

一、背景
携程是业界比较早进行 AB 实验的公司。AB 实验可以简单认为是传入一个实验号和用户分流 ID 到 AB 实验分流器,分流器吐出分流版本 A、B、C、D 等,通过截取应用流量落地一段时间的分流数据,就可以分析具体版本的优劣,决定启用新版本或者沿用老版本。
携程的 AB 分流器沿用至今,在业务发展上发挥了很大作用,但也存在一些问题。
1)携程内部,除了携程 App,还有小程序、Online 页面等都在用 AB 实验分流器,这些分流器是不同部门维护的不同接口,导致 AB 实验人员在开发的时候,有时候会用错,或者经过几轮沟通才能找到适合的分流器接口;
2)AB 实验分流器在公司越来越多的 AB 实验应用接入的时候,响应效率不尽人意,没有开始的时候那么好。还有实验新配置的分流规则,在一个访问量大的页面如携程 App 酒店主页上很难即时生效,有时候要等到凌晨访问量较少时才生效;
3)AB 实验方法论也需要改进,从而更精确地指导 AB 实验结论。但 AB 实验分流器前端接口里直接引用了 AB 实验配置表的全量字段信息,导致 AB 实验配置表随着 AB 实验方法论改进更新的时候,AB 实验分流器也需要更新换代,这对公司的各个实验应用方来说是不可接受的。
基于此,我们开始着手携程 AB 实验分流器的改进。AB 实验分流器的效率改进是重中之重,收口公司众多的分流器接口,迁移旧接口流量到新接口和推进公司 AB 实验应用采用新分流接口,这样才可以适应 AB 新方法论上的 AB 实验配置的更新迭代。
二、改进结果
截至到目前,除少量在 2020 年年底计划下线的.net 应用外,其他的应用都通过公司的 slbportal 工具把分流流量迁移到改进过的新 AB 实验分流器接口,或者直接采用了新 AB 实验分流器。下面贴上新旧 AB 实验分流器的改进效果,供大家参考。
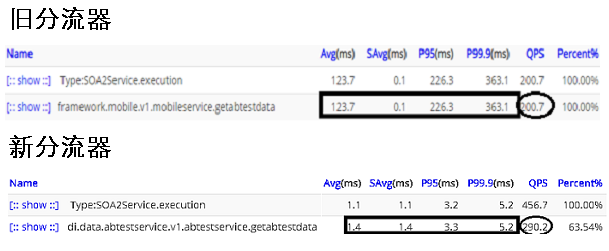
从以上的流量统计图可以看出,新 AB 实验分流器在 QPS 相应更大的情况下(200.7->290.2),P99.9 线反而表现的更好(363.1ms->5.2ms)。可见新 AB 分流器的响应更快,对旧 AB 实验分流器接口的效率改进还是比较显著的。
三、改进方案
本文将从 AB 实验分流器整体设计,收口,SDK 设计和分流器后台选型设计方面进行分享,主要说明如何提升 AB 分流器的分流效率,希望给 AB 实验特别是 AB 实验分流器的开发人员带来一定的启发和帮助。
3.1 AB 分流器整体设计
AB 分流器整体设计是用 SDK 还是 service 方式,是一开始就要制定的,因为如果方向搞错,后面都要重新来。
采用 service 有改动和运维方便等优点,但考虑到全公司都在使用 AB 分流器,如果用 service 方式,除了网络访问 service 影响分流效率外,携程用户的每台手机,每个 pc 和小程序页面等都可能调用到这个 service,对 service 的冲击还是很大的。
一个访问量很大的 AB 实验页面,也会影响到其他访问量相对小的 AB 实验页面,这也是不公平的。所以用驻留 SDK 的方式,把 AB 实验分流器分发到各个部门的各个 AB 实验应用中,让各个部门自行根据 AB 实验流量调配资源,分流效率也可以最大化。
