

随着公司业务的快速发展,离线计算集群规模和提交的作业量持续增长,如何支撑超大规模集群,如何满足不同场景的调度需求成为必须要解决的问题。基于以上问题,快手大数据团队基于 YARN 做了大量的定制和优化,支撑了不同场景下的资源调度需求。
今天的介绍会围绕下面四点展开:
调度相关背景及快手数据规模与场景
快手调度器 Kwai scheduler 介绍
多调度场景优化介绍
其他工作 &未来规划
快手数据规模场景
1. 快手数据规模
目前快手离线计算单集群数万台机器,每日处理数百 P 数据量,百万级别作业,对大数据存储,计算,调度有非常大的挑战。首先介绍下快手大数据架构体系技术栈。
2. 快手大数据体系架构介绍
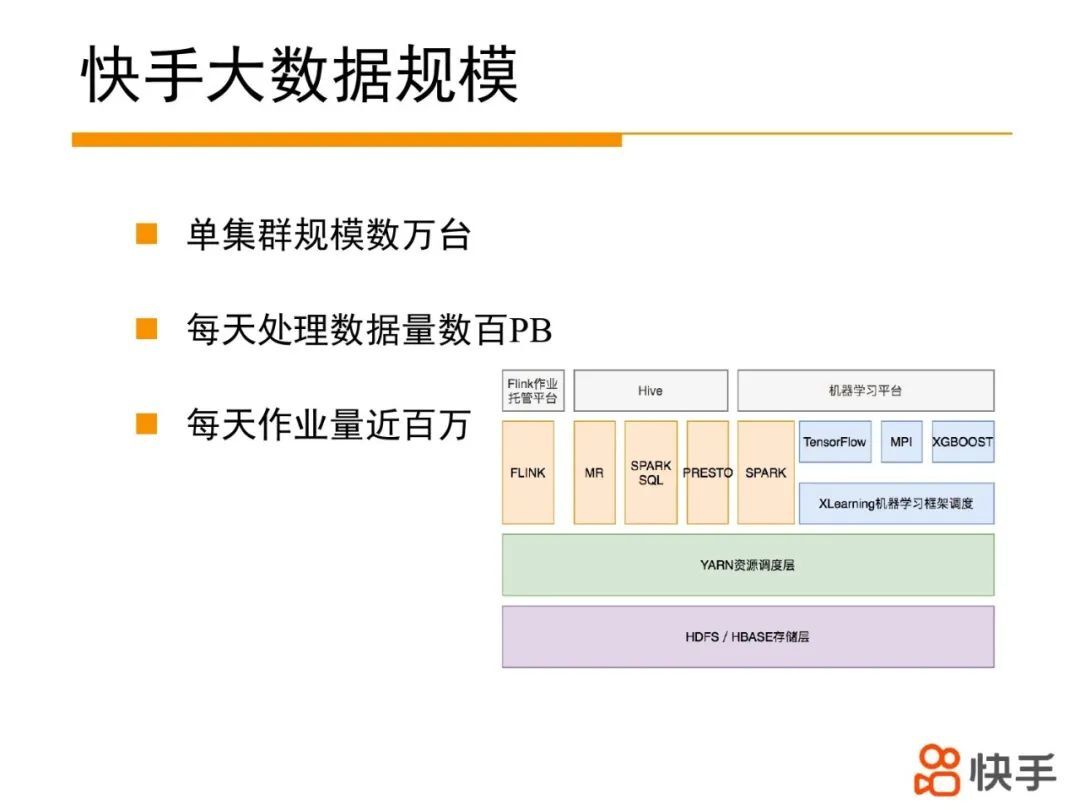
快手大数据架构底层采用 hdfs/hbase 构建数据存储层,用于支撑海量数据的存储;上层是 YARN 资源调度层,实现百万级别的作业和任务调度;再上层是各种计算引擎构成的执行层,如 Flink、MR、SPARK,PRESTO,TensorFlow 等计算框架用于执行业务的计算任务,最上层属于应用层如 FLink 作业托管平台,机器学习平台,以及 SQL 提交平台,面向用户提供服务。本次分享的 YARN 属于资源调度层,用于把计算引擎的 Task 快速调度到合适的机器上。
3. YARN 资源调度系统介绍
YARN 背景介绍:
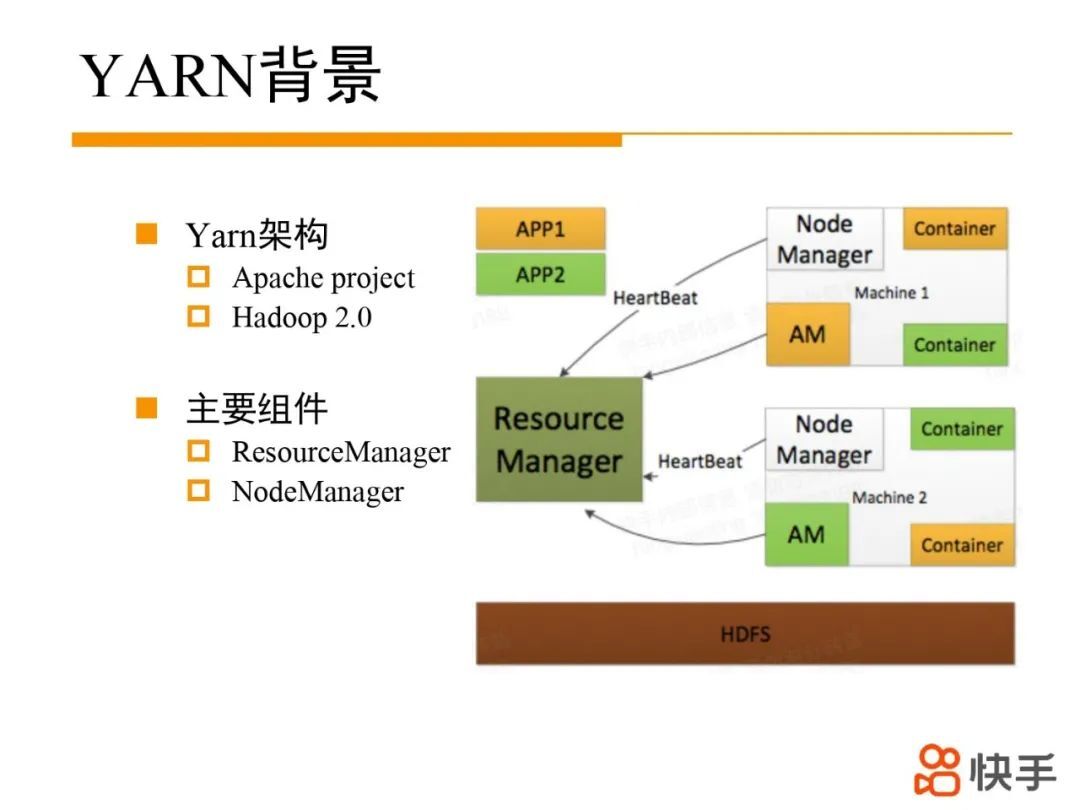
