

百度近几年在视频领域做了一些基础技术的研究和积累,这些技术在百度内部有非常多的应用场景,其在面向 C 端和面向 B 端的诸多场景中得到广泛的使用,并取得不错的应用效果。今天将主要介绍百度在不同视频场景下主要运用的关键技术。
百度视频基础技术架构
首先和大家分享下百度视频基础技术架构。

1. 视频研发平台
研发平台方面,百度主要使用飞桨平台,以及在飞桨平台基础上开发的 Paddle CV。飞桨(PaddlePaddle)是以百度多年的深度学习技术研究和业务应用为基础,集深度学习核心训练和推理框架、基础模型库、端到端开发套件和丰富的工具组件于一体深度学习开发平台。
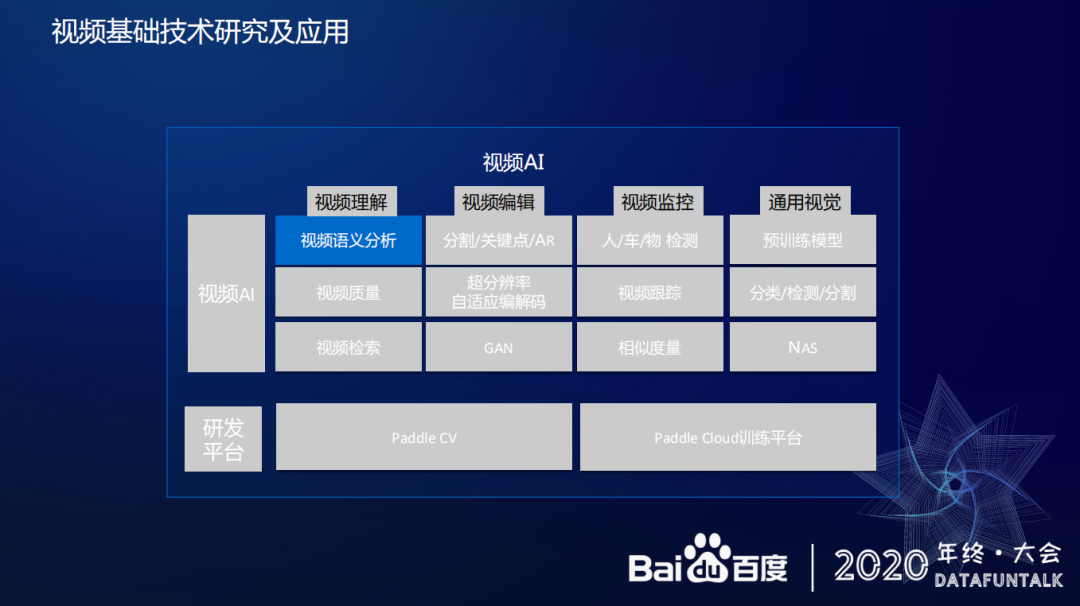
2. 视频 AI 技术
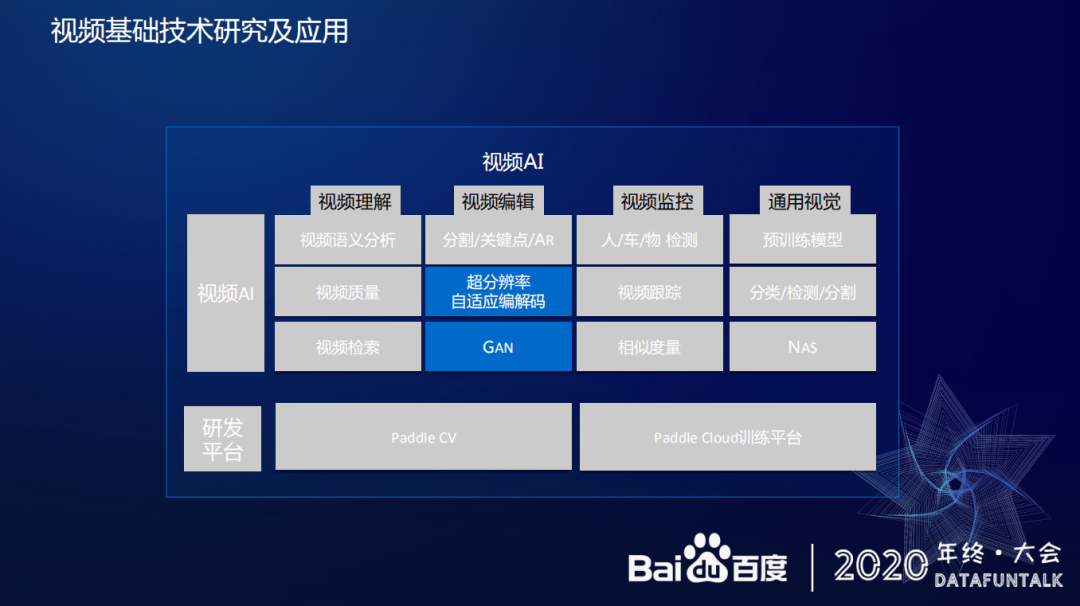
视频 AI 技术方面,主要分为视频理解、视频编辑、视频监控和通用视觉四部分内容。
视频理解:主要包括视频语义分析、视频质量和视频检索技术。主要应用于 1、内容分析,包括视频的内容、文字 OCR 和人脸等内容的分析。2、质量判断,在视频播放分发时对视频质量进行判断,去除低质量视频或者进行质量优化提升。
视频编辑:主要包括分割/关键点/AR、超分辨率、自适应解码和 GAN 技术。主要应用于人像的分割关键点、AR 特效、智能创作和降低视频带宽等方面。
视频监控:主要包括人/车/物检测、视频跟踪和相似度量等技术。主要应用于人车物的检测、人像追踪等方面。
通用视觉:主要包括预训练模型、分类/检测/分割和 NAS 等技术。主要应用于分类检测分割、基于 NAS 搜索更好的网络结构等方面。
百度视频基础技术
1. 视频理解
视频理解将主要介绍视频分类技术点:
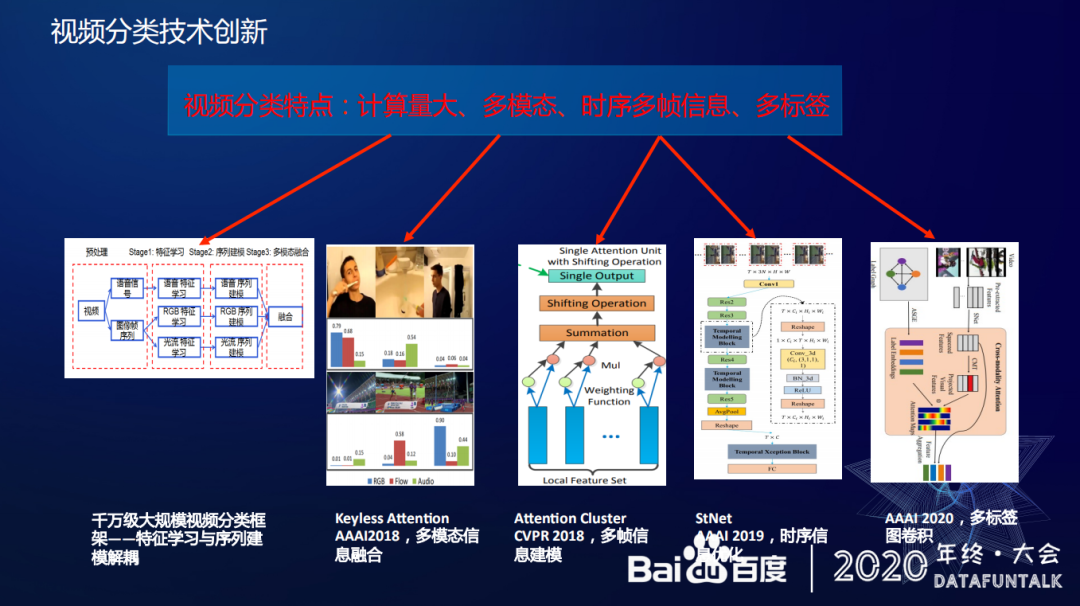
视频分类技术是视频理解中的关键技术之一,视频分类技术和传统的图片分类技术相比有较大的差异,视频分类主要有以下特点:
视频分类的计算量大,在单位时间内有较多的帧。如果一个视频有 30 秒,1 秒有 25 帧,那么对应的图片将可能有几百张,要逐个分析每张照片的标签内容需要较大的计算量。
视频分类需要多模态信息融合,视频不止有图像,还有图像的运动信息和语音信息等等,这将带来多模态信息融合的问题。
视频分类需要如何处理时序多帧问题,即在各帧之间的如何实现时序多帧的建模。
视频分类的标签不唯一,视频具备多标签的特点,可能包括人名、地名、环境和动作等等不同维度的标签。
针对视频分类的以上特点,百度也做了一些创新工作。
针对计算量大的问题,百度专门设计了一个针对大规模视频分类的框架,支持千万级的视频分类工作。
针对多模态信息融合,百度研发了 KeyLess Attention 技术方案。
针对时序多帧信息,百度通过 Attention-Cluster 技术方案,实现多帧信息建模。通过 StNet 实现时序信息优化。
针对多标签,百度通过多标签信息卷积实现多标签标定。
① 注意力聚类网络(Attention-Cluster)
下面将详细介绍一种视频分类的网络结构——注意力聚类网络(Attention-Cluster)

注意力聚类网络的主要思想是:帧间冗余性、局部判别性、近似无序性和多段可分性。
帧间冗余性:
上图中第一排的 4 张图片取自一段打高尔夫球的视频,我们从图中不难看出在挥杆的动作中,不论是看哪一帧我们都能判断这是一个打高尔夫球的视频。因为视频中有比较多重复的视频帧,也就提供了帧间巨大的冗余性。
局部判别性:
上图中第二排的 4 张图取自一段人刷牙的视频,可以看到,我们只看到第一帧时就能判断出刷牙的动作,这样后面几帧很可能是多余的信息,这说明在这段视频里,只要能够找到关键帧就能对分析视频起到事半功倍的效果。
近似无序性和多段可分性:
