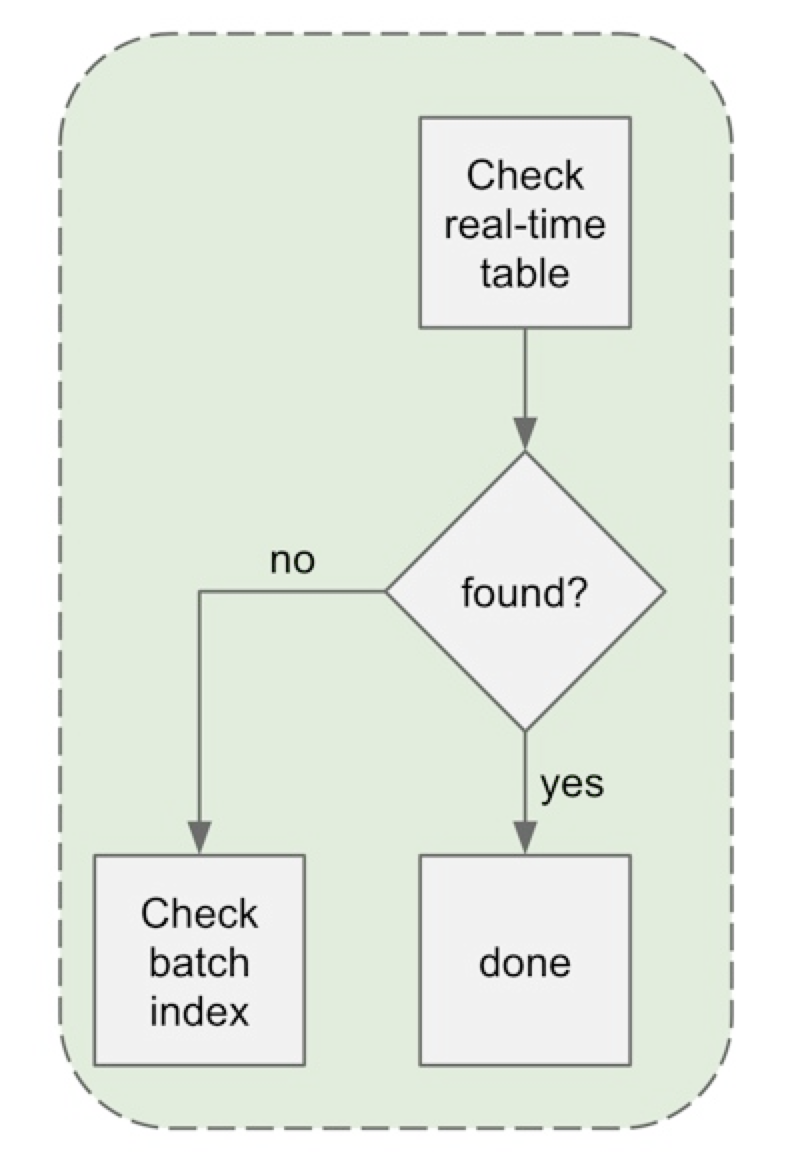
单个单元格的读取还是和平常一样进到实时表,因为大多数请求(>90%)都是针对最近的数据。如果成功,请求之后就会终止。如果不成功,请求会“溢出到”批处理索引,找到批处理表,并在同一查询中获取它。下图显示了这个流程。
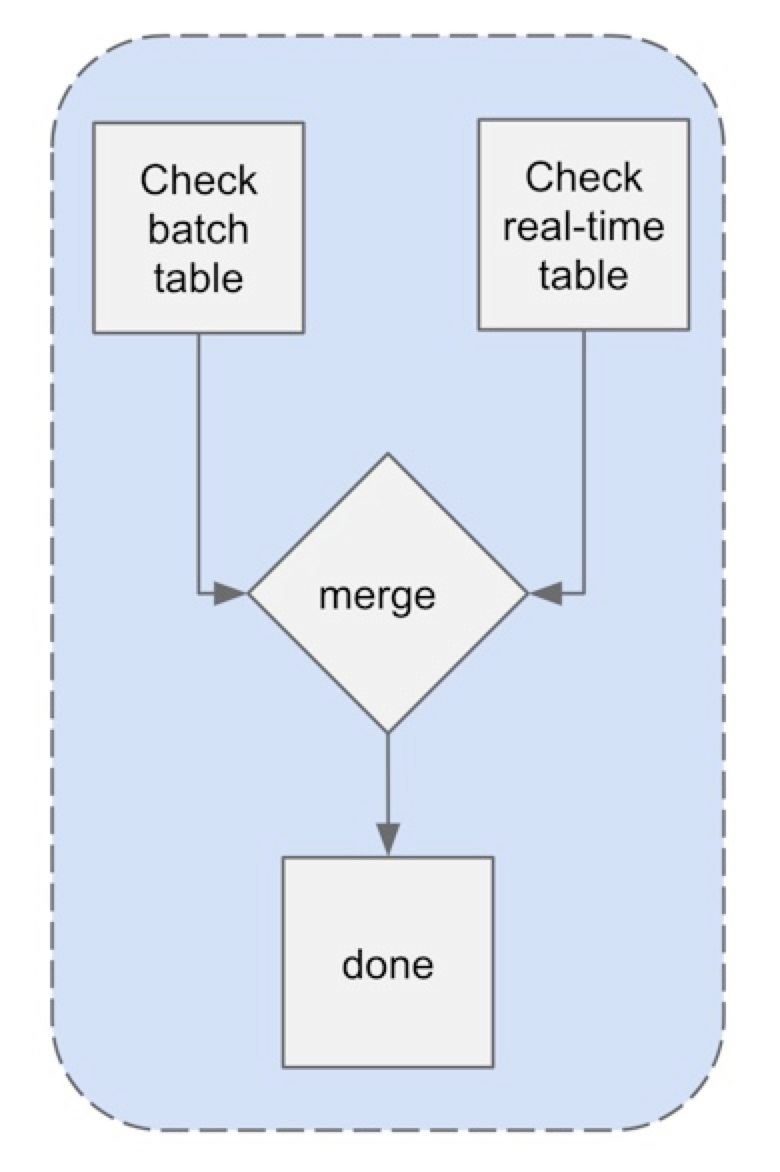
还有一种类型的读取,它请求一个完整的行(构成一个逻辑业务实体的若干单元格,如行程)。这种请求的数据可能跨越了实时表和批处理表的界限。对于这样的请求,我们调用两个后端,并根据用户定义的一些顺序合并结果,如下图所示。
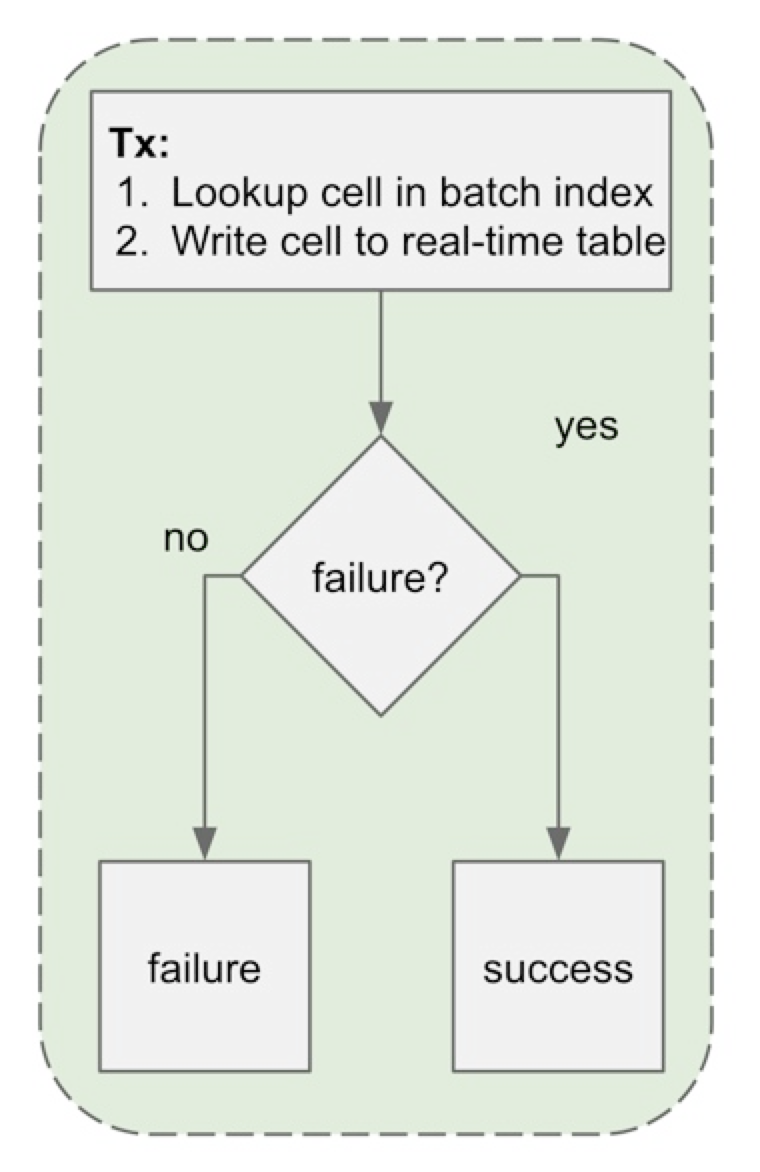
写入
随着数据被分割到两个表中,主键的唯一性不复存在。为了应对这种情况,我们需要扩展写入查询,以检查数据在批处理索引中是否存在,并作为同一事务的一个组成部分。我们发现,由于批处理索引比较小,所以查找的速度很快。下图显示了写入路径的新流程。
上 线
对于 Uber 而言,Schemaless 是一项关键任务,因此,Jellyfish 的上线需要做到绝对完美。为此,上线过程需要通过多个验证阶段,而且最后是分阶段推广到实际的生产实例上。