

相比于传统的调度系统,Kubernetes 在 CSI、CNI、CRI、CRD 等许多可以扩展的接口上有很大提升。从生态系统上来讲,Kubernetes 依托于 CNCF 社区,生态组件日趋丰富。在云原生设计理念方面,Kubernetes 以声明式 API 为根本,向上在微服务、Serverless、CI/CD 等方面可以做更好的集成,因此不少公司开始选择基于 K8s 搭建机器学习平台。在ArchSummit全球架构师峰会(北京站)的现场,InfoQ 采访到了小米人工智能部高级软件工程师褚向阳,听他分享小米机器学习平台以及基于 K8s 原生扩展的机器学习平台引擎 ML Engine。
2015 年,现任小米人工智能部高级软件工程师褚向阳加入了创业公司——数人云,开始进行 PaaS 平台的研发,算是国内比较早的一批投身容器化 PaaS 平台研发的工程师,后来去到京东广告部,这个阶段积累了一些 GPU 的使用经验,为他之后来小米做机器学习平台打下了基础。采访中,褚向阳表示,相较于通用型 PaaS 平台,机器学习平台更加聚焦业务,需要对机器学习相关业务具备清晰认知,并理解困难点。在小米工作的这段时间,褚向阳参与构建和优化了小米 CloudML 机器学习平台以及 ML Engine 架构。本文,褚向阳分享了他的一些实践经验和想法。
小米 CloudML 机器学习平台
对于机器学习平台的定位,褚向阳套用了 ABC 概念图(如下图),并表示机器学习平台应该处于这三者中间的支撑位置,只有机器学习平台可以充分利用云原生的计算能力和特性,不断加速把数据转化为用户价值的循环过程,这也是机器学习平台真正起作用的地方。
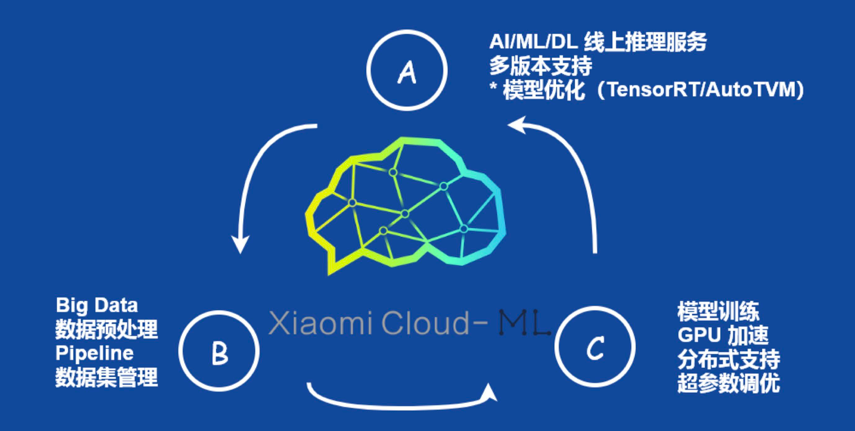
在小米,机器学习平台承载了图像、NLP、声学、搜索推荐等应用业务,各应用作为用户接入机器学习平台,然后可以利用平台提供的所有功能,比如训练、Pipeline、模型服务等,机器学习平台团队对用户提供这些能力的定义,帮助用户更好的使用这些服务。
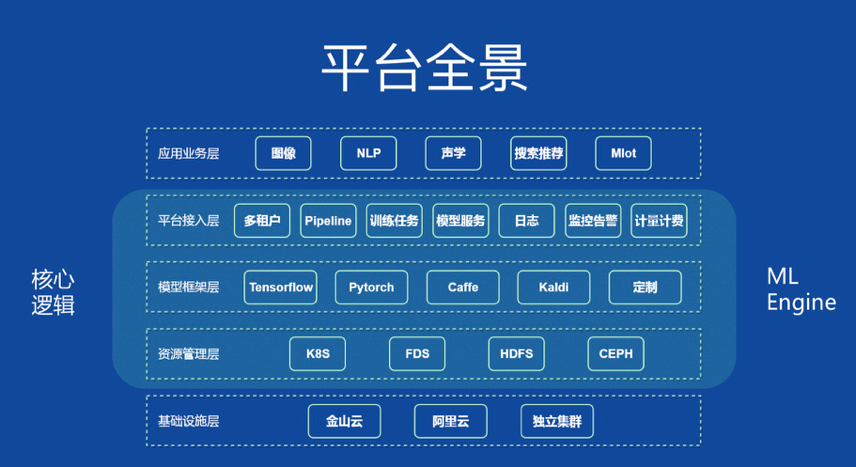
在这个全景图中,核心逻辑也就是平台接入层、模型框架层和资源管理层被抽离出来形成了 ML Engine。