YARN 是 Apache Hadoop 旗下的顶级项目,Hadoop 2.0 发布时引入,主要用于解决 hadoop1.0 面临的集群调度性能和扩展性问题。通过把集群资源管理和作业资源管理拆分成 ResourceManager 和 ApplicationMaster 两个组件,实现调度架构从单级架构向二级架构的转变,提升了集群性能。YARN 专注于集群资源管理和调度,包含 ResourceManager 和 NodeManager 两个核心组件;ResourceManager 负责集群资源管理和分配;NodeManager 在每台机器上部署,负责管理所在机器上资源。
YARN 调度器演进过程:
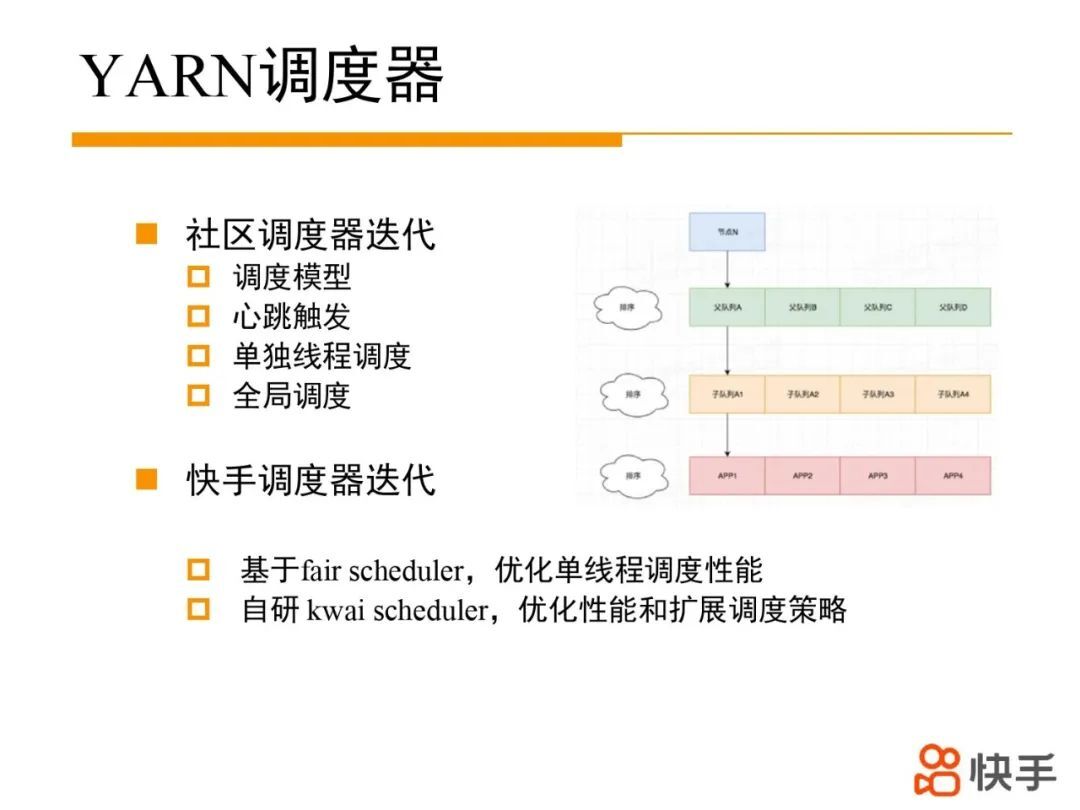
原生 YARN 在调度过程中,先选择一个节点,并对队列进行排序,递归从 root 队列找到最优的叶子队列,再对叶子队列中运行的 app 进行排序,选出 app 在这个节点上调度资源。随着集群规模增长和队列数目的增加,调度耗时越来越长,调度吞吐成为制约集群规模的主要瓶颈。为提升调度吞吐,调度器的发展经历了三个阶段:第一阶段通过心跳触发调度过程,实现比较简单,但心跳处理逻辑和调度逻辑在同一个线程,调度和心跳处理逻辑会相互影响。第二阶段将调度逻辑剥离到单独的线程以降低调度和心跳逻辑耦合性,从而提升了调度性能;但调度逻辑和心跳处理共享一把大锁,并且调度过程中对队列排序占据大量时间,整体性能提升有限。第三阶段引入全局调度器的概念,可以并发对队列资源进行调度,最终通过统一的 commit 过程保证调度结果一致性。多线程并发调度可以提升调度性能,但没有解决调度过程中排序耗时过多问题,并且引入的多线程调度,会损害调度结果的公平性。
