1. 公安领域的工作背景
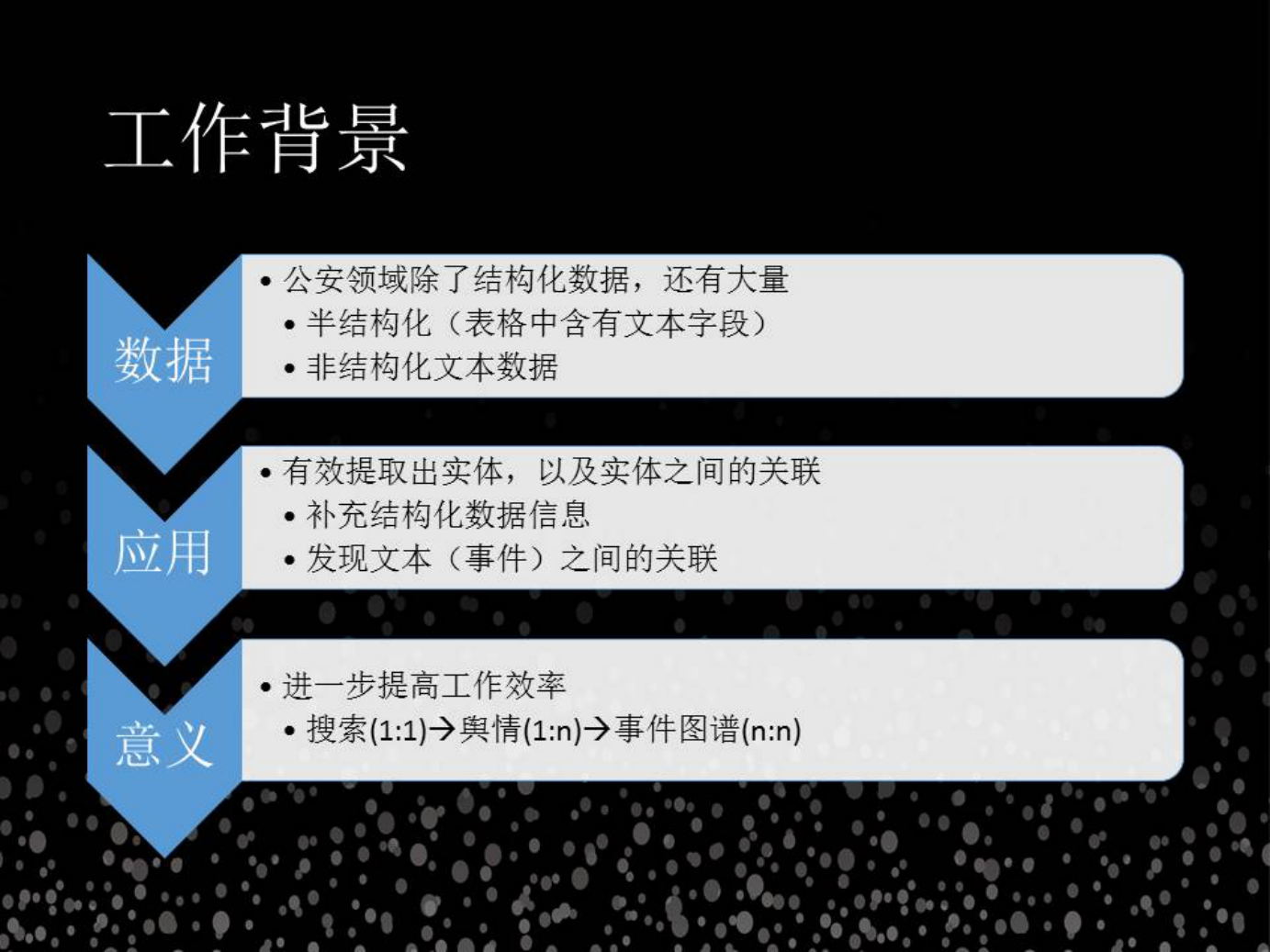
从特定类型文本中提取实体关系。这些领域除了有很多结构化数据之外,还有跟多的文本数据,通俗意义上都叫做非结构化数据(这里不包括语音、图片、视频等)。在应用里面,结构化描述的数据是非常清楚的,对于文本来说,由于大家书写的形式各异,表达方式多样,这个里面提到的很多要素,如人名、车牌号、手机号、组织名等都是称之为实体。实体和实体的关系,以及实体和事件的关系,是比较难发现之间的关联,说明了前两点之后再看第三点,意义在哪里?其实随着文本数据,文本数据的信息被大规模的被发挥出来,最早来自于互联网公司,比如说百度、Google 以及基于此创造很大的价值,随着互联网公司的兴起,大家对非结构化数字文化挖掘越来越重视。
这个搜索 1:1 是什么意思,第一,就是一个人找一件事情,第二,1:n 是舆情,即使你做营销也好,你都需要知道统计的信息,舆情是一对多的情况,第三就是我们需要关注的所有的事情其实都是并发的,各种各样的发展的趋势都是同步进行的,你不可能用一个人来监测这些变化,我们也没有这么大的团队做这样的事情,需要机器做事情,N:N 就是用机器发现追踪非常多的线索,每条线索都涉及到很多的实体。
2. 有效地找到特定类型文本这种蕴含的实体关系
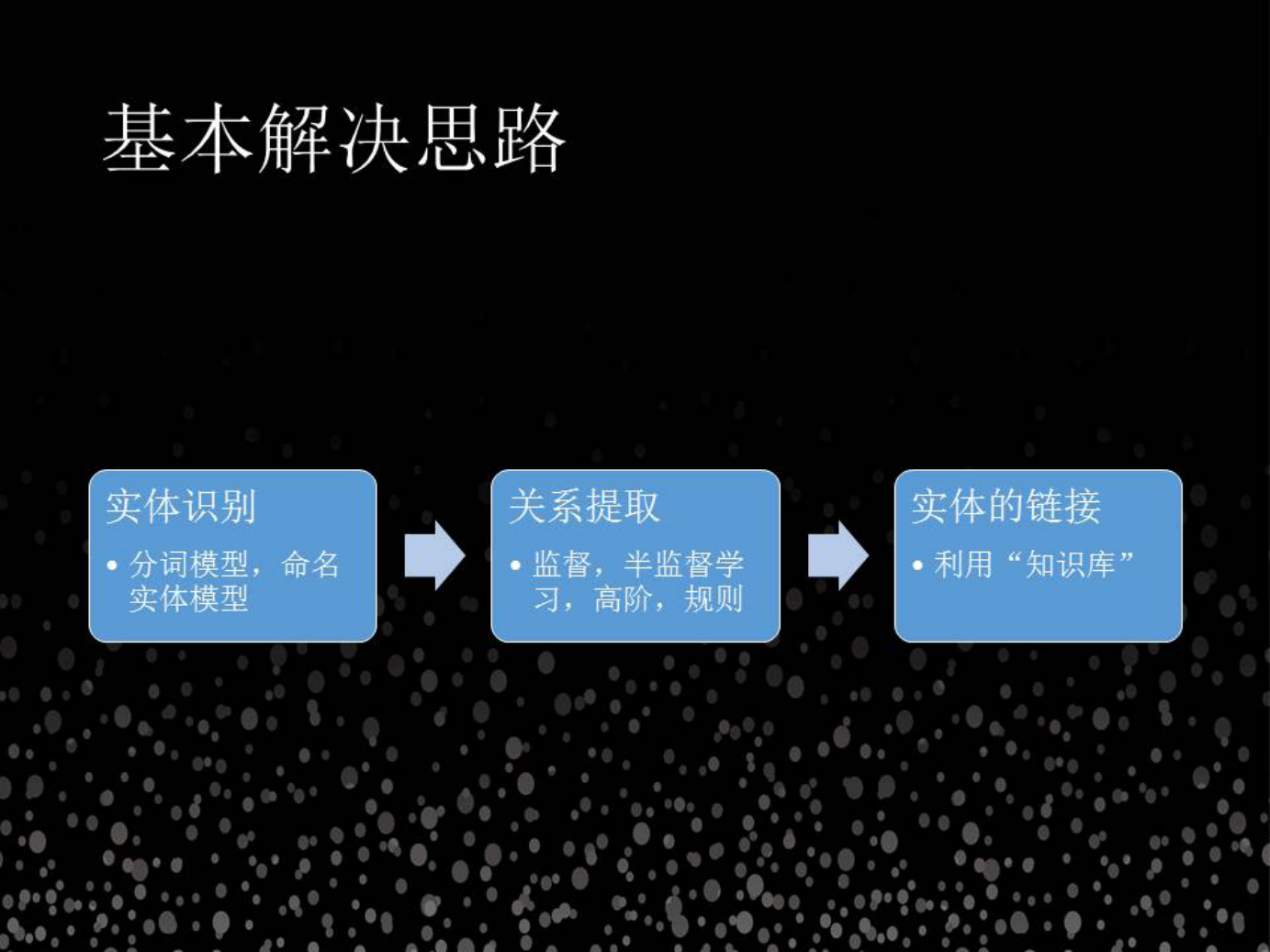