ML Engine 架构设计演进
据介绍,ML Engine 是基于 K8s 原生扩展的新一代机器学习平台引擎 ,在此之前,小米机器学习平台应用了原生 K8s 的所有对象,比如原来的 Job、Deployment、Service 等,初期的 CloudML 架构图如下所示:
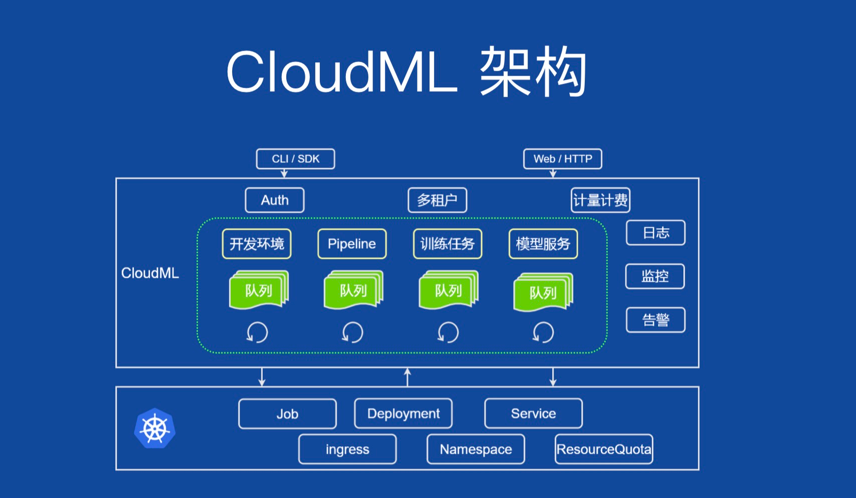
如上图,分布式训练任务主要是一组 Job/Pod+SVC,模型服务主要是 Deployment+SVC+Ingress。褚向阳表示,最初的架构在队列、状态同步,生命周期管理和调度策略层面均存在挑战,比如随着业务规模逐渐成熟,大部分业务训练对分布式提出了比较强的需求,当时虽然可以支持,但用户体验上不够友好。最终,出于解决这些问题的想法,团队开始对平台进行改进。
团队对可能的开源方案进行了调研,发现 TF Operator 的设计理念与现有想法比较吻合,但又没有完全解决问题,因为小米需要对多个框架做统一支持,所以团队决定通过自研解决问题。ML Engine 的主要思路则是充分利用 K8s 原生的扩展机制,包括 CRD / Webhook / Scheduling Framework 等,将机器学习平台相关的业务模型、控制逻辑和调度策略融入到 K8s 集群中,提供更好的生命周期管理,同时满足高可用、稳定性和易维护性的云原生特性。最终,ML Engine 变成了由 CRD、Webhock、定制调度器组成的状态。
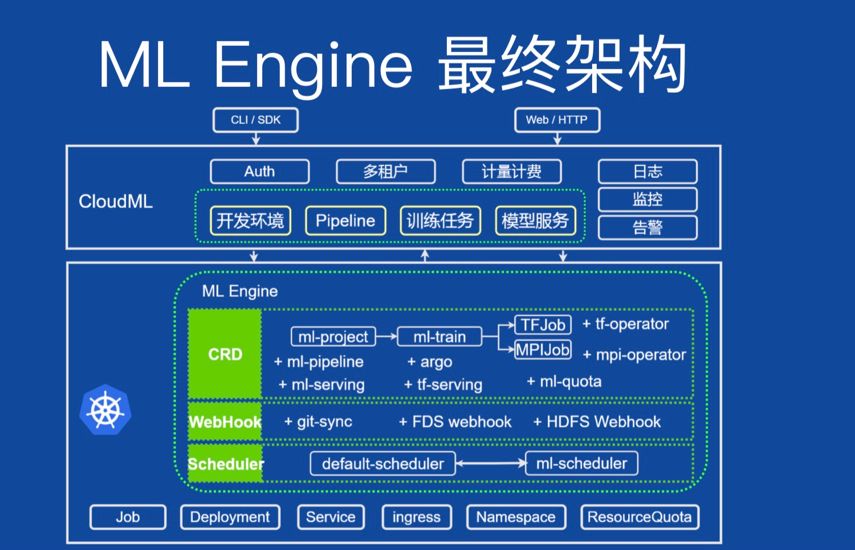
总结来看,ML Engine 新版架构具备如下特点:
机器学习平台业务的合理抽象 CRD
针对机器学习任务特性的定制调度器
公共的 validating/mutating 逻辑
提供统一的对外接口
褚向阳表示,整个引擎可以理解为基于 K8s 原生扩展做的定制和改造,使它更适合于平台直接把它当做机器学习能力的输出口。举例来说,K8s 里面可能只有 Job,没有机器学习训练或者模型推理,但是通过 ML Engine 将这些能力抽象到了平台里面,用户调用 K8s 的 API 或者 SDK 时,就可以使用定义好的模型推理和训练能力,直接做 API 级别的交互。
为什么不直接放在 K8s 之上?