快手基于 fair scheduler 单线程调度版本,不断优化单线程调度的性能,但由于单线程调度的局限性,在集群节点接近万台规模时,集群性能出现瓶颈;上线自研的 kwai scheduler 调度器后,在集群调度性能上有极大的提升,目前单集群规模已达数万台,同时在调度策略方面,支持可插拔的调度架构,方便扩展新的调度策略。
Kwai scheduler 调度器介绍
kwai scheduler 主要用于解决调度性能问题以及调度策略扩展性问题。性能方面,传统的调度器一次只能调度一个 task,并且在调度过程中需要对所有队列以及 APP 进行排序,有很大的资源开销;kwai scheduler 采用多线程并发批量调度模式,一轮可以调度数十万个 task。在调度策略方面,传统的调度器先选择节点再选择 APP,难以扩充新调度策略。kwai scheduler 先选择 APP 再选择节点,从而 APP 可以看到所有节点信息,通过对节点进行过滤与打分排序,可以针对不同场景扩展不同的调度策略。
1. 基于集群状态做全局批量调度
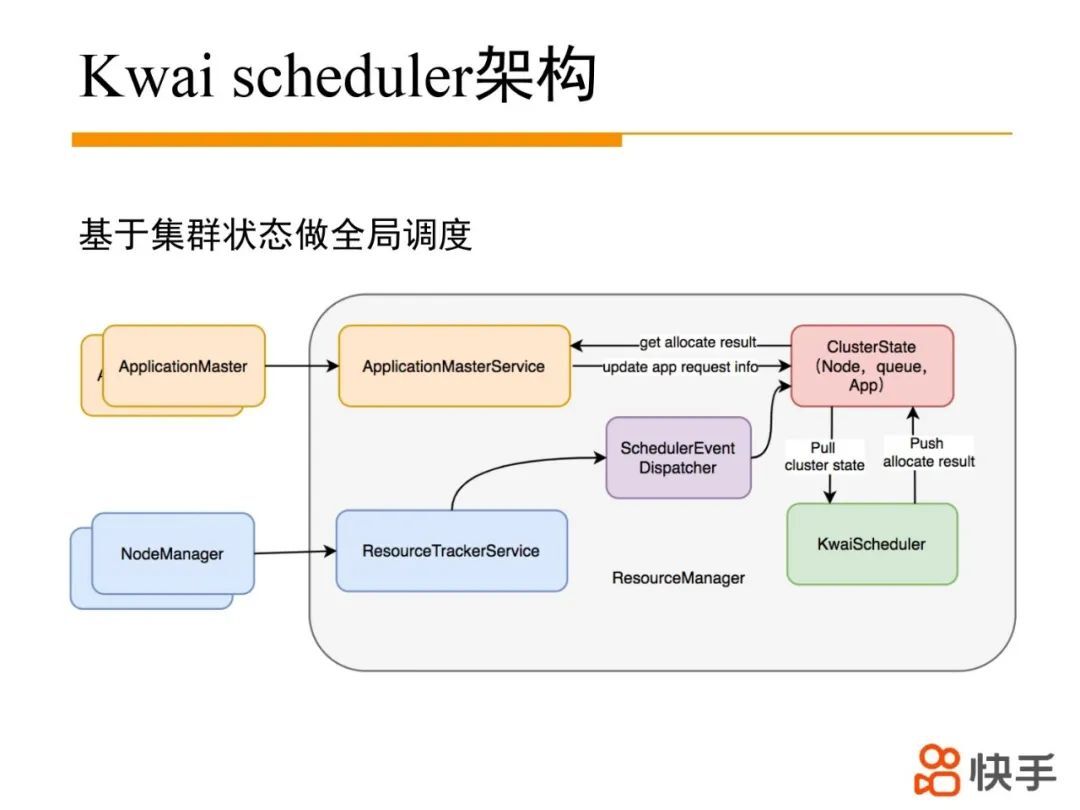
Kwai scheduler 整体架构如上图所示,ResouceManager 中 RPC 层和事件处理层基本保持不变,主要改动点是将调度逻辑做一个整体的剥离替换原先的 fair scheduler 调度。每次调度过程中拉取集群状态做镜像,基于集群镜像并发批量调度,调度完成后,将调度结果推送回去。App 可以通过原有的心跳接口获取调度 container。
2. Kwai scheduler 调度流程
