
本期节选自《中国卓越技术团队访谈录》(2023年第二季)。此次我们深入采访了腾讯向量数据库团队,与他们一同探讨了腾讯云向量数据库背后的故事以及他对于向量数据库现在所面临的挑战和未来发展趋势的思考。
在大模型爆火之前,国内向量数据库赛道略显荒芜,市场上独立开发向量数据库的厂商只有个位数。
这是因为向量数据库的应用场景比较单一,大多用于推荐、图搜图等场景中,因此在 AI 技术没有取得突破性进展之前,向量数据库一直不温不火,这种状态直到去年 ChatGPT 问世后才有所改变。
去年 10 月,OpenAI发布了智能聊天机器人 ChatGPT,随后短短几天内注册用户就突破上亿人,一时间,与 AIGC 等大模型相关的技术成为了 VC 眼中炙手可热的投资项目。
从目前 VC 的投资数据来看,投资者对于 AI 的关注点主要有三个:第一个是基础大模型 LLM,第二个是具体某个场景的应用(包括小模型),第三个就是基础模型与应用层之间的中间层(开发者工具和数据库等)。
随着各种 AI 应用诞生,中间层已经成为各大 VC 争抢的投资标的,早期默默无闻的向量数据库一跃成为当下最大的一个热门,各数据库厂商摩拳擦掌都想在这一垂直赛道分一杯羹。机构观点认为,AI 大模型或催生向量数据库应用骤增,向量数据库或迎重要发展机遇。
最近,腾讯云团队也正式发布了专业型向量数据库(Tencent Cloud VectorDB),InfoQ 有幸采访到了腾讯云数据库团队,与他们一同探讨了腾讯云向量数据库背后的故事以及他对于向量数据库现在所面临的挑战和未来发展趋势的思考。
定调数据库,从拥抱开源到发展自研
“走了不少弯路,也踩过很多坑,但最终还是遇见了星辰大海。”
2010 年,腾讯这家千亿巨头还埋头在自家地里辛勤耕耘,QQ 空间等一众应用的爆火,让腾讯的服务器忙得不可开交,为了承接住如此高并发的流量洪潮,腾讯在短短一个月内额外购买了上千台服务器。
但流量不会永远停在峰值上,当流量回落后,闲置的服务器就造成了资源的浪费。
另一方面,应用的爆火也为腾讯下游的小程序和游戏方们带去了巨大的流量,但他们有限的服务器无法承接住如此庞大的流量洪流。
天下苦服务器,久矣,腾讯说,别急,服务器我有。
找上门的生意没有不做的道理,就这样,2011 年左右腾讯开始筹备组建一支十几人的云团队,将内部技术能力以产品和服务的形式对外销售,当时他们做了一个产品,叫 Open Cloud(开放云),这就是后来腾讯云的雏形。
有了一众明星级应用等加持,腾讯云团队的技术实力很快得到了市场的认可,同年年底,腾讯就已经积累了近 3000 家客户。
云计算是一个人力密集型的赛道,需要投入大量人力才能把客户维护好。就这样,为了更好地支持腾讯云业务,腾讯深圳大本营分别在深圳、北京和成都扎了根,随后扩展到了多个城市。
随着 Open Cloud 打磨了云技术的底座,腾讯成立了独立的云计算品牌腾讯云,正式开启了公有云的万里征程。
担任腾讯云数据库副总经理的罗云,就是腾讯云业务团队的创始成员之一。
据罗云介绍,从 2011 年开始做云业务至今,整个团队经历了多次方向上的调整,直到 2017 年看到国产数据库这个大趋势后,成都团队才定下调来主攻数据库赛道。
与很多互联网公司不同的是,腾讯初始的业务发展并未对数据库有过强依赖,腾讯内部没有去 IOE 的过程。
一开始,腾讯云数据库建设主要引入了当时业界较为主流的开源数据库,如 MySQL、Redis、MariaDB、PostgreSQL 等。随后针对云上客户定制需求,腾讯云在数据库中衍生研发了如数据库并行复制、审计日志、在线加字段等核心功能,并计划逐步将以上功能回馈给 MariaDB 和 MySQL 社区。
随着腾讯云数据库积累的客户越来越多,客户的需求越来越定制化且应用场景更加复杂,在业务倒逼之下,从 2012 年开始,腾讯云研发了适配内部业务自研数据库 TDSQL,此后又推出多款自研数据库 TDSQL-C、TBase 等产品。
在习惯了 Oracle、MySQL等国外十分成熟的数据库后,客户对新兴数据库产品的要求很高,既要求高并发、高可用、低延迟等高性能,还要保证数据持久化,因此对团队的技术水平要求极高。
罗云举例称,“在数据库每次热升级时,要做到让用户无感是非常困难的。在断开又重连的过程中,我们的团队能做到秒级别的抖动。因为我们在数据库的内核上做了很多工作,比如做了两层架构,软件的第一层叫 proxy(接入层),下面有 cache(存储层),我们通过一些逻辑使这两层叠加后就可以实现做业务替换时让客户毫无感知。”
为了应对高性能和数据持久化的要求,腾讯内部还 100%自研了 KeeWiDB 数据库,这是一款完全兼容 Redis 协议的新一代分布式 KV 存储数据库,实现了数据的冷热分级,满足业务高性能、持久化、低成本、大规模的四大诉求,这也为后面腾讯自研向量数据库打下了坚实的技术基础。
