

结合 UDDB 的功能特性和产品理念,我们明确了它的发展方向——基于数据库中间件来做公有云上的分布式数据库。在刚开始选择较为简单的工程实现复杂度,然后通过公有云这种互联网服务的快速迭代能力和在线服务能力,不断的提高对业务的支持度,从而覆盖更多的业务。最终演进为大数据时代的分布式数据库解决方案,为互联网、物联网、传统行业的转型提供海量数据存储、处理的在线服务。
UDDB 的技术演进路径
虽然技术服务于产品,而产品的发展方向体现了根据客户和市场所做的战略思考,但是在执行层面上,还只是一个模糊的目标。因此,在技术实现上,需要把执行的路径想清楚,才能将目标清晰地落地。互联网创业,强调的是树目标、定路径、滚雪球式发展。其中,定路径是关键的一环:向上,必须与战略规划很好地对接;往前,每一步都要踩到点上。如此,才能在每一个阶段创造价值,吸收资源,发展壮大。
执行路径的确定,需要回归到客户需求上,要深入到客户业务中,去寻找规律和办法。通过大量的调研,我们发现目前技术圈的热点:超大表水平拆分问题,其实并不是客户主要的痛点,读写分离和垂直分库的需求,反而是沉默的大多数。从技术演进的趋势来看,水平拆分必然是分布式数据库最终的目标。
但现阶段水平拆分对 SQL 的支持度不高,导致为了做水平拆分,很多业务层必须要做脱胎换骨的改造。因此在数据量或性能要求还没有到这个程度的情况下,客户并不希望为了水平拆分做业务层的改造,而是倾向于更保守的读写分离和垂直分库策略。UCloud 技术团队基于客户的这个诉求,最终确定了这样一条技术演进路径:
基于数据库中间件,用最短的时间做到一主多从读写分离场景下 100% 兼容 MySQL,让客户的业务在库表零变动、代码零改动的情况下,使用上 UDDB;
在垂直分库场景下对 MySQL 的 100%兼容,让一部分有垂直分库需求的客户,只需要调整好库表位置,即可将业务接入 UDDB;
逐步完善对水平拆分的支持,在产品推出初期,功能对齐业内主流数据库中间件。后续进一步完善对 SQL 和事务的支持,结合对存储系统(MySQL)的优化、裁减或替换,实现最终的产品目标。
在技术演进上,三个阶段并非割裂,每一个阶段目标的达成,都为下一个阶段的目标做好铺垫。在读写分离和垂直分库场景下,实现对 MySQL 的 100%兼容,核心在于构建一个完全对齐 MySQL 的语法解析器,解析完成后识别 SQL 的操作类型,即可进行读写分离;识别 SQL 的作用对象(库/表/视图),即可在垂直分库场景下,将 SQL 进行有效路由和透传;语法解析器的完善和成熟,又为水平拆分场景下,完善语义分析、分布式执行计划的生成、优化和执行打下了基础。
总之,UDDB 的最终目标就是通过该技术演进路径,成为一款基于 Shared-Nothing 架构的分布式数据库。
在系统架构和计算模型上,数据库中间件+MySQL 节点的分布式数据库解决方案和 NewSQL 产品本质上是一回事。限于本文的主题,关于数据库中间件和 NewSQL 讨论,在此不作展开。
UDDB 的技术实现
技术路径的确定是将产品目标进行落地,而技术实现则是将技术路径进行落地。到了技术实现的层面,重点有两个:第一是把基础打好,让产品的生长有一个牢靠的地基;第二是要进行大胆创新,在时间和人力资源有限的情况下,通过灵活巧妙的办法满足客户的需求或解决客户的问题。
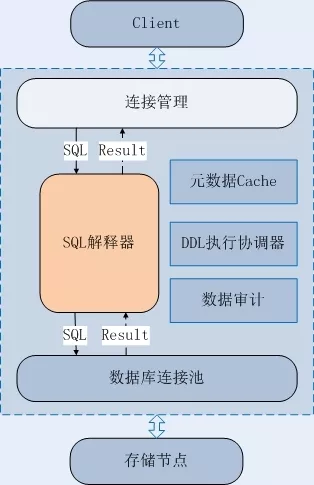
