

虽然咱们是数据库内核博客,但流式处理系统已经成为数据系统的主流之一,并且提供了类似于 SQL 的接口,现在也有流批一体的趋势(我个人觉得,还得观察一下,因为毕竟数据源方式不同,服务的应用也不同,使用一套系统,感觉很难鱼和熊掌兼得)。这一期,咱们聊一聊流处理系统。内容源于 Facebook 2016 年 SIGMOD 上发表的一篇文章,标题就叫做《Realtime Data Processing at Facebook (Meta)》。
首先,为什么需要流处理系统,因为有低延时的应用需求:如实时数据分析,如性能指标,error 指标;推荐系统,为了取得最好的推荐结果,希望可以采集到某些实时的特征等。
这篇文章首先讨论了一下流处理(或者叫实时数据处理)系统的 5 个重要属性。分别是:
1)易用性:程序员如何声明流处理的逻辑,SQL 语言(或者类 SQL 语言)支持是否已经足够;还是要支持 general purpose 的处理逻辑,比如可以让程序员用 C++或者 Java 语言来实现处理逻辑然后交给系统执行(类似于 map-reduce)。从声明,测试到发布,整个生命周期需要多长时间?
2)性能:性能一般指延迟和吞吐量(throughput)需求。延迟是毫秒级别,秒级别,或者是分钟级别?吞吐量需要多高?
3)健壮性(fault-tolerance):系统能够支持什么级别的崩溃恢复?对于数据处理,能提供什么样的 service level agreement ,是至少一次,至多一次,还是保证一次?如果某个 task 崩溃了,如何恢复 in-memory 的状态,等等。
4)扩展性(scalability):数据处理是否能被 shard 或者 reshard 来提高吞吐量?系统是否能动态地伸缩(elasticity)。
5)正确性:是否提供类似数据库的 ACID 保证?是否会有数据丢失(这点和上面的健壮性有重叠)。
Facebook 在设计流系统时的决策是基于这个前提:秒级别的延迟和几百 GB/s 吞吐量需求(a few seconds of latency with hundreds of GB/s throughput)。在这个前提下,不同的批处理过程可以通过一个 persistent 的 message bus 系统(Scribe,类似于 Kafka)相连来传输数据。异构数据传输和数据处理,能够使得整个系统更好地处理上述提到的这些属性。
Facebook(Meta)流处理系统简介
整个 Facebook 流处理生态提供了 3 个不同的系统。结合下面这张数据流图,依次来介绍。
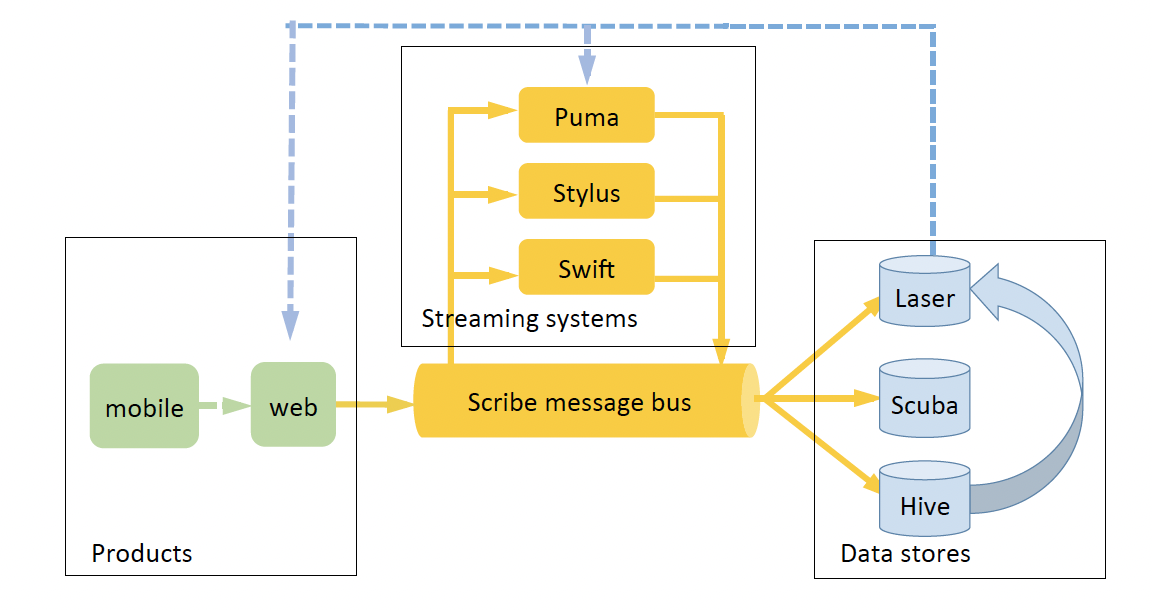
数据从 mobile 端或者服务器(web)端产生,首先以 log 形式记录到 Scribe(上文提到的 persistent 的 message bus 系统)。流系统 Puma,Stylus 和 Swift 可以从 Scribe 中读取数据,执行数据处理,再写回 Scribe。以这种方式,三个系统结合 Scribe 可以组成复杂的数据处理 DAG。最终,处理完的数据通过 Scribe 写入 Laser,Scuba 和 Hive 三类 Data stores。
Scribe
Scribe 是一个非常 scalable,基于 persistent store(文件系统)的message bus系统,类似开源的 Kafka 系统。数据以一个个 category(Kafka 中的术语叫 topic)的形式存在,每个 category 可以 shard 成多个 bucket 来提高吞吐量。bucket 是流处理系统的基本单元。Scribe 将数据存储在 HDFS 上,通常 retention 可以到几天。
Puma
Puma 提供了类 SQL 的语法并支持用 Java 语言写可扩展的 UDF(user defined functions)。Puma 的优势在于开发流程非常快(因为提供了类 SQL 语法),整个声明周期可以在小时级别完成。Puma 可以非常高效地完成简单的类 SQL 的聚合操作。文中给出了一个简单示例,在 5 分钟的 sliding window 中计算 topK events。Puma 的简易 code 如下,即使从来没接触过 Puma 语法,相信理解下面的内容也不困难。

Puma 的另一个优势是对于简单的 filtering 逻辑,比如只选取某些相关的数据,可以提供秒级别的延迟(这些处理后的数据可以马上被写入到另一个 scribe category)。和传统数据库不同,Puma 选择更好地支持那些被长期运行的 app 而不是 ad-hoc analytics,因此它可以通过 code generation 来生成优化的处理代码。
