
RAG 管道
检索增强生成(RAG)是现代 AI 应用中最有趣的架构模式之一。它不仅仅是技术的演进和趋势,而且是一种范式,使我们能够克服生成式大语言模型(LLMs)的一些主要限制,并有效地将它们集成到现有的业务系统中。
像 OpenAI 这样的 LLMs 在生成连贯、创造性和看似“智能”的文本方面已被证明是强大的。然而,当应用于企业环境时,它们存在一些限制和问题:它们的知识是静态的,仅限于训练数据,有时缺乏与公司内部数据相关的上下文。
在这些场景中,RAG 方法是一种理想的策略:它不是完全依赖于模型的预训练知识,而是将 LLM 的语言生成能力与受控的企业知识库结合起来,受控的企业知识库通常由专有文件、结构化数据集和经过验证的来源提供。
关键思想很简单,但却非常重要。它不是要求模型从过去的训练中发明每一个响应,而是首先经过一个检索阶段,从使用数值嵌入索引的更新公司数据库中搜索相关文档。然后,将这些相关文档提供给生成模型作为生成的上下文,从而提高了准确性、相关性和透明度。
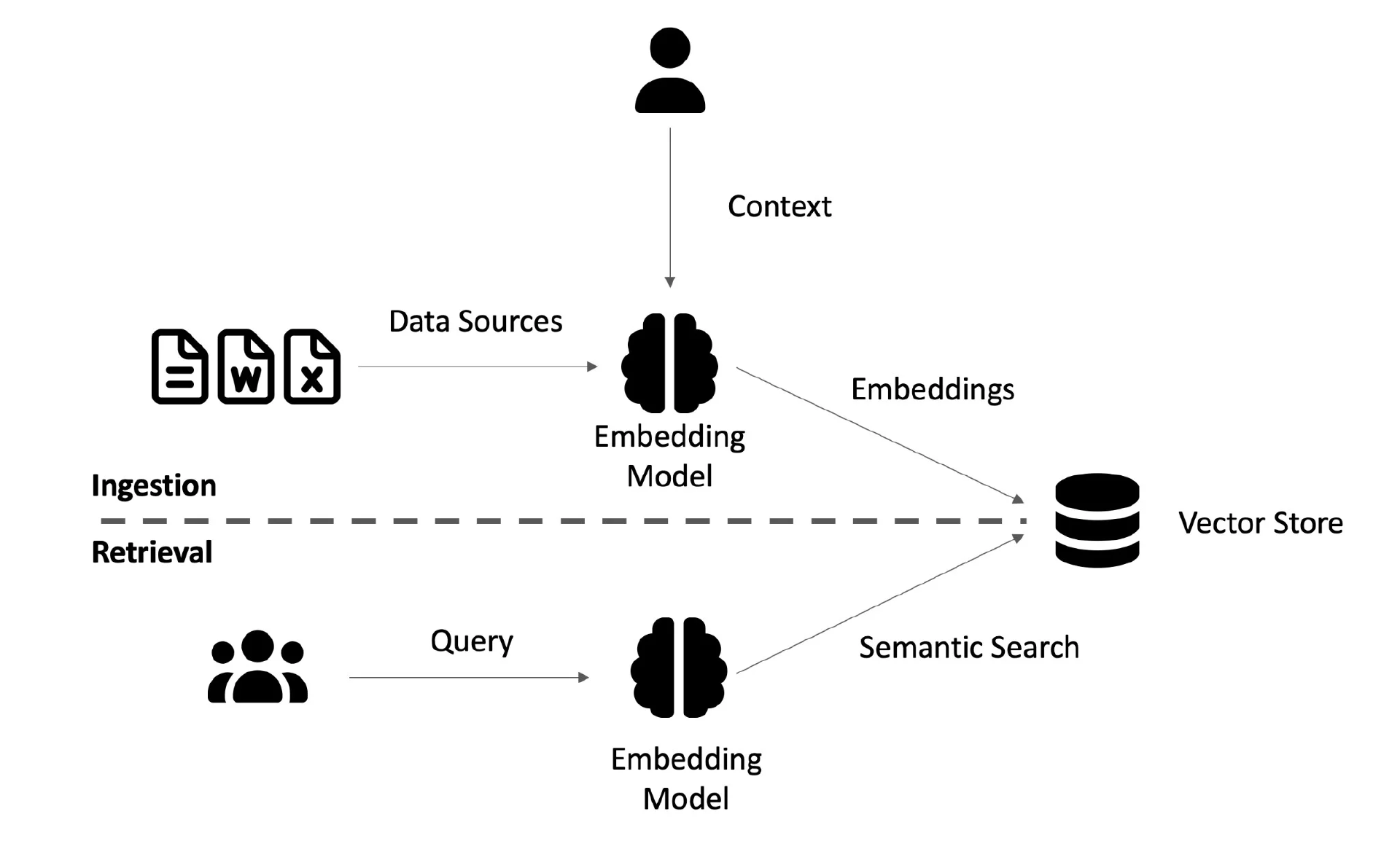
图 1:RAG 管道
这种架构对企业环境特别有吸引力,原因有几个。首先,它避免了在特定专有数据集上微调模型的巨大成本和复杂性,允许集成模块化来源。处理数据检索的引擎可以独立更新和实时查询,从而提供反映数据当前状态的响应。RAG 的模块化特性还允许你保持对数据的控制、安全性和治理,这对于管理敏感信息至关重要。
在本文中,我们将构建一个基于情感的音乐推荐系统原型,利用许多企业公司中常见的技术栈。这个想法是使用一个用例来展示我们如何能够构建一个非常强大和可扩展的系统,利用现有的技能和知识。像 Spring Boot、MongoDB 和 OpenAI 这样的广泛可用技术可以用于这个目的。
Spring Boot + Spring AIRAG 管道的有效性不仅取决于 AI 模型和向量存储的潜力,还取决于解决方案所基于的应用层的健壮性,以及各种必要组件之间集成的质量和简单性。在这种情况下,Spring Boot 和 Spring AI 代表了理想的组合,使你能够编排流程、集成不同的 LLMs,并同时保持可维护性和可扩展性的通用标准。
Spring 框架在 Java 企业生态系统中占据主导地位已经超过 20 年了,展示了独特的演变能力,经常预见市场需求。从作为 EJBs 的“轻量级”替代品的起源,到 Spring Boot 的微服务时代,再到 Spring Cloud 的云原生转型,该框架不断重新定义复杂架构挑战的开发和实施方式。
Spring AI 代表了这种演变的最新、最雄心勃勃的篇章。它不是一个简化和包装对 AI 服务的 API 调用的平凡库,而是一个关于如何将 AI 有机地集成到 Java 生态系统中的新概念。Spring AI 源于这样的认识:在企业环境中采用 AI 不是一个技术问题,而是一个组织和技能问题。公司拥有具有多年 Spring 生态系统经验的 Java 开发团队、成熟的基础设施、运转良好的运维流程以及由于法规和标准而产生的合规约束。要求这些公司完全彻底改革他们的技术栈可能是不现实的,甚至可能是适得其反的。
Spring 的既定模式被应用于 AI 世界。例如,控制反转(IoC)原则成为与多个 AI 提供商合作的基础。在一个项目中,你可以开始使用 OpenAI 进行原型设计,迁移到 Azure OpenAI 以满足合规要求,然后评估像 Hugging Face 这样的本地解决方案,这是一个提供 AI 和自然语言处理工具和预训练模型的开源平台,用于特别敏感的数据。有了 Spring AI,这些变化变成了配置更改,而不是新的实现。嵌入式模型、聊天模型、图像模型和向量存储因此不仅仅是技术抽象,而是允许你以业务逻辑而非集成的方式与 AI 合作的合同,从而腾出时间来创造价值。
图 2:Spring AI 生态系统
MongoDB Atlas 作为向量存储 MongoDB Atlas 中向量搜索的引入代表了 NoSQL 数据库领域最重要的发展之一;它从一个文档数据库转变为一个统一平台,能够同时管理结构化、半结构化和高维向量表示。
传统上,引入 RAG 系统需要在现有企业技术栈中添加新技术:专门的向量数据库,如 Pinecone、Weaviate 或 Chroma。对于已经大量投资 MongoDB 作为主要数据库的组织来说,添加新技术代表了技术和运维开销,需要新的技能、监控和管理生产流程。
在技术层面上,MongoDB Atlas 向量搜索实现了分层可导航小世界(HNSW)算法,这被认为是高维空间中近似最近邻(ANN)搜索的最新技术。选择这个算法并非偶然,而是因为它在准确性、性能和内存消耗之间提供了极好的权衡。
HNSW 索引会在集群的所有节点之间自动共享,实现透明和自动的水平可伸缩性。此外,向量相似性查询可以在单个操作中与传统查询相结合,实现所谓的混合搜索。MongoDB Atlas 支持高达 4096 维的向量嵌入,覆盖了几乎所有目前在生产中使用的模型嵌入。向量以 float32 数组的形式保存,优化以最小化相似性搜索操作期间的存储和带宽。

图 3:MongoDB 向量存储
MongoDB 向量存储的一个特别有趣的方面是,可以在同一个文档中拥有多个向量表示,从而允许实现多模态搜索策略,而无需在对象和/或系统之间进行同步。
