
本场分享将围绕开源治理核心的生态工程能力框架展开探讨,从 openEuler 开源项目的实践经验出发,分析开源项目合规和数字化运营工作的痛点,以及针对这些痛点的解决思路,包括方法论、流程、规则 &标准、工具 &服务落地。
本文整理自华为公司 2012 实验室工程师的高琨和 LF CHAOSS 中国社区发起人、华东师范大学硕士在读的夏小雅在DIVE全球基础软件创新大会 2022的演讲分享,主题为“OpenEuler开源项目合规和数字化运营的探索与实践”。
分享主要分为四个部分展开:第一部分是开源社区合规的常见问题的分享;第二部分会介绍 openEuler 如何基于合规的问题做应用实践;接下来第三部分和第四部分则是开源社区运营的常见问题以及实践经验分享。
以下是分享实录:
开源社区常见问题和风险
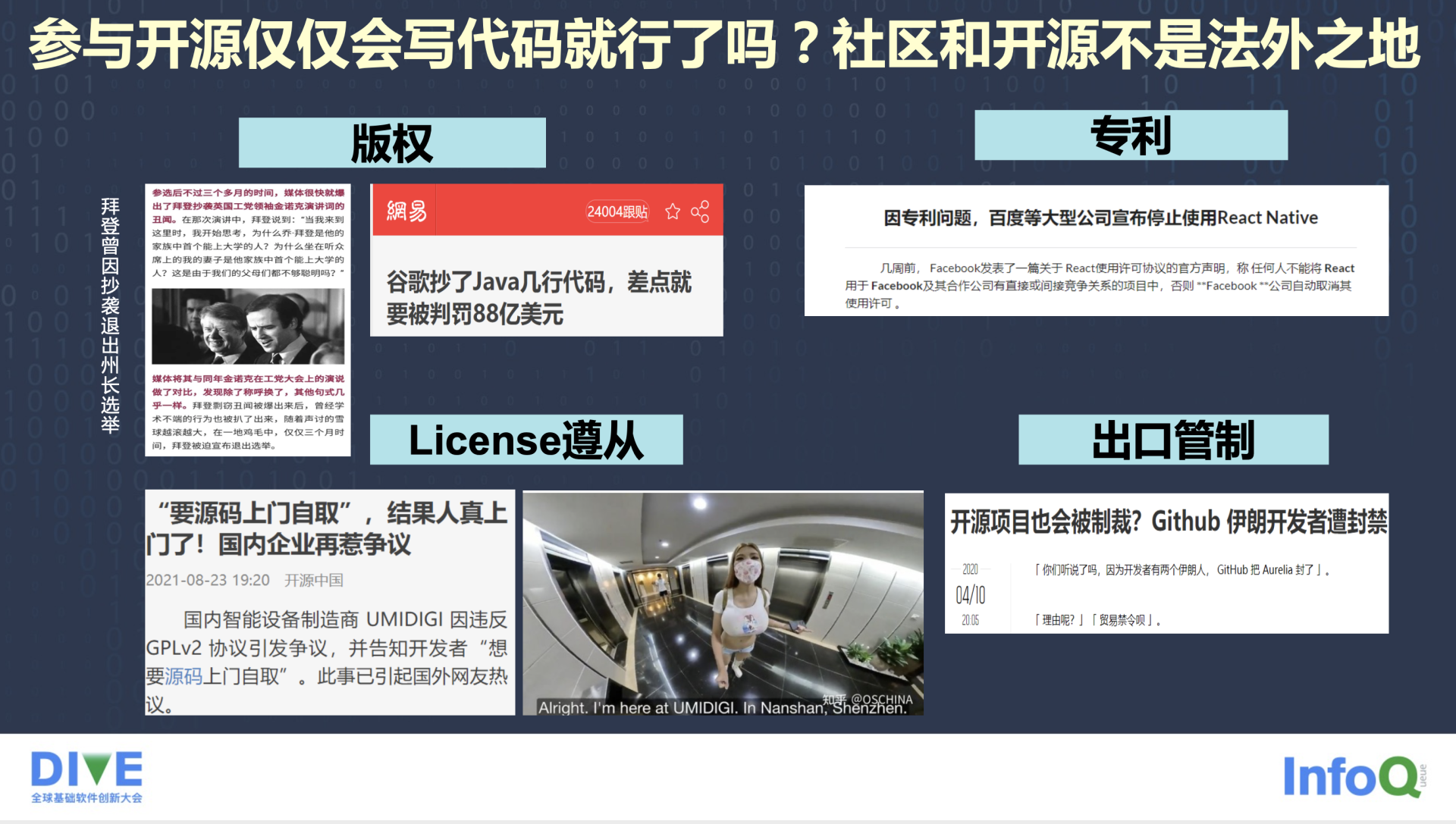
在开源社区仅仅写几行代码就可以了吗?只要会写代码就 OK?其实并非如此,社区跟开源不是法外之地,开源社区里有大量的人跟人之间的交互,难免涉及需要守法律法规的情况,比如说 License 的要求以及版权的要求。
开源社区常见的合规问题分为以下四大类。
第一类是版权。这里有个很好的例子,就是美国的总统乔·拜登,他在 2016 年参加党内州长选举时,抄袭了英国工党领袖金诺克的演讲台词,他仅仅是把金诺克的名字改成了乔·拜登,然后就拿上台讲了,因此造成了丑闻的曝光,退出了当年的党内人士选举。类似的例子还有 Google 结合了 Oracle Java 代码。这个例子比较有名,很多人也知道,这里不做赘述了,这些都是版权的问题。
第二类是专利问题,有一个很有名的软件相信很多人都用到了,就是 React,基本上 90%的公司都用这个软件。它把专利条款写到了它的 License 条款中,只要你用了 React,你就可能被 Facebook 公司诉讼。如果有专利诉讼问题,你的公司的专利会自动授权给 Facebook 公司,这也是条款。
还有就是最常见的 License 遵从。2021 年 8 月份,深圳的一个设备制造商因为用了一个 Kernel 但不对外提供源代码而违背了 GPLv2 协议,这家公司告诉开发者上门去要代码,最后这家公司变成了网红,在国内外都引发了热议。
最后一类是常见的出口管制问题,当年 GitHub 禁止伊朗开发者使用,最近俄乌战争相信大家也看到了,很多消息说美国人对俄罗斯进行制裁,通过 GitHub 的出口管制限制俄罗斯使用。
