

本文首创地提出了一种面向中文地址文本的语言模型预训练方法(GeoBERT),该方法通过多子任务共同约束的方式,能够有效捕捉地址文本之间的空间语义关系、在不依赖外部映射字典的情况下学习地址的行政层级要素以及行政区划之间的隶属关系,能够对地址中单字及其上下文环境信息进行语义表征,并在高维空间仍保持两条地址的真实关系。
基于该模型获得的地址文本的向量化表征矩阵可作为地址分类、地址分词、地址中 POI 提取、地址相似度对比或地址真实性核验等地址文本相关深度神经网络的输入 Embedding,减少上层具体任务对标注数据的依赖,减少模型训练收敛时间,并提高模型的准确性和召回率。本文主要内容分为模型训练数据预处理、预训练语言模型构建、预训练语言模型训练、应用场景四个部分。
一、模型训练数据预处理
原始的语料数据包括地址文本数据及其对应 ID 两部分。在原始语料的基础上进行文本清洗,包括:剔除过短或过长的地址条目,剔除字段缺失的地址条目,然后将字符全角转换为半角,剔除地址文本中空格、制表符、引号、各种括号等中文标点符号,得到标准预料。为保证模型训练数据的无偏性,将标准化后的地址语料数据进行分层采样,得到分布均衡的地址语料数据,并将数据条目的顺序随机打乱。
在上一步清洗处理好的语料数据基础上,对模型构建所需的数据进行预处理,并按比例划分出训练集、验证集、测试集。具体方式如下:
1、 对于步骤 1 中的每一条地址,以概率 p(如 50%)从剩余地址中随机选择一条地址,以概率 1-p 选择该条地址本身,构建地址对(address pair),然后将地址对中两条地址文本及其对应省、市、区县进行对比,即两条地址是否相同、两条地址是否为同一物理对象的地址(例如,对于同一所学校,不同人填写的地址文本可能有差异,但指向的是同一所学校;对于同一小区的同一栋楼,不同住户填写的地址文本可能有差异,但指向的是同一栋楼)、两条地址所属省份是否相同、两条地址所属市是否相同、两条地址所属区县是否相同。同时,对于地址对中两条地址文本,借助最长公共子序列算法得到最长公共子序列,并计算最长公共子序列的长度占两条地址平均长度的比值。按以上步骤构建如表 1 所示的基础数据集。该过程可重复多次,重复次数由重复因子参数决定。
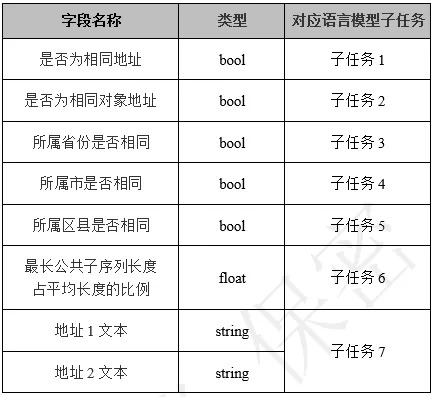
表 1-模型训练基础数据集表结构及对应语言模型子任务
2、 将上一步得到的模型训练基础数据集中的两条地址文本按字分词(即划分为单个单个字符),构建语料字典,并将两条地址文本长度对齐到参数设置的最大长度。当两条地址文本的总长度超过了参数设置的最大长度时,则挑出其中较长的一条,依次随机地删除头部或尾部字符,直至满足最大长度条件;当两条地址文本的总长度小于参数设置的最大长度时,则在末尾补充特殊字符“[PAD]”。然后随机对一定比例(如 15%)的单字(token)进行遮掩或替换,即把遮掩替换字中的 80%的字替换为“[MASK]”,10%的字保留为原始字,10%的字替换为预料字典中的随机取出的字。然后将地址文本中的每个字转换为语料字典中相应字符对应的整数索引。对数据的格式转换参照谷歌 BERT 中提出的方法。