OpenAI 聊天和嵌入模型 OpenAI 提供了一系列可用于 RAG 架构的模型,将语义搜索与自然语言生成相结合,以支持开发智能、可扩展和可靠的系统。
嵌入模型旨在将文本转换为能够表达和捕获概念之间语义关系的密集数值向量。这种设计允许基于上下文含义而非仅关键词进行搜索,从而提高结果的相关性和准确性。
OpenAI 目前提供了两个模型:text-embedding-3-small 生成紧凑且轻量级的嵌入,适用于数据量大和具有成本优化要求的场景 text-embedding-3-large 生成更丰富、更准确的嵌入(1536 维),适用于语义相似度要求最高精度的上下文
OpenAI 的对话性 LLM(聊天模型)在生成和细化阶段发挥作用。一旦从向量存储中检索到最相关的文档,选定的模型就会根据请求和使用的数据库生成最终的自然语言响应。OpenAI 提供:gpt-4o-mini 模型优化了速度并降低了成本,是具有大量请求的 RAG 管道的理想选择 gpt-4o 比前一个模型更强大,适用于精度要求更高、推理需求复杂的企业场景 gpt-4-1 模型专为高度复杂的上下文而设计,在这些上下文中,生成质量至关重要
LyricMind:一个音乐 RAG 推荐系统该项目旨在开发一个基于 RAG 的应用程序,使用现代技术栈,结合 Spring Boot、Spring AI、MongoDB Atlas 向量搜索和 OpenAI。
基本思想是构建一个名为 LyricMind 的音乐推荐系统,它接受用户输入(例如,一种感觉或心情)并返回从预加载的知识库中选出的相关文本结果集。在这种情况下,知识库由歌词组成,但该概念适用于任何领域。
该系统由两个主要阶段组成:摄取和嵌入阶段查询和检索阶段
在第一阶段,Spring Boot 应用程序执行大量歌曲上传,包括标题、作者、专辑和歌词(该结构可用于任何类型的文本文档)。通过 Spring AI,每个文档被发送到 OpenAI 嵌入模型,生成密集的数值表示。这个表示,连同原始文本和相关的元数据,存储在 MongoDB Atlas 中。在这里,由于对历史记录和向量搜索的原生支持,每个嵌入都被索引以实现快速高效的语义搜索。
在第二阶段,当用户输入一个用语义术语表达的问题时,它也通过 Spring AI 转换为嵌入。MongoDB Atlas 执行向量相似性搜索以返回与查询相关的最相关文档。这些结果不仅会显示出来,还会传递给生成模型(OpenAI 的聊天模型,在这种情况下由 Spring AI 编排和抽象),该模型执行额外的重新排序和上下文化阶段,从而确保更准确和上下文更丰富的响应。

图 4:LyricMind 的 RAG 管道架构
动手编码现在我们已经介绍了所有成分,让我们尝试将它们混合起来构建一个提供音乐推荐的 RAG 系统。
以下架构将作为参考,展示系统如何工作。
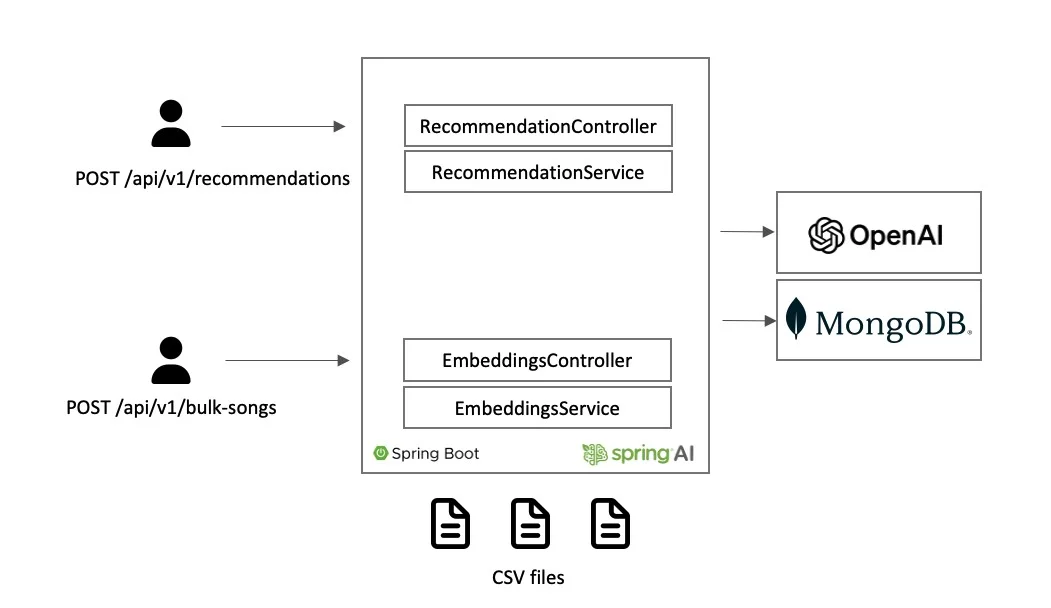
图 5:LyricMind 技术实现
让我们来分析下实现,它将表示分为两个独立的部分:第一部分与嵌入引擎相关,第二部分与音乐推荐引擎相关。
使用了 Spring Boot 3.5.5 和 Java 24。以下依赖对于实现至关重要:
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId></dependency><dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-openai-spring-boot-starter</artifactId></dependency><dependency> <groupId>org.springframework.ai</groupId><artifactId>spring-ai-mongodb-atlas-store-spring-boot-starter</artifactId></dependency><dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-actuator</artifactId></dependency>
依赖
spring-ai-openai-spring-boot-starter用于与 GPT-4o-mini(聊天)和 text-embedding-3-large(嵌入)模型集成spring-ai-mongodb-atlas-store-spring-boot-starter用于持久化和向量搜索spring-boot-starter-actuator用于应用监控和管理
嵌入生成器
在摄取和嵌入阶段,目标是从文本内容生成嵌入,在这个案例中是歌曲。嵌入的生成将遵循以下管道:
从 CSV 文件读取数据集
创建代表每首歌曲的文档并保存在 MongoDB 中
为每首歌曲生成嵌入
保存在向量存储中
表示歌曲的 Song 类如下所示:
@Getter@Setter@NoArgsConstructor@Document(collection = "songs")public class Song { @Id public String id; public String title; public String artist; public String album; public String genre; public String lyrics; public String description; public List<String> tags; public Integer releaseYear; public Song(String title, String artist, String description) { this.title = title; this.artist = artist; this.description = description; }}