如何找到文本里面的实体关系。这是一个工业界也好,学术界都在持续做的事情,在这里列出来这些步骤,其实主要是想说我们做这个事情,从最开始到逐渐去完善,到最后去结合实际,把事情做到产品级别;
第一步,因为我们是处理中文,分词是必须的,也是最关键的第一步。第二步就是分词之后才会出现所谓的实体,这个实体就是一个字符串,什么样的字符串才是实体,这个我慢慢跟大家分享。
第二步就是关系的提取,这块虽然有各种深度学习的方法,但我们发现是统计的思路依然非常好用。但有一个问题,对于模型训练问题,我们需要巨大的人工。举例来说,你告诉机器 1+1 等于 2 一万次,这样下次它遇到的同等情况就会以较大概率猜到 1+1 等于 2。
关系不只限于二元,你和你的亲戚、父母都是二元关系,还有多元关系,我和我的朋友一起去旅游,假如说我们一共有四个人,分别叫张三、李四、王五、刘七,那这个就是所谓的高阶关系。为了处理这些关系,我们除了基于基于统计,还可以利用一些规则的东西。
所有这些做完之后,我们得到了很多的事实,如何把文本本身提取到的实体进一步完善,确认这个实体,这个人名,我怎么确定这个人就是我想找的那个人,而不是重名的人,我们就需要利用知识库来做一些事情了。
3. 把文本本身提取到的实体进一步完善
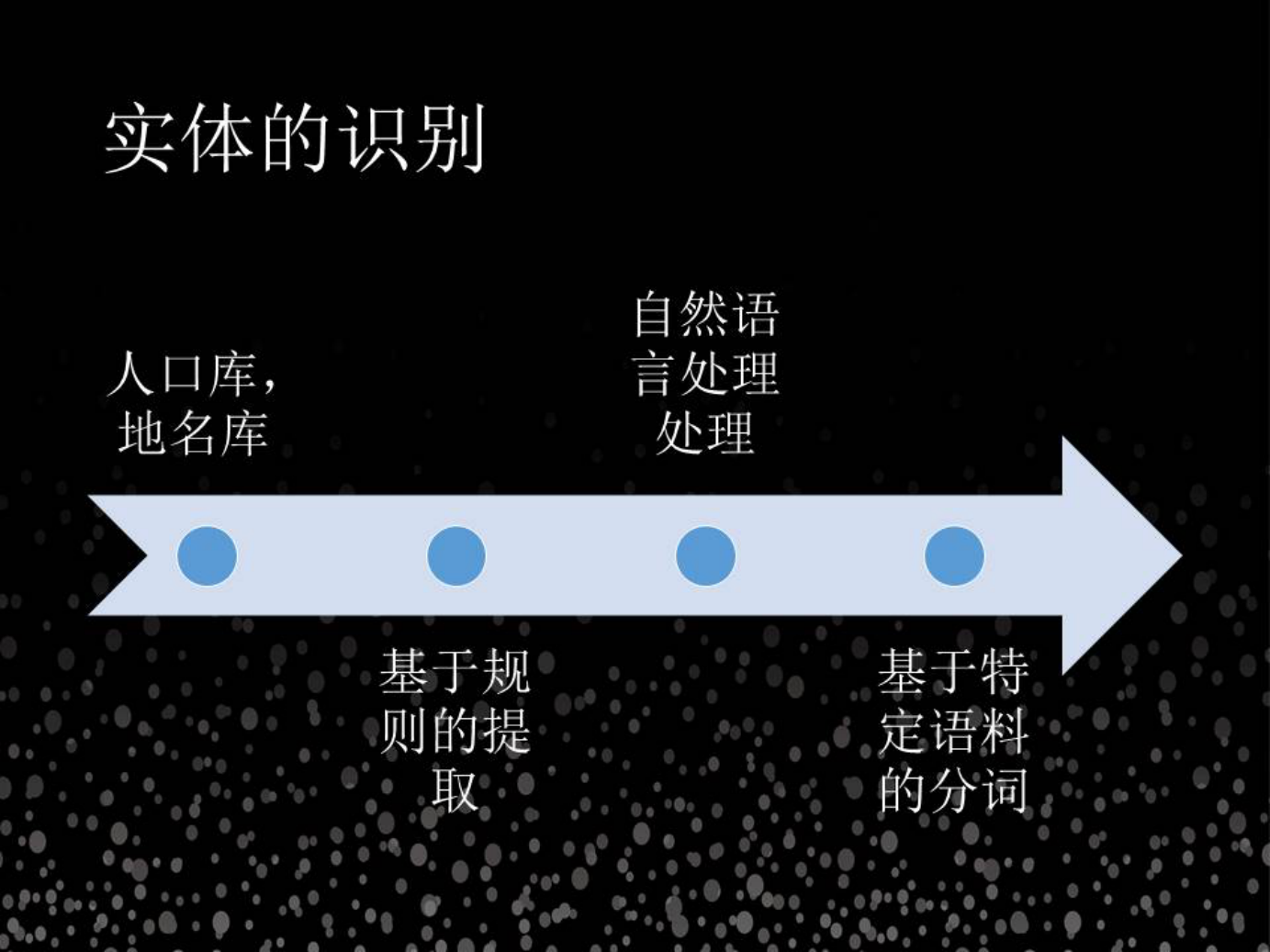
第一步就是实体的识别,在我们实际的处理过程中有一些主要尝试的思路,首先是最基本的字符串匹配,这件事做好的前提是我们原先知道足够多的人名、地名等实体名字,但是我们是没有办法拿到非常全的各种各样的库的数据。那么我们就要要想办法,找规律。那么我们就要要想办法,找规律。
