

本文最初发表于 Medium 博客,经原作者 Jerry Wei 授权,InfoQ 中文站翻译并分享。
ELMo,是来自语言模型的嵌入(Embedding fromLanguageModels)的缩写,这是一种最先进的语言建模思想。是什么让它如此成功?
2018 年发表的论文《深度上下文的词嵌入》(Deep Contextualized Word Embeddings),提出了语言模型嵌入(ELMo)的思想,在问答、情感分析和命名实体提取等多项热门任务上都实现了最先进的性能。事实证明,ELMo 可以带来高达 5% 的性能提升。但是,是什么让这个想法如此具有革命性呢?
ELMo 是什么?
Elmo 不仅仅是一个木偶人物玩具的名字,而且 ELMo 还是一个强大的计算模型,可以将单词转换成数字。这一重要的过程允许机器学习模型(以数字而不是单词作为输入)可以在文本数据上进行训练。
为什么 ELMo 这么厉害?
当我通读原始论文时,有几个主要观点引起了我的注意:
ELMo 解释了单词的上下文。
ELMo 是基于大型文本语料库进行训练的。
ELMo 是开源的。
让我们详细讨论一下这些要点,并讨论它们的重要性。
1. ELMo 可以唯一地解释单词的上下文
像 GloVe、词袋和 Word2Vec 只是根据单词的字面拼写生成嵌入。它们不会考虑单词的使用方式。例如,在下面的示例中,这些语言模型将为“trust”返回相同的嵌入:
I can’ttrustyou.
They have notrustleft for their friend.
He has atrustfund.
然而,ELMo 会根据其周围的单词,返回不同的嵌入:其嵌入是上下文相关的。在这些示例中,它实际上会返回“trust”不同的答案,因为它会识别出该词在不同的上下文中使用。这种独特的能力本质上意味着 ELMo 的嵌入有更多的可用信息,因此性能可能会提高。一种类似的解释上下文的语言建模方法是BERT。
2. ELMo 是基于大型文本语料库训练的
无论你是一名资深的机器学习研究者,还是一名普通的观察者,你都可能熟悉大数据的威力。最初的 ELMo 模型是在 55 亿个单词的语料库上进行训练的,即使是“小”版本也有 10 亿个单词的训练集。这可是一个很大的数据量啊!在如此多数据上进行训练,意味着 ELMo 已经学习了很多语言知识,在大范围的数据集上都会有不错的性能。
3. 任何人都可以使用 ELMo
推动机器学习领域发展的因素是将研究予以开源的文化。通过将代码和数据集开源,研究人员可以让该领域的其他人轻松地应用并构建现有的想法。与这种文化相一致,ELMo 是广泛开源的。它有一个网站,不仅包括它的基本信息,还包括了模型的小版本、中版本和原始版本的下载链接。想使用 EMLo 的人一定要看看这个网站,来获取模型的快速拷贝。此外,该代码还发布在GitHub上,并包括一个相当详尽的自述文件,让用户知道如何使用 ELMo。如果有人花了几个小时的时间才能让 EMLo 模型正常运行,我会感到很惊讶。
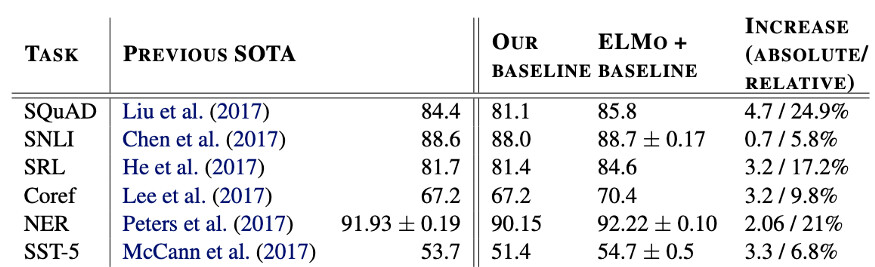
ELMo 在著名的任务上取得了最先进的性能,如 SQuAD、NER 和 SST
作为上下文感知词嵌入和大数据的强大组合,ELMo 在自然语言处理中的大数据集(包括 SQuAD、NER 和 SST)上取得了最先进的性能。ELMo 彻底改变了我们处理计算语言学任务的方式,比如问答和情感检测,这显然是该领域的一个关键进展,因为原始论文已被引用了 4500 多次。此外,在发表 ELMo 的论文后,提交给最大的国际自然语言处理会议——计算语言学协会(Association for Computational Linguistics,ACL)会议收到的投稿量翻了一番,从 2018 年的 1544 份增加到 2019 年的 2905 份(不过这也可能是由于 2019 年初发表的 BERT)。
我还要指出的是,ELMo 和 BERT 非常相似,因为它们都来自芝麻街(译注:Elmo 和 Bert 都是美国经典动画片《芝麻街》的角色)!好吧,它们都是解释单词上下文的语言模型,都是基于大型数据集进行训练的,并且正如给我们所知的自然语言处理领域带来了革命性的变革。我还写了一篇关于 BERT 的博文,如果你有兴趣的话,可以读一读。
ELMo 是自然语言处理最大的进步之一,因为它本质上是第一个关注上下文的语言模型,允许在多种任务中实现更好的性能。
延伸阅读
作者介绍:
Jerry Wei,对人工智能,尤其对医学图像分析和自然语言处理感兴趣。
原文链接:
https://towardsdatascience.com/elmo-why-its-one-of-the-biggest-advancements-in-nlp-7911161d44be

InfoQ 技术编辑

中国卓越技术团队访谈录(2022 年第二季)
本迷你书精选了微软 Edge、蚂蚁可信原生、明源云、文因互联、Babylon.js 等技术团队在技术落地、团队建...











评论