而其嵌入由 SongEmbedding 类表示:
@Document(collection = "song_embedding")@Data@NoArgsConstructor@AllArgsConstructorpublic class SongEmbedding { @Id private String id; private String songId; private String content; private List<Double> embedding; private Map<String,Object> metadata;}
在这个类中,我们可以看到嵌入,表示为 List ,是歌曲的向量表示,之后将在此上执行语义相似性搜索。
数据集通过暴露 REST API 读取,如 EmbeddingsController 类中定义的,可以通过指定要读取的 CSV 文件名称来调用。在这种情况下,为了简单起见,一些 CSV 文件已经被直接插入到 src/main/resources 路径中,包含一些著名歌手的歌曲。
@RestController@RequestMapping("/api/lyricmind/v1/embeddings")public class EmbeddingsController { @Autowired SongEmbeddingService songEmbeddingService; @PostMapping("/bulk-songs") ResponseEntity<BulkSongResponse> createEmbeddingFromBulkSong(@RequestBody BulkSongRequest request){ return new ResponseEntity<>(songEmbeddingService.createEmbeddingFromBulkSong(request), HttpStatus.CREATED); }}
一旦 API 被调用,服务层将处理所有业务逻辑,生成歌曲的表示及其向量表示,最后将文档保存在向量存储中。
@Servicepublic class SongEmbeddingService { private final SongRepository songRepository; private final VectorStore vectorStore; private final DatasetGeneratorComponent datasetGeneratorComponent; @Transactional public Integer createEmbeddingFromSongList(List<SongRequest> requestList) { if (requestList == null || requestList.isEmpty()) { throw new IllegalArgumentException("Song request list cannot be null or empty"); } log.info("Starting bulk embedding for {} songs", requestList.size()); List<Song> savedSongs = new ArrayList<>(); List<Document> documents = new ArrayList<>(); try { for (SongRequest request : requestList) { Song song = mapRequestToSong(request); savedSongs.add(song); } savedSongs = songRepository.saveAll(savedSongs); documents = savedSongs.stream() .map(this::createDocumentFromSong) .collect(Collectors.toList()); embedDocuments(documents); log.info("Successfully embedded {} songs", documents.size()); return documents.size(); } catch (Exception e) { log.error("Failed to embed songs in bulk", e); throw new RuntimeException("Bulk embedding failed", e); } }}
在 SongEmbeddingService 类中,有一个名为 createEmbeddingFromSongList() 的方法,首先读取 CSV 文件,每一行被转换为歌曲列表,作为文档保存在 MongoDB 中。然后调用 embedDocuments() 方法,该方法触发对 OpenAI 的调用以向量化内容并保存在 Vector Store 中。所有这些通过 Spring AI 公开的接口操作,对用户来说是透明的。
private final VectorStore vectorStore;private void embedDocuments(List<Document> documents) { try { vectorStore.add(documents); log.debug("Successfully embedded {} documents", documents.size()); } catch (Exception e) { log.error("Failed to embed documents", e); throw new RuntimeException("Vector embedding failed", e); }}
但这一切是如何配置的呢?和任何值得尊敬的 Spring Boot 应用程序一样,所有配置都可以通过属性文件完成,指定要调用的模型以及该模型的特性。在这种情况下:
spring.ai.vectorstore.mongodb.collection-name=lyricmind_vector_storespring.ai.vectorstore.mongodb.initialize-schema=truespring.ai.vectorstore.mongodb.path-name=embeddingspring.ai.vectorstore.mongodb.indexName=lyricmind_vector_indexspring.ai.openai.api-key=<<insert-here>>spring.ai.openai.embedding.options.model=text-embedding-3-large
在这些行中,我们可以看到:
一个 MongoDB 向量存储被配置,它在名为
lyric_mind_vector_store的集合中保存文档,在名为embedding的路径中使用定义的索引来利用语义搜索,该索引名为lyricmind_vector_index。OpenAI 被配置为生成嵌入的提供者,指定了 API 密钥和所需的模型。在这种情况下,我们选择使用
text-embedding-3-large模型。
需要注意的是。在这个实现中,没有提供文本内容分块的机制。在实现 RAG 的项目中,分块(将文本内容分成几个部分,然后生成单独的嵌入)的问题至关重要。当文档非常长并且包含异质概念时(例如,技术手册、法律文件),分块是有用的。在这种情况下,不建议对歌词进行分块。一首歌通常是几行到几百字长。即使在最长的情况下,文本也远低于 OpenAI 嵌入模型支持的 token 限制( text-embedding-3-small 或 text-embedding-3-large 接受高达 8192 个 token 的输入)。此外,在一首歌中,意义是从整体文本中产生的,而不是从孤立的片段中产生的。
最终实现的结果是:两个 MongoDB 集合,一个包含代表处理过的歌曲的原始文档,另一个集合包含代表歌曲嵌入的文档。
{ "_id": "643e8955-a861-4c5a-90b4-fd3fb065b112", "content": "Title: Circles\nArtist: Post Malone\nLyrics: oh oh oh oh oh oh oh oh oh oh oh we couldn't turn around ...", "metadata": { "artist": "Post Malone", "album": "Hollywood’s Bleeding", "genre": "Pop", "title": "Circles", "songId": "68b5915de008fb195e7957d7", "releaseYear": 2019 }, "embedding": [ -0.022942420095205307, -0.01588321290910244, -0.01264774426817894, 0.003707451280206442, -0.001795582938939333, -0.015212862752377987, -0.02701924741268158, -0.002011052798479795, ..... ], "_class": "org.springframework.ai.vectorstore.mongodb.atlas.MongoDBAtlasVectorStore$MongoDBDocument"}
推荐引擎
一旦加载并生成了嵌入,就该创建推荐引擎的核心了。在这种情况下,将公开一个 REST API,该 API 根据心情和推荐数量的限制,为我们提供适合所指示心情的歌曲列表,并解释选择的原因。
步骤如下:
在向量数据库中生成语义查询并搜索具有最高相似性配置文件的文档
查询 LLM 聊天模型以重新对语义搜索结果进行排名,并生成选择的原因
因此,一切都从公开的 API 开始。
@RestController@RequestMapping("/api/lyricmind/v1/recommendations")public class RecommendationController { @Autowired RecommendationService recommendationService; Logger logger = LoggerFactory.getLogger(RecommendationController.class); @PostMapping public ResponseEntity<List<SongRecommendationResponse>> recommendSongs( @RequestBody MusicRequest request) { List<SongRecommendationResponse> recommendations = recommendationService.recommendSongs( request.mood(), request.limit() != null ? request.limit() : 10 ); return ResponseEntity.ok(recommendations); }}
整个推荐引擎的核心位于 RecommendationService 类中。
public List<SongRecommendationResponse> recommendSongs(String mood, int limit) { log.info("Requesting song recommendations for mood: '{}' with limit: {}", mood, limit); try { // Get candidate songs through semantic search List<Document> candidates = findCandidateSongs(mood, limit); if (candidates.isEmpty()) { log.info("No candidate songs found for mood: '{}'", mood); return Collections.emptyList(); } // Re-rank candidates using AI List<Document> rerankedResults = rerankCandidates(mood, candidates); // Map to recommendation responses List<SongRecommendationResponse> recommendations = mapDocumentsToRecommendations(rerankedResults, limit); log.info("Successfully generated {} recommendations for mood: '{}'", recommendations.size(), mood); return recommendations; } catch (Exception e) { log.error("Failed to generate recommendations for mood: '{}'", mood, e); throw new RuntimeException("Recommendation generation failed", e); }}private List<Document> findCandidateSongs(String mood, int limit) { try { // Request more candidates than needed to allow for filtering int candidateLimit = Math.min(limit * 2, MAX_LIMIT); List<Document> candidates = semanticQueryComponent.similaritySearch(mood, candidateLimit); return candidates; } catch (Exception e) { log.error("Failed to find candidate songs for mood: '{}'", mood, e); throw new RuntimeException("Candidate search failed", e); }}private List<Document> rerankCandidates(String mood, List<Document> candidates) { try { List<Document> rerankedResults = rerankComponent.rerank(mood, candidates); return rerankedResults; } catch (Exception e) { log.error("Failed to re-rank candidates for mood: '{}'", mood, e); return candidates; }}
在这个类中,有两个对两个组件的调用,SemanticQueryComponent 和 RerankComponent。
@Componentpublic class SemanticQueryComponent { private final VectorStore vectorStore; private Logger logger = LoggerFactory.getLogger(SemanticQueryComponent.class); public SemanticQueryComponent(VectorStore vectorStore){ this.vectorStore = vectorStore; } public List<Document> similaritySearch(String mood, int limit) { String query = buildSemanticQuery(mood); logger.info("Building semantic query: "+query); SearchRequest searchRequest = SearchRequest.builder() .query(query) .topK(limit*2) .similarityThreshold(0.6) .build(); return vectorStore.similaritySearch(searchRequest); } private String buildSemanticQuery(String mood) { return String.format("Mood: %s. " + "Search for songs that match this mood.", mood); }}
在这个类中,我们组合了要应用于向量存储的语义查询。具体来说:
一个加倍的 topK 值:系统故意检索请求的文档数量的两倍,以允许重新排名有更多的选择。
设置为 0.6 的相似性阈值:一个平衡的值,过滤掉语义上相差太远的结果,同时保持多样性。
查询增强:查询通过额外的上下文进行丰富,以改善搜索。
实现的一个重要方面是定义相似性阈值,设置为 0.6。这个值代表了用户查询和保存在 MongoDB 中的歌曲嵌入之间的语义亲和力的最低水平。实际上,这意味着只有与请求有中高相关性的文本被检索,从而避免包含太远或不相关的结果。较低的值会引入噪声,而过高的值则有过度过滤的风险。因此,选择 0.6 是一个很好的折中:它保证了足够一致的候选集,然后重新排名模型可以对其进行细化,以返回最相关的推荐。
候选文档列表及其相似性阈值被传递给 RerankComponent,该组件调用 OpenAI 的 Chat Model 对歌曲进行重新排名。
public List<Document> rerank(String mood, List<Document> docs) { log.info("Re-ranking {} documents for mood: '{}'", docs.size(), mood); try { // Limit documents to avoid token limits and improve performance List<Document> documentsToRerank = limitDocuments(docs); // Create and execute re-ranking prompt String prompt = buildRerankingPrompt(mood, documentsToRerank); ChatResponse response = executeRerankingQuery(prompt); // Parse and process the response List<Map<String, Object>> ranking = parseRerankingResponse(response); List<Document> rerankedDocs = applyRerankingResults(documentsToRerank, ranking); log.info("Successfully re-ranked {} documents (from {} candidates) for mood: '{}'", rerankedDocs.size(), docs.size(), mood); return rerankedDocs; } catch (Exception e) { log.error("Failed to re-rank documents for mood: '{}'", mood, e); throw new RuntimeException("Document re-ranking failed", e); }}
这里重要的是如何构建查询聊天模型的提示。像任何好的提示一样,你在描述请求时越具体,模型的查询就越有效。在这种情况下:
String.format(""" You are a music recommendation ranking assistant. Rank the following songs based on their semantic relevance to the requested mood. Consider the artist, title, genre, and overall musical style when determining relevance. Provide a brief motivation for each ranking without referencing other songs. Requested Mood: %s Songs to rank: %s Instructions: - Return ONLY a JSON array - Include ALL documents in your response - Sort by relevance (most relevant first) - Score should be between 0.0 and 1.0 - Keep motivations concise (max 100 characters) Expected format: [{"doc_index": 1, "score": 0.95, "motivation": "Upbeat tempo matches energetic mood"}] """, sanitizeInput(mood), documentsText);
与 Chat Model 的交互是如何配置的?答案总是一样的:Spring AI 允许你使用 application.properties 文件中的属性来配置与模型的交互:
spring.ai.openai.api-key=<<insert-here>>spring.ai.openai.chat.options.model=gpt-4o-mini
最后的结果是什么?让我们试着让该服务为我推荐在回想童年时该听什么音乐:
curl --location 'http://localhost:8080/api/lyricmind/v1/recommendations' \--header 'Content-Type: application/json' \--data '{ "mood": "A song that talks about love", "limit": 2 }'
以下是服务的响应:
[ { "title": "I Fall Apart", "artist": "Post Malone", "album": "Stoney", "genre": "Hip-Hop", "releaseYear": 2016, "motivation": "This song is an emotional ballad that recounts the pain of a relationship that has ended. It is considered an anthem for those who have experienced a break-up, thanks to its melancholic melody and direct lyrics." }, { "title": "Circles", "artist": "Post Malone", "album": "Hollywood’s Bleeding", "genre": "Pop", "releaseYear": 2019, "motivation": "Circles tackles the theme of cyclical relationships and the difficulty of letting go of a loved one. The sound is softer and more melodic, with indie-pop influences, and the lyrics reflect on the complexity of love and separation." }]
现实世界中的用例
本文中描述的 RAG 管道处理一个特定的用例,但是所描述的功能恰恰在于其应用于不同业务部门的能力。该设计的核心在于它能够将结构化知识库的检索与语言模型的生成相结合,从而在多个专业环境中找到巨大的范围:
金融和保险,搜索法规、公司政策和监管文件,以回答合规问题或支持财务报告分析。
医疗保健,咨询临床指南、治疗协议和医学研究,以支持临床决策或将患者与试验匹配。
法律,搜索判决、法律条文和合同,以协助律师分析复杂文件和识别关键条款。
客户服务,聊天机器人和帮助台系统,搜索技术手册、内部文件和常见问题解答中的信息,以提高响应时间和支持质量。
教育和培训,基于讲义、教科书和教学材料的智能辅导和问答系统,提供完全个性化的学习体验。
结论
使用 Spring Boot、Spring AI、MongoDB 和 OpenAI 模型创建 RAG 管道,突出了如何将这些技术自然地集成到生态系统和企业架构中。
向量存储的使用允许对结构化知识库进行管理,而嵌入和生成模型允许对这些数据进行语义查询。通过 LLM 增加的重新排序步骤使系统的输出得到进一步加强和上下文化,从而提供与参考领域一致的答案。
所提出的解决方案也适用于其他用例和应用领域,适应不同的数据库和交互模型。
所有代码都可以在这个 GitHub 仓库中找到。
我希望你能对这篇关于用来创建 RAG 管道工具感兴趣,并希望你可以将问题转化为实现机会。
原文链接:
https://www.infoq.com/articles/rag-with-spring-mongo-open-ai/