3.2 AB 实验分流器收口
文章开头提到携程 AB 实验几乎在用户能用到的携程产品上无处不在,携程 App、小程序等,这些 AB 实验调用的是不同部门开发的不同的 AB 分流器。
AB 实验最重要的是两个口子,一个入口是 AB 实验分流器,一个出口是 AB 实验分析报表,入口要进的简单,出口要出的明白。收口这些众多的分流器接口到一两个简单接口,对 AB 实验开发人员和 AB 分流器的开发维护都是有利的。
下图概括了 AB 实验分流主要接口的收口工作(左边是旧分流器接口,右边是新分流器接口):
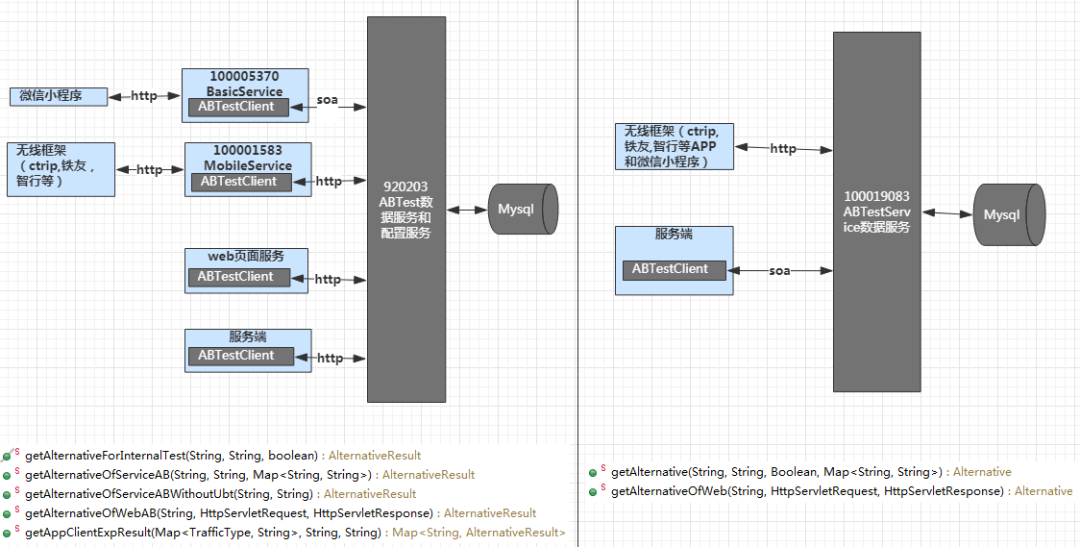
3.3 AB 实验分流器 SDK 设计
分流器收口的效果是显而易见的,原来需要跨部门多个接口沟通解决的事情,现在一个部门一个接口就可以了,开发测试也方便。
新分流器 SDK 完全兼容旧分流器接口的业务功能,并做了一个主要的技术改进,从“胖”SDK 变成“瘦”SDK。
旧 SDK 中,当一个实验分流请求过来后,会关联查询缓存里实验的各种 AB 实验表信息,如实验域、实验层、分流规则(分流桶)和指定版本等信息,然后计算一个分流版本信息返回。
新 SDK 缓存里只有一个类似 AB 实验宽表的信息存在,这个宽表是影响实验分流的各个字段信息的最小集,去除了旧 SKD 中的对分流结果无影响的分流频道等字段信息。最小集定义好后,基本就固定不变了,旧 SDK 里的关联查询动作在新 SDK 里推到分流器后台去做。
上述最小集宽表的存在,让 AB 实验系统在改进 AB 实验方法论后进行的不断迭代开发过程中,不用频繁替换 AB 实验应用的分流器。因为、新 AB 分流器后台会提前关联查询,组织好宽表数据提供给前端的分流器 SDK 使用就可以了。
上述的减肥操作让分流器 SDK 的效率提高一大截。另外旧分流器 SDK 的实验缓存没有读写分离的概念,当 AB 实验页面,如携程 App 酒店主页有大量并发请求过来的时候,有可能会导致 AB 实验新配置的分流规则或者指定版本等很长时间不生效,新 AB 分流器 SDK 缓存引入了 CopyOnWrite 的设计,让影响到分流的 AB 实验改动能够快速生效。
3.4 AB 实验分流器后台选型设计
AB 实验业务特点是读多写少的,写有单个数据的写入,也有批量数据的写入,采用 CopyOnWrite 设计可以很好地支撑这种场景,后面讲到的分流器后台分布式缓存系统也采用了类似的设计。
旧 AB 实验分流器后台通过 SOA 服务直接读取 DB 里的 AB 实验分流配置信息,会让 DB 成为 AB 实验分流的瓶颈。SOA 服务可以根据分流器请求的流量自动扩容缩容,但 DB 不是。DBA 看到复杂的 sql 查询,还有这么多的访问量的时候,也是不允许的。
所以新 AB 实验分流器后台需要在 DB 前面多加一层前置的数据缓存系统来提高分流效率,这个缓存系统是采用公司成熟的 qconfig 还是 redis,或者结合 AB 实验特点自己部署一个分布式缓存系统呢?