上图中第三排的 4 张图取自一段人跳高视频,这段视频的时间序列关系是打乱的,但是我们仍可以判断视频内容,说明某些情况下视频存在近似无序性的特点。除此之外,无论是前两张视频截图还是后两张视频截图,我们都能判断这是一个跳高的视频,前面是跳高落地过程,后面是跳高起跳过程,这说明视频中可能有多段信息能够表征视频的类别,这种情况类似于有多个 key 的 keyframe。基于这些思想,可以使用 attention 机制来做识别,即通过筛选机制来捕获类似的 keyframe,就能够实现对关键帧的分析。由于还有多个不同的 keyframe,那么显然就能用 Attention-Cluster 来学习多个不同的特性机制来捕获不同的关键片段,从而优化分类结果。
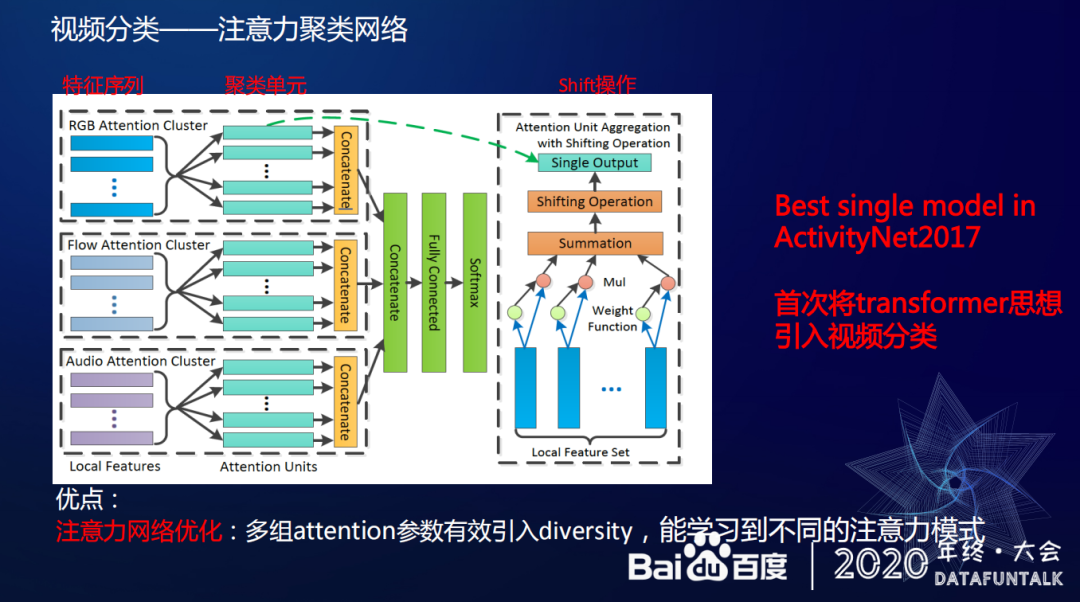
注意力聚类网络的思想类似于 transformer 的思想,注意力聚类网络的主要思想也是引入多个 attention 机制来捕获一些不同的注意内容模型。除此之外,如网络结构图片所示,图中最左边的蓝色条块,表示特征序列。每次我们抽取特征序列,即对蓝色条块输入 sequence 做 attention 操作,每一个青绿色的条块代表一个 attention unit,表示基于一个注意力机制加权后输出的向量,多个青绿色条块,就是代表做过很多 attention unit 操作。最后不同的输出向量会 concat 在一起,除了 RGB,对 Flow 和 Audio 也做同样的操作操作,让他们各自学习各自的注意力特征,最后再拼成一个完成的特征。
注意力网络优化:
那么如何保证用不同的注意力机制去捕获不同的 keyframe 权重的时候,让不同的 attention unit 学习的权重组合是不完全相同的呢?百度提出将这种特征映射到新的空间里去,增加表达性,尽量让 attention unit 学习到多主要推荐参数之间的 diversity,以此来保证注意力机制间的互补性。
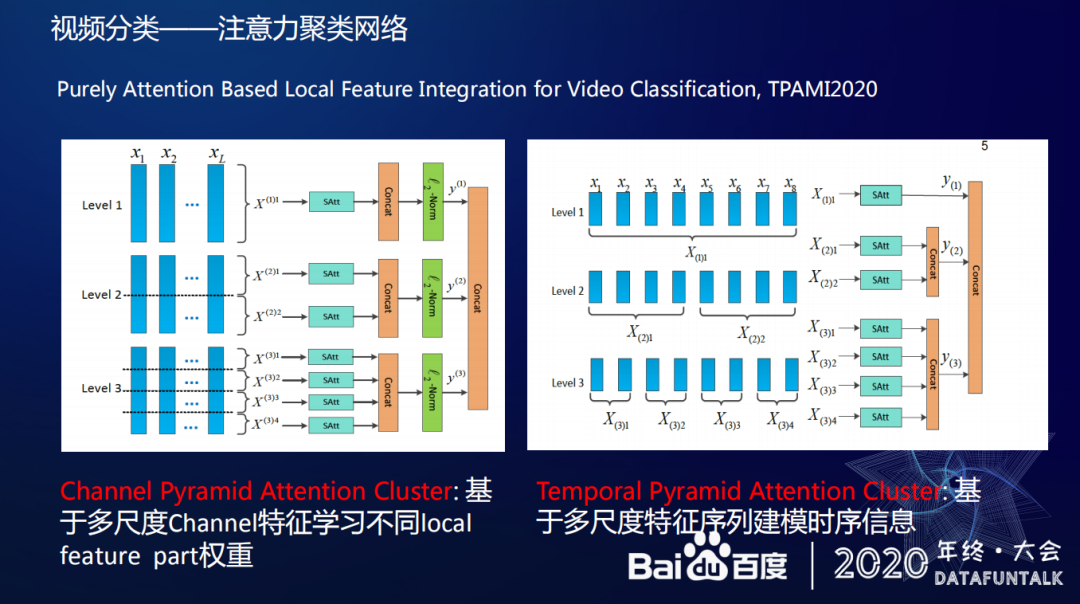