Swift
(插一句题外话,在读这篇 paper 前,我都不知道有这个系统,其实读完简介,我依然是云里雾里)。Swift 只提供了非常简单的 API:从某个 scribe 中读取 N 个 string 或者 bytes,然后周而复始。如果在处理某个 checkpoint 的时候 app crash 了,可以接着从当前 checkpoint 重来。Swfit 通常用于非常低吞吐量,且无状态的数据处理。
Stylus
Stylus 是一个通用的流处理系统,语言是 C++。它提供的 API 和开源的流处理系统如 Storm,Samza,Millwheel 类似,它分别支出无状态和有状态的流处理。因为实现语言是 C++,因此 Stylus 不仅支持各种操作(包括读取外部系统获取信息),性能也非常高。
咱们也快速介绍一下 data store,这些系统可以从 Scribe 导入数据,但不再支持导出到 Scribe,而是通过自身的 API 对外提供数据服务。
Laser
Laser 是一个高吞吐量,低延迟的 key-value 存储,它可以通过 Scribe 导入数据,之后这些数据就可以被其他应用访问,包括 Stylus,Swift 和 Puma。
Scuba
Scuba 可以看成一个高性能,但支持单个 table 的 in-memory 数据库。它可以支持非常低延时的数据导入,然后通过类 SQL(但是只能查询单个 table)或者 UI 操作来查询数据,查询也在毫秒级别完成。因此 Scuba 广泛应用在各种性能,监控, debug 指标中。
Hive data warehouse
Hive data warehouse 就省略了,大家都懂。
介绍完了所有系统,再通过一个简单的例子来梳理一下。文中给出了下面这个示例:从 event 流里找出最热的 event topic(通过将 event count 进行高到低排序),输入 event 流有 event 的基本信息如 event timestamp,event type,dimension_id(用来获取相关 dimension 信息)event text 等,输出就是每个 topic 的 TopK events。
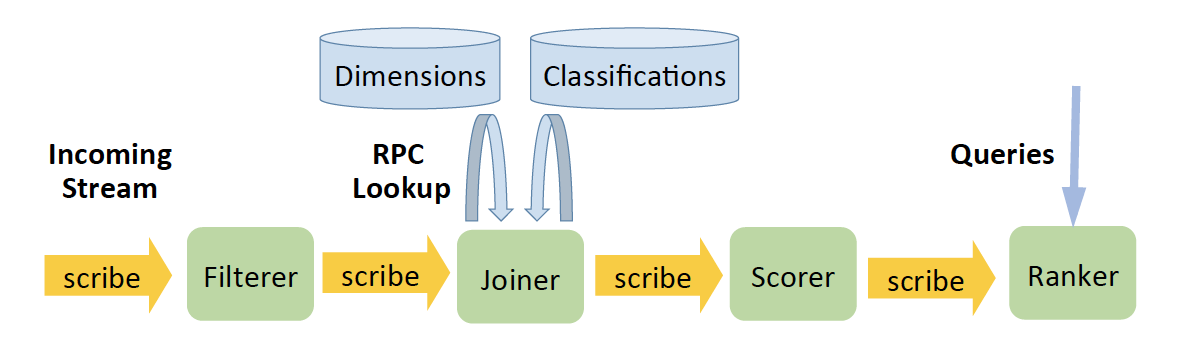
1)Filterer:可以过滤掉不符合规定的信息,并且将 event 流重新以 event 的 dimension_id 作为 sharding 的形式分发到下游的 scribe 中(这样,下游处理可以根据 dimension_id 来进行并行处理)。
2)Joiner:Joiner 需要根据 dimension_id 抓取相应的 dimension 信息,并且调用 classification 系统来得到 event topic。因为上游的 scribe 是以 dimension_id 作为 sharding,因此 joiner 可以 cache 相应的 dimension 信息来减少 network bandwidth(有状态的处理)。处理过的信息以<event, topic>的 pair 形式发送到下游的 Scribe。
3)Scorer:Scorer 通过收集一个 sliding window 里 topic 的 event count 来计算 score。由于计算 score 需要考虑到 long-term trend 和 current count,因此 scorer 需要存储 long-term trend 作为状态。最终输出<topic,event,score>(shard by topic)到下游。
4)Ranker:最终, Ranker 针对每个 topic 计算出当前 sliding window 的 topK events。
文中有提到,所有的 logic 都可以用 Stylus 来实现。不过,Filterer 和 Ranker 可以更快地用 Puma 实现。
设计决策
接下来才是本文的重点,文中介绍了 5 个维度的设计决策。并且讨论了这些决策是如何影响文章最开始介绍的流处理系统的 5 个属性(易用性,性能,健壮性,扩展性,正确性)。
编程语言支持(language paradigm)