对 K8s 的改造其实也花费了团队不少精力,但在褚向阳看来,整个社区的发展,包括 Tensorflow,都在对 K8s 进行扩展,以保证真正把 K8s 用的更灵活,或者真正使用好这份扩展性,也就是云原生的特性,可以很好地继承云原生的稳定性、高可用特性等。如果只是底层基于 K8s,而不做任何改造,很难用好。正是基于这样的扩展机制,开发团队才可以更加灵活和可靠的设计业务场景。
为什么不直接用 K8s 生态里面的工具?
如开篇所言,K8s 依托 CNCF 形成了丰富的开源生态,开源社区中也有很多工具可供选择,但褚向阳表示,这些工具不会为了机器学习一个场景调整调度策略,或者资源分配逻辑。举例来说,深度学习和机器学习中占据主导地位的 GPU 资源,在其他场景下并不常见。目前,社区在这方面比较火的项目是 Kubeflow,小米也吸取了很多 Kubeflow 的优势,但是为了能给平台向上提供统一的接口,只能把这些作为引擎里的关键组成部件。
ML Engine 对多框架的分布式训练支持
在小米,ML Engine 训练任务的核心用例有用户给定训练代码及启动命令(可选:定义数据及产出物);支持选择不同的机器学习框架及运行时环境(CPU/GPU);下发集群,需要支持分布式启动训练,且需要遵循一定的调度优化策略等。
褚向阳表示,ML Engine 训练任务的整体流程为:
1、发起训练任务请求;
2、提交 K8s,创建 ML Train;
3、触发 ML Engine Controller;
4、根据 MLTrain Spec,决定创建 TF Job;
5、ML Train Code 相关 Spec,触发 git-sync Mutating 逻辑;
6、Patch Request;
7、Pod 调度;
8、识别分布式任务,触发 framework plugins
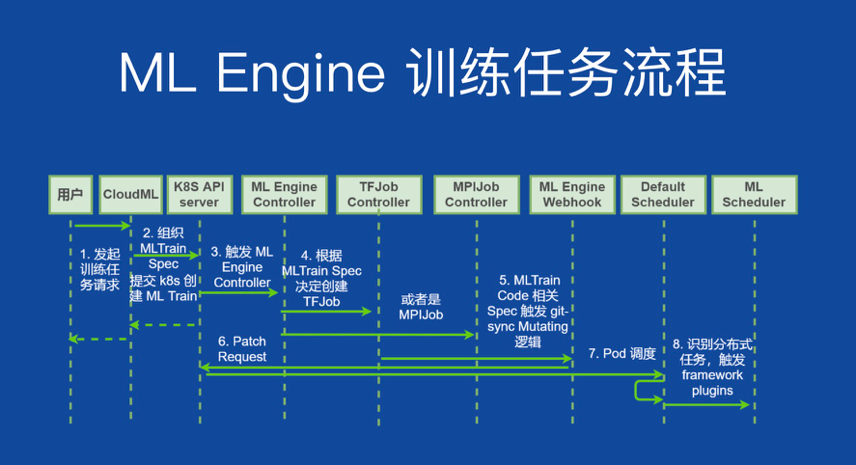
在整个过程中,小米机器学习团队逐渐解决了用户接口层统一、框架状态统一等问题。谈到未来的发展方向,褚向阳表示,整体还是以解决内部需求为主,只要内部用户有需求,团队都会满足。功能上,主要考虑将计量、计费也抽象成 CRD,提供更方便的数据管理逻辑和更丰富的模型服务管理能力。 此外,与模型优化相关的项目,或者说所有可以提高效率的做法也会实时关注,并在时机成熟后积极尝试开源。
经验总结
在机器学习平台搭建层面,每家公司由于背景、业务不同,所以会出现不同的做法,在褚向阳的理解中,K8s 原生的扩展性、服务的可用性保证以及服务的易维护性是可取的优点,但使用时需要注意 admission webhook 是把双刃剑,建议设置过滤条件,以及处理好各框架不同版本之间的 golang 依赖等。
最后,容器也有自己的应用场景,K8s 诞生之初就对无状态应用提供了非常好的支持,无论是开发快速试用环境,还是用来跑大规模分布式训练的任务调度,包括云原生的推理服务,都是非常合适的。如果希望充分发挥云原生的特性,不但平台层和应用层要做改造,底层的支撑平台,包括存储等都要为云原生做好准备,否则会遇到各种各样的困难。
采访嘉宾:
褚向阳,小米人工智能部/高级软件工程师。2013 年毕业后加入红帽软件,吸收开源文化,接触 OpenStack 和 IaaS 平台相关技术。2015 年底开始加入容器云创业公司,参与打造容器化的 PaaS 平台,2018 年从京东广告部加入小米人工智能部,负责小米机器学习平台的建设,重点支持各个框架的分布式训练,订制优化 K8s 调度,努力提高平台用户体验的同时保证集群利用率。持续关注 Kubeflow 社区及性能优化相关开源项目发展。

极客邦科技 总编辑

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论