今年百度对注意力聚类网络模型进行了改进,这次改进主要针对两个问题,一是之前没有考虑对每个 Attention 输入图片的时序信息。二是针对每一个 feature channel,之前没有考虑 channel 之间的权重问题。最近对这些问题进行了优化,优化的结果是一个叫 Channel Pyramid Attention Cluster,这个模型可以基于多尺度 channel 特征学习不同 local feature part 权重,即在视频中每一帧的 feature 可以按照金字塔的形式,将其切分成两份、四份或者多份。这样每一个 channel 里的 feature 都有可能学习到不同的 local feature part 权重。以前每个 local feature part 是同样的权重,那么现在切分之后,各个部分各自学习自己的参数,这样 local feature part 就有了多样性。另一个优化结果是 Temporal Pyramid Attention Cluster 即在时序上和上一种优化类似,通过把序列分成一份两份或者多份,在每一个 part 里,都可以使用 Attention Cluster 去学习,但在时序里面,这种拼在一起的顺序,可以增加多尺度特征序列建模时序信息。
具体相关工作可以参考论文:
Purely Attention Based Local Feature Integration For Video Classification,TPAMI2020。
② 跨模态注意力机制+图卷积优化多标签问题
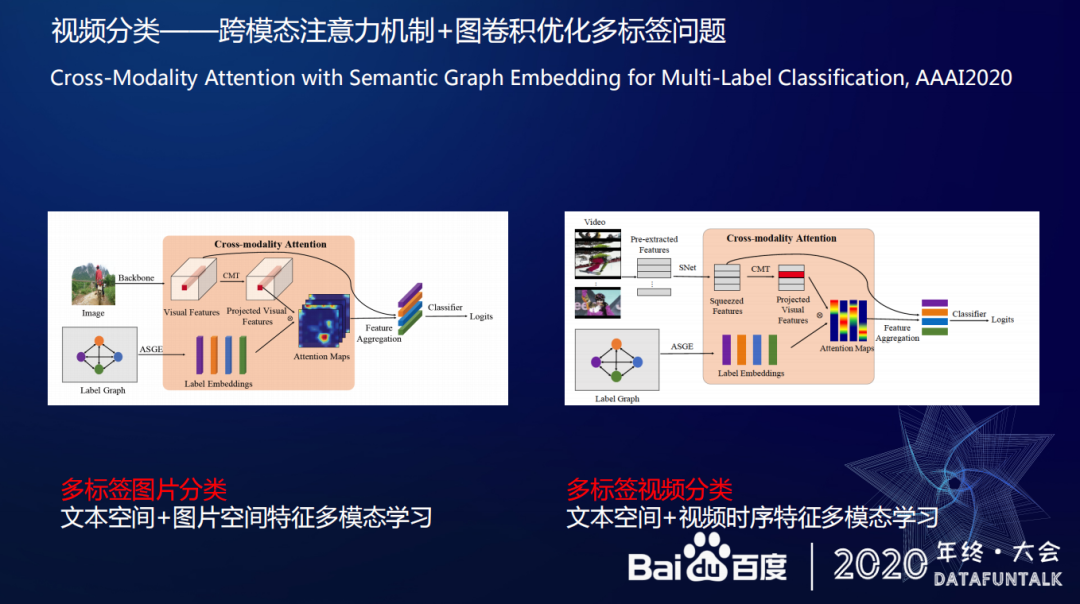
多标签是因为视频分类或者图片分类里含有多个标签信息,那么如何利用多标签信息来优化视频分类结果。针对多标签优化问题,百度提出以下解决思路,通过跨模态注意力机制+图卷积来实现优化工作。上图左边的图片是用跨模态的注意力机制+图卷积来优化图片分类工作,即通过文本空间+图片空间特征实现多模态学习。一个图片可以有多个标签,首先标签之间会有共现信息,比如说很多图片出现了自行车和人,那么自行车和人这两个标签之间的关系就比较近,如果构造一张图,每个节点就是一个标签,他们的边权重可能就比较高。