第二步就是用所谓的规则,可能大家都知道正则表达式。
4. 自然语言处理的技术
上面两种思路都不好使的前提下,必须用自然语言处理的技术。
市面上很多的工具,包括公布出来的斯坦福的工具,北京大学的工具,但这是这些工具中的语言模型很多都是从新闻媒体语料训练二来的。新闻媒体的提及的语言文字,范围广,涉猎多,所以处理的广度是有的,但是当应用到一个特定的领域之后,这个精度是远远不够的(尤其当这里的很多用语独居特色,和新闻语料有明显区分度)。作为一个业务人员使用这些已有的工具需要找到你所需要知识的时候是不够的。

这里提到的就是常见的市面上的工具,主要存在的问题,我在前面说得比较多了,解决办法就是我们希望用到更多更细的方法:为我们特定领域的文本重新训练的分词模型,重新训练实习模型。根据前两步已经做出来的模型,通过规则引擎以及半监督的方法再来实现关系的提取。
5. 关系提取的方法

关系的提取有很多方法,并且学术界也一直在研究,但是当你遇到特定问题的时候,我们不得不针对问题重新思考。首先第一想到的就是基于监督的方法,不过你需要不少的人工的工作量在里面,人工告诉机器什么样的东西才是你所需要提取的关系,这个也是教机器很多次,希望它在后续的过程当中能够猜出来你希望的结果。它的优点就是针对领域,识别率比较高,我们在做的时候也用到了这种方法。缺点也很明显,如果更换了应用领域,原来的模型就不太适用了。
但是我们知道在这个过程中,人也是会累的,人是会犯错的,每个人的知识、背景都不一样,没有办法高精度确的教会机器。
