
整理 | 华卫
近日,阿里巴巴的研究团队与浙江大学合作提出了一种新的 Scaling Law:并行计算缩放定律(Parallel Scaling Law,简称 ParScale),即在训练和推理期间增加模型的并行计算,可以在不增加模型参数的情况下提升大模型的能力,且推理效率更高。
与实现相同性能提升的参数缩放相比,ParScale 带来的内存增加量是前者的 4.5%(1/22) ,延迟增加量是前者的 16.7% (1/6)。它还可以通过在少量 token 上进行后训练,将现成的预训练模型转换为并行缩放模型,进一步降低训练成本。
“我们发现的新缩放定律有可能促进更强大的模型在低资源场景中的部署,并为计算在机器学习中的作用提供了另一种视角。”研究人员表示,ParScale 通过重用现有参数来扩展并行计算,可以应用于任何模型结构、优化过程、数据或任务。
目前,这一研究进展已在 GitHub 上开源代码,在 HuggingFace 的 Space 上就可以直接体验,相关论文《Parallel Scaling Law for Language Models》也在 arXiv 上发表。
开源地址:https://github.com/QwenLM/ParScale?tab=readme-ov-file
体验链接:https://huggingface.co/ParScale
ParScale 怎么实现?
提升大语言模型(LLM)的智能水平,通常有两条主流的 Scaling Law 路线。一是扩展参数,用更多模型参数来更细致地学习,这种方法非常吃显存;二是扩展推理思考的时间,增大思维链长度,这种方法非常吃时间且依赖于训练数据、训练策略(RL),只适用于部分场景。
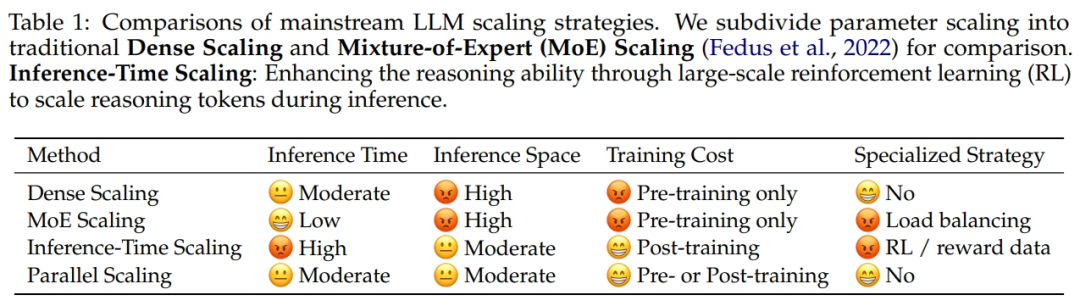
主流 LLM Scaling 策略的比较
不同于这两种传统 Scaling 方法,ParScale 是通过在训练和推理阶段引入多个并行流(parallel streams) ,将一个输入转换成多个输入,然后对它们进行前向传播,最后将结果合并为一个输出。
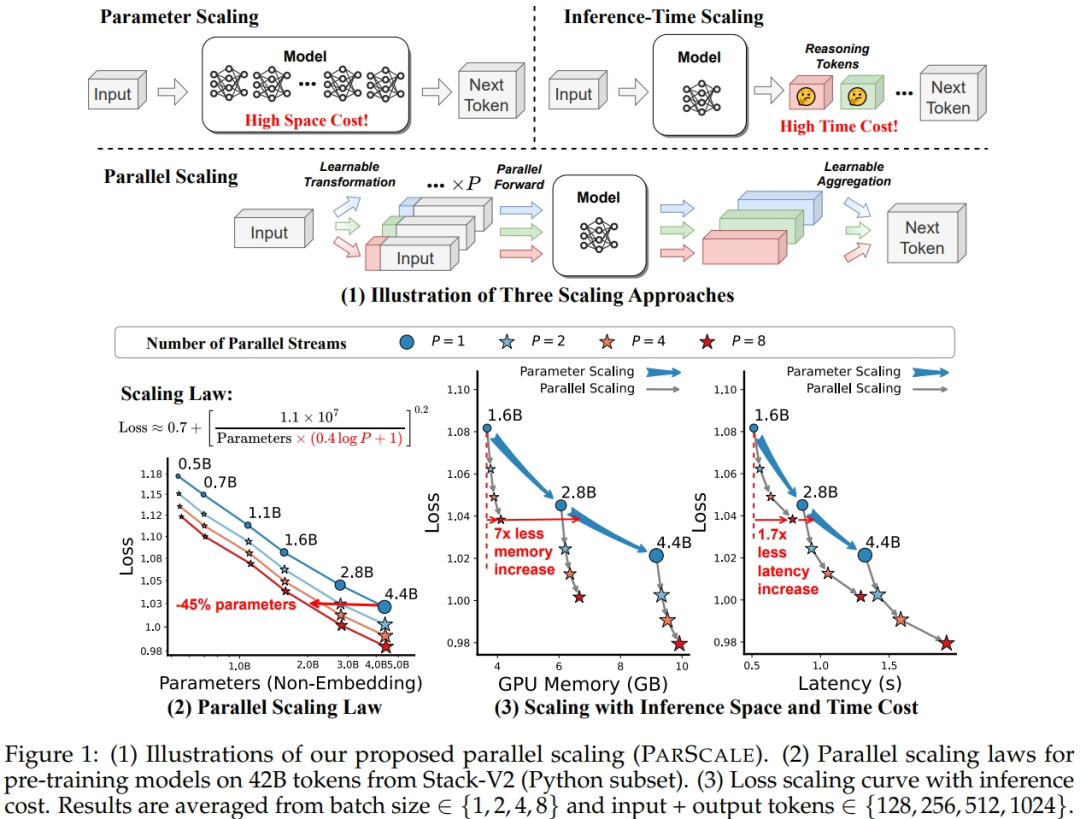
该成果论文的第一作者 Mouxiang Chen 在知乎平台公开介绍,他们的核心想法就是:在参数量不变的情况下,同时拉大训练和推理并行计算量。
据悉,Mouxiang Chen 目前在浙江大学读博士,拓展并行计算量的思路始于他在宿舍时和舍友学习 diffusion 模型的一次经历,他们对于 diffusion model 必用的一个 trick 百思不得其解:Classifier-Free Guidance(CFG)。