根据共现信息去求每两个节点的一个条件概率,来标识它们之间的相似性,基于此去监督学习文本的 Embedding。在学习图片分类时,可以用 label 的向量和图片的信息做匹配,生成 attention maps,然后用 attention maps 去做一些加权求和特征。最后每个类别就能学习到对应的跨模态特征。以上就是在图片分类中使用跨模态加图卷积识别多标签的思想。视频方面的思路类似,通过文本空间+视频时序特征实现多模态学习,比如在 Youtube-8M 训练集中,每个视频可能有一到多个标签,同样可以采用把视频的标签做一个 label graph 去学习每个 label embedding feature,针对视频将不再采用空间这种 attention 机制,把视频在时序上做卷积,在每个时间片段上,他们都可以跟其他的时间片段去做 attention 机制,在跨模态方面,可以把每个 label 的 feature 和视频的每个 segment 的 feature 做跨模态分析,这会让视频分类效果有比较明显的提升。
具体相关工作可以参考论文:
Cross-Modality Attention with Semantic Graph Embedding for Multi-Label Classification,AAAI2020
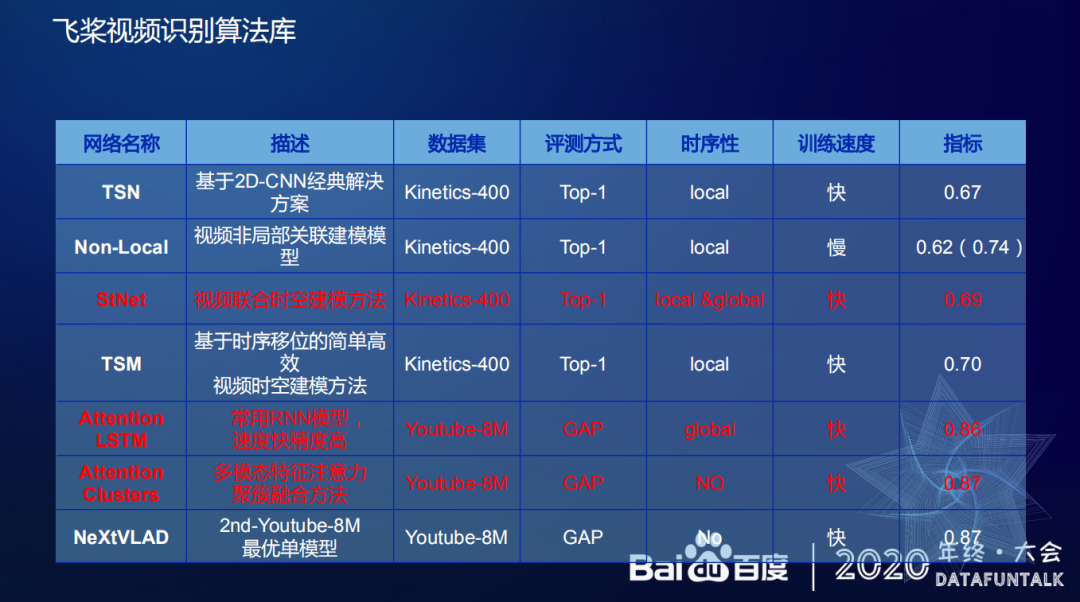
以上识别网络已经在飞桨平台实现开源,有需要的同学可以去飞桨上使用。
2. 视频编辑
视频编辑将主要介绍两个技术点,一是 GAN,二是超分辨率技术,三是自适应编解码技术。

① GAN
生成式对抗网络(GAN, Generative Adversarial Networks )是一种深度学习模型,是近年来复杂分布上无监督学习最具前景的方法之一。
GAN 提供了一种生成高质量数据的方法,在一些场景下,基于 GAN 生成的数据达到了新的高度。
