

计算机视觉技术是实现自动驾驶的重要部分,美团无人配送团队长期在该领域进行着积极的探索。不久前,高精地图组提出的 CenterMask 图像实例分割算法被 CVPR2020 收录,本文将对该方法进行介绍。
CVPR 的全称是 IEEE Conference on Computer Vision and Pattern Recognition,IEEE 国际计算机视觉与模式识别会议,它和 ICCV、ECCV 并称为计算机视觉领域三大顶会。本届 CVPR 大会共收到 6656 篇投稿,接收 1470 篇,录用率为 22%。
背景
one-stage 实例分割的意义
图像的实例分割是计算机视觉中重要且基础的问题之一,在众多领域具有十分重要的应用,比如:地图要素提取、自动驾驶车辆感知等。不同于目标检测和语义分割,实例分割需要对图像中的每个实例(物体)同时进行定位、分类和分割。从这个角度看,实例分割兼具目标检测和语义分割的特性,因此更具挑战。当前两阶段(two-stage)目标检测网络(Faster R-CNN[2]系列)被广泛用于主流的实例分割算法(如 Mask R-CNN[1])。
2019 年,一阶段(one-stage)无锚点(anchor-free)的目标检测方法迎来了新一轮的爆发,很多优秀的 one-stage 目标检测网络被提出,如 CenterNet[3]、 FCOS[4]等。这一类方法相较于 two-stage 的算法,不依赖预设定的 anchor,直接预测 bounding box 所需的全部信息,如位置、框的大小、类别等,因此具有框架简单灵活,速度快等优点。于是很自然地便会想到,实例分割任务是否也能够采用这种 one-stage anchor-free 的思路来实现更优的速度和精度的平衡?我们的论文分析了该问题中存在的两个难点,并提出 CenterMask 方法予以解决。

图 1. 目标检测,语义分割和实例分割的区别
one-stage 实例分割的难点
相较于 one-stage 目标检测,one-stage 的实例分割更为困难。不同于目标检测用四个角的坐标即可表示物体的 bounding box,实例分割的 mask 的形状和大小都更为灵活,很难用固定大小的向量来表示。从问题本身出发,one-stage 的实例分割主要面临两个难点:
如何区分不同的物体实例,尤其是同一类别下的物体实例。two-stage 的方法利用感兴趣区域(Region of Interest,简称 ROI)限制了单个物体的范围,只需要对 ROI 内部的区域进行分割,大大减轻了其他物体的干扰。而 one-stage 的方法需要直接对图像中的所有物体进行分割。
如何保留像素级的位置信息,这是 two-stage 和 one-stage 的实例分割面临的普遍问题。分割本质上是像素级的任务,物体边缘像素的分割精细程度对最终的效果有较大影响。而现有的实例分割方法大多将固定大小的特征转换到原始物体的大小,或者利用固定个数的点对轮廓进行描述,这些方式都无法较好的保留原始图像的空间信息。
相关工作介绍
遵照目标检测的设定,现有的实例分割方法可大致分为两类:二阶段(two-stage)实例分割方法和一阶段(one-stage)实例分割方法。
two-stage 的实例分割遵循先检测后分割的流程,首先对全图进行目标检测得到 bounding box,然后对 bounding box 内部的区域进行分割,得到每个物体的 mask。two-stage 的方法的主要代表是 Mask R-CNN[1],该方法在 Faster R-CNN[2]的网络上增加了一个 mask 分割的分支,用于对每个感兴趣区域(Region of Interest,简称 ROI)进行分割。而把不同大小的 ROI 映射为同样尺度的 mask 会带来位置精度的损失,因此该方法引入了 RoIAlign 来恢复一定程度的位置信息。PANet[5]通过增强信息在网络中的传播来对 Mask R-CNN 网络进行改进。Mask Scoring R-CNN[6]通过引入对 mask 进行打分的模块来改善分割后 mask 的质量。上述 two-stage 的方法可以取得 SOTA 的效果,但是方法较为复杂且耗时,因此人们也开始积极探索更简单快速的 one-stage 实例分割算法。