CFG 在推理阶段拿到输入 x 时,首先做一次正常的 forward 得到 f(x);然后再对 x 进行主动的劣化(比如去除条件)变为 x’,再进行一次 forward 得到 f(x’)。最终的输出 g(x) 是 f(x) 和 f(x’) 的一个加权组合,它的效果比 f(x) 更好,更能遵循输入的条件。这个现象事实上有点反直觉:f(x) 和训练阶段是对齐的,而 g(x) 明显和训练阶段的目标存在 gap。按照常识,只有训练目标和推理目标形式相同,推理才能发挥最大效果。另外,f(x) 的参数量和 g(x) 也是相同的,输入的有效信息量也相同,为什么 f(x) 反而学不到 g(x) 的能力?这说明背后或许存在更深层次的原因。
受到这一启发,Mouxiang Chen 做出一个大胆的猜想:Classifier-Free Guidance(CFG)在推理阶段生效的原因,本质上是用了双倍的并行计算量,它拉大了模型本身的 capacity。
具体到 ParScale 上,其实现包括以下三步:
输入多样化变换 :使用"前缀微调"(Prefix Tuning)技术,给每个输入添加 P 个不同的可学习前缀,使模型能从多个视角理解和处理同一任务;
并行处理 :将这些输入送入模型的不同路径中并行处理;
动态聚合输出 :采用动态加权平均方法,使用可学习的权重对各路径输出进行加权融合,利用 MLP 将来自多个流的输出转换为聚合权重,得到最终结果。
通俗来讲,ParScale 的基本思想,不是让模型对同一个问题反复回答,而是让模型“多角度”进行回答,再通过动态加权融合回答,得出更聪明的答案。
至于 P 有没有上限,仍然是悬而未决的问题,研究人员已将其留作未来工作。“即使有上限,它也和模型的参数有关。模型越大,直觉上提升 P 的收益应该也会越大。”Mouxiang Chen 表示。
在数学、编程等强推理任务中更强
在预训练完成后进入后训练阶段时,研究人员采用了一种新的两阶段后训练策略,来控制因并行流数量 P 增加而导致的训练成本上升:
第一阶段使用 1T token 进行传统训练,采用固定学习率;
第二阶段引入 ParScale 方法,在仅 20B token 的数据上进行微调,使用学习率退火策略。
简单来说,该策略将资源密集型的训练任务集中在第一阶段,而在第二阶段只需少量数据即可完成对并行扩展机制的有效适配,不仅大幅降低了总体训练成本,同时还保留了 ParScale 的性能增益。
为证明了该策略的有效性,研究人员在多个下游基准测试中验证了模型应用 ParScale 后的性能,包括常识、数学和编码方面。