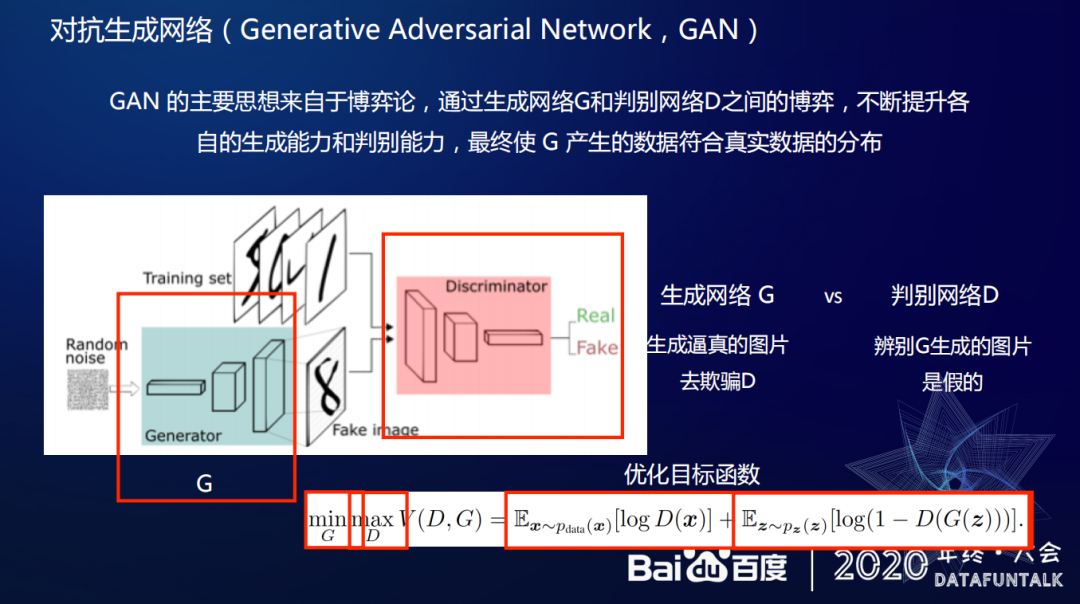
GAN 的主要思想来自于博弈论,通过生成网络 G 和判断网络 D 之间的博弈,不断提升各自的生成能力和判别能力,最终使 G 产生的数据符合真实数据的分布。生成网络具备迭代属性,生成网络 G 每次都会进行生成逼真的图片去欺骗判断网络 D,判断网络 D 也会自主迭代判断生成图片的真伪,当生成网络 G 的生成的图片被判断网络 D 认可,即完成和真实数据分布的匹配工作。
GAN 避免了对数据分布的假设,能够整合各类损失函数,提高了生成效果。
GAN 的重要应用场景-人脸属性编辑。
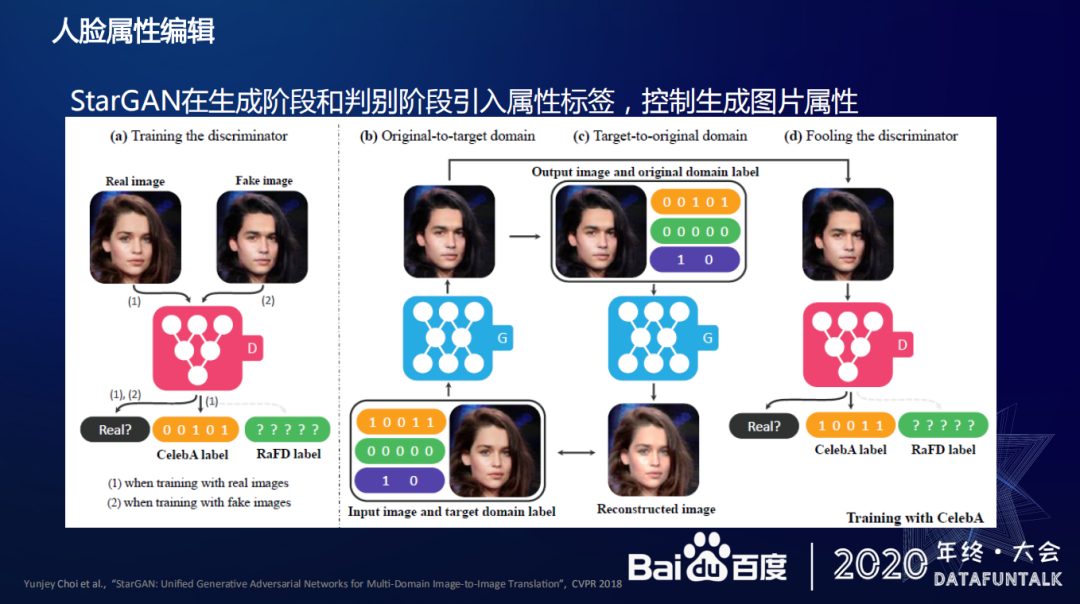
人脸属性编辑使用 StarGAN,StarGAN 在判别图片真伪的同时还要判别图片的属性,输入参数除了原图,还有变化后的图片属性参数。针对生成的结果图片,判别器将判别每一个它生成的图片的属性是否符合我们的预期。除此外,这中间还有一个循环生成的过程,这个过程加上让图片重构的损失尽量小的约束,使我们最终能够有效控制图片生成的属性跟质量。
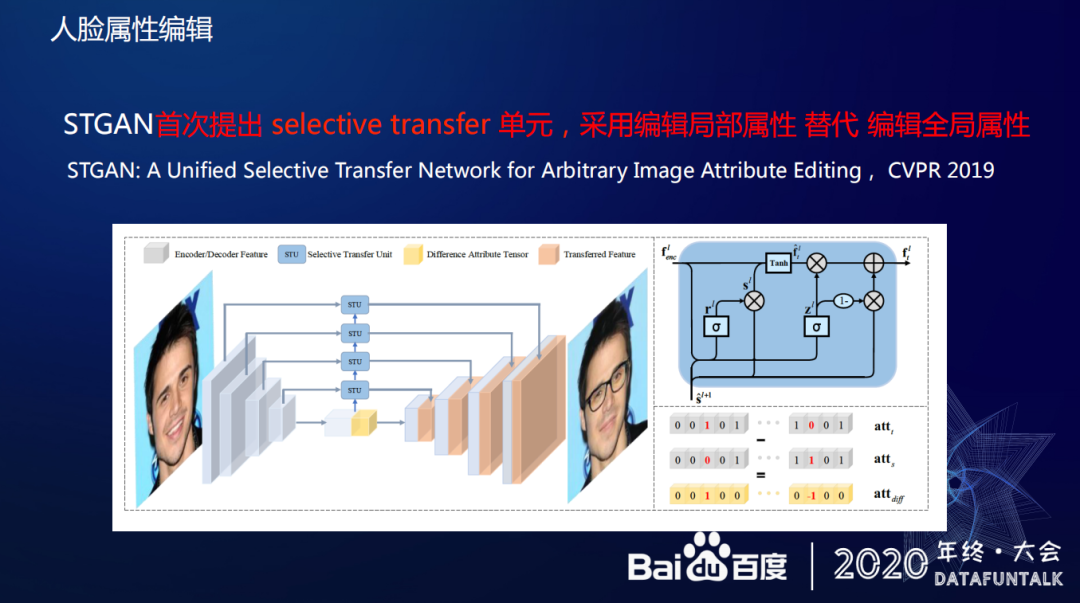
StarGAN 是一个比较经典的网络结构,百度在这方面也做了一些改进工作,这部分工作的主要内容是首次提出 selective transfer 单元,采用编辑局部属性替代全局属性,主要思想是对每个属性进行 0 和 1 的假设,以人脸图片为例,如果人脸面部有 10 个属性,其中 1 个属性代表是否佩戴眼镜,那么就可以通过 0 和 1 来控制这个属性的变化。这篇文章部分思想借鉴了残差网络的思想。即只对需要变化的属性特征置 1,让网络在学习过程中聚焦这些需要改变属性的区域,不需要改变的属性置 0 依然保持不动,这和传统的算法是不一样的,以前需要对整张图片进行重新学习和改变,即网络在学习的时候是没有学习重点的。基于以上思想百度也提出 selective transfer 单元,这个单元能够把深层特征按照想改变的属性牵引,不停的把需要改变的区域的深层特征传到浅层做融合。