为了保证功能行为的正常,我们对所有新增的和调整过的端点进行了验证,也包括一些边缘情况。此外,为了度量其时间特性,我们还对端点的非功能方面做了微基准测试。我们对启用了 Jellyfish 的测试实例做了宏基准测试,以度量它们在各种工作负载下的性能特性。为了找到吞吐量和延迟之间的关系,我们也进行了压力测试。可以确定,启用 Jellyfish 后,几百毫秒的延迟服务协议是可以满足的。
随着 Jellyfish 准备就绪,我们开始将其推广到生产系统中。Uber 的行程存储系统 Mezzanine 占用的空间特别大。我们对如何分阶段推出 Jellyfish 进行了讨论。
阶段
向生产实例的推广要经历几个阶段,如下图所示。下文大概介绍了我们使用单个分片推广的情况。然后,我们逐步推广到各分片和区域。
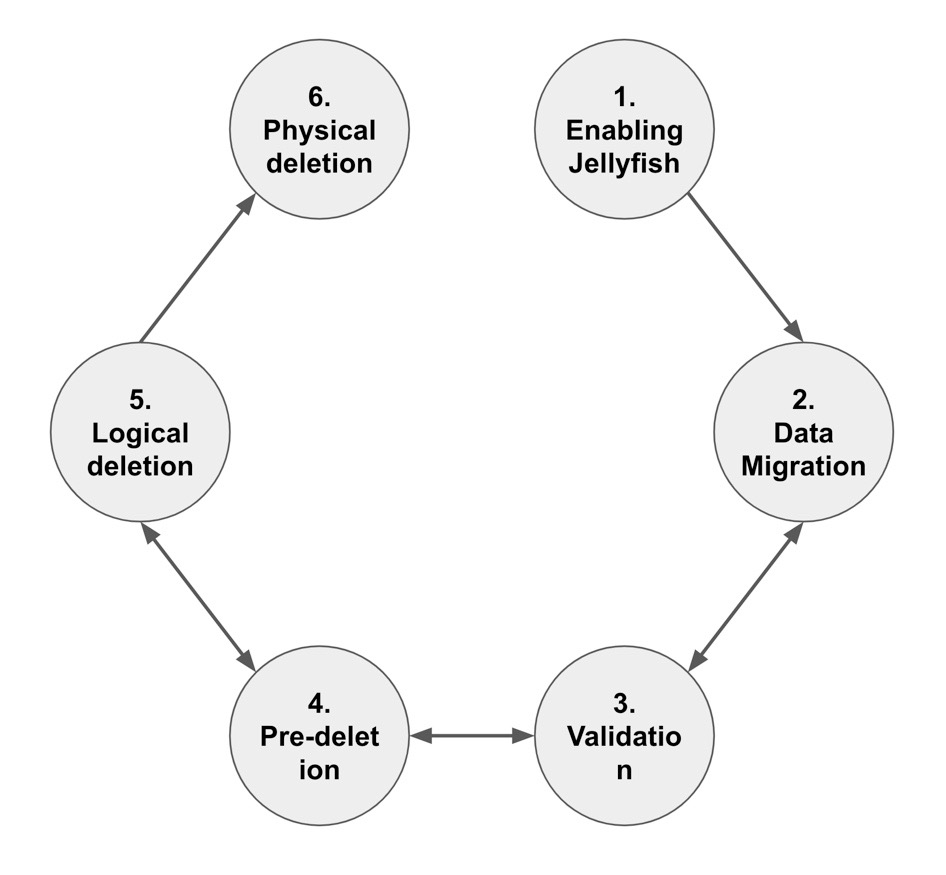
启用 Jellyfish:针对实例配置 Jellyfish 和迁移范围,并允许创建批处理后端。
迁移:从实时后端读取旧数据并将其复制到批处理后端。这个阶段最耗时也最耗资源,并随要迁移的数据量而伸缩。
一致性验证:对发送到实时表的流量做了投影处理,以便可以在批处理后端进行数据验证。它针对请求的旧数据计算摘要,并将其与来自 Jellyfish 的数据进行比较。我们会报告两种类型的一致性:内容和计数。对于成功的迁移,两者都必须为零。