3、 将上一步构建的数据集随机打乱,按 70%:15%:15%比例划分出训练集、验证集和测试集。在训练集上训练模型,根据模型在测试集上的性能表现调整超参数。
二、预训练语言模型构建
面向中文地址的预训练语言模型构建的流程如图 1 所示。
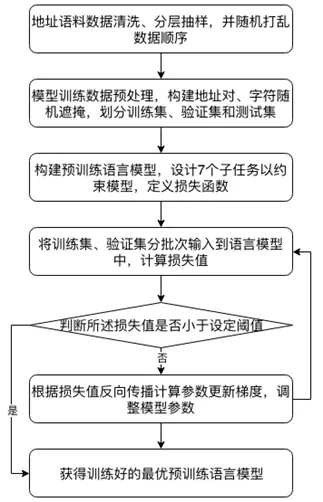
图 1-地址预训练语言模型构建流程示意图
由于地址文本的特殊性,本文提出的预训练模型在谷歌提出的 BERT 模型基础上进行了改进。
1、 对于相同的两条地址文本,在随机对一定比例(如 15%)的单字(token)进行遮掩替换后,子任务 1 – “是否相同地址”约束模型仍需准确判断两条地址文本的关系,从而使模型更好地学习字语义表征及其上下文环境。具体地,在模型训练数据预处理的步骤(1)中构建模型训练样本地址对(address pair)时,类似于谷歌 BERT 模型中句子对(sentence pair)的“前后句子关系”子任务,预留一个标识位“[CLS1]”,由 Transformer 模型逐层提出语义信息后,在最上层输出的向量矩阵中提取“[CLS1]”对应的多维向量,输入到一个二分类模型中,并计算交叉熵损失 loss1。
2、 地址文本不像谷歌 BERT 论文中提到的句子对(sentence pair)存在前后句子关系,但其在地理空间上是存在空间关系的,即两条地址是否对应同一物理对象,尽管不同人在地址文本的填写方式上有差异。因此,本文对预训练语言模型增加了子任务 2 – “判断两条地址是否是相同对象地址”的约束,以使模型能够捕捉地址文本之间的空间语义关系以及相同地理实体不同写法在高维空间的对齐。具体地,在模型训练数据预处理的步骤(1)中构建模型训练样本地址对(address pair)时,类似于谷歌 BERT 模型中句子对(sentence pair)的“前后句子关系”子任务,预留一个标识位“[CLS2]”,由 Transformer 模型逐层提出语义信息后,在最上层输出的向量矩阵中提取“[CLS2]”对应的多维向量,输入到一个二分类模型中,并计算交叉熵损失 loss2。
3、 地址文本不同于普通的文本,其包含了地理区划的空间拓扑关系,表达的语义是存在明显的行政层级及行政层级之间隶属关系的。例如,地址 1“北京市海淀区青龙桥街道功德寺 1 号海淀学校后勤管理中心”中,“北京市”、“海淀区”、“青龙桥街道”是存在行政层级及行政层级隶属关系的,而且是地址文本中包含的重要地理信息。地址 2“北京市朝阳区大屯路甲 11 号”中的“朝阳区”与地址 1 中的“海淀区”是并列的关系。本文提出在预训练语言模型中通过增加子任务 3 – “所属省份是否相同”、子任务 4 – “所属市是否相同”、子任务 5 – “所属区县是否相同”子任务约束,以将这种外部知识以及行政层级隶属关系编码至文本的语义表征中。