
本文根据才云科技首席大数据科学家郑泽宇在 QCon2016 全球软件开发大会(上海站)上的演讲整理而成,希望大家可以了解如何通过 TensorFlow 实现深度学习算法,并将深度学习运用到企业实践中。
讲师介绍
郑泽宇,谷歌高级工程师。从 2013 年加入谷歌至今,郑泽宇作为主要技术人员参与并领导了多个大数据项目,拥有丰富机器学习、数据挖掘工业界及科研项目经验。2014 年,他提出产品聚类项目用于衔接谷歌购物和谷歌知识图谱(Knowledge Graph)数据,使得知识卡片形式的广告逐步取代传统的产品列表广告,开启了谷歌购物广告在搜索页面投递的新纪元。他于 2013 年 5 月获得美国 Carnegie Mellon University(CMU)大学计算机硕士学位, 期间在顶级国际学术会议上发表数篇学术论文,并获得西贝尔奖学金。
什么是深度学习?
深度学习这个名词听了很多次,它到底是什么东西,它背后的技术其实起源于神经网络。神经网络最早受到人类大脑工作原理的启发,我们知道人的大脑是很复杂的结构,它可以被分为很多区域,比如听觉中心、视觉中心,我在读研究中心的时候,做视频有计算机视觉研究室,做语言有语言所,语音有语音所,不同的功能在学科划分中已经分开了,这个和我们人类对大脑理解多多少少有一些关系。之后科学家发现人类大脑是一个通用的计算模型。
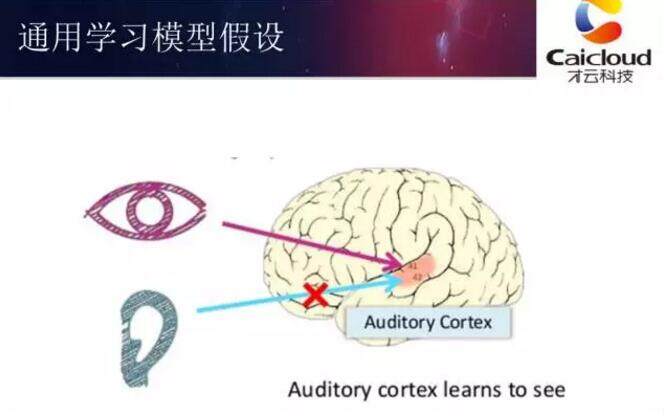
科学家做了这样一个实验,把小白鼠的听觉中心的神经和耳朵通路剪断,视觉输入接到听觉中心上,过了几个月,小白鼠可以通过听觉中心处理视觉信号。这就说明人类大脑工作原理是一样的,神经元工作原理一样,只是需要经过不断的训练。基于这样的假设,神经学家做了这样的尝试,希望给盲人能够带来重新看到世界的希望,他们相当于是把电极接到舌头上,通过摄像机把不同的像素传到舌头上,使得盲人有可能通过舌头看到世界。对人类神经工作原理的进一步理解让我们看到深度学习有望成为一种通用的学习模型。
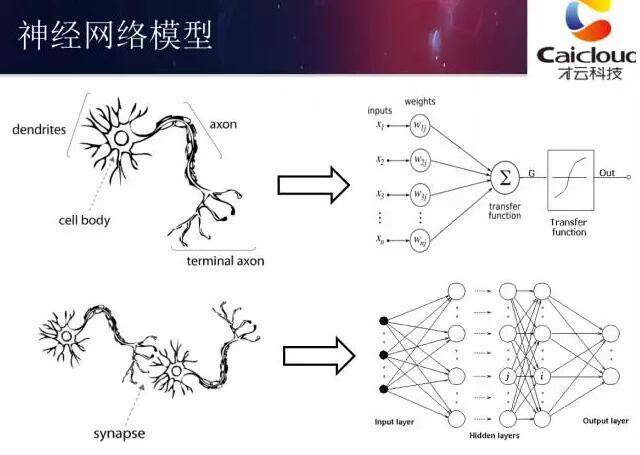
上图给出了神经网络的大致结构。图中左侧是人类的神经元,右侧是神经网络的神经元。神经网络的神经元最早受到了人类神经元结构的启发,并试图模型人类神经元的工作方式。具体的技术这里不做过深的讨论。上图中下侧给出的是人类神经网络和人工神经网络(Artificial Neural Network)的对比,在计算机神经网络中,我们需要明确的定义输入层、输出层。合理的利用人工神经网络的输入输出就可以帮助我们解决实际的问题。
神经网络最核心的工作原理,是要通过给定的输入信号转化为输出信号,使得输出信号能够解决需要解决的问题。比如在完成文本分类问题时,我们需要将文章分为体育或者艺术。那么我们可以将文章中的单词作为输入提供给神经网络,而输出的节点就代表不同的种类。文章应该属于哪一个种类,那么我们希望对应的输出节点的输出值为 1,其他的输出值为 0。通过合理的设置神经网络的结构和训练神经网络中的参数,训练好的神经网络模型就可以帮助我们判断一篇文章应该属于哪一个种类了。
深度学习在图像识别中的应用
深度学习,它最初的应用,在于图像识别。最经典的应用就是 Imagenet 的数据集。
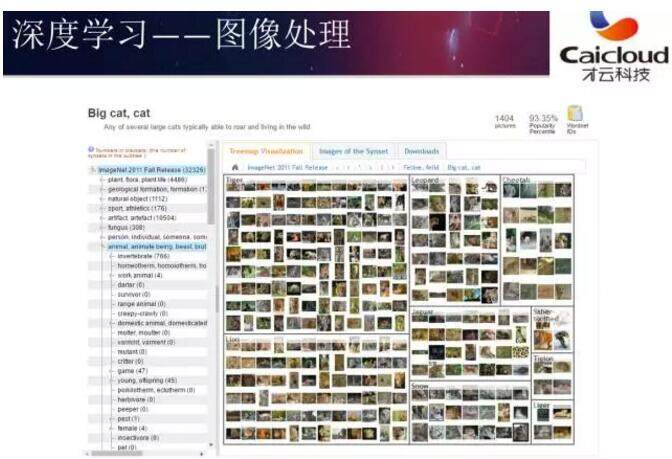
ImageNet 是一个非常大的数据集,它里面有 1500 万张图片。下图展示了数据集中一张样例图片。