预删除:实际上是逆向投影,只有在一致性达到 100% 时才会启用。请求旧数据的流量实际上是由 Jellyfish 提供的,不过我们仍然从实时后端计算摘要并与之比较。
逻辑删除:会在请求旧数据时关闭实时后端读取路径,因此,也就不再对选择的分片做摘要计算。这个阶段完全模拟了旧数据从实时后端消失的情况。它有助于测试分层逻辑以及数据被真正删除后的新数据流。
物理删除:是在确认逻辑删除成功后真正地删除数据,与之前的阶段不同,这个阶段是不可逆的。此外,不同副本的删除是交错进行的,这样可以确保在遇到意料之外的运行时问题时数据的可用性和业务的连续性。
挑战
对任何正在使用的生产系统做更改都会面临不小的挑战。为了确保数据的安全性和可用性,我们非常谨慎地采用了分阶段的方法。而且,在从一个阶段转入下一个阶段时,我们会确保客户有足够的时间进行监控和测试。
我们面临的一项挑战是,有一个特定的服务导致了高负载,该服务主要是搜索旧数据来重新计算摘要。高负载导致了无法接受的延迟,所以我们与正要弃用该管道的客户展开了合作。另一个更严重的挑战是,用户在请求单元格最近有更新的旧数据行时得到的是不完整的数据。我们需要推出一个修复方案,将其从实时后端和批量后端返回的结果合并后再返回给用户。第三个挑战和其他数据密集型任务的迁移工作有关,如重建用户定义的索引和回填(backfill)作业。