具体地,在模型训练数据预处理的步骤(1)中构建模型训练样本地址对(address pair)时,类似于谷歌 BERT 模型中句子对(sentence pair)的“前后句子关系”子任务,对应“所属省是否相同”、“所属市是否相同”、“所属区县是否相同”三个子任务,分别预留标识位“[CLS3]”、“[CLS4]”、“[CLS5]”,由 Transformer 模型逐层提出语义信息后,在最上层输出的向量矩阵中分别提取“[CLS3]”、“[CLS4]”、“[CLS5]”对应的多维向量,分别输入到一个二分类模型中,并计算交叉熵损失 loss3、loss4、loss5。
4、 两条地址文本的最长公共子序列长度占两条地址平均长度的比例在一定程度上反应了两条地址文本的相似程度,子任务 6 – “最长公共子序列长度占平均长度的比例”子任务约束模型在对地址进行单字遮掩替换及多层的语义抽象后,其在对应的高维空间仍能保持两条地址的相似关系。具体地,在模型训练数据预处理的步骤(1)中构建模型训练样本地址对(address pair)时,类似于谷歌 BERT 模型中句子对(sentence pair)的“前后句子关系”子任务,预留一个标识位“[CLS6]”,由 Transformer 模型逐层提出语义信息后,在最上层输出的向量矩阵中提取“[CLS6]”对应的多维向量,输入到一个回归模型中,并计算均方误差损失 loss6。
5、 对于子任务 7 – “遮掩单字预测”子任务,其处理方式与谷歌 BERT 相同,损失记为 loss7。
三、预训练语言模型训练
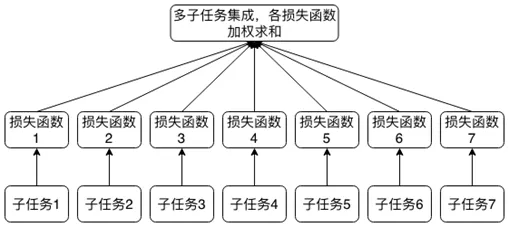
图 2-基于 BERT 改进的语言模型多子任务集成示意图
本文提出的针对中文地址的预训练语言模型为一个多子任务约束的模型,集成方式如图 2 所示,其总的损失函数由各子任务的损失函数加权求和,即:
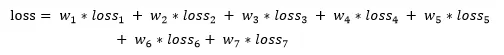
式中,分别对应于上一步定义的 7 个子任务的损失函数,为对应子任务损失函数的权重。
将训练集分批输入到上述模型中,进行前向传播过程计算模型损失值,判断所述模型损失是否低于设定阈值。如果低于设定阈值,则结束模型训练,获得训练好的最优预训练语言模型。否则,进行反向传播过程,计算每一层的参数更新梯度,进行权值更新。以上过程多次迭代,直至模型收敛和模型损失值低于设定阈值,从而得到最终的预训练语言模型及最优参数。
模型训练的原始数据包含约 9000 万条地址,并按数据预处理环节介绍的方法进行了转换和增强。参数设置如下:
train_batch_size=64,max_seq_length=120,
max_predictions_per_seq=18,learning_rate=1e-5,
其它同 Google BERT。在 2 张 V100 GPU 上累计训练 6 天。由于 GPU 资源的可用性限制,模型分成 4 个阶段进行训练,后一阶段训练以上一阶段训练的参数初始化模型,模型在验证集上的损失值变化如图 3 所示。