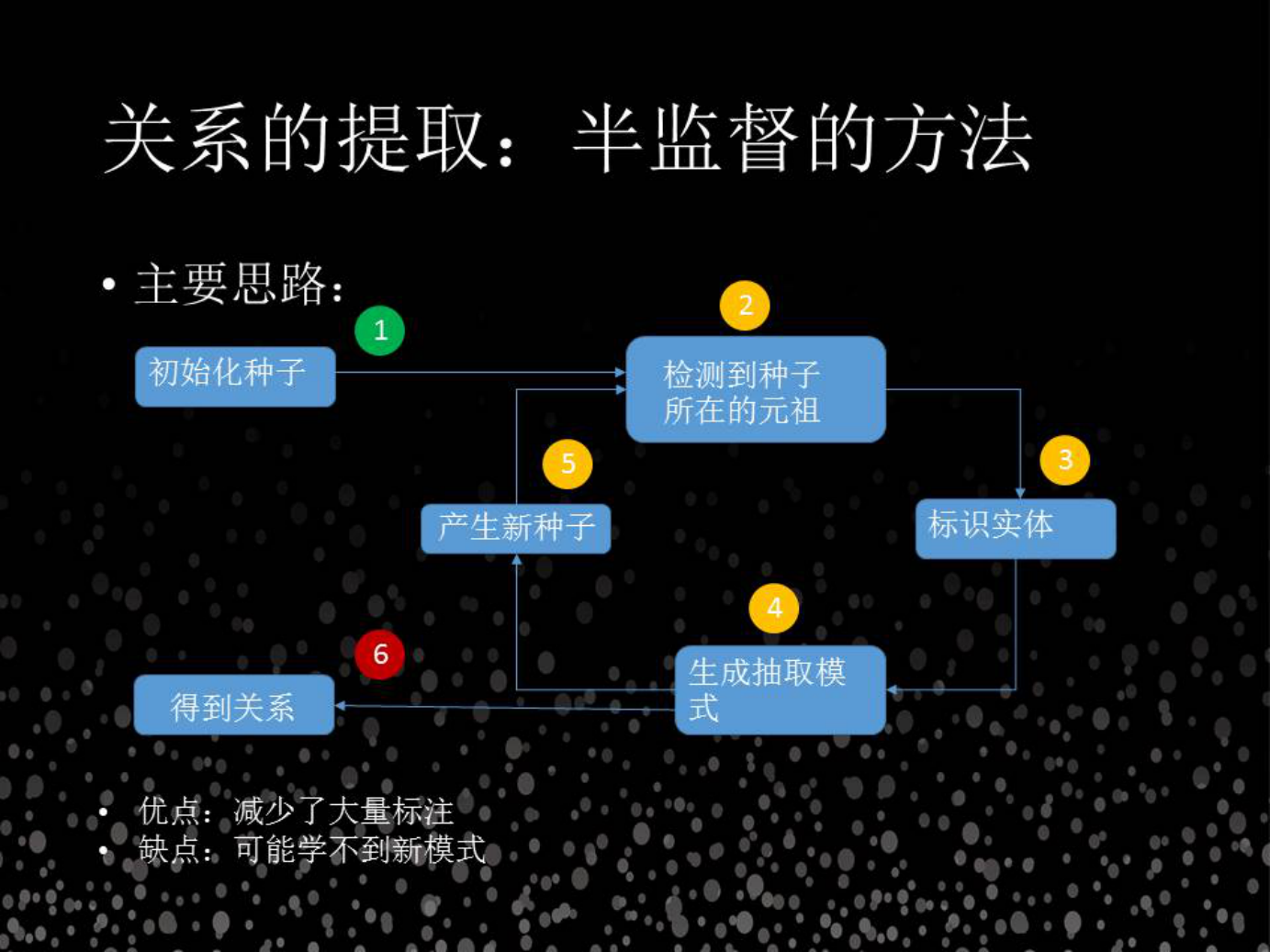
下面介绍一种更好的方法,就是半监督的方法,半监督的方法,思想非常好,比如说先说张三是张仨的儿子,在这句话中蕴含了一个模式,就是 xx 是 yy 的儿子,简而言之就是“父子关系”的模式,我可以把这个模式推广放到更广阔的范围,可以在互联网里面查找“xx 是 yy 的儿子”这样的形式,这个过程当中,除了初始化的种子里面提到这种模式之外,还可以通过新发现的关系来查找到更多的模式。再把更多模式里面学到的东西,不断地滚雪球,能够得到更多的关系。但是做这个事情最最重要的前提问题域本身是有这么多的各种各样丰富的模式,不止是单一的模式,如果只有单一的模式,你希望从单一的模式扩展到所有的模式都是不可能的。
接下来是高阶关系,这个是我从别人论文取得里面的截图,举例说明高阶关系。高阶关系其实我们遇到的不是很多,高阶关系处理的还是比较复杂的,不能依赖于单一的简单的解决方法,论文中提到的方法并不实用,现在高阶也会规则引擎去做识别。

这里举了一个使用规则提取关系的例子,这个规则看着非常复杂的东西,其实说明的是亲属关系,提到两个人,再加上两个人之间的关键词,我们这个规则可以识别出来这种模式。

假设我们前面这些问题都已经解决了,我们已经利用文本中原有的信息解决了上述问题,但是把文本里面的信息挖掘的非常充分后,会发现涉及到很多人的重名。你需要确认两个事件人都是同一个人,这件事情需要上下文,还需要外部的知识库辅助完成这个事情。一方面需人口库,甚至地图库,你甚至需要确认说提到的地点在地理上确实是相近的。