此外,KeeWiDB 的技术背后,腾讯云与中科大联合撰写的论文 《PLIN: A Persistent Learned Index for Non-Volatile Memory with High Performance and Instant Recovery》 已被数据库国际顶会 VLDB 收录。
两个多月做完一款自研数据库
在大模型浪潮爆发后,腾讯云在一众大厂中抢先发布了自己的向量数据库产品。据悉,整个产品从立项到最终完成产品化仅用了不到 3 个月的时间。
之所以能如此快地推出这款产品,罗云表示,这主要得益于两方面:一个是云团队内部多年的技术积累;另一方面是这个团队中每个人都是能打“硬仗”的好兵。
去年年初,随着 ChatGPT 的爆火,国内“百模大战”趋势日渐明显。腾讯云也在思考从哪个方向找到突破口切入到大模型“军备竞赛”中。随后到了 3 月份,ChatGPT发布了一个叫“Plugin”的插件功能,Plugin 的标准案例中提到向量数据库是大模型产品中必不可少的一个组件。因为当前的大模型都是预训练大模型,它能够学到的数据只是公开数据,更多的企业私有数据和实时数据大模型是学不了的。
既无法学习实时数据,又学不到企业私有数据,这是预训练大模型在时间和空间上的两大限制。基于这个逻辑,大模型一定会需要一个外部的“海马体”,也就是存储组件来存储这些知识。
另一方面,市场上很多做大模型的企业也在向腾讯云团队寻求一款企业级的向量数据库产品。
就这样,在加深了对大模型的探索和对行业有了更清晰的认知后,腾讯云团队认为向量数据库是一个必须要做并且要赶紧做出来的产品。
对齐了需求后,就来到了执行层面。 摆在腾讯云面前的第一个选择就是到底要做什么类型的向量数据库类型,究竟是做插件式还是自研?
出于市场需求侧的压力,腾讯云想快速推出一款产品,所以刚开始也考虑了用 Redis Search 插件式的方案来做产品。但经过调研发现,这种全内存的方案成本太高,这也腾讯云坚定了要做自研的决心。
据腾讯云向量数据库产品负责人邹鹏介绍,腾讯云向量数据库真正立项时间是在 5 月中下旬,随后技术团队就着手调研研发方案了。既然时间如此紧迫,那不如从腾讯的内部项目中考察是否有能够匹配得上的产品,这样是最高效的解决方案。
邹鹏认为,做一款云数据库最核心的两大要素就是管控和内核:管控是指要给数据库做一些功能,把它产品化,就比如数据库的控制台上一系列可操作的功能;内核就是数据库数据层面的东西。
在管控层面,通过多年的技术积累,腾讯云沉淀出了一个比价成熟的云原生管控平台——云巢,这是一款 PaaS on IaaS 方案,自 2019 年上线后一直稳定地为所有腾讯云数据库产品服务。
在内核层面的选择上就要比管控层复杂一些。因为腾讯集团内部有多款数据库内核可供选择,究竟该选择哪一款就是个问题。
经过调研后,腾讯云数据库团队认为,使用规模和体量最大的向量引擎 Olama 是向量数据库内核的最佳选择。
QQ、QQ 空间、腾讯视频、腾讯新闻这些业务场景中都会涉及推荐、搜索等向量技术,也从一定程度上验证了 Olama 的技术实力。此外,Olama 采用了比较前沿的分布式的、Raft 架构设计,这种架构设计逻辑也更偏向于数据库的架构逻辑,且易于维护。更重要的是,Raft 架构在弹性上也设计得非常灵活,它甚至能够做到表级别的资源扩展。
邹鹏称,在和 PCG 团队沟通后,了解到他们也有非常强烈的上云需求,两个团队一拍即合,管控层和内核层全部尘埃落定,这个项目基本上已经完成了大半。
Olama 和云巢都是腾讯集团内部非常成熟的产品,如何高效强执行的将两者融合在一起的过程中还是给团队带来了一些挑战。
整个团队花费时间和精力比较多的工作在接口和协议的处理上。由于 Olama 和云巢此前都是腾讯内部自用的产品,它们接口的一些功能设计无法友好地对外服务,因此需要进行重新设计接口,这是对内核改造最大的一部分工作,也会占用一些新的研发资源并加大在这方面的投入。
经过了两个多月的摸爬滚打后,腾讯云向量数据库现已在官网上线。
要想做出一款好产品,仅有技术上的积累是不够的,背后团队的技术实力也同样重要。
罗云称,“数据库是个比较卷的赛道,没有最卷,只有更卷。在这么短的时间内推出上线一款全新的自研数据库,对团队成员来说是不小的挑战。但好在我们的工程师都是很‘能打’的。”
向量数据库是风口,更是刚需
“专业的向量数据库需要有长时间的积累和投入才能做得出来,但相应的它的天花板也更高。”
AIGC 技术迎来大爆发后,国内外科技公司纷纷推出自家大模型产品,这一波浪潮把向量数据库这一原本没那么火爆的赛道推到了聚光灯下。
向量数据库本质有三种形态:第一种是纯单机向量数据库,它不是分布式的;第二种是在传统数据库上加上一个具备向量检索能力的插件;第三种是独立的、专业的企业级向量数据库。
目前国内的许多企业并没有采用专门的向量数据库,而是在原来传统数据库上增加了一项向量检索能力,也就是上述提到的第二种形态。从表面上看,独立的、专业的向量数据库看起来并不是那么刚需,但事实的确如此吗?