现有的 one-stage 实例分割算法可以大致分为两类:基于全局图像的方法和基于局部图像的方法。基于全局的方法首先生成全局的特征图,然后利用一些操作对特征进行组合来得到每个实例的最终 mask。比如,InstanceFCN[7]首先利用全卷积网络[8](FCN)得到包含物体实例相对位置信息的特征图(instance-sensitive score maps),然后利用 assembling module 来输出不同物体的分割结果。YOLACT[9]首先生成全局图像的多张 prototype masks,然后利用针对每个实例生成的 mask coefficients 对 prototype masks 进行组合,作为每个实例的分割结果。基于全局图像的方法能够较好的保留物体的位置信息,实现像素级的特征对齐(pixel-to-pixel alignment),但是当不同物体之间存在相互遮挡(overlap)时表现较差。与此相对应的,基于局部区域的方法直接基于局部的信息输出实例的分割结果。PolarMask[10] 采用轮廓表示不同的实例,通过从物体的中心点发出的射线组成的多边形来描述物体的轮廓,但是含有固定端点个数的多边形不能精准的描述物体的边缘,并且基于轮廓的方法无法很好的表示含有孔洞的物体。TensorMask[11]利用 4D tensor 来表示空间中不同物体的 mask,并且引入了 aligned representation 和 tensor bipyramid 来较好的恢复物体的空间位置细节,但是这些特征对齐的操作使得整个网络比 two-stage 的 Mask R-CNN 还要慢一些。
不同于上述方法,我们提出的 CenterMask 网络,同时包含一个 全局显著图生成分支 和 一个局部形状预测分支 ,能够在实现像素级特征对齐的情况下实现不同物体实例的区分。
CenterMask 介绍
本工作旨在提出一个 one-stage 的图像实例分割算法,不依赖预先设定的 ROI 区域来进行 mask 的预测,这需要模型同时进行图像中物体的定位、分类和分割。为了实现该任务,我们将实例分割拆分为两个平行的子任务,然后将两个子任务得到的结果进行结合,以得到每个实例的最终分割结果。
第一个分支(即 Local Shape 分支)从物体的中心点表示中获取粗糙的形状信息,用于约束不同物体的位置区域以自然地将不同的实例进行区分。第二个分支(即 Global Saliency 分支)对整张图像预测全局的显著图,用于保留准确的位置信息,实现精准的分割。最终,粗糙但 instance-aware 的 local shape 和精细但 instance-unaware 的 global saliency 进行组合,以得到每个物体的分割结果。
1. 网络整体框架
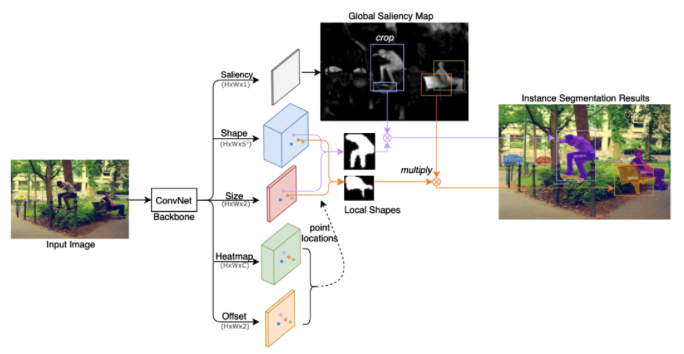
图 2. CenterMask 网络结构图
CenterMask 整体网络结构图如图 2 所示,给定一张输入图像,经过 backbone 网络提取特征之后,网络输出五个平行的分支。其中 Heatmap 和 Offset 分支用于预测所有中心点的位置坐标,坐标的获得遵循关键点预测的一般流程。Shape 和 Size 分支用于预测中心点处的 Local Shape,Saliency 分支用于预测 Global Saliency Map。
可以看到,预测的 Local Shape 含有粗糙但是 instance-aware 的形状信息,而 Global Saliency 含有精细但是 instance-aware 的显著性信息。最终,每个位置点处得到的 Local Shape 和对应位置处的 Global Saliency 进行乘积,以得到最终每个实例的分割结果。Local Shape 和 Global Saliency 分支的细节将在下文介绍。
2. Local Shape 预测
为了区分位于不同位置的实例,我们采用每个实例的中心点来对其 mask 进行建模,中心点的定义是该物体的 bounding box 的中心。一种直观的想法是直接采用物体中心点处提取的图像特征来进行表示,但是固定大小的图像特征难以表示不同大小的物体。因此,我们将物体 mask 的表示拆分为两部分:mask 的形状和 mask 的大小,用固定大小的图像特征表示 mask 的形状,用二维向量表示 mask 的大小(高和宽)。以上两个信息都同时可以由物体中心点的表示得到。