6. 实体的链接

最好的知识库是什么?除了处理大量的非结构化数据之外,还有半结构化的数据,半结构化数据是天然的知识库,比如说你一行数据里面,有很多的名字、身份证号、手机号,后面还会加描述,事件的起因、结果等,文本里面提到的东西可以在自己所在的结构化字段行里找到更多的对应关系。
7. 一个文本处理工具

这个其实是我们自己研发的一款对于文本处理的工具,这个图说的是什么事情呢?大家可以看到最左边,左边是非常多的文字的描述,描述很多的事件,事件里面会有人、车,手机号,还会有实体关系的关键词的描述。通过这些实体和标识实体关系的挖掘,最后可以把文本里面描述的事件,最后变成一种图的结构化形式的展示。可以看到右上角这个人是有电话号码,还拥有一辆车,还跟另外一个人有亲属关系,这个人又有一个电话号码,整个文字里面提到的故事情节都可以被结构化称实体之间的关联,这个可以非常方便的让我们的相关的业务人员能够看到这个文字里面到底描述的是什么。一篇文本不算什么,但是一万篇文本里面的提到的人和事件做关联的话,很多事情就很好的分析了。
这个产品其实是在整个的 SCOPA 里面的组成部分,在非结构化数据里面帮助我们进一步完善整个关系的挖掘,包括我们能够全方位,更多的把更加全面的关系挖掘出来。我今天的演讲就到这里,谢谢大家!
Q1: 文本的实体分析目前我们明略识别的准确率是多少?