这就要从传统数据库和向量数据库的区别来看了。传统数据库和向量数据库的主要区别在于它们的数据存储方式、数据规模、查询方式和计算密集型。
数据存储方式:传统数据库存储的是结构化数据,而向量数据库存储的是向量数据,即将非结构化数据(如图片、音频、文章等)转换为向量方式来存储。
数据规模:传统关系型数据库的管理数据规模通常为千万级,而向量数据库的需求数据规模则以达到千亿级。
查询方式:传统数据库的查询通常是精确查询,即查询结果要么符合条件要么不符合条件。而向量数据库则使用相似性查找,即查找与查询条件最相似的结果,这需要更高的计算能力。
计算密集型:传统数据库的查询主要是事务处理,而向量数据库的查询则是计算密集型,需要进行大量的向量计算和比较。
总而言之,向量数据库的主要特点是能够高效地存储和查询大规模的向量数据。它通常采用基于向量相似度的查询方式,即根据向量之间的相似度来检索数据。这种查询方式可以用于各种应用场景,例如图像搜索、音乐推荐、文本分类等。维度越高、信息量越大,这些特性都是传统数据库很难做到的。
这种专门用于存储、索引和查询嵌入向量的数据库系统,可以让大模型更高效率的存储和读取知识库,并且以更低的成本进行 finetune(模型微调),还将进一步在 AI Native 应用的演进中扮演重要作用。
目前,大语言模型(LLM)往往包含数十亿个参数,嵌入则广泛作用于这些模型的训练和微调过程,使其获得执行各种 NLP 任务的能力。在 MaaS 业务的训练、推理等场景,向量数据库都非常重要。
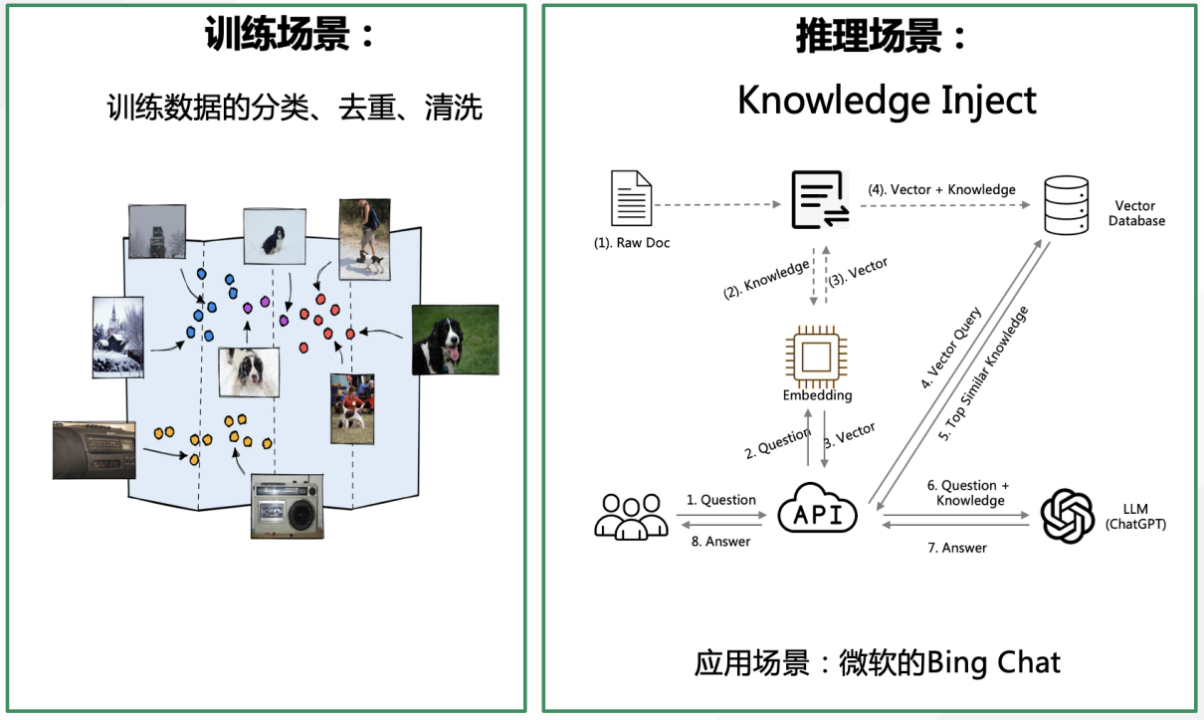
更重要的是,向量数据库可以大幅度拓展大模型的时间边界和空间边界。目前的大模型都是预训练模型,对于训练截止日之后发生的事情一无所知。向量数据库可以通过存储最新信息后给大模型访问来弥补这点不足。
此外,通过向量数据的本地存储,向量数据库能够协助解决目前企业界最担忧的大模型泄露隐私的问题。向量数据库还自带多模态功能,能够实现用中文搜索英语图书、用俄文搜索图片内容等操作,向量数据库的近似搜索能力能够给向量数据库带来巨大的商业化潜力。
在罗云看来,现在我们无法完全笃定地说最终向量数据库会停留在哪个形态上,但他认为第三种形体是可以向下兼容前面两种形态的,只是这种专业的向量数据库需要有长时间的积累和投入才能做得出来。第一个形态它可能边界就在几十万行的下面,第二个形态它可能做到几百万行到亿可能就搞不定了,如果要做到亿到 10 亿的数据规模,就需要专业的企业级分布式向量数据库了。