AB 实验通用的业务操作是对一个实验进行用户分流,也有对同一类型的实验进行分流,如携程 App 对这个 App 版本下的所有 App 页面端实验进行分流,这也是为分流效率考虑的。
qconfig 可以进行简单配置数据的实时推送,对于 AB 实验这样稍显复杂并且是大批量的关系型数据是不太适合的。举例来说,一个携程 App 上的 AB 实验分流器需要拿到所有手机页面进行的实验,是在 qconfig 上一个配置文件中配这些所有实验,还是每个实验一个配置文件?
单一一个配置文件会让携程 App 访问公司 qconfig 服务器成为一个很大的 IO 操作,多个配置文件会让携程 App 收到这些改动的实验配置信息后,还要进行聚合操作。qconfig 中会存在一个“长连接”来进行实时配置信息推送,每个 AB 实验应用的多个设备上都会建立一个和 AB 实验分流后台 qconfig 服务器上的这样的连接。“长连接”是很难适时根据流量进行扩容和重连的,公司的灾备演练过程中出现的 apollo 和 qconfig 配置系统负载过高就说明了这一点。因此新 AB 实验分流器后台的设计中首先排除了 qconfig 这一方案。
redis 在公司和业界用的比较成熟,采用 redis 如出现数据问题,可以给到公司的 redis 框架部门解决。但任何设计都是为业务服务的,如果一个流行的方案不适合现在的业务,那就要考虑改进或者自行设计了。
还以携程 App 页面端实验分流为例,可以把 app 页面端单个实验的名称作为 redis 的 key,value 里存影响实验分流的关联字段信息。当更新一个或者多个 app 页面端实验,或删除一个或者多个过期的 app 页面端实验的时候,批量读取 app 页面端实验就会产生不一致的现象。
如果把这些批量的 app 页面端实验分流信息组合放在一个 key 对应的 value 里,这个 key 的读取效率就会很差,会影响到其他类型单个实验信息的读取。AB 实验分流的字段信息比较多,就一个 AB 实验指定版本 varchar 字段已经定义为 20000 还不能满足某些部门的需求,可以想象多个实验分流放在一个 value 里, size 会有可能很大。
AB 实验分流的一致性设计要求是要高于时效性的,可以晚一点拿到最新的分流规则,但同一时间读取到的实验分流应该是一致的,这对于 AB 实验报表分析也是有利的。
综上所述,redis 不大适合 AB 实验分流,其分布一致性 hash 也未必能满足特定的 AB 实验业务数据扩展的需求,在其上改动的成本也大。所以我们在 apache ignite 的基础上开发了一套分布式缓存系统,满足实时性、一致性、高并发、高性能、高可用的需求。
这套分布式缓存系统可以走公司 paas 发布系统发布,系统节点可以纳入公司的监控告警系统,可以水平扩展,可以以 key-value 的形式写入 annotation 标记过的 java object,以符合 ANSI-99 语法的 sql 语句读出,一个个分布式缓存节点发布的时候不影响缓存一致性的读取。AB 实验分流器后台部署图如下:
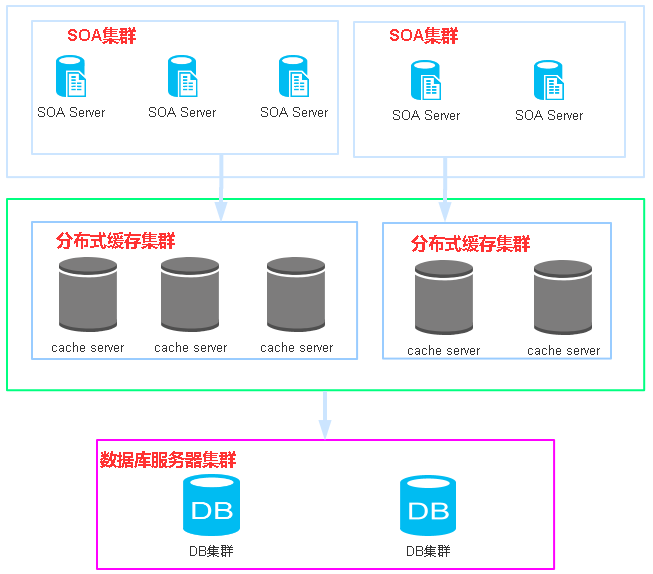
