

“异构计算”(Heterogeneous computing),是指在系统中使用不同体系结构的处理器的联合计算方式。在 AI 领域,常见的处理器包括:CPU(X86,Arm,RISC-V 等),GPU,FPGA 和 ASIC。(按照通用性从高到低排序)本文是异构计算系列的第二篇文章,重点介绍机器学习领域涌现的异构加速技术。
机器学习与异构计算
在机器学习领域,异构计算技术的应用是近年来备受产业界和学术界关注的话题。在数据高速增长的背景下,异构计算技术是提升机器学习应用开发流程中“人”与 “机”的效率的重要途经。本文将结合机器学习应用的开发闭环对近期涌现的相关异构加速技术进行介绍。
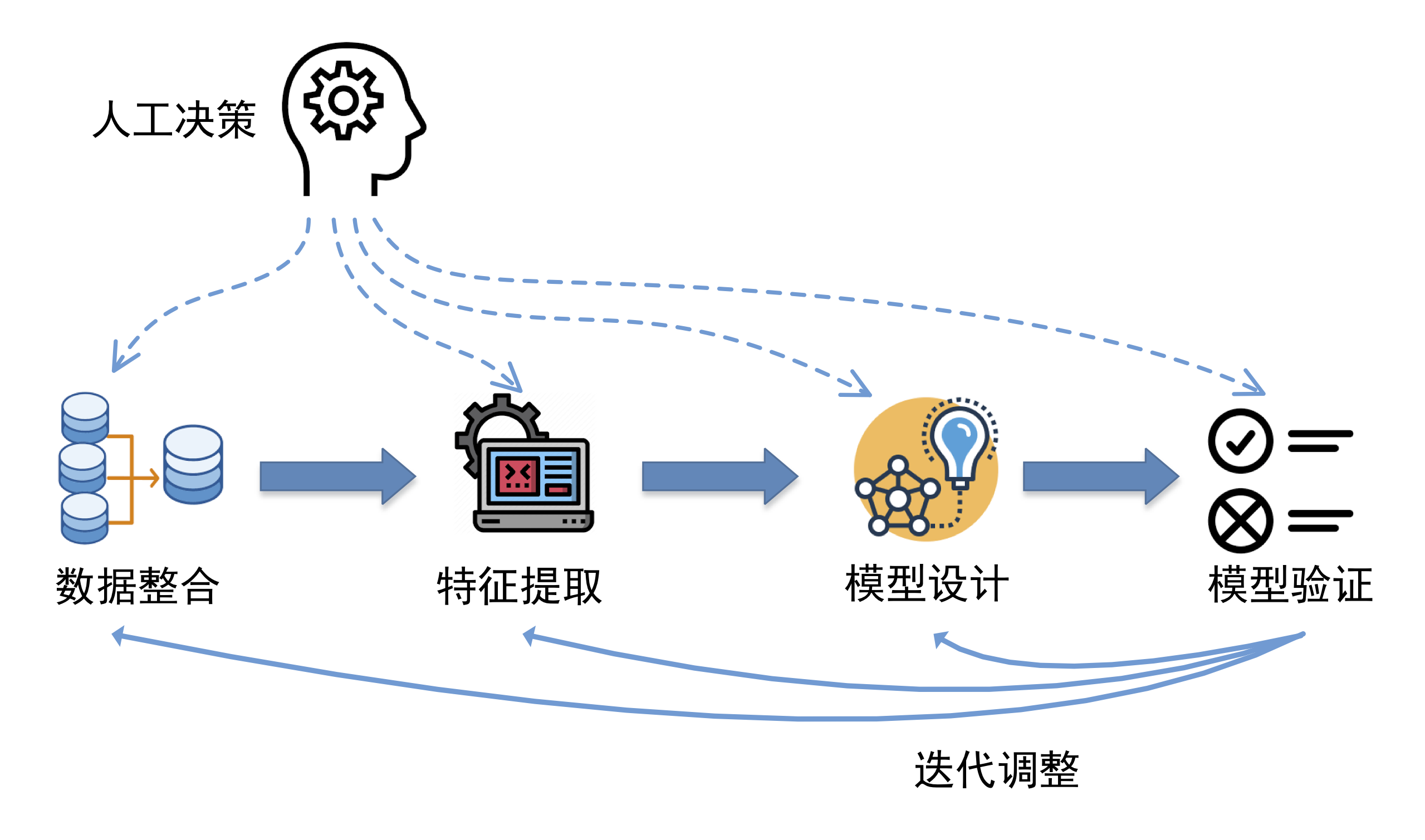
如上图所示,机器学习应用的开发闭环包括数据整合、特征提取、模型的设计、训练和验证等多个环节。首先需要对原始数据进行汇聚整理,然后进行数据分析并提取数据特征作为模型输入。在模型设计环节,需要对模型类型、优化算法和配置参数进行选择。在模型训练完成后,需要数据科学家根据模型验证的结果对上游的各环节进行调整,例如补充新的数据源、扩展数据特征、调整模型的选择和参数设计,然后重新训练和验证模型,直到多次迭代之后得到令人满意的结果。
先谈谈上述流程中的“人”。“有多少人工就有多少智能”这个现象在生产应用中较为普遍。上述流程中存在大量的人工决策环节,需要数据科学家根据专业知识和经验进行合理决策。由于应用场景的多样性,通用的设计通常无法满足各种场景下对机器学习系统的特定需求。数据科学家需要结合实际问题,通过大量的观察分析以及多次的尝试和调优之后才能获得真正合适的设计。随着机器学习理论方法和应用场景的日益丰富,数据科学家正面临着前所未有的决策数量和难度。随着工作难度的增加,人力对机器学习系统开发效率的影响也将逐渐增大,甚至成为整个流程的瓶颈。
再谈谈“机”。从机器效率角度上看,上述迭代过程中涉及到了大量的数据处理和计算操作。例如,在数据整合环节,涉及到多个数据源不同维度大量数据的关联分析和清洗操作。特征提取环节中原始数据的统计特征分析以及特征数据的构造和编码均需要进行大量的浮点运算和矩阵运算。而在模型训练和验证环节会涉及到机器学习模型的训练和推理计算,包含了大量的数值计算、矩阵运算和浮点运算操作。数据的飞速增长使得机器学习应用对计算机系统数据处理的性能要求日益严苛,上述环节的计算效率将直接影响到人工参与效率以及机器学习系统的整体迭代效率。
异构加速技术对“人”与“机”的效率带来了巨大的提升空间。当前的异构加速算法覆盖了数据整合、特征提取、模型训练等环节。与传统的基于 CPU 的算法相比,异构并行算法可获得一到两个数量级的加速,显著提升了机器的运算效率。另一方面,异构加速技术帮助数据科学家更快的获得运算结果,并可有效加速 AutoML 的解空间搜索过程,提高设计与调优效率。
下文将聚焦数据整合、特征提取、模型设计调优、模型训练四个环节,对其中涌现的新兴异构计算技术进行介绍。
数据整合