在深度学习算法被应用之前,传统的机器学习方法对图像处理的能力有限。在 2012 年之前,最好的机器学习算法能够达到的错误率为 25%,而且已经很难再有新的突破了。在 2012 年时,深度学习首次被应用在在 ImageNet 数据集上,直接将错误率降低到了 16%。在随后的几年中,随着深度学习算法的改进,错误率一直降低到 2016 年的 3.5%。在 ImageNet 数据集上,人类分类的错误率大概为 5.1%。我们可以看到,机器的错误率比人的错误率更低,这是深度学习带来的技术突破。
什么是 TensorFlow
TensorFlow 是谷歌在去年 11 月份开源出来的深度学习框架。开篇我们提到过 AlphaGo,它的开发团队 DeepMind 已经宣布之后的所有系统都将基于 TensorFlow 来实现。TensorFlow 一款非常强大的开源深度学习开源工具。它可以支持手机端、CPU、GPU 以及分布式集群。TensorFlow 在学术界和工业界的应用都非常广泛。在工业界,基于 TensorFlow 开发的谷歌翻译、谷歌 RankBrain 等系统都已经上线。在学术界很多我在 CMU、北大的同学都表示 TensorFlow 是他们实现深度学习算法的首选工具。
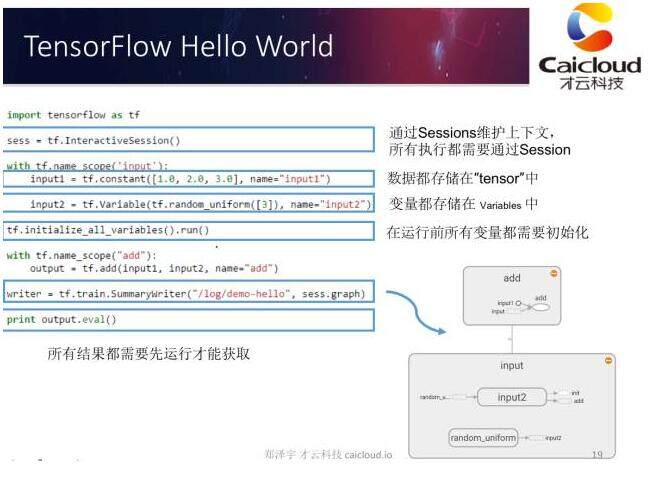
上面的 ppt 给出了一个简单的 TensorFlow 程序样例,这个样例实现了向量加法的功能。TensorFlow 提供了 Python 和 C++ 的 API,但 Python 的 API 更全面,所以大部分 TensorFlow 程序都是通过 Python 实现的。在上面程序的第一行我们通过 import 将 TensorFlow 加载进来。在 TensorFlow 中所有的数据都是通过张量(Tensor)的方式存储,要计算张量中数据的具体取值,我们需要通过一个会话(session)。
上面代码中的第二行展示了如何生成会话。会话管理运行一个 TensorFlow 程序所需要的计算资源。TensorFlow 中一个比较特殊的张量是变量(tf.Variable),在使用变量之前,我们需要明确调用变量初始化的过程。在上面的代码最后一行,我们可以看到要得到结果张量 output 的取值,我们需要明确调用计算张量取值的过程。

通过 TensorFlow 实现神经网络是非常简单的。通过 TFLearn 或者 TensorFlow-Slim 可以在 10 行之内实现 MNIST 手写体数字识别问题。上面的 ppt 展示了 TensorFlow 对于不同神经网络结构的支持,可以看出,TensorFlow 可以在很短的代码内支持各种主要的神经网络结构。
虽然 TensorFlow 可以很快的实现神经网络的功能,不过单机版的 TensorFlow 却很难训练大规模的深层神经网络。

这张图给出了谷歌在 2015 年提出的 Inception-v3 模型。这个模型在 ImageNet 数据集上可以达到 95% 的正确率。然而,这个模型中有 2500 万个参数,分类一张图片需要 50 亿次加法或者乘法运算。即使只是使用这样大规模的神经网络已经需要非常大的计算量了,如果需要训练深层神经网络,那么需要更大的计算量。神经网络的优化比较复杂,没有直接的数学方法求解,需要反复迭代。在单机上要把 Inception-v3 模型训练到 78% 的准确率大概需要 5 个多月的时间。如果要训练到 95% 的正确率需要数年。这对于实际的生产环境是完全无法忍受的。