社区里最常见的就是这四类合规问题,其中重中之重就是 License 合规,我们也把它叫 License 遵从。今天我们重点就围绕 License 遵从给大家带来我们的分享。
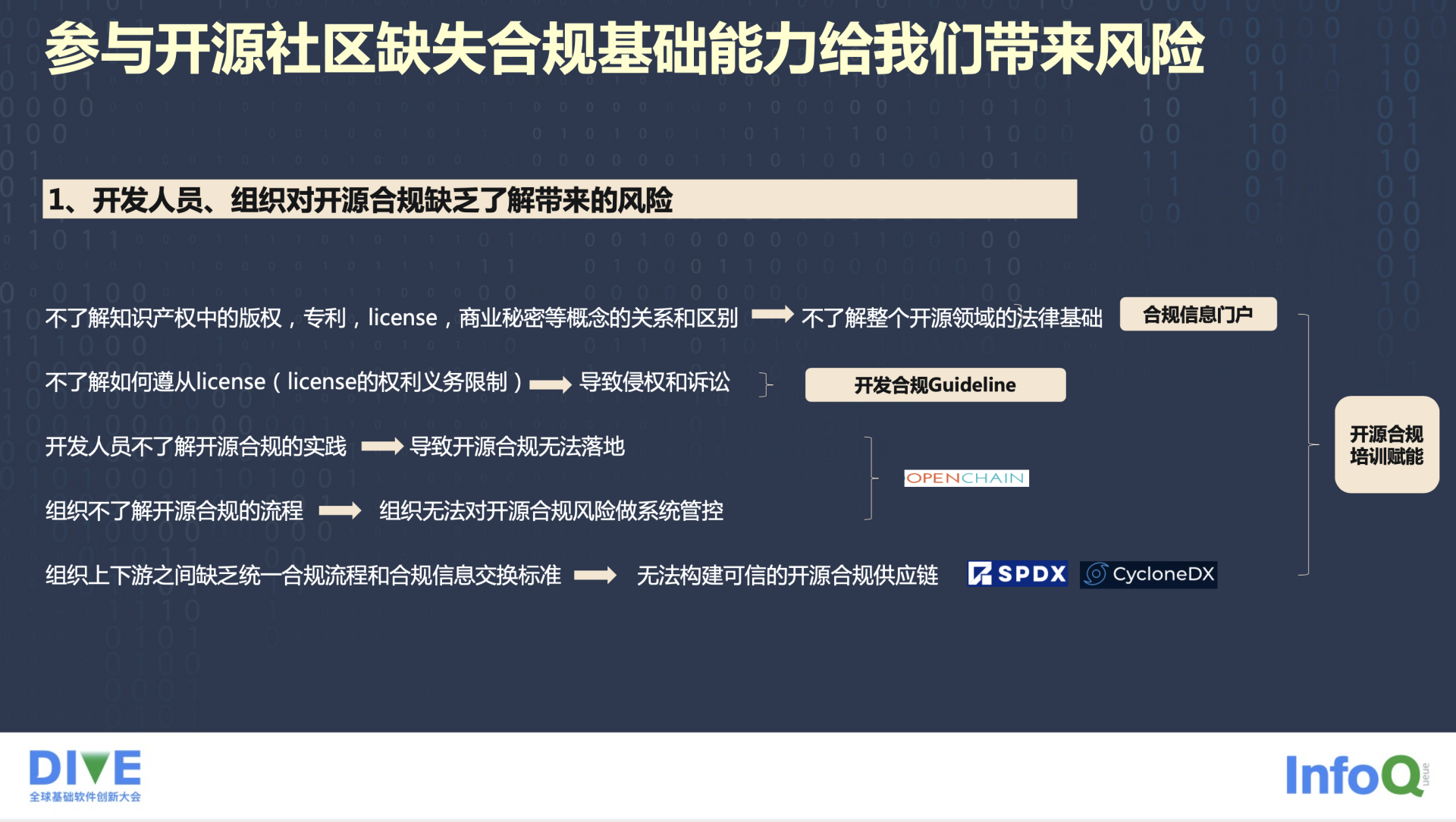
在开源社区,缺失合规基础可能会带来两类风险。一类是开发人员或组织缺乏合规能力带来的风险,这可以通过对合规人员进行培训来解决。
它又分为五小类,第一个是意识层面的,就是不了解我们刚才讲的版权专利、License、商业秘密、出版等等这些概念和它们之间的关系区别,这部分概念是法律基础层面的。当然这也能理解,很多社区里的开发者都是学理工科出身的,不是文科法律系的,这是大家面临的很大的一个挑战。而 openEuler 在合规门户、信息门户这块会给大家提供一些支持。
第二个是我们不了解如何去做 License 遵从,可能会导致权利侵权和诉讼。这块 openEuler 面向开发者提供一个 Guideline,会对大家进行辅导。同时,开发人员可能不了解开源的合规实践,不了解合规的流程应该是怎么样子,到底怎么做一个系统性的管控。在 Linux Foundation 下面有一个叫 OpenChain 的项目,它现在已经成为了 ISO 5230 的国际标准,很多欧美大厂都在借助这个标准,它给我们带来了很好的指引,在合规流程和系统管控上做了很好的解释和认证,也提供了一些例子可以让大家学习。
最后一点,开源软件之间其实存在一个供应链,开源软件一层一层集成,在整个供应链之间需要一个合规信息的交换标准。在 Linux Foundation 下面有一个叫 SPDX 的项目,它做了信息元数据的标准。同时还有个项目叫 CycloneDX,这是由欧洲的一个组织发起的,它也有一套标准,当然这个标准是可以做格式转换的。我们通过企业合规的赋能培训,就可以解决这些问题。

除了有意识、有赋能之外的,合规还有大量操作层面的东西,可能会存在一些重复性工作,有一些人工的工作,我们可以用工具替代它,如果组织跟社区缺乏合规的工具可能会带来一些风险。我相信在很多的中国的以及国际的开源社区里,其实都缺乏合规工具。
这块,我们把它分为了四类。第一类针对源码,源代码或者 SCA 扫描工具,开发人员如果自己搭建的话成本太高了。在这一方面,openEuler 提供了貂蝉、张飞、华佗等一系列扫描工具供大家查询、调用、扫描。第二类针对 License 的文本识别工具,License 可能会存在一些变种的情况,它会导致后续 License 遵从性全部都会出现错误,这块我们会使用语义比对工具“吕蒙”。然后是在 License 和业界标准格式上面,License 和版权声明通常缺乏清晰性,这块我们有标准比对工具。还有就是在全局管控上面,社区经理缺少一个合规的风险看板,无法对合规的风险进行追踪管理,这块由“诸葛亮”这个看板工具来解决。这是我们整个工具链的建设思路。
