
【编者的话】近年来社交媒体已经越来越流行,可以从中获得大量丰富多彩的信息的同时,也给我们带来了严重的“信息过载”问题。推荐系统作为缓解信息过载的最有效方法之一,在社交媒体中的作用日趋重要。区别于传统的推荐方法,社交媒体中包含大量的用户产生内容,因此在社交媒体中,通过结合传统的个性化的推荐方法,集成各类新的数据、元数据和清晰的用户关系,产生了各种新的推荐技术。本文总结了推荐系统中的几个关键研究领域,进行综述介绍。本文是推荐算法综述的第四部分。第一部分主要介绍了推荐算法的主要类型。第二部分,主要涵盖了不同类型的协同过滤算法,突出他们之间的一些细微差别。第三部分详细介绍了基于内容的过滤算法。在本文中,我们将介绍混合引荐技术,它是建立在我们前面介绍过的算法之上的。我们也将简要讨论针对协同过滤算法(collaborative filtering,CF)和基于内容的过滤方法中存在的不足,可以如何通过融入 item 的流行度来缓解这些局限性。
注:本文翻译自 Building Recommenders ,InfoQ 中文站在获得作者授权的基础上对文章进行了翻译。
正文
本文是推荐算法综述的第四部分。第一部分主要介绍了推荐算法的主要类型。第二部分,主要涵盖了不同类型的协同过滤算法,突出他们之间的一些细微差别。第三部分详细介绍了基于内容的过滤算法。在这篇博客中,我们将介绍混合引荐技术,它是建立在我们前面介绍过的算法之上的。我们也将简要讨论针对协同过滤算法(collaborative filtering,CF)和基于内容的过滤方法中存在的不足,可以如何通过融入 item 的流行度来缓解这些局限性。
混合方法组合了用户和项目内容特征以及用户的历史行为数据,从而从两种数据中提取信息。一个混合推荐系统如果结合了算法 A 和 B,那么它是希望使用算法 A 的优势来解决算法 B 的缺点。例如,协同过滤算法存在新 item 的问题,即它们不能为用户推荐所有用户没有使用过或评分过 item。但这对基于内容的推荐算法来说并不是问题,因为当新的 item 进入系统的时候,基于内容的推荐算法可以基于 item 的内容推荐新的 item 给用户。通过提出一个混合推荐方法,让其组合协同过滤算法和基于内容的过滤算法,可以克服单个算法存在的不足,例如冷启动问题和流行度偏差问题。将两种基本的推荐技术进行组合形成一个混合推荐系统存在不同的方式,我们对此进行了概括,如表 1 所示。
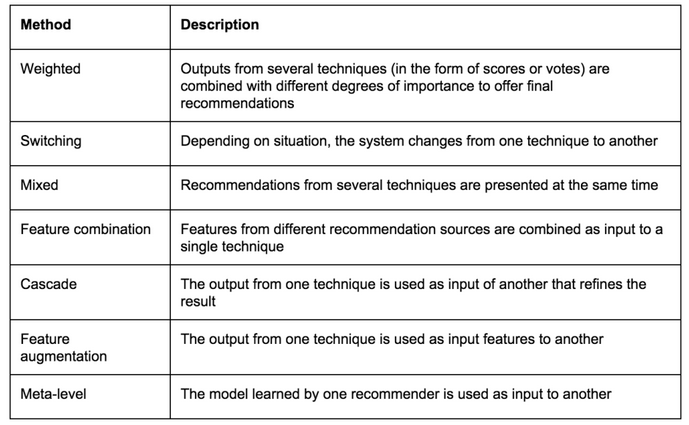
表 1:将两种基本的推荐技术进行组合形成一个混合推荐系统的不同方式。
举个例子,假设有一些用户表达过对于一系列书籍的偏好。他们越喜欢一本书,他们对书籍的评分就会越高,通常划分为从 1 到 5 的 5 个等级。可以将用户对于书籍的偏好表示为一个矩阵,其中行代表用,列表示书籍,如图 1 所示。