我们得到的启示是,生产环境总是会向我们提出一些挑战,不仅会影响项目的时间表,也会影响解决方案的适用性。为了克服这些挑战,我们需要仔细诊断,并与客户密切协作。
优化
在 Jellyfish 项目的整个实施过程中,对于 Jellyfish 会明显改变数据访问模型的部分,我们一直在进行延迟或吞吐量方面的优化,其中包括:
对请求的单元格进行解码:当用户请求一个单元格时,会一次性获取整个批次。我们只对所请求单元格的 JSON 部分进行解码,而不对其他 99 个单元格进行解码。
只删除元数据:当就地删除单元格时(由于 TTL 等原因),我们只从批处理索引中删除该单元格的条目,这样用户就无法访问它了。单元格实际的删除工作是由一个后台作业完成的,该作业通过一个 read-modify-write 操作更新批处理单元格。我们将被删除的单元格的信息存储在一个日志表中,供后台作业使用。这样,我们就避免了在前台运行这个昂贵的操作,在线读 / 写路径就不会受到影响,用户感知到的延迟也会相应降低。
按批次整理更新:当就地更新单元格时,一个批处理单元格可能会多次更新。使用 read-modify-write,更新过程既耗费资源又耗费时间。通过对更新按批次进行分组,我们能够将一个作业的总更新时间降为 1/4。
收获
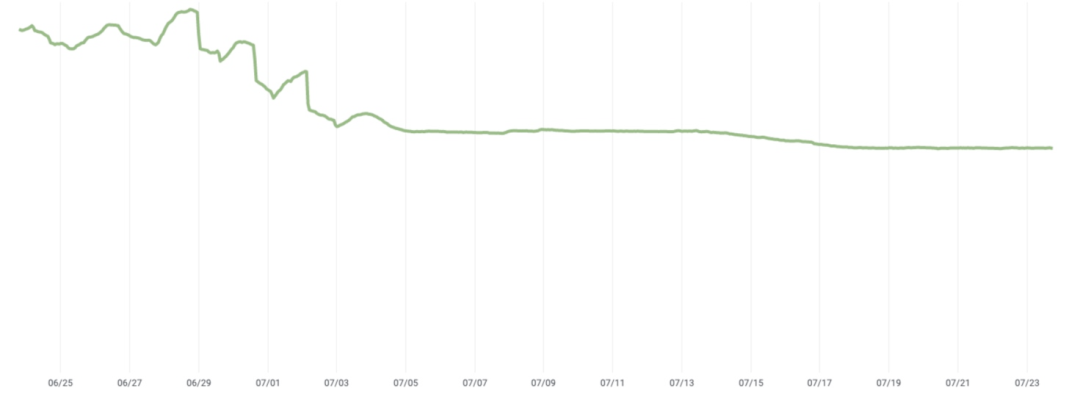
在 Jellyfish 全面推出并确认可以满足我们的要求后,我们就准备开始收获了。为此,我们开始分阶段地从旧的后端中删除数据。下图显示了在开始删除后的几天内,实际占用的存储空间减少的情况。在我们的情况下,Jellyfish 节省了 33% 的存储空间。
未来展望
Jellyfish 项目成功地降低了 Uber 的运营费用,并且未来可以节省更多的存储资源。这里介绍的分层概念可以通过多种方式进行扩展,进一步提高效率并降低成本。我们正考虑将 Jellyfish 应用于 Docstore、显式分层以及使用不同的物理层等一些方向上。要实现这一目标,其中一部分工作是向用户开放一套新的 API 用于访问旧数据,并优化不同层级的软件和硬件栈。Uber 非常欢迎有才华的工程师加入这项工作。
查看英文原文:
https://eng.uber.com/jellyfish-cost-effective-data-tiering/

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论