openEuler 合规实践分享

常见的一些问题讲完之后,我们也讲一下 openEuler 一些好的实践。反过来大家可以想想,我们为什么要选择 openEuler 来做这个事情?我们选定了目标之后,是怎么开展工作的?包括我们在理论研究及技术突破方面,做了大量的实践,这些实践包括什么?最后,我们在工程落地的实践方面,有标准的流程,组织的建立,生态的搭建以及工具服务的不断发展。
为什么选择 openEuler

首先聊聊为什么会选择 openEuler?
openEuler 有 8000+镜像项目,95+ SIG 组,它的合规场景非常复杂。它的发行版社区是个大杂烩,所以这种情况下对合规要求是非常高的。大家可以看到这个图示,整套生态包括上游社区、贡献者的贡献,以及贡献的合入,在 openEuler 社区里进行开发,以及发布、ISO、下游的发行版发布,有好几种不同的场景。浅绿色的点包括了上游开源项目的使用,包括了依赖组织的项目。不只有一层,还有二层、三层需要考虑它的兼容性怎么识别。在这种场景下,我们希望共建出依赖软件的关系图谱。同时还有大量的独立软件的镜像开源,上游社区项目升级的时候会涉及到变更、更新、合入。
黄色的这部分是我们自己的自研项目,我们进行代码的开发和贡献,也会把它共享到 openEuler 社区里,再把它发布出去。总共有四类场景,包括了初始的捐赠跟引入、贡献的合入、开源软件的使用跟依赖软件使用以及开源的发布。
以上就是我们选择 openEuler 作为合规 SIG 探索的一个方向的原因。
理论研究和技术突破

选定目标之后,首先要进行理论研究和技术突破,我们读了大量学术界论文。在 Daniel 教授的一些论文中,他会分析出 License 的变种场景,基于 MIT、基于 BSD 有大量的变种 License。这种 License 就是一个 License 文本,可能改一行字或者改一个单词,它的语义就完全反过来了。我们都需要遵从这个 License,然而需要履行的义务却是不一样的,甚至有可能完全相反。还有,它会基于社区的升级情况,看 License 的演进情况。论文里还会识别出这个 License 是否是通过 FSF 自由软件基金会或者 OSI 审批的 License,这样的 License 会更安全一些,还会识别有多少 Permissive License 等等。论文量非常多,这块我截了一些图,大家感兴趣可以下载下来自己阅读一下。基于这些论文,我们做了一些技术上的探索,并取得了一些突破,比如刚才讲的变种的 License 文本,我们会集结相似度算法调研。我们有五种基于文本相似度算法识别 License 的工具,后面也会详细介绍。