A1:利用纯粹的自然语言处理技术,人名的识别率能够达到 95%,地名也在 90% 以上,但国内某些小城市的名字比较有特色,如“任城镇”这类,就不容易识别对,如果没有地理信息库的话。
Q2: 感觉明略的大数据专家团队女性很少很少,女性在从事这方面工作中有什么样的明显劣势?
A2:女生确实偏少,但我相信后续会越来越多。我们的工作氛围和互联网公司非常像,扁平管理,所有人都能学到和了解到公司的方方面面。胆大心细的女生其实会有更大的机会。
Q3: 文本的实体关系分析有成熟的方法论吗?感觉还是在就事论事的阶段。我们都是到 plantir 在 connect 方面做的很牛,有可借鉴的地方吗?
A3:我们有自己的 NLP 开发 SDK,但是我们不会把所有问题都使用同样的 pipeline 来处理。我们非常在意准确率。Palantir 的方法其实大家都在猜测,但我们认为足够多的数据以及优秀的人才才是真正的核心。
Q4:实体的识别是根据分词后的词性得到的吗?你提到分词模型要重新训练,所用的训练数据源是怎么得到的,是靠专家的标记么?
A4:实体的识别可以把词性加到特征里面,还可以加入更多的特征。我们所使用的数据源来自于客户,但是并不需要专家来标记。
Q5:老师,我想向大数据发展,怎么开始?
A5:最好的建议是把现有的工作做好,提升内功,然后找机会进入一家大数据公司,比如明略数据
感谢杜小芳对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。