TensorFlow on Kubernetes
如我们上面所介绍的,在单机环境下是无法训练大型的神经网络的。在谷歌的内部,Google Brain 以及 TensorFlow 都跑在谷歌内部的集群管理系统 Borg 上。我在谷歌电商时,我们使用的商品分类算法就跑在 1 千多台服务器上。在谷歌外,我们可以将 TensorFlow 跑在 Kubernetes 上。在介绍如何将 TensorFlow 跑在 Kubernetes 上之前,我们先来介绍一下如何并行化的训练深度学习的模型。
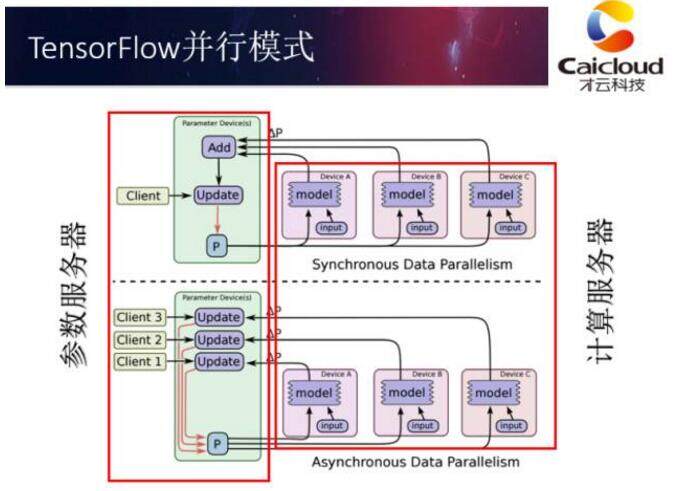
深度学习模型常用的有两种分布式训练方式。一种是同步更新,另一种是异步更新。如上面的 ppt 所示,在同步更新模式下,所有服务器都会统一读取参数的取值,计算参数梯度,最后再统一更新。而在异步更新模式下,不同服务器会自己读取参数,计算梯度并更新参数,而不需要与其他服务器同步。同步更新的最大问题在于,不同服务器需要同步完成所有操作,于是快的服务器需要等待慢的服务器,资源利用率会相对低一些。而异步模式可能会使用陈旧的梯度更新参数导致训练的效果受到影响。不同的更新模式各有优缺点,很难统一的说哪一个更好,需要具体问题具体分析。
无论使用哪种更新方式,使用分布式 TensorFlow 训练深度学习模型需要有两种类型的服务器,一种是参数服务器,一种是计算服务器。参数服务器管理并保存神经网络参数的取值;计算服务器负责计算参数的梯度。
在 TensorFlow 中启动分布式深度学习模型训练任务也有两种模式。一种为 In-graph replication。在这种模式下神经网络的参数会都保存在同一个 TensorFlow 计算图中,只有计算会分配到不同计算服务器。另一种为 Between-graph replication,这种模式下所有的计算服务器也会创建参数,但参数会通过统一的方式分配到参数服务器。因为 In-graph replication 处理海量数据的能力稍弱,所以 Between-graph replication 是一个更加常用的模式。

最后一个问题,我们刚刚提到 TensorFlow 是支持以分布式集群的方式运行的,那么为什么还需要 Kubernetes?如果我们将 TensorFlow 和 Hadoop 系统做一个简单的类比就可以很清楚的解释这个问题。大家都知道 Hadoop 系统主要可以分为 Yarn、HDFS 和 mapreduce 计算框架,那么 TensorFlow 就相当于只是 Hadoop 系统中 Mapreduce 计算框架的部分。
TensorFlow 没有类似 Yarn 的调度系统,也没有类似 HDFS 的存储系统。这就是 Kubernetes 需要解决的部分。Kubernetes 可以提供任务调度、监控、失败重启等功能。没有这些功能,我们很难手工的去每一台机器上启动 TensorFlow 服务器并时时监控任务运行的状态。除此之外,分布式 TensorFlow 目前不支持生命周期管理,结束的训练进程并不会自动关闭,这也需要进行额外的处理。
感谢孟夕对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论