工程与实践落地
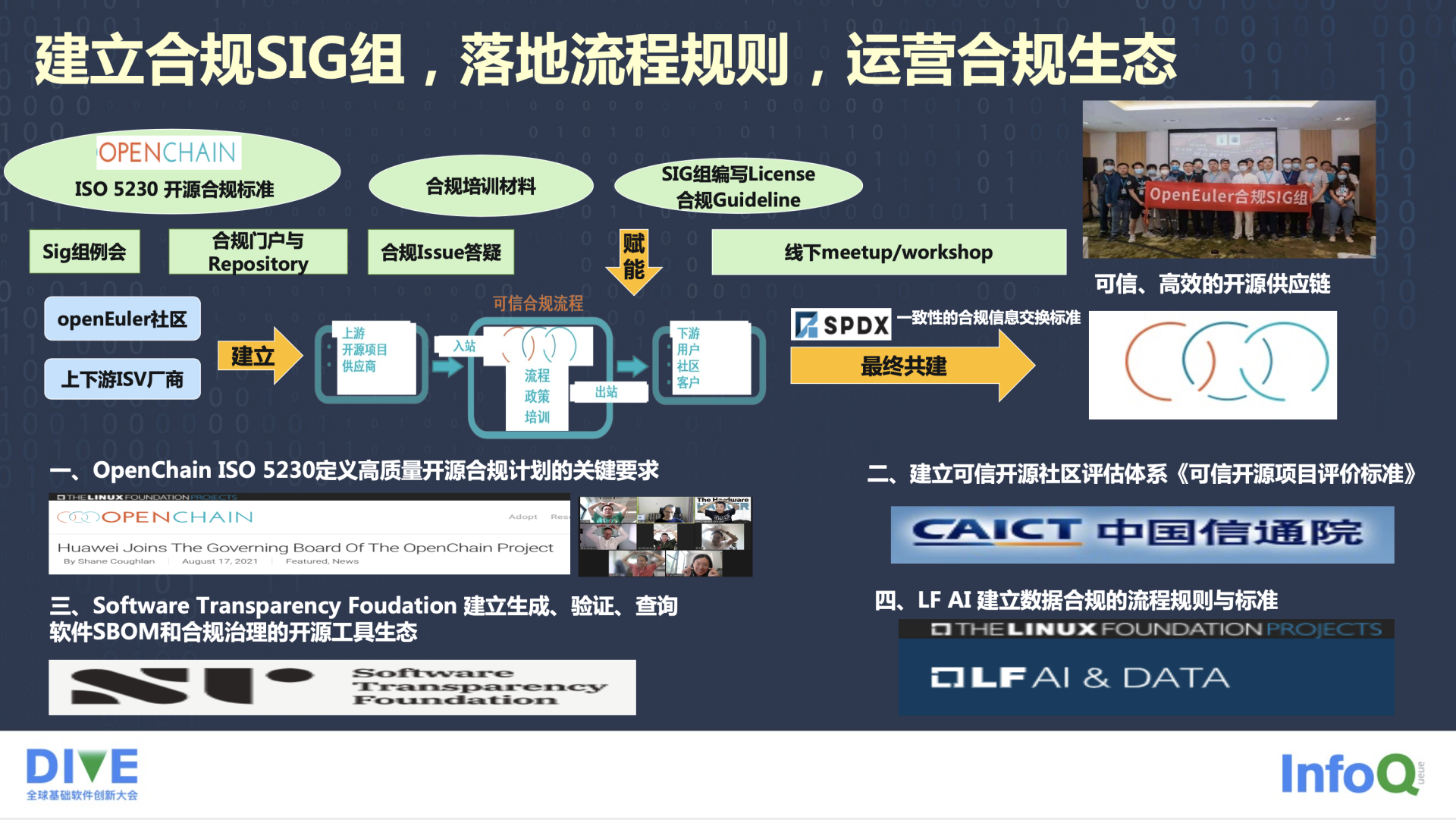
基于理论研究和突破,后面的工程能力需要怎么去建设?首先要成立相关组织,以方便工程能力落地流程中。我们在 2021 年的 1 月份成立了 openEuler 合规的组织,SIG 组里会定期召开双周例会。我们也有自己的门户网站,就是貂蝉;在 gitte 上还有代码仓库,可以通过 Issue 答疑和开发者交互。我们也会做一些公开的合规培训,就是刚才所说的的 Guideline,这个 Guideline 是面向开发者和贡献者去写的。同时我们还会组织一些 Meetup 和 Workshop,给大家做一些分享。同时在流程上,目的是通过上游的社区、OSV 厂商建立整个核心的合规供应链以及下游,通过 SPDX 这个标准格式进行一个交换,建立了一套类似于 OpenChain 的可信、高效的开源供应链。它里面包含每一层的供应链,可信合规的流程,它的入栈、流程、Policy、培训以及出栈、社区,和它下游用户社区,每一层都是这样一套供应链。
在这块完成了四件具体的事情,也有一些成果。第一、华为在 2021 年 8 月份成为了 OpenChain 的白金会员;第二、华为跟中国信通院一起推动了可信开源项目评价标准的体系的建设,希望基于它去影响更多的开源项目,让开源项目更合规、更可信;第三、还会围绕 Software Transparency Foudation 建立生成、验证、查询、合规这些 SBOM 和合规治理的开源工具生态,包括国际标准、国内标准、工具生态;第四、除了 OSS 合规,还有一个很有意思的事件,就是在开源组件这块,随着 AI 技术的大量应用,我们发现数据合规这块现在是一片空白的,在这方面我们也做了一些流程、规则的标准和研究。同时在 Linux Foundation 下面的 LFAI DATA 基金会也做了大量的分享,制定这个标准。

成立 SIG 组之后,在组织、有流程、有生态,整个框架搭起来之后,开源项目也有 License 合规的基线需要遵守。我们把基线分为五类,所谓基线就是必须要做到的。