如图 3 所示,P 表示由 backbone 网络提取的图像特征,shape 和 size 表示预测以上两个信息的分支。用 Fshape(大小为 H*W*S*S)表示 shape 分支得到的特征图,Fsize(大小为 H*W*2)表示 size 分支得到的特征图。假设某个物体的中心点位置为(x,y),则该点的 shape 特征为 Fshape(x,y),大小为 1*1*S*S,将其 reshape 成 S*S 大小的二维平面矩阵;该点的 size 特征为 Fsize(x,y),用 h 和 w 表示预测的高度和宽度大小,将上述二维平面矩阵 resize 到 h*w 的大小,即得到了该物体的 LocalShape 表示。
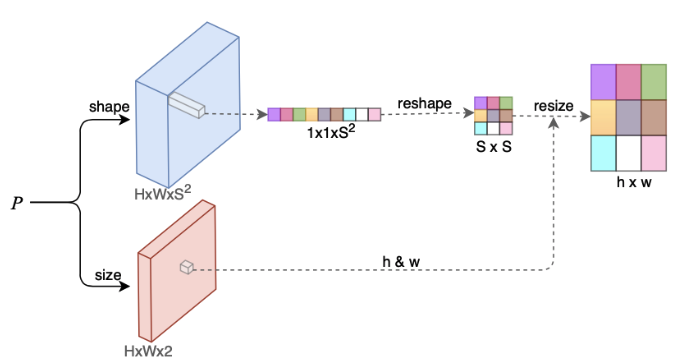
图 3. Local Shape 预测分支
3. Global Saliency 生成
尽管上述 Local Shape 表示可以生成每个实例的 mask,但是由于该 mask 是由固定大小的特征 resize 得到,因此只能描述粗糙的形状信息,不能较好的保留空间位置(尤其是物体边缘处)的细节。
如何从固定大小的特征中得到精细的空间位置信息是实例分割面临的普遍问题,不同于其他采用复杂的特征对齐操作来应对此问题的思路,我们采用了更为简单快速的方法。启发于语义分割领域直接对全图进行精细分割的思路,我们提出预测一张全局大小的显著图来实现特征的对齐。平行于 Local Shape 分支,Global Saliency 分支在 backbone 网络之后预测一张全局的特征图,该特征图用于表示图像中的每个像素是属于前景(物体区域)还是背景区域。
实验结果
1. 可视化结果

图 4. CenterMask 网络不同设定下的分割结果
为了验证本文提出的 Local Shape 和 Global Saliency 两个分支的效果,我们对独立的分支进行了分割结果的可视化,如图 4 所示:
(a) 表示只有 Local Shape 分支网络的输出结果,可以看到,虽然预测的 mask 比较粗糙,但是该分支可以较好的区分出不同的物体。
(b) 表示只有 Global Saliency 分支网络输出的结果,可以看到,在物体之间不存在遮挡的情形下,仅用 Saliency 分支便可实现物体精细的分割。
© 表示在复杂场景下 CenterMask 的表现,从左到右分别为只有 Local Shape 分支,只有 Global Saliency 分支和二者同时存在时 CenterMask 的分割效果。
可以看到,在物体之间存在遮挡时,仅靠 Saliency 分支无法较好的分割,而 Shape 和 Saliency 分支的结合可以同时在精细分割的同时实现不同实例之间的区分。
2. 方法对比
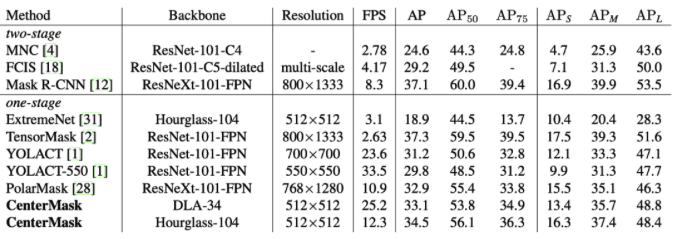
图 5. CenterMask 与其他方法在 COCO test-dev 数据集上的对比
CenterMask 与其他方法在 COCO test-dev 数据集上的精度(AP)和速度(FPS)对比见图 5。其中有两个模型在精度上优于我们的方法:two-stage 的 Mask R-CNN 和 one-stage 的 TensorMask,但是他们的速度分别大约 4fps 和 8fps 慢于我们的方法。除此之外,我们的方法在速度和精度上都优于其他的 one-stage 实例分割算法,实现了在速度和精度上的均衡。CenterMask 和其他方法的可视化效果对比见图 6。

图 6. CenterMask 与其他方法在 COCO 数据集上的可视化对比
除此之外,我们还将提出的 Local Shape 和 Global Saliency 分支迁移至了主流的 one-stage 目标检测网络 FCOS,最终的实验效果见图 7。最好的模型可以实现 38.5 的精度,证明了本方法较好的适用性。
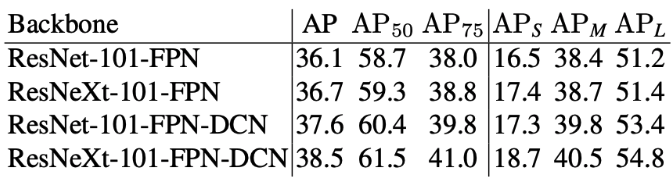
图 7. CenterMask-FCOS 在 COCO test-dev 数据集上的性能
四、未来展望
首先,CenterMask 方法作为我们在 one-stage 实例分割领域的初步尝试,取得了较好的速度和精度的均衡,但是本质上仍未能完全脱离目标检测的影响,未来希望能够探索出不依赖 box crop 的方法,简化整个流程。
其次,由于 CenterMask 预测 Global Saliency 的思想启发自语义分割的思路,而全景分割是同时融合了实例分割和语义分割的任务,未来希望我们的方法在全景分割领域也能有更好的应用,也希望后续有更多同时结合语义分割和实例分割思想的工作被提出。