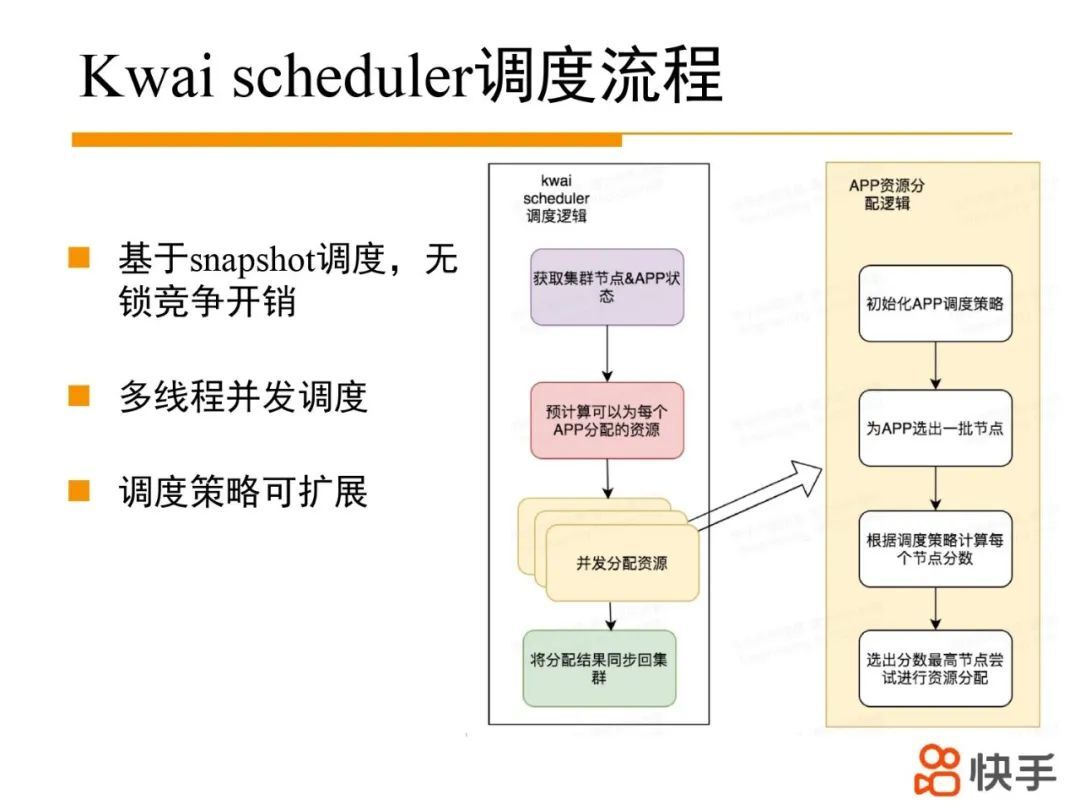
Kwai scheduler 基于集群镜像(节点的资源使用情况;队列的最小资源和最大资源量,以及当前资源使用量,APP 资源使用量和资源需求量等)进行资源的预分配,计算出每个 APP 可以在这一轮调度中分配多少资源。APP 根据预先分配到的资源量,并发去竞争节点上的空闲资源,如果竞争成功,完成 APP 的资源调度过程。
APP 资源调度过程中,可以根据不同场景为 APP 配置不同的调度策略,根据调度策略过滤节点并计算每个节点分数,选出分数最高节点尝试进行资源分配。调度过程中基本都是 CPU 密集操作,避免了锁的干扰(不同 APP 竞争节点资源时有轻量的自旋锁),有非常高的性能。并且不同的 APP 可以多线程并发调度,具备很好的扩展性。
3. Kwai scheduler 调度策略
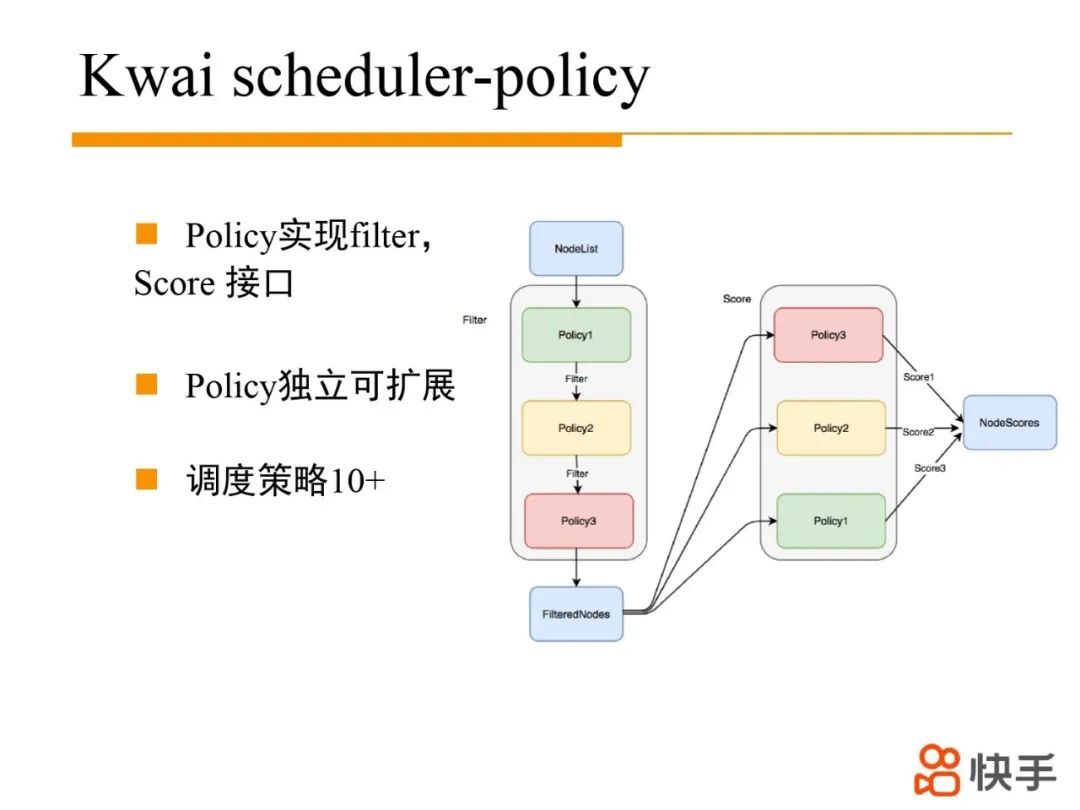
Kwai scheduler 调度策略主要实现 filter 和 score 接口。filter 接口用于过滤节点,score 根据节点信息,为节点进行打分,然后选出最优节点进行调度。比如 APP task 打散策略,根据每个节点分配的 APP 资源量,对节点进行打分,节点上分配的 APP 资源量越多,节点分数越低,从而把 APP 的 task 在集群范围内打散到不同的节点。
4. Kwai scheduler 调度线上效果
Kwai scheduler 上线后,支撑单集群数万台机器,1 万+作业同时运行,每天调度吞吐量峰值 5w/s+,资源分配率 93%+,同时支持不同的调度场景。