可以看到这个表格里,比如在根目录下面,无论是在 License 里,还是 Readme、Copyright、Notice 里,或者 1 层子目录(/License(s)/ License, *Notice*/License 下面,没有完整的 License 文本说明是不符合规范的。保证 License 文本的完整性,这是一个基线的要求。
第二,项目 spec 文件的 License 不规范,在 Fedora 里发现也有很多 Spec 文件与 Fedora 所依赖的上游文件写的完全不一样,也有错误的情况,甚至包括 License 直接写错的,多 License 的场景写错,版本号写的不规范的问题。
第三,缺乏项目级的 Copyright 声明,建议在根目录或者 1 层子目录下面,在这些最容易看到的地方,对于 License、Copyright、Readme、Notice 等这些文件必须要添加 Copyright 字段描述。
第四,就是刚才提到的,基于论文的发现,使用经过 FSF 或 OSI 认证的 License 更安全,因为它们经过大量的律师、工程师以及业界大牛一起讨论的这个技术软件究竟满不满足开源软件、自由软件的 License 定义,如果它认证了,说明它是满足的,因此要用这些组织认证的 License。
最后,就是开源软件的声明,因为开源软件要发布二进制文件,建议必须要用 Notice 声明。上述这些基本上是所有的文件 License 作者许可用开源软件的最底线的要求,基本上 100%的软件都会有这个要求,这是一个底线。

刚才讲了基线,基线是底线的要求,那么怎么做是最好的?这块分享一些优秀实践。比如说第一类就是整体的 License,建议两种方式,第一是在根目录下面放独立的 License 文件,清晰明了,或者在 License 的子目录下面放独立的 Licenses/License 文件。第二,License 名称建议使用统一格式的 spdx-indentifier 标准的名称,因为 SPDX 已经是 ISO 的标准了。第三,项目级的 Copyright 声明,建议两种模式,第一种方式是在根目录下放 Copyright Notice 文件,第二个方式是在 Notice 下面放独立完整的 Notice 文件。第四、项目所有使用的 License,建议全部是通过认证过的 License。当然没有通过认证的 License 也不代表你不能用,但是这时候需要通过另外一套流程,请律师重新审核。第五,开源软件声明,建议在项目的根目录或一级目录下面提供原样的第三方软件的 License & Copyright 声明,千万不要改,原汁原味地放入,这是最安全的。