上端是 SOA service 供 AB 分流器调用,中间是分布式缓存系统,下端就是 AB 实验配置数据库。
AB 实验分流系统后台取数据的概要设计如下:
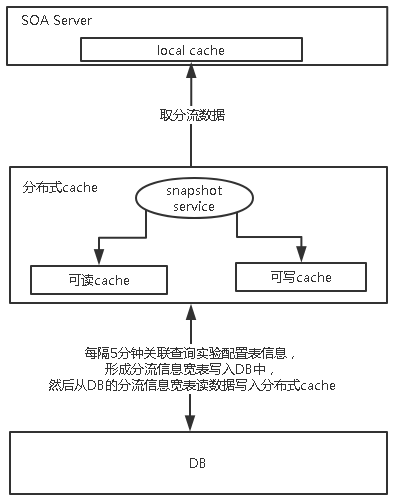
上图的分布式缓存系统部署有一个 snapshot service,这个 service 负责每 5 分钟关联生成分流信息宽表,把可写 cache 清空,然后把分流信息宽表的全量数据写入。写入完成后会把可写 cache 标成可读 cache,可读 cache 标成可写 cache,每次 soa 访问分布式缓存系统的时候,会先从 snapshot service 里检查哪个 cache 是可写的,然后从可写 cache 中读数据,可读和可写 cache 的数据有效期都设置成一天。
Snapshot service 这种设计可以避免前面 redis 方案中提到的批量数据一致性的问题,效率上也是好的,相当于读写分离。可以认为 snapshot service 是分布式缓存系统的数据自治中心,在分布式系统重启的时候,还能自动从 DB 中再拉取组织数据。这种设计还有别于通用的缓存设计 cache aside, read/write through 和 write behind 三种设计。
AB 实验分流系统后台实时更新数据的概要设计如下:
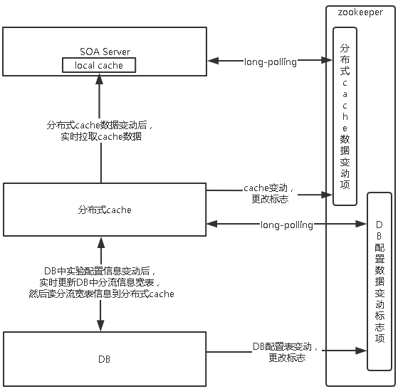
上图设计可以让分流实验数据改动后实时在分流器中生效,而不是在分布式缓存系统 5 分钟后更新全量分流宽表信息后才生效。注意在设计中没有采用用消息包里放改动的实验分流信息,让 SOA service 收到消息后立即改动对应实验,而是 SOA service 收到消息后,再重新以拉的方式读一遍数据。通过一种方式更改数据比通过多种方式更改数据更安全,检查问题也方便,同时也能聚合并发的消息再拉取。
四、后序
携程 AB 实验分流器的改进和设计大致情况如上所述。目前改进的新 AB 实验分流器和分流器后台在公司的几次灾备演练中表现的很稳定。分布式系统在开发的时候遇到过分布式唯一标示控制和读取的问题,在部署分布式系统时遇到过 snapshot service 重复部署的问题等,这些都一一解决了。
在公司灾备演练切换集群网络的过程中,出现过后台的分布式缓存系统无法从单点系统恢复成多点系统的问题,这可能是分布式系统的共病。因为掉线的节点数据的一致性校验是很繁琐的,这时候需要手工重启下掉线的分布节点。
AB 分流器设计还有很多需要完善的地方,譬如实时缓存监控和告警等,路还没走完,要眼望前方,同时要时不时回头看看,总结提高。
作者介绍:
Will Wang,携程技术专家,负责 AB 实验分流和其他数据智能项目的开发。关注大数据和分布式方面,会做一些深入的开发部署和结合业务数据的基准调试工作。
本文转载自公众号携程技术(ID:ctriptech)。
原文链接:
https://mp.weixin.qq.com/s/yleskA9beaSCpFVD4uroqw

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论