多调度场景优化
1. 离线 ETL 场景
离线场景下如何保障核心作业的 SLA 是比较核心的问题。在快手,核心作业和普通作业在同一个队列中,通过完善作业分级保障能力和异常节点规避能力,保障核心作业的 SLA。
离线 ETL 场景中经常会遇到以下情况以及相应的优化方案:
① 其他队列作业大量占据资源不释放
通过优化队列间资源抢占来解决这个问题。为防止抢占影响过大,默认情况下只有高优先级核心作业触发抢占,并且会限制每轮抢占的最大资源量。抢占过程中根据作业优先级,饥饿等待时间等条件动态计算每个队列可以抢占的资源量,从而把资源倾斜给优先级更高,饥饿等待时间更长的作业。
② 队列内低优先级作业占据大量资源不释放
在生产场景下如果低优先级作业占用大量资源不释放,导致优先级比较高的任务无法获取到足够资源,从而导致产出延迟。为解决这个问题提出基于虚拟队列来保障高优先级作业产出。所谓虚拟队列,是在物理队列下,按照一定逻辑规则(比如优先级)抽象出的逻辑队列。每个虚拟队列有一定的资源配额,并且会触发物理队列内部的抢占,从而解决上面的问题。
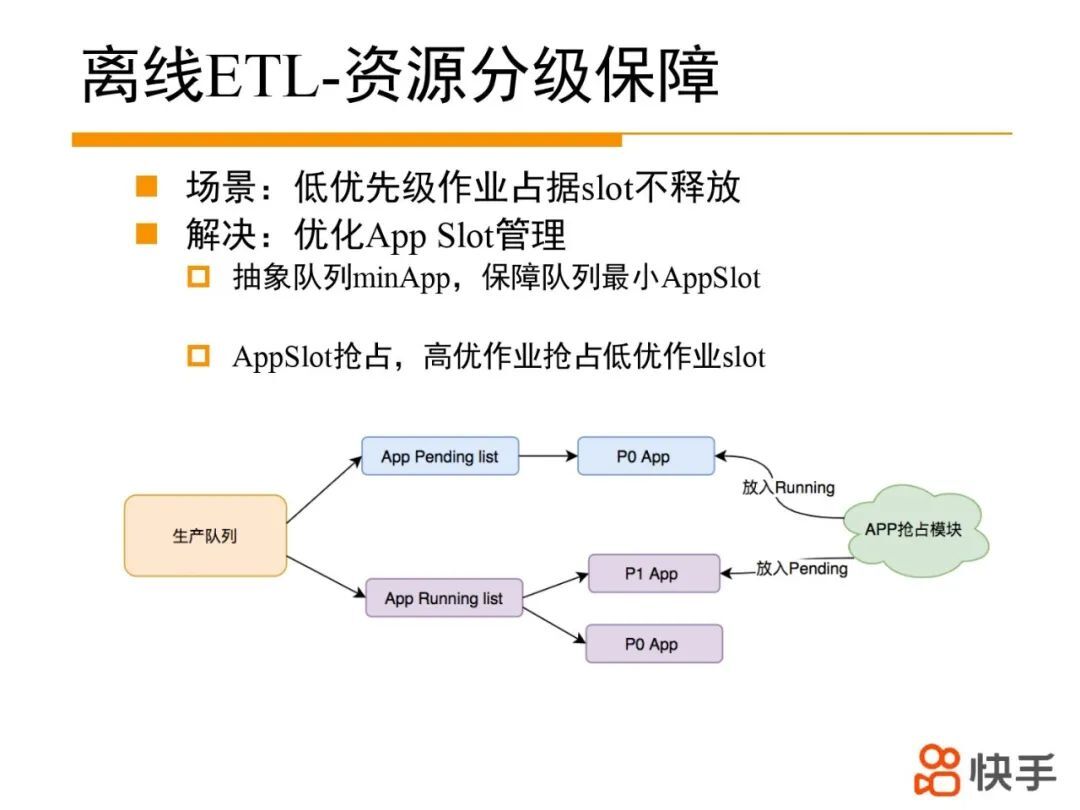
③ 低优先级作业占据 app solt 不释放
为方便 AppSlot 资源的管理,抽象出 minApp 概念,如果 App 启动时,队列 running App 小于 minApp,将会立刻启动 App,不会受限于父队列的 maxRunningApp,这样在队列层面保障有可预期的 app slot。但同样存在一个问题,队列内部低优先级作业占据大量 AppSlot 不释放,导致高优先级作业启动延迟。