数据整合处于机器学习开发流程的上游,包括数据源整合,数据提取与数据清洗等工作。由于各应用场景差异较大,数据源与数据类型纷繁复杂,数据整合阶段所涉及的方法与工具相当丰富。其中数据库、数据处理引擎、数据分析程序库扮演了重要角色,分别应对数据汇聚、对接、通用数据处理、定制化数据处理等任务。
数据库方面,ZILLIZ 面向 PostgreSQL 生态推出了 GPU 分析引擎 MegaWise [1][2],阿里巴巴在 AnalyticDB [3] 中提供了 GPU 加速能力,BlazingSQL [4] 基于 RAPIDS [5] 构建了 GPU 加速的 SQL 分析引擎。近期在数据库领域涌现的异构加速技术集中于 AP 方面,这些新型分析引擎对于数据加载、变换、过滤、聚合、连接等特定负载获得了十倍至百倍的加速效果。
数据处理引擎方面,Spark3.0 将引入对 GPU 的调度支持 [6]。此外,在预览版中,也看到 SparkR 以及 SparkSQL 引入了列式处理模式。异构计算资源调度与列式处理这两项内容为 Spark 核心组件的异构加速工作奠定了良好的基础。此外,也为有定制需求的高级用户提供了异构加速 UDF 的条件。
数据分析程序库方面,英伟达推出 cuDF [7]。自 0.10 版本以来,开启了一轮大规模重构,在持续提升底层库性能的同时,对 Python 层的 API 也进行了扩展。截止目前 0.13 版本,逐步完成了一套类 Pandas API。目前接口成熟度可支撑 Pandas 与 cuDF 的协同数据处理。
特定数据类型处理方面,OpenCL 提供了图像处理的 GPU 加速能力 [8],英伟达在 cuStrings [9]项目中提供了面向字符串的 GPU 加速处理函数库,ZILLIZ 在其即将开源的 Arctern 项目中将推出面向地理信息数据处理的 GPU 加速引擎 [10]。
特征提取
特征提取过程对原始数据中的关键信息进行提取并编码成结构化数据,其结果将作为模型的输入数据参与模型的训练和验证过程。特征提取过程涉及的计算操作主要包含数据的特征分析、变换和选取,例如均值、方差、协方差、相关系数等统计特征的计算,归一化、白化等数据变换操作,以及 PCA、SVD 等特征选取操作。上述操作普遍涉及到对大量数据进行相同或相似的处理过程,适合采用异构加速技术提升计算效率。
数据统计特征分析方面,cuDF [11]提供了对最值、期望、方差、峰度、偏度等常用统计量的计算接口。此外,cuDF 还支持 UDF,通过 JIT 技术将 UDF 编译成 cuda kernel 在 GPU 中执行,从而实现用户自定义的数据特征分析。当前该功能相比 pandas UDF 能力较弱,仅支持数值型及布尔型计算。
数据变换方面,英伟达面向高维数据运算发布了 cuPy 项目。该项目使用 ndarray 结构对高维数据进行组织,并在此基础之上提供了大量的异构加速数据运算功能,其中包括傅里叶变换以及线性代数矩阵变换等常用数据变换功能。
特征选取方面,英伟达推出的 cuML 项目提供了一套异构加速的机器学习基础算法库。该项目自 2018 年发布以来持续地扩展对常用的机器学习算法的异构加速支持,当前包含了 SVD、PCA、UMAP、TSNE、Random Projection 等特征成分分析功能。