编程语言支持会影响到易用性和性能。文中介绍了三大类:declarative(声明式)类似于 SQL 应该是最易于理解和上手的,缺点在于表达的局限性;Functional(函数式)将整个 application 封装成不同 function(operator)的组合,不如 SQL 那么容易上手,但提供了更多的控制。最后就是 procedural:直接提供 C++或者 Java 等语言接口。Procedural 提供了最大的控制同时也在很大程度上能保证性能,缺点就是开发周期更长。这三类各有优缺点,在 Facebook 内部,Puma 实现了 declarative,而 Stylus 实现了 procedural。
数据传输(data transport)
复杂的流处理逻辑通常用 DAG 表示。如何实现数据从一个节点传输到另一个节点,影响到整个流数据的健壮性,性能以及可扩展性,以及一定程度的易用性(尤其是在 debugging 时)。
文中也介绍了三大类:
1)direct message transfer:类似于用 RPC 或者 in-mem message queue 来直接传输数据,这类的好处在于延迟非常低。
2)broker based:通过引入中间 broker 来 decouple 上游和下游。Broker 虽然增加了性能负担,但提高了扩展性,方便 scale out。
3)persistent storage based broker:类似 Scribe 或者 Kafka。毋庸置疑,这个方法虽然最 heavy,但是带来了 message bus 系统所有的好处,解耦,扩容,订阅分发,持久保存等等。Facebook 内部使用第三类,用来提升健壮性,可扩展性,以及易用性。
数据处理语义(processing semantics)
数据处理语义决定了正确性和健壮性。 文中也介绍了三大类:
1)更新内部状态:读取一个 event,进行相应处理(如查询外部系统)然后对 in-memory 状态进行更新;
2)生成 output event:处理完 event 后,生成一个 output event 到下游;
3)保存状态至外部系统,如数据库:这里面可以涉及到 offset 和 checkpoint 的保存来进行灾备恢复。如果是无状态的节点,只能选择生成 output event,有状态的节点三者都可能涉及。
对于 event 处理的正确性,如果选择 at least once(至少一次),节点应该选择先保存 in-memory state,再更新 offset;如果选择 at most once(至多一次):节点应该选择先保存 offset,再更新 in-memory state;如果选择 exactly once(强一致):必须保证原子更新,如利用 transaction 机制。在介绍的系统中,Puma 选择了 at least once,而 Scuba 选择了 at most once。因为 Scuba 本身就自带 sampling,而且查询,为了追求效率是 best effort,因此,少量的数据丢失是可以接受的。
状态保存方式(state-saving mechanism)
对于有状态的处理节点,如何保存状态。文中介绍了下面这几类:
1)复制到其他节点;
2)本地数据库或文件存储;
3)远程数据库或文件存储;
4)依赖上游节点存储;
5)全局 snapshot 存储。
在介绍的系统中,Stylus 提供了本地数据库和远程数据库的状态存储。本地存储的优势是减少带宽,程序崩溃恢复也快。而远程存储则可以应对硬件级别的机器故障(需要重新 provision 一个新 node,再将状态导入)。
重复处理机制(reprocessing/backfill mechanism)
由于某些特定应用场景,我们会需要重新处理一些旧数据。如引入了一个新的流处理逻辑,需要用一段过去的数据来测试;引入新指标,需要重新运行数据来获取这个指标。要处理旧数据,需要以下这些机制:1)stream 的数据保留的 retention 足够长,比如在 Scribe 中设置更长的 retention;2)使得流处理系统可以处理 data warehouse 的数据(batch 处理)。Facebook 系统中 Scribe 的 retention 通常不能很久,通常几天。因此,需要使得流系统对接 data warehouse 来处理,通过引入 tailer。Backfill 机制会影响系统的易用性,可扩展性和正确性。
总结一下,这期,我们通过介绍 Facebook 内部的流处理系统生态,讨论了流处理系统中 5 个维度的设计决策,以及它们对流处理系统 5 个关键属性的影响(下图展示了不同维度的设计决策分别会影响哪些属性,以供参考)。感觉阅读!


Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...










评论 2 条评论