为此提出了 App Slot 抢占功能。如下图所示,如果发现高优先级作业(P0)长时间 pending 不能启动,扫描队列内 runningApp,选择低优先级作业进入睡眠模式(不再调度新 task,极端情况下回收 task)从而释放出 slot 资源,保障高优先级作业能及时启动。
④ 回溯作业影响生产作业
回溯作业的特点在于大量提交多个作业,如果不加控制可能会影响生产作业的产出。主要方案是限制回溯作业最大资源量和最大运行 APP 数目,将影响控制在一定的范围以内。但是限制最大资源量和运行数目导致大量回溯作业在 yarn 处于 pending 状态,对 yarn 有比较大的压力,通过与上游调度系统打通,反压上层工作流调度系统,阻止新提交的回溯作业,从而减轻了 YARN 负载。对于已经提交到 yarn 上的作业,会限制每个队列最大 pending app 个数,从而保障总体 pending app 数目可控。
⑤ 高优先级作业大块资源请求不能及时满足
原有的 Reserve 机制中,调度器可以 reserve 一批节点,不再调度新 task,等待节点上自然释放资源。如果被 reserve 节点资源长时间不释放,如何处理?针对这个场景开发了 reserve 抢占功能,用于抢占 reserve 节点上的低优先级的 container,从而保障节点上有足够的空闲资源启动高优先级作业。
⑥ 规避异常节点,避免核心作业长尾
通过采集节点物理指标,task 失败率,task 运行速度,以及 shuffle 失败率等,将此节点标记为异常节点,不再调度新 Task。从而尽量减少异常节点的影响范围,规避其导致的 Task 长尾,失败问题。