模型设计与调优
在提取特征之后,数据科学家们需要根据实际的机器学习问题以及训练数据的特征对机器学习模型经行设计和调优。模型设计包括对机器学习模型的类型、模型训练中求解优化问题的算法以及模型参数进行选择。在模型训练完成之后,还需要验证模型的结果准确度,并相应的对模型设计进行迭代调优。在传统的机器学习系统中,该环节完全由人进行决策,其效率严重依赖于数据科学家和算法工程师的专业知识和经验。
为了减少机器学习过程中对人力和专业知识的依赖,近年来学术界和产业界对 AutoML 相关技术投入了大量的关注和尝试。AutoML 致力于自动化完成模型设计,并根据模型验证结果对模型的设计空间进行自动搜索,从而达到近似最优的模型选择和配置。AutoML 减少了机器学习过程中的人工参与,从而有望提高机器学习迭代过程的效率。
当前尚未出现针对 AutoML 的异构加速项目或者算法库。然而,不论是人工还是自动化的模型设计都需要对模型的训练和验证过程进行大量迭代,在这方面异构计算技术已经被普遍用于计算过程的加速。
模型训练
机器学习的模型训练部分存在大量的运算密集型任务,其运算负载不仅取决于算法逻辑,也取决于训练集、数据集的量。随着数据的爆炸式增长,模型训练的任务负载也显著提升,传统的基于 CPU 的方案在性能、设备成本、能耗等几个方面迎来较大挑战。因此,异构加速技术成为解决上述挑战的重要途径,更高的模型训练速度也将直接提高模型迭代中人工环节的参与效率。
数据集处理方面,cuML 提供了 train_test_split,与 sklearn 中的接口行为类似,用于划分训练集和测试集。
算法方面,cuML 提供了一套 GPU 加速的 ML 算法包。在当前 0.13 版本中,常用算法如 linear regression, SGD, random forest, SVM, k-means 等都有涵盖,另外还提供了对时间序列预测分析的支持,包括 HoltWinters, kalman filter, ARIMA 三个模型。在早期版本中,受制于显存容量,cuML 对于大模型或大训练集的支持不尽人意。cuML 自 0.9 版本提供多节点/多卡方案(MNMG),当前已有的 MNMG 算法包括:K-means, SVD, PCA,KNN,random forest。
基于树的算法方面,XGBoost 早在 16 年底就开始了算法的 GPU 加速工作,并于 17 年支持多卡。cuML 在近期的版本中也对基于树的算法进行了性能优化 [12],自 0.10 版本提供与 XGBoost GPU 加速算法的对接支持 [13]。
总结与展望
异构计算在机器学习应用的开发闭环中对于提高“人”与“机”的效率展现出巨大潜力,部分库、系统与产品已经应用于生产环境。但异构计算技术在人工智能领域仍处于快速发展期,进一步丰富工具链以及完善与已有生态的整合是异构计算技术加速落地的重要挑战。当前异构计算技术的主要推动力是英伟达等技术巨头,也涌现出一批如 ZILLIZ、Kinetica、OmniSci 等新兴技术团队,主流的计算框架如 Spark 等也逐步提高对异构计算的原生支持。可以预见,异构计算将成为人工智能应用领域的重要技术趋势,在提高产品演进效率、降低设备与人工成本方面发挥至关重要的作用。