1 UDDB 的系统架构

如图所示 UDDB 的整个架构主要有三大模块:
UDB 资源池:等同于 UDB 产品的资源池, UDDB 存储节点和只读实例直接复用处于同一可用区的 UDB 资源。
分布式数据库中间件系统:基于数据库中间件技术构建的分布式、多租户数据库中间件系统由以下几个模块构成:Routerd、 Mgrd、高可用 UDB 实例(负责元数据和配置存储)、Zookeeper 集群(负责决策和调度)。
UDDB 管理控制台:提供 UDDB 创建、管理、释放等操作的 Web 界面。
我们可以从以下两个方面理解该系统架构:
一、从左往右,以业务访问的视角来看待该架构,可以看到:
客户可以通过标准的 MySQL API 或者客户端来访问 UDDB, 客户的请求均发往 ULB,由 ULB 转发到某个中间件节点的 Routerd 模块。
Routerd 模块将对客户请求进行分析:
如果是 DML 请求,则在进行处理后,直接转发到相关的 UDB 节点,然后将各 UDB 节点的返回结果进行聚合并返回给客户端;
如果是 DDL 请求,则通过 Zookeeper 集群,将该 DDL 任务通知到 Mgrd 模块。 由 Mgrd 模块将该 DDL 任务取出、处理并广播到 UDDB 下 所有 UDB 节点。广播完成后,将返回结果按原路经 Zookeeper 集群递交到 Routerd ,最后返回给客户端。
二、从右往左,以系统管理的视角来看待该架构,可以看到:
UDDB 的创建过程基本等同于目前利用数据库中间件软件+ MySQL 实例+负载均衡组件来搭建一个分布式数据库解决方案的过程。这个过程为众多开发团队的研发或者 DBA 所熟悉, 而 UDDB 的管理平台无非是对这些流程做了一个完整的封装,把这些烦琐的操作替换为点击鼠标即可搞定。
2 SQL 解析和路由模块
UDDB 在架构上注重稳健务实,而在 SQL 的解析和路由模块(Routerd)的设计和实现上,则注重规范和专业。
Routerd 的核心是一个 SQL 解释器。它接收 SQL 语句,解析其语法和语义,确定该 SQL 影响哪些 UDB 节点,然后将 SQL 转换成子 SQL 并下推到相关 UDB 节点。待 UDB 节点将结果返回后,可能需要根据原始 SQL 的语义将结果进行过滤聚合,最终返回到客户端。
该 SQL 解释器的完善程度是 Routerd 的一个重要设计指标。SQL 解释器越完善,则对业务的支持越好,能够支持的客户端就越多,从而具备更好的通用性。公有云产品不能限制客户类型和使用场景,因此通用性是非常重要的指标。
业内不少历史悠久的数据库中间件,虽然稳定可靠支撑了不少实际项目,但是其 SQL 解释器,却一直做得不够好。考察业内各种数据库中间件的源码实现,我们可以看到, 不少中间件的实现存在两个问题:
①有的中间件没有独立的 SQL 语法解析模块,而是直接复用其他数据库(如 SqlLite)的语法解析器,或者开源 SQL 解析库(如 alibaba druid)。短期内,这种做法的确能够让项目迅速得以推进,但是后续功能的扩展却往往受制于该 SQL 语法解析器,因此不利于产品的长期发展。
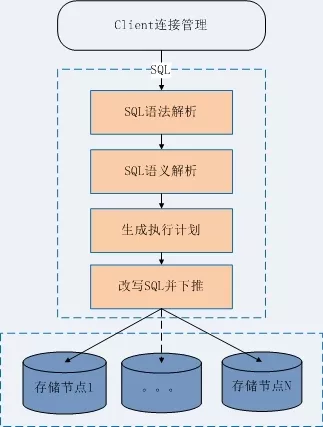
②有的数据库中间件有独立、规范的语法解析器,但是在语义解析上做的不够专业,这些中间件一般的解析流程如图:
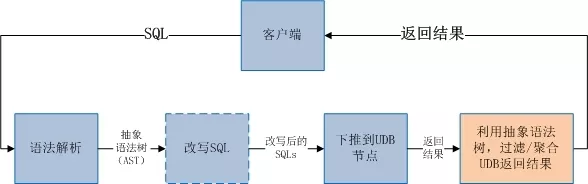
这样虽然也能够让中间件工作,但是 SQL 的生成和结果的过滤聚合,都依赖抽象语法树(AST)来完成。然而 AST 结构复杂,携带信息也有限,使用 AST 来做 SQL 的生成和结果的过滤聚合,一方面会带来编程上的复杂度;另一方面也不能执行一些复杂的操作,比如 group by、order by、distinct、limit 和集函数同时存在的 SQL 语句的聚合操作,因此很难实现通用性和可扩展性。
如何做好 Routerd 的通用性? 可以从两个方面着手:
第一是基于 Lex&Yacc 构建一个独立、规范的语法解析模块。让研发团队做到对 SQL 语法图和 SQL 语法解析实现,做到了如指掌。这样才能在有 Bug 时迅速修复,需要添加新功能时能够立即支持。
第二是采用类似数据库系统实现的方式,来实现 Routerd 的语义解析。如大家所知,通用的数据库系统,执行一条 SQL 有规范的流程如图:
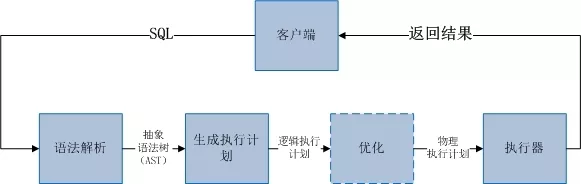
流程可以概括为语法解析、生成执行计划、执行计划优化(查询优化)和执行 4 个步骤。每一个步骤能够很好地解耦,步骤之间通过约定的数据结构来交互。这些数据结构中,执行计划是最核心的,它详细描述了 SQL 的语义、涉及到哪些数据库内部对象以及对这些内部对象操作的顺序。
参考数据库系统的 SQL 解释流程,UDDB 的 Routerd 模块的流程是:
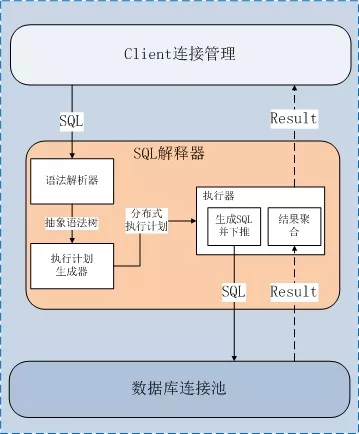
Routerd 中的分布式执行计划:一方面是对抽象与语法树结构更加精简、扁平的描述,让子 SQL 的生成更方便;另一方面,加入 SQL 结果过滤聚合的控制信息,方便对 UDB 节点返回结果的提取、过滤和聚合。
经过一年多的演进和迭代,UDDB 的分布式执行计划和计划执行在逐步完善。从最初实现对单表 SQL,以及落到同一节点 的 JOIN SQL 的 100%支持,到支持多表跨节点 Join、分布式事务这两个核心功能(分布式事务功能目前内测中,跨节点 JOIN 计划于 2018 年上半年推出)。
实践证明,通过合理的架构,能够让 UDDB 从一款简单的中间件出发,走向更开阔的未来,成为基于 MySQL 并保留 MySQL 原生部署和运维体验的,真正的分布式数据库。同时,引入和数据库内核同样的架构,这意味着还可以添加执行计划优化的环节,对分布式执行计划进行优化,最终不仅在功能上对齐单机数据库,在性能上也有不断优化的空间。
3 读写分离模式 100%兼容 MySQL
接下来我们将给出读写分离 100% 兼容 MySQL 的一个创新性的技术实现供业内参考。垂直分库实现对 MySQL DDL、DML 语法的 100% 支持,其原理也类似,在本文中不做赘述。
如果做一款单纯的读写分离中间件, 在这款中间件中做到 100% SQL 兼容并不难。 只需要对 SQL 做轻量的解析,识别 SQL 的是读 SQL 还是写 SQL,然后使用透传的方法透传到主从节点即可:
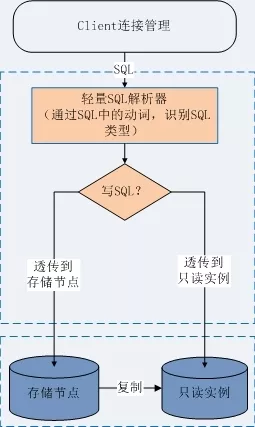
作为一种描述性语言,SQL 的语法有一个非常明显的规律:最前面的单词必然是操作行为(动词), 后面是操作对象(名词)和限制条件。而从操作行为即可完全判断出该 SQL 的读/写类型(call 存储过程除外,因为存储过程可写可读)。因此只需要提取前面几个单词,即可做正确的路由。