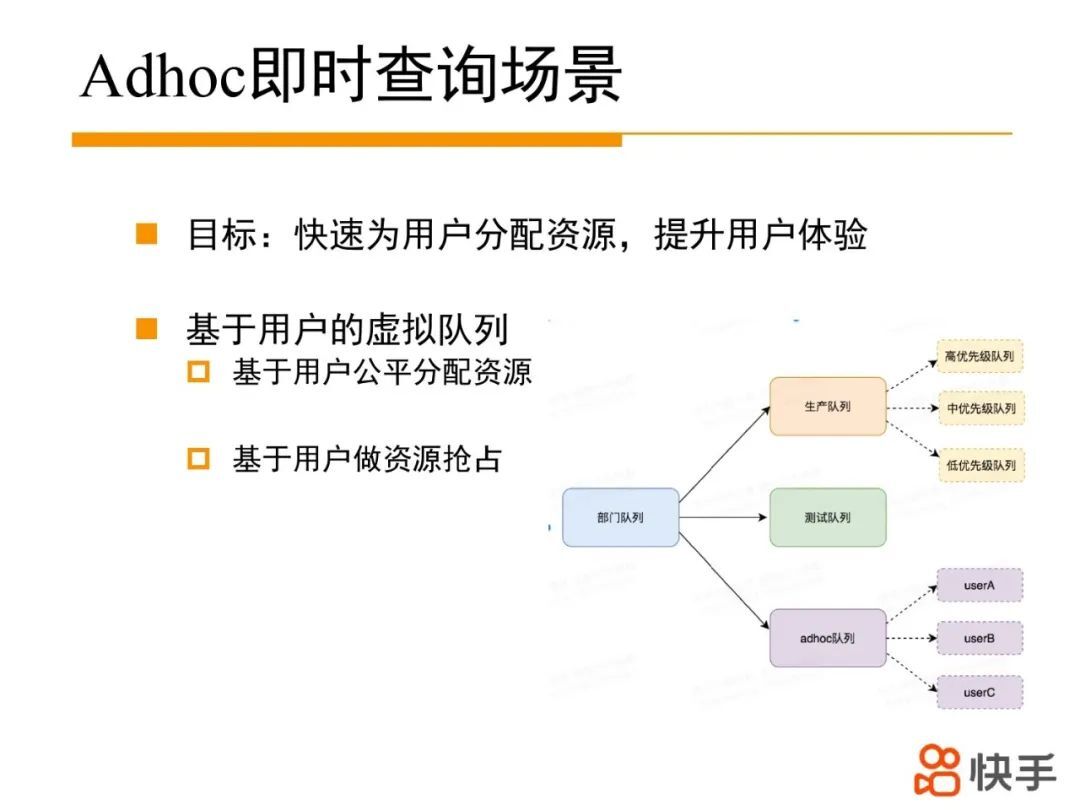
2. Adhoc 即时查询场景
AdHoc 场景主要着力于提升每个用户的查询体验。
通过虚拟队列技术,从 user 维度来划分虚拟队列,实现基于 user 公平的资源的分配,配合基于 user 的资源抢占,从而避免大量资源被某一个用户占用,导致其他用户长时间得不到资源。
3. 机器学习训练场景
机器学习训练场景下,资源需求呈现 all or nothing 特点,在队列资源紧张时,如果基于 yarn 原生的公平调度方式,为每个 app 分配部分资源,容易产生资源分配死锁问题。为此我们采用 APP 轮转调度策略,采用类似 FIFO 策略,保障头部 APP(头部会动态变化,轮转策略名称的由来)的资源需求,避免死锁问题。
4. Flink 实时作业场景
FLink 实时场景下,主要介绍故障发生时,如何尽量减少故障的影响范围,以及如何快速恢复故障作业:
通过 cpu 均衡调度,避免机器 cpu 热点。
通过 AM 失败节点规避机制,避免调度到 AM 失败机器。
NM 挂起(不调度新 Task,介于 RUNNING 和 LOST 状态)机制,防止 NM 异常退出导致 Task 失败。
基于 Hawk 秒级发现节点宕机,快速进行作业恢复。
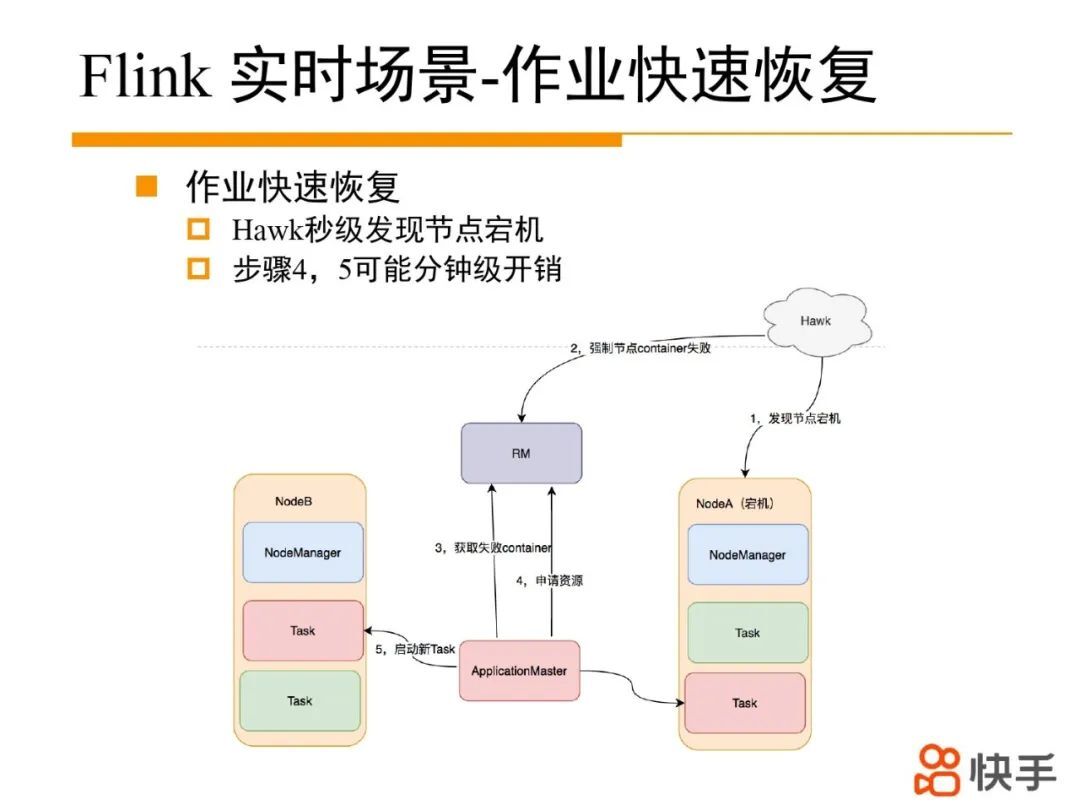
虽然可以基于 Hawk 秒级发现节点宕机,但作业恢复过程可能需要几分钟(申请资源,下载 jar 包,job recover 等)。我们通过资源冗余分配策略,优化掉其中资源申请和下载 jar 包过程,最终实现秒级作业恢复。