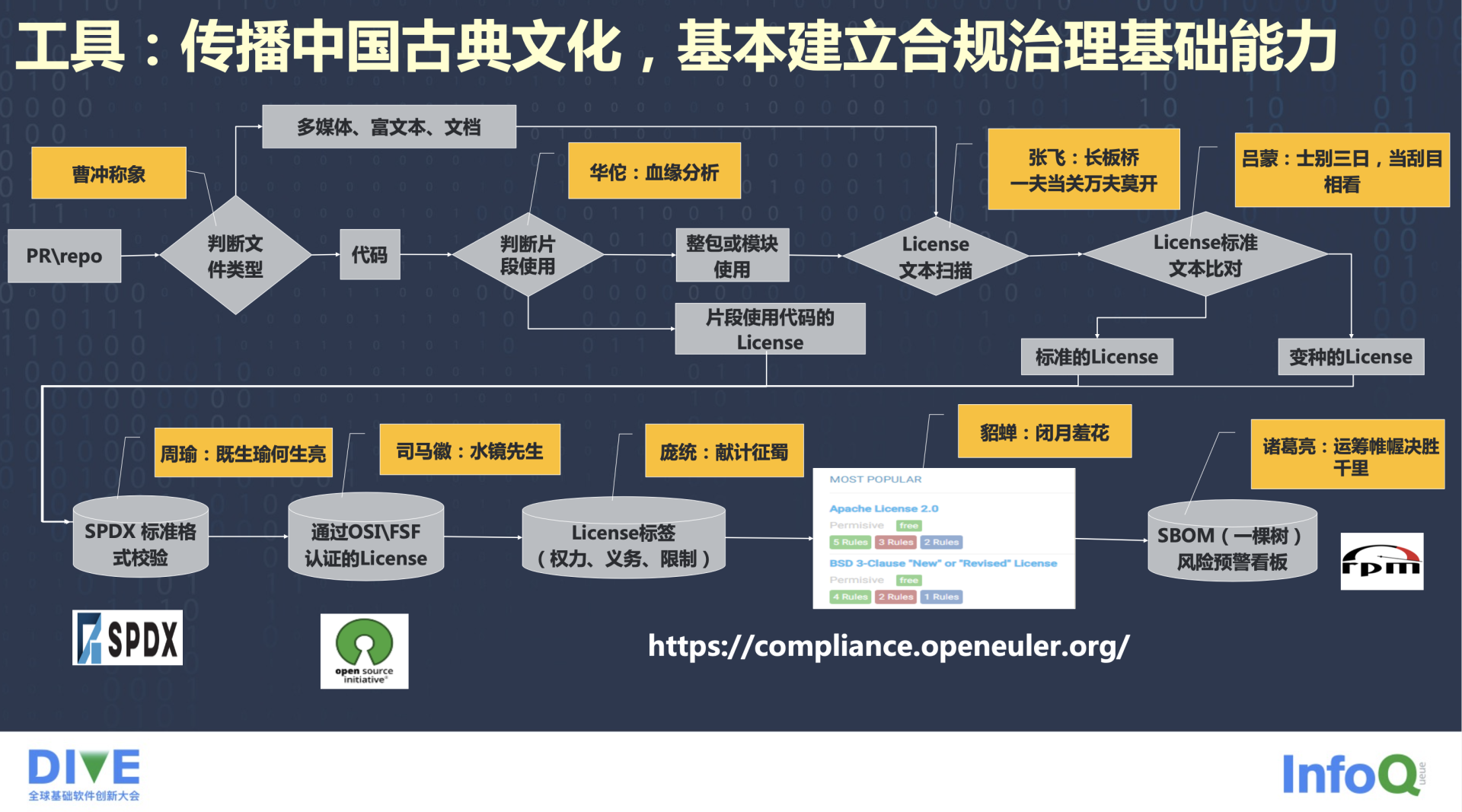
最后,给大家分享一下相关工具。这是我在 2021 年做的规划,基本上现在这些工具都已经落地了。这是基于当时的开发流水线做的,黄色的框里就是工具的名字,希望可以借助这些东西传播中国的古典传统文化,基于它建立合规治理的基础类。可以看到有曹冲、华佗、张飞、吕蒙、周瑜、诸葛亮等等。
无论是一个 Commit、一个提交、一段代码,还是对一个 Repo 的静态扫描,都可以先做文件类型的判断,就像曹冲称象一样,他不可能把大象切开,因此他只能把大象用相同的石头去代替,再分解开。我们也一样,先把文件类型分解开,如果是代码类的文件,会进行一些 SCA 的分析扫描,如果不是代码类的文件,而是多媒体、富媒体这些文档类或图片类的文件,就会走到后面,提升扫描效率。
大家知道很多程序员在写代码的时候有一个误区,他会去复制别人的一段代码,甚至直接一个函数拿过来用,这样是非常危险的。不是不可以,但是非常危险,一定要管理好。如果这段代码来自开源软件,你有可能拷过来之后就忘了,认为是自研的,这可能就会给你带来法务上的风险。这块的识别我们现在用的是华佗这个工具,用于做血缘分析。
如果是片段使用,也一定要把 License 识别出来。文档类、图片类也是有 License 的,需要对 License 进行一个文本扫描,看一下是否与标准 License 有区别,这里就有了“张飞”这个工具。“张飞”会判断它是不是一个标准的 License,如果是的话没问题,如果它跟标准 License 不是 100%一样,就会去看一下它是不是变种的 License,语义和标准 License 有多大的差距。这也就是“吕蒙”这个工具,士别三日当刮目相看,指的就是这个 License 和标准 License 变化的可能已经不一样了。
变种 License 风险非常大,它的履行义务是不一样的,权利可能会变化。基于这三种 License 会把它组合起来,类似于 License 的清单,进行 SPD 标准格式校验。这里用的是“周瑜”这个工具,既生瑜何生亮,它的标准是唯一的。
下面这个工具也是受到了论文的启发,用来识别哪些 License 是被 OSI 和 FSF 组织认证的 License,这就是“司马徽:水镜先生”,它来负责做认证。License 文本如果都满足了要求,这时候要去对它文本进行解析了,它的权利是什么,义务是什么,限制是什么,这就是“庞统”,献计征蜀。想当年庞统在征蜀的时候,给刘备献了三策,上策、中策、下策。大家肯定是希望权利越多限制越少,License 如果也能这样子就是最完美的,但是现实往往与之相反。