具体相关工作可以参考论文:
A Unified Selective Transfer Network for Arbitrary Image Attribute Editing ,CVPR 2019
② 超分辨率技术
在视频中广泛存在超分辨率技术应用需求,超分辨率技术指的是把低分辨率的图片和视频优化为高分辨率图片和视频,优化图片和视频的显示效果。
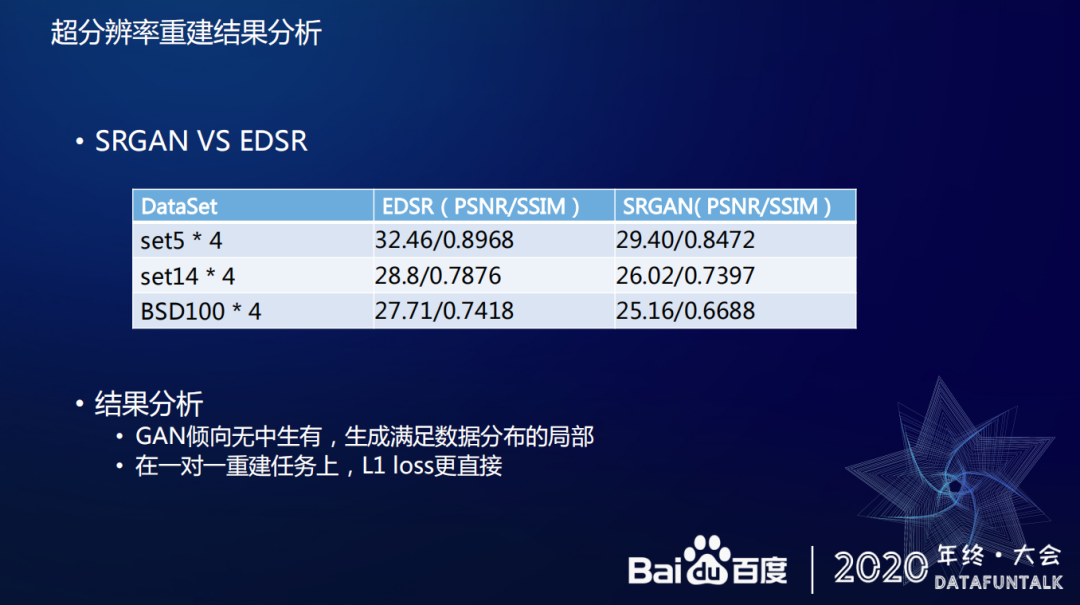
百度也尝试过使用多种不同的算法来实现超分辨率技术,从实际使用效果来看,GAN 的使用效果一般,不如传统算法,GAN 倾向无中生有,生成满足数据分布的局部。在一对一重建任务上,L1loss 更直接,能够更好的保证超分后的效果。
③ 自适应编解码技术
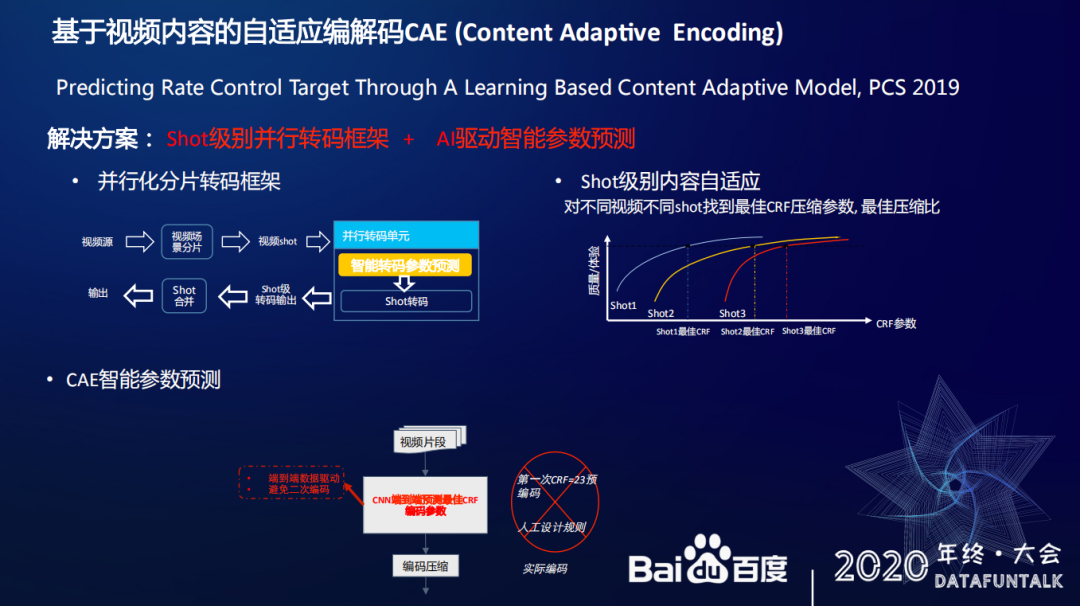
自适应编解码技术主要针对一些带宽成本较高的场景,比如短视频。针对这些场景,确定视频的最佳压缩参数,既保证压缩带宽又保证视频质量的需求十分迫切。百度去年也做了一个基于视频内容自适应编解码的工作,叫做 Content adaptive Encoding。这部分工作的主要思路是先把视频按照 shot 级别进行切割,这样能够有效提高算法并行速度,除此之外,不同的 shot 能根据视频的内容信息以及需要保证的质量寻找最合适的 CRF 压缩参数,确定最佳压缩效果。
具体相关工作可以参考论文:
Predicting Rate Control Target Through A Learning Based Content Adaptive Model,PCS 2019
3. 视频监控
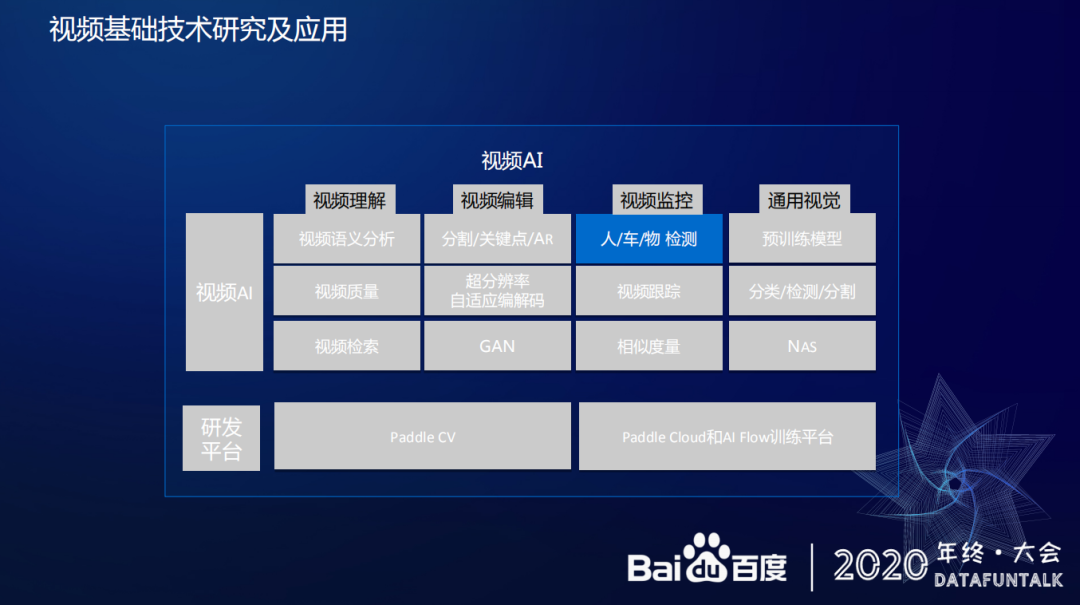
视频监控将主要介绍人/车/物检测技术。