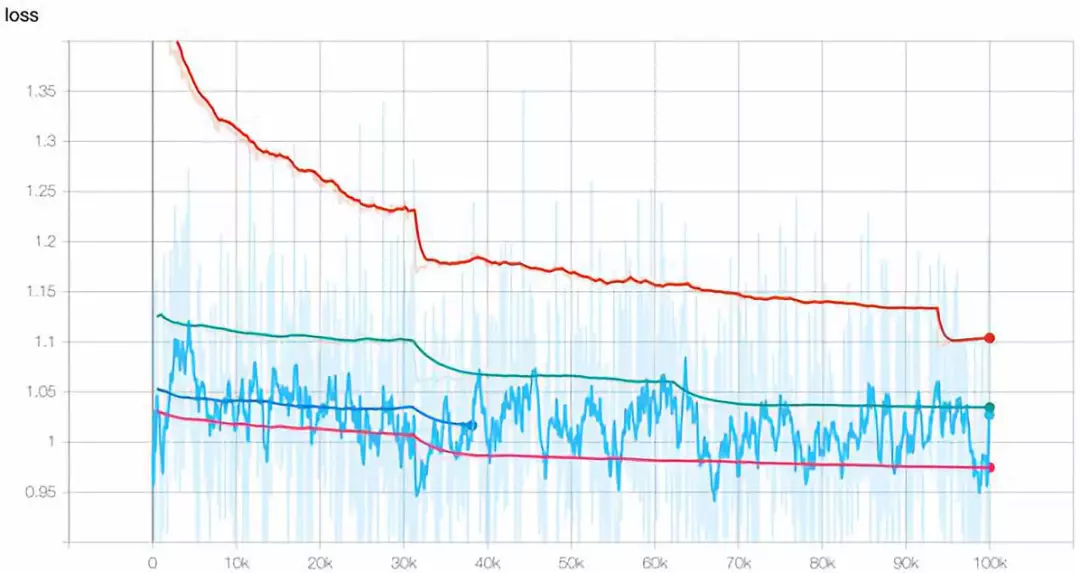
图 3-预训练语言模型损失值随着迭代次数增加的变化
四、应用场景
1、地址文本数据保护
数据是大数据时代的一项重要资产,地址文本数据涉及到隐私,更需要保护。在金融风控、地址商业智能以及城市治理等领域均离不开对地址文本数据的应用与挖掘。本文提出的面向地址数据的语言模型预训练方法能够有效学习到地址数据中的语言模式、地理行政区划之间的层级关系以及地址文本中单字在其上下文环境的语义表征。如图 4 所示,对于拥有地址数据的相关方,可参照本文提出的方法构建预训练模型,进行模型参数共享,而不是共享地址明文数据。基于合作方共享的模型在自有数据上继续更新优化模型,并将优化的语言模型提交到合作约定的共享仓库,方便合作方基于自有地址数据继续更新优化模型,从而避免了共享地址明文数据,却又达到了充分利用多方数据提高模型精度的目的。
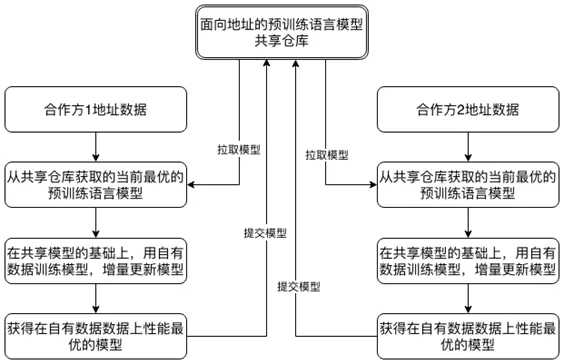
图 4-基于预训练语言模型的地址文本数据保护的流程示意图
2、地址真实性核验
在金融风控场景中,核验申请人的家庭地址或工作地址的真实性以抵抗欺诈风险是一种重要的风控手段。在实际业务中进行地址验真,一般是将用户填写的家庭地址或工作地址与其它系统中获取的用户真实的地址进行比较,以判断地址的真实性,从而为下一步的操作提供决策依据。
基于中文地址预训练语言模型获得的地址文本的向量化表征矩阵,将其作为地址真实性核验模型神经网络的输入 Embedding,通过 Fine Tuning 的方式将地址验真模型与本文提出的预训练语言模型结合,从而减少模型训练对标注数据的依赖,并显著提高准确率和召回率。基于模型的地址验真能够实现大批量地址验真,降低人工判断的主观性风险以及人工成本,并使整个风控流程自动化。
3、地址分词
地址分词是指通过对地址文本的解析,将地址文本划分为有意义标签的文本块,实现地址文本中的行政区划层级、地理实体对象和有意义的文本信息的提取。地址分词技术是地址数据价值的挖掘、利用的基础。通过从在大规模无标注地址数据上预训练的语言模型中迁移学习地址文本的特征和空间语义模式,构建地址分词深度学习模型,可以减少对标注数据的依赖,无需人工定期更新和维护关键词字典和规则,减少了人力、物力的投入。
地址分词模型的构建、训练及效果评估等情况,将在下一篇文章中进行详细介绍。
参考文献
Vaswani A, et al. Attentionis All you Need[J]. NIPS, 2017: 5998-6008.
Devlin J, et al. BERT:Pre-training of Deep Bidirectional Transformers for Language Understanding[J].NAACL, 2019.

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论