未来发展趋势展望
虽然去年至今年国内外大模型产品和企业层出不穷,但罗云认为,目前大模型还处于技术发展的初期阶段,相应地,与之相关的技术也处于较早期。以向量数据库技术发展现状来看,向量数据库的发展可以分为三个演进阶段:
第一个阶段,是向量数据库概念的定义和规范阶段。也就是一款数据库它要具备向量数据库所有的特征,在向量存储能力、检索能力上达到向量数据库的要求,能够满足客户的基本需求,才可以称之为向量数据库。
第二个阶段,是向量数据库核心成本优势的竞争阶段。当我们把向量数据库的概念和特征明确后,就要求数据库厂商们“卷起来”了。他们要去真刀真枪地对比谁家的产品成本更低,比如单 QPS 查询需要客户付多少钱、它节省了多少人力和时间成本等。
第三个阶段,是向量数据库的易用性打磨阶段。这个阶段就主要去解决客户“既要又要”的问题了。客户已经不再只要求成本上的降低,还会更加关注数据库性能的极致体验,这也是向量数据库厂商们要大力投入的方向。
目前来看,客户的需求还只是停留在需要一款真正的向量数据库上。
相比于传统数据库,客户在做向量数据库选型时就容易得多,因为应用场景单一,不会涉及太多混合场景需求。罗云称,“在市场侧,国内客户在做数据库选型时更倾向于选择有持久性保障的厂商,客户们会考虑你的服务的可延续性,这个比较重要。”
在技术层面,罗云预判向量数据库未来会朝着与云和云的基础设施结合的发向发展,也就是 AI Native 化的向量数据库。
他进一步解释道:“在向量里面,决定向量数据库核心性能的指标是它的向量检索算法,而这个算法其实比较成熟了。所以当我们要攻破数据库单 QPS 查询成本的时候,就会考虑如何将整个云服务结合 IaaS、容器的核心竞争力都组合在一起去打磨向量数据库,这也是我认为在向量数据库赛道未来云厂商能够跑出来的第一个点”。
此外,随着向量数据库和 AI 的结合更加紧密,客户向量数据库的易用性会有更高要求,这也是刚才罗云提到的第三个发展阶段,有了 AI 和数据库相关技术的积累后,就可以很方便地将这些能力组装进向量数据库里,产生核心竞争力。
采访嘉宾简介:
罗云,腾讯云数据库副总经理
邹鹏,腾讯云向量数据库产品负责人
中国卓越技术团队访谈录(2023 年第二季)深入采访了腾讯、网易伏羲、阿里云、QQ 等技术团队,呈现了这些团队在向量数据库、大模型、前端和研效等方面的技术落地、产品演进和团队建设等方面的多年实践经验和相关心得体会。点击下载电子书,查看更多精彩内容。