建完模之后,就可以把建模结果展示出来,在前端有两个工具,一个是“貂蝉”,这是和开发者交互最多的,在 compliance.openEuler.org 官网下面可以直接搜到。在这个工具里,输入任何一个 License,页面会返回这个 License 对应的权利、义务、限制,以及它有没有被 FSF 和 OSI 两个组织认证过,是不是 SPDX 标准格式,标准格式应该怎么写。
前端还有一个工具是“诸葛亮”,它会基于对“貂蝉”标签的调用,告诉项目经理或者社区经理,当前 Licence 合规有没有问题、要遵从哪些权利和义务,这就是“诸葛亮”。因为它是通过 SDX 格式校验的,也是一个标准的 SBOM 一棵树的形式,主要用来做风险的预警。以上就是整个工具链体系。
我选择这套体系中的部分工具,给大家进行详细的展示。
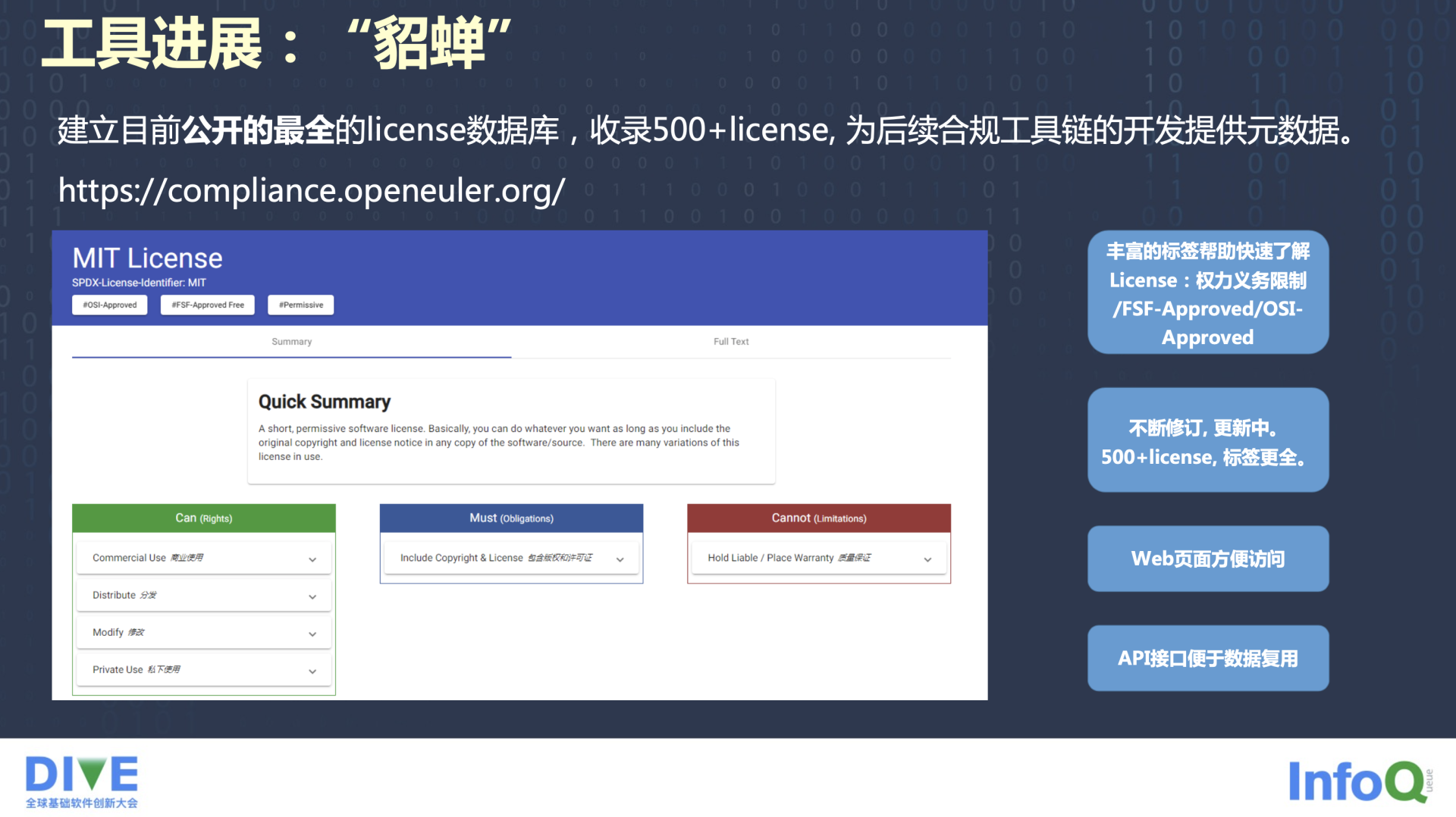
第一个工具是“貂蝉”,这也是大家最容易看到的可视化面板。“貂蝉”基本上是现在全世界最全的 License 数据库,大概收录有五百种 License。虽然其他社区也有类似的面板,但是他们标签和数量都也没我们多。目前我们也还在不断修订中,持续丰富我们的数据库。“貂蝉”是一个 Web 页面,方便访问,而且也提供了 API 接口做数据的查询复用。
大家可以看到截图上是 MIT License,页面会显示基于 SPDX 的 Identifier 识别情况,以及这个 license 是不是经过 OSI 跟 FSF 认证,是 Permissive 的,还是其他类型的 License。同时,还会展示它的标签,标签我们也翻译成了中文,但是这里有一个问题,中文的意思可能表达得不如英文那么准确,大家在用的时候可能要注意一点,有些英文单词我们中文翻译的时候是比较别扭的,不太容易更精准地表达它的意思。

第二个工具是“张飞”,张飞是基于一个开源工具 Scancode 构建的,是一个低使用门槛的合规代码扫描工具。“张飞”可以对 License 文本和 Copyright 进行扫描,最终基于 SPDX 的标准格式生成一个报告展示出来。它会通过一个饼图会告诉你,你有多少 License,分别有哪些,它是 Copyleft License 还是 Permissive License,它有多少个文件缺乏 Copyright 声明,有多少种不同的 Copyright 声明。这里可以看到,不同的公司可能 Copyright 写法是不一样的,但是同一个公司应该是同一套。我们在扫描过程中也发现,有些公司贡献的代码 Copyright 写法不一样。这块可以通过一些看版去观察,方便更系统地识别风险。