图 1:用户对书籍的偏好。所有的偏好都分为 5 个等级,5 表示最喜欢的。第一个用户(行 1)对于第一本书的偏好给出了一个 4 分的评分。如果一个单元格是空的,表示用户对于该书籍的偏好没有给出。
使用相同的设置,我们在第二部分介绍过两个例子,分别展示如何使用基于用户的协同过滤技术和基于 item 的协同过滤技术来对用户产生推荐,并在第三部分,我们展示了如何使用基于内容的过滤技术来对用户进行推荐。现在,我们将组合这三种不同的算法来构建一个新的混合推荐系统。我们将使用加权方法(表 1)来组合这几种不同技术的结果,在这种情况下,通过考虑不同结果的重要性(即权重)来产生新的推荐。
让我们选择第一个用户,并为他产生一些推荐。首先,我们从第二部分中提取使用基于用户的协同过滤技术和基于 item 的协同过滤技术(CF)所得到的推荐结果,从第三部分中提取使用基于内容的过滤技术(CB)所得到的推荐结果(图 2)。值得注意的是,在这个小的例子中,即使三种方法的输入相同,但它们为相同用户产生了略微不同的推荐结果。

图 2:分别使用基于用户的协同过滤技术、基于 item 的协同过滤技术和基于内容的过滤技术所产生的推荐结果。
接下来,我们使用一个加权混合推荐系统为给定的用户产生推荐,基于用户的协同过滤的权重为 40%,基于 item 的协同过滤的权重为 30%,基于内容的过滤技术的权重为 30%(图 3)。相比使用单个算法的例子中仅仅向用户推荐两本书,在这个例子中,用户将被推荐所有他们未评分过的三本书。
(点击放大图像)

图3:使用加权混合推荐系统对用户进行推荐。基于用户的协同过滤的权重为40%,基于item 的协同过滤的权重为30%,基于内容的过滤技术的权重为30%。
虽然混合方法解决CF 方法和CB 方法中存在的一些局限性(见表3),但它们同时也需要大量的工作来获取系统中的不同算法之间的平衡。组合单个的推荐算法的另一种技术是集成方法,它需要学习一个函数(即集成器)来确定不同推荐算法组合的权重。值得注意的是,通常集成方法不仅仅结合了不同的算法,同时也组合了基于相同算法的不同变种(模型)。例如,在赢得Netflix 竞赛的解决方案中,研究者使用了来自于超过10 种不同算法(流行度、领域方法、矩阵因子分解、受限玻尔兹曼机、回归等)的100 多种模型,并通过使用梯度boosted 决策树将它们组合到一个集成器中。
值得补充的是,基于流行度的方法对于新用户的冷启动问题也是一个很好的解决方法。这种方法在对item 进行评分时使用某种形式流行度度量,例如最多的下载次数或购买量,然后向新用户推荐这些受欢迎的item。当你有一个好的流行度度量的时候,这是一个基本的、但功能强大的方法,而且在与其他推荐算法进行比较时提供一个好的基线。在可以切换到其他能够更好地建模用户偏好的方法(协同过滤技术和基于内容的过滤技术)之前,流行度度量本身可以作为一种算法来增强一个推荐系统,以获得足够的活跃度和使用量。流行度的模型也可以组合在混合方法中,以帮助解决推荐系统的新用户冷启动问题。
本文是一篇翻译稿,读者也可以参考英文原文。
编后语
《他山之石》是InfoQ 中文站新推出的一个专栏,精选来自国内外技术社区和个人博客上的技术文章,让更多的读者朋友受益,本栏目转载的内容都经过原作者授权。文章推荐可以发送邮件到editors@cn.infoq.com。
感谢杜小芳对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们,并与我们的编辑和其他读者朋友交流(欢迎加入 InfoQ 读者交流群 (已满),InfoQ 读者交流群(#2))。
(已满),InfoQ 读者交流群(#2))。

暂无签名

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论