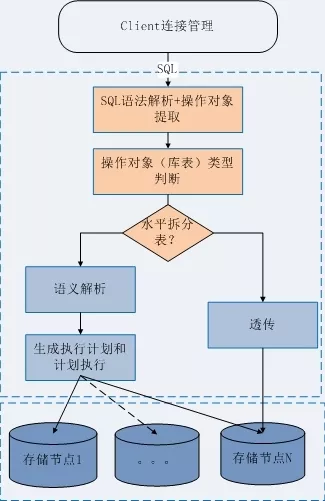
通过这两个流程可以看到读写分离和水平分表两种模式,在技术实现上的一个矛盾:读写分离假定所有的表都是不拆分的普通表, 需要提取 SQL 中的动作语义来识别读写 SQL,继而将 SQL 进行透传; 而水平分表模式下,则需要提取 SQL 中的作用对象,识别到底是哪几张表,然后进行表名的改写(必要时也进行其他子句的改写)。两者提取信息的逻辑没有交集,导致两种模式无法有机结合。
4 UDDB 的技术创新
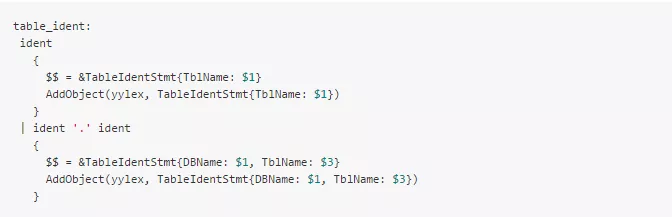
**1.修改语法解析模块:**在解析 SQL 生成抽象语法树的同时,将 SQL 中的库表名称提出到一个链表中。 假如语法解析器足够规范,那么必然会有一个或几个非终结符用于归约 SQL 中的库表名称。此时,可以在这些非终结符对应的语义动作代码中,增加将库表名称保存到链表的操作:
**2.在语法解析之后获得抽象语法树以及链表,然后扫描链表,依次取出该 SQL 涉及的库表名称,**结合中间件的元数据信息,判断这些表是普通表还是水平分表。如果都是普通表,则将该 SQL 按照读写类型透传到主节点或从节点;如果是水平分表,则再进行语义分析、执行计划生成和计划执行。
通过以上两步,做到读写分离模式下,SQL 接近 100% 的兼容以及读写分离模式和水平分表模式在一个产品中和谐共存。
这其中的关键点在于语法解析模块:需要实现一个规范完整并且能够和 MySQL 官方对齐的语法解析模块,有了该模块即可做到对所有 SQL 都能够进行语法解析,在解析过程中进行库表提取;同时, 需要精心设计该语法解析模块,将所有 SQL 的库表子句,抽象为特定的几个非终结符,从而方便植入库表提取代码。
该方法的优点在于性能和实现上的简单:库表的提取,充分复用了语法解析过程,没有额外的开销;库表类型(普通表/水平拆分的大表)的判断,则只需要扫描提取出的库表链表即可完成,性能开销几乎可以忽略不计;实现上也非常简单,总共不超过 150 行代码。
结语
本文介绍了 UDDB 的技术演进路径及其背后的系统架构技术实现原理,以帮助客户解决单机 MySQL 中的问题、让客户业务运行更顺畅为宗旨。结合 UCloud 高水平的数据库内核开发能力,打造了一个结构规范、实现工整的数据库中间件,具备独立完整的语法解析、语义解析、执行计划生成和计划执行模块;我们不断解决 MySQL 的兼容性问题,目前已经支持所有的 MySQL 客户端管理工具,包括 PhpMyAdmin、Navicat、SequelPro 等。
2018 年上半年,我们将实现对分布式事务和分布式 Join 的原生支持,从而完成对存储、事务以及 SQL 执行三大块的分布式化,最终成为既保留 MySQL 原生部署和运维体验,又彻底解决单机 MYSQL 容量和性能问题的真正的分布式数据库。
本文转载自公众号 UCloud 技术(ID:ucloud_tech)。
原文链接:
https://mp.weixin.qq.com/s/1WTvSg3MxdPvOzyJYPTy8g

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论