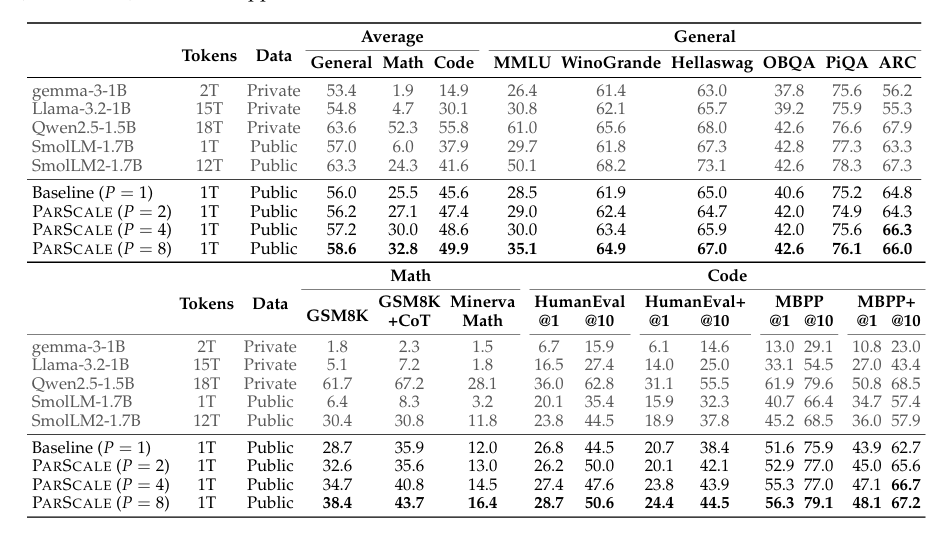
结果显示,随着并行流值数量 P 越多,模型在大多数基准测试的效果越好,且在数学、编程等需要强推理能力的任务中尤为显著。当 P 增加到 8 时,在完全相同的训练数据下,模型在编码任务中提升了 4.3%,数学任务中提升了 7.3%,常识任务中提升了 2.6%;在 GSM8K 上提高了 10%,相当于原本 34% 的提升。
研究人员还在已经训了 18T token 的模型 Qwen-2.5 上应用了 ParScale,并在两种设置下进行了验证:一是持续预训练(CPT),二是参数高效微调(PEFT)。结果显示,即便在这样一个已经经过全面训练的模型上, ParScale 仍能带来显著的性能提升。这也表明动态并行缩放的可行性 —— 可以使用相同的模型权重,在不同的场合下使用不同数量的并行流,从而快速地动态调整模型能力以及推理开销。这是目前的主流方法比较难做到的。
适用于手机、汽车和机器人等边缘设备
许多网友都对这项成果表示赞赏,称其“让人眼前一亮”。还有人评价,“好思路,就像一层窗户纸突然被捅开。”
“随着人工智能的日益普及,我们认为未来的 LLM 将逐步从集中式服务器部署转向边缘部署,而 ParScale 可能成为适用于这些场景的一项有前景的技术。”研究人员表示。
据了解,研究人员在分析不同 batch 的推理成本发现,ParScale 非常适合智能手机、智能汽车和机器人等资源匮乏的边缘设备,这些设备的查询通常很少,batch 也很小。鉴于这些环境中的内存资源有限, ParScale 可以有效地利用小 batch 的内存和延迟优势。与实现相同性能提升的参数扩展相比,并行扩展只会带来前者 1/22 的内存增加和 1/6 的延迟增加。
目前,研究人员对 ParScale 的相关研究仍然在进行中。未来,他们计划进一步在更多的模型架构比如 MoE)以及更大的数据上进行尝试。“ParScale 是一种计算密集型(但更高效)策略,与参数密集型的稀疏 MoE 架构形成互补。鉴于 MoE 架构对延迟友好,而 ParScale 对内存友好,两者结合能否生成更高效、高性能的模型值得研究。”
参考链接:
https://arxiv.org/pdf/2505.10475
https://www.zhihu.com/question/1907422978985169131?utm_psn=1908460136185459759
声明:本文为 AI 前线翻译整理,不代表平台观点,未经许可禁止转载。