其他工作 &未来规划
支持超大规模集群:
主要目标支撑十万量级的集群规模,目前基于社区的 federation 方案进行改造。
Hadoop 跨 IDC 集群建设:
受限于公司物理集群规划,离线集群会分布在不同的 IDC,如何基于有限的跨 IDC 带宽,对数据和计算进行合理排布,是一个非常有挑战的问题。
在离线资源混合部署:
基于在线机器的空闲资源运行离线任务,在资源调度和隔离方面有很多工作要做,目前已经取得一定收益。
在离线资源统一管理:
目前 YARN 托管离线调度,k8s 托管在线调度,如何让资源更弹性更统一?我们也在做一些尝试。
流 shuffle 服务建设:
shuffle 过程产生大量大量的随机 IO,通过流 shuffle 服务接管 MR 和 SPARK shuffle 过程,将随机 IO 转变成顺序 IO,提升集群算力并减少在离线混部过程中 IO 影响。
大家如何有兴趣或者疑问可以随时联系我,也欢迎考虑快手大数据架构的工作机会,一起解决更有挑战的事儿。
嘉宾介绍:
房孝敬
快手 | 大数据架构师
2017 年加入快手,负责快手大数据资源调度方向,包括超大规模分布式资源调度,分布式计算,AI 架构等。此前曾在阿里,腾讯,负责搜索 &大数据系统研发工作,hadoop/spark/k8s 社区的 contributor。
本文转载自:DataFunTalk(ID:dataFunTalk)
原文链接:快手超大规模集群调度优化实践

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论