第三个工具是“华佗”,就是我们刚才讲的代码血缘分析工具,主要用于识别有没有片段使用。举个例子,这是它的一个界面,它会显示这个代码文件中有多少行开源软件的代码行是片段使用的,跟开源组件供应商匹配度是多少。它集成在 openEuler 的门禁中,无论是提 PR,还是对 Repo 静态仓库进行扫描,都可以去调用这个工具。而且支持多语言,现在业界所有常用的语言基本都支持,而且也可以在私有云上调用。

第四个工具是“吕蒙”,就是我们刚才说的基于论文发现变种 License 而产生的工具。我们当前已经集成了五种的算法用来识别变种 License,看一下究竟距离标准 License 语义有多远。它可以打标签,来提醒大家更好地去遵从义务,它还会做相似度识别。这里给大家描述一个概念,其实开源的 License 文本逻辑性非常强,有点像法律文本,前后衔接的逻辑非常强,所以它不像我们正常人说话一样,它不能用人类的自然语言处理来进行识别,这块难度非常大。我们的解决方案就是去叠加不同的算法,基于这个算法不断地扩充,进行一个综合判断,再进行人工的综合判断,最终识别出来它的变种 License。
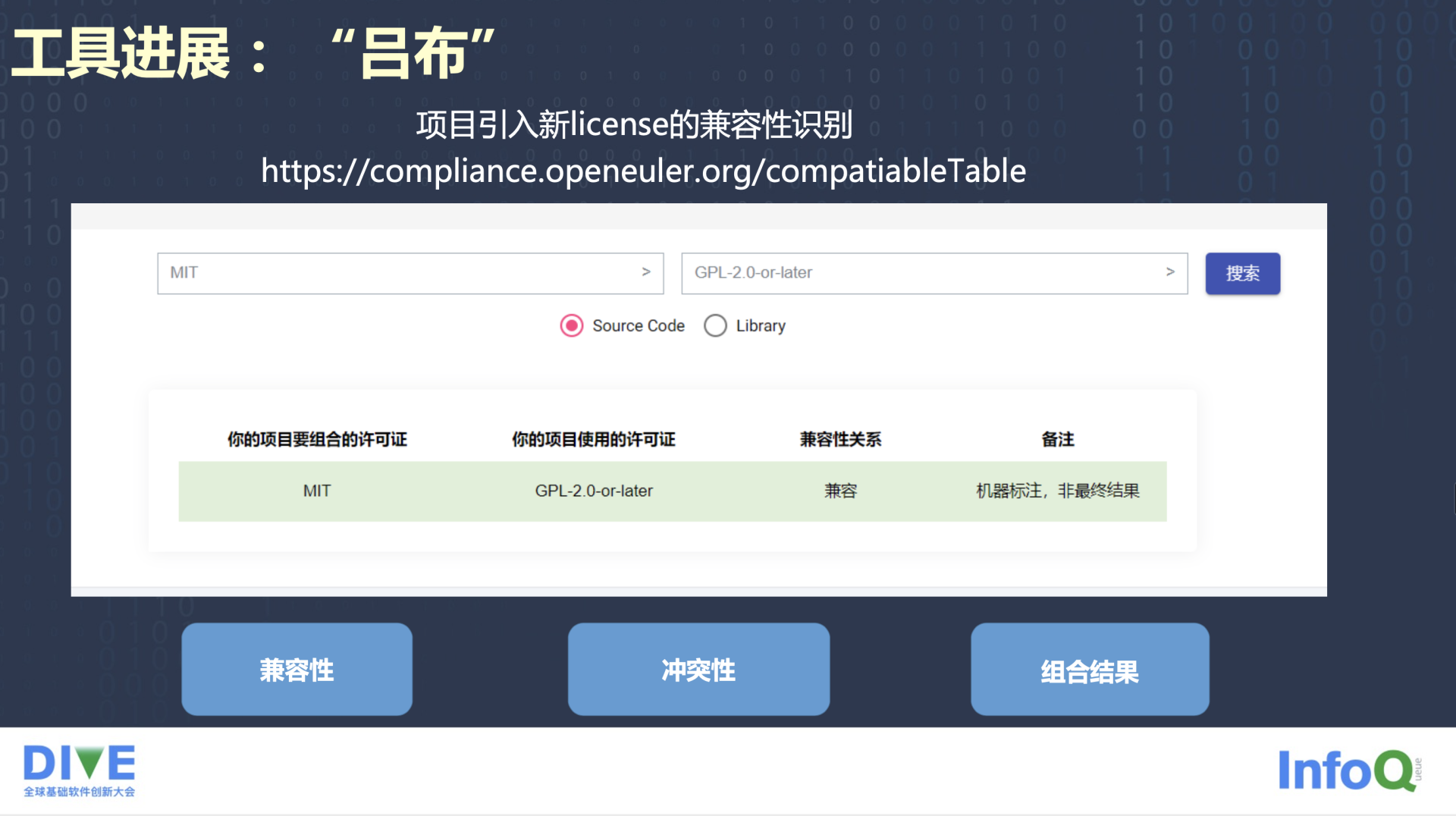
最后这个工具前面没有介绍,大家可以看到,这是一个新的工具,也是今年要重点做的一个工具。之所以把它放出来,也是想告诉大家,我们的合规工具还在不断地完善中,还有很多工具没有做完,就比如 License 兼容性识别工具“吕布”。
为什么叫“吕布”?这也是有来源的。大家都知道吕布跟了很多主子,所谓三姓家奴。我们这个工具也叫“吕布”,只要输入两个 License,在两个 License 之间要结合两个开源组件,谁调用谁,谁嵌入谁,它究竟是源码的调用还是二进制的调用,是什么样的关系,就能一目了然。只要输入两个 License,它会告诉你,你要组合的许可证是什么,你自己的项目使用的是什么,你要用的开源项目用了什么。如果这两个项目的许可证不兼容,那么这两个开源组件是不能在一起用的。如果兼容,是单向兼容还是双向兼容,兼容后使用什么 License 它也会做出一个推荐。这个工具现在已经可以试用了,大家也可以访问图中这个 URL 链接去看看,欢迎大家来试用。
合规的部分,基本上今天就给大家分享到这,同时合规 SIG 也在不断地往前探索,欢迎大家加入合规 SIG。
开源社区运营常见问题