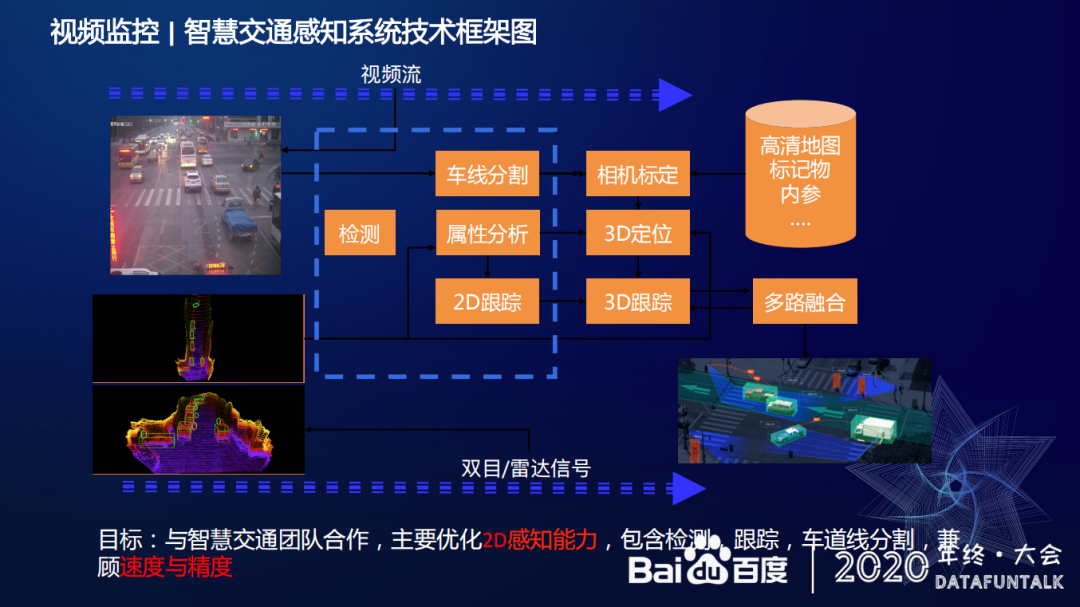
人/车/物检测技术主要通过智慧交通感知技术来举例,这部分技术主要目标是优化 2D 感知能力,包括检测、跟踪、车道线分割,最终实现兼顾速度和精度。
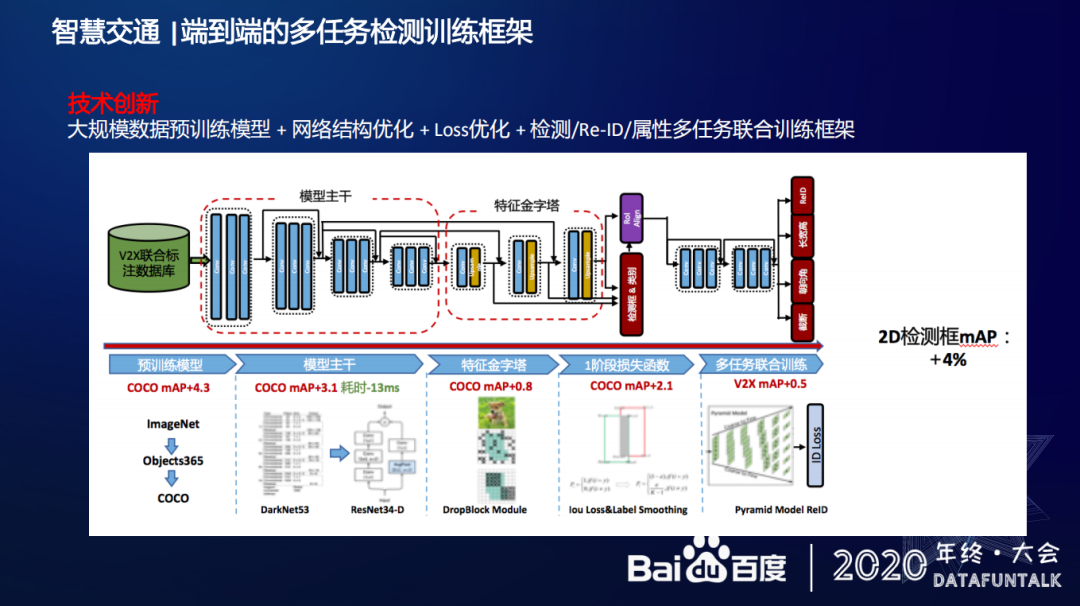
在优化过程中,百度采用以下思路进行技术创新:首先是建立大规模数据预训练模型,在模型主干上,百度将 YOLO 算法的主干网路换成 ResNet34-D,并在这上做了一些改进,提升速度,通过在特征金字塔里引入 DropBlock 来进一步提升效果,除此外还有很多其他 trick,不再一一举例。
4. 通用视觉
通用视觉将主要介绍分类/检测/分割技术:
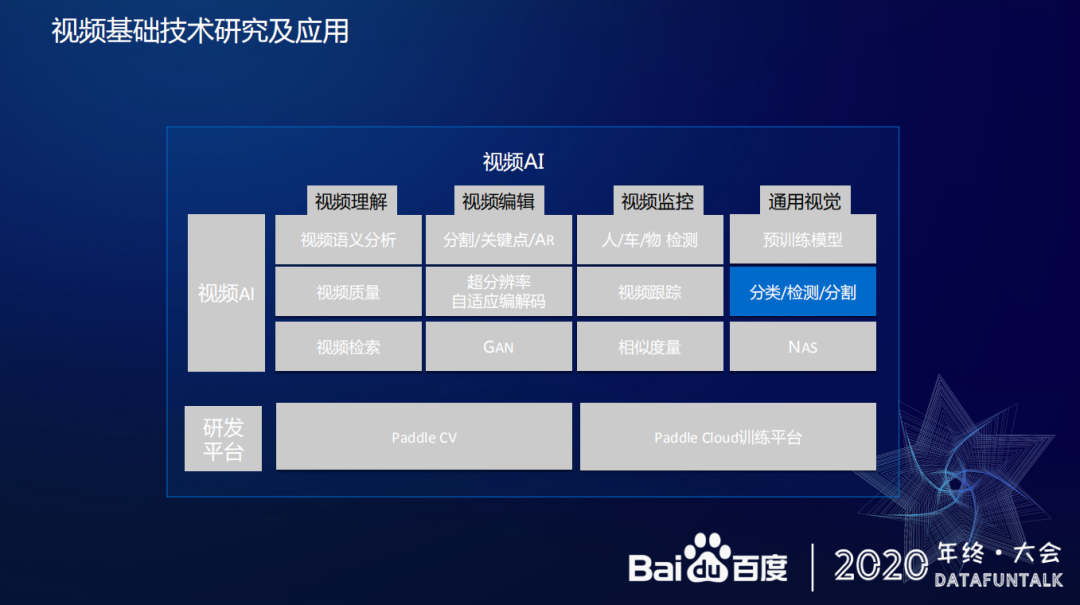
无论在 C 端的图像理解还是 B 端的视频监控场景下,图像最基础的分类/检测/分割技术都和场景应用息息相关。
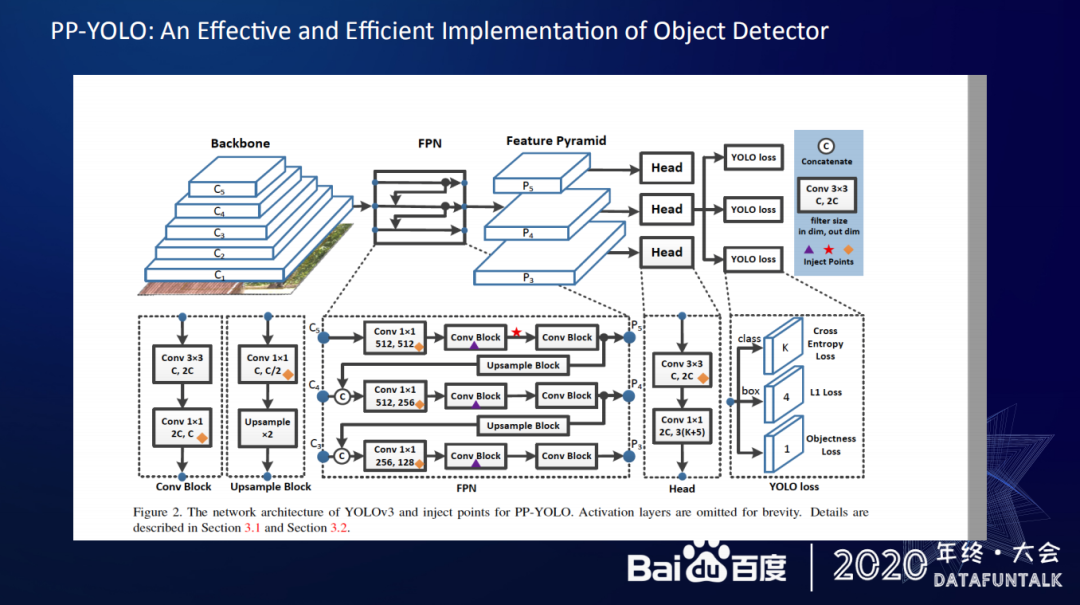
百度基于飞桨平台开发了 PP-YOLO 网络结构,PP-YOLO 的主要思路是在提升检测每个点的效果的同时,也会增加运算速度,如果能保证在尽量高的网络结构的模式和进度的同时,尽量减少它的运算速度,这样就能有效提升效果。这是 PP-YOLO 网络优化的一个主要的目标。
具体工作可以参考论文:PP-YOLO: An Effective and Efficient Implementation of Object Detector
分享嘉宾:
文石磊,百度视频理解技术负责人 | 百度智慧城市主任架构师。
本文转载自:DataFunTalk(ID:dataFunTalk)
原文链接:视频基础技术在百度的应用

腾讯大规模云原生技术实践案例集
本案例集详细阐释了 QQ、腾讯会议、和平精英、小红书、斗鱼、微盟等十多个亿级用户产品背后的大规模云原生...













评论