更多细节内容,参见论文 :CenterMask: single shot instance segmentation with point representation
参考文献
[1] He K, Gkioxari G, Dollár P, et al. Mask r-cnn[C]//Proceedings of the IEEE international conference on computer vision. 2017: 2961-2969.
[2] Ren S, He K, Girshick R, et al. Faster r-cnn: Towards real-time object detection with region proposal networks[C]//Advances in neural information processing systems. 2015: 91-99.
[3] Zhou X, Wang D, Krähenbühl P. Objects as points[J]. arXiv preprint arXiv:1904.07850, 2019.
[4] Tian Z, Shen C, Chen H, et al. Fcos: Fully convolutional one-stage object detection[C]//Proceedings of the IEEE International Conference on Computer Vision. 2019: 9627-9636.
[5] Liu S, Qi L, Qin H, et al. Path aggregation network for instance segmentation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 8759-8768.
[6] Huang Z, Huang L, Gong Y, et al. Mask scoring r-cnn[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019: 6409-6418.
[7] Dai J, He K, Li Y, et al. Instance-sensitive fully convolutional networks[C]//European Conference on Computer Vision. Springer, Cham, 2016: 534-549.
[8] Long J, Shelhamer E, Darrell T. Fully convolutional networks for semantic segmentation[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2015: 3431-3440.
[9] Bolya D, Zhou C, Xiao F, et al. YOLACT: real-time instance segmentation[C]//Proceedings of the IEEE International Conference on Computer Vision. 2019: 9157-9166.
[10] Xie, Enze, et al. “Polarmask: Single shot instance segmentation with polar representation.” //Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2020
[11] Chen, Xinlei, et al. “Tensormask: A foundation for dense object segmentation.” Proceedings of the IEEE International Conference on Computer Vision. 2019.
本文转载自公众号美团技术团队(ID:meituantech)。
原文链接:
https://mp.weixin.qq.com/s/xvvwgxqXrBoXmTKk5Iyizg

腾讯大规模云原生技术实践案例集
本案例集详细阐释了 QQ、腾讯会议、和平精英、小红书、斗鱼、微盟等十多个亿级用户产品背后的大规模云原生...










评论