相关链接:
[1] MegaWise 简介 https://zilliz.com/cn/docs/megawise_intro
[2] MegaWise 技术初探:面向异构计算的查询优化与编译 https://zhuanlan.zhihu.com/p/100407033
[3] 阿里如何实现海量数据实时分析技术-AnalyticDB https://www.cnblogs.com/barrywxx/p/10141153.html
[4] BlazingSQL https://blazingsql.com/
[5] RAPIDS https://rapids.ai/
[6] Apache Spark 3.0 预览版正式发布,多项重大功能发布 https://www.infoq.cn/article/oBXcj0dre2r3ii415oTr
[7] cuDF https://github.com/rapidsai/cudf
[8] OpenCL https://developer.nvidia.com/opencl
[9] cuString https://github.com/rapidsai/custrings
[10] Arctern https://github.com/zilliztech/arctern
[11] cuPy https://cupy.chainer.org/
[12] Accelerating Random Forests up to 45x using cuML https://medium.com/rapids-ai/accelerating-random-forests-up-to-45x-using-cuml-dfb782a31bea
[13] A New, Official Dask API for XGBoost https://medium.com/rapids-ai/a-new-official-dask-api-for-xgboost-e8b10f3d1eb7
作者简介:
易小萌, ZILLIZ 高级研究员,于 2017 年获得华中科技大学计算机系统结构博士学位,曾加入华为公有云架构设计团队。主要的研究领域为云资源调度和异构资源调度。研究成果在 IEEE Network Magazine、IEEE TON、IEEE ICDCS、ACM TOMPECS 等期刊和会议上发表。
郭人通,华中科技大学计算机软件与理论博士, ZILLIZ 技术总监。主要研究领域为异构计算、缓存系统、分布式系统。研究成果在 USENIX ATC 、 ICS 、 DATE 、 IEEE TPDS 等会议与期刊上发表。曾加入华为云深度学习团队,目前在 ZILLIZ 从事异构数据分析系统的构建工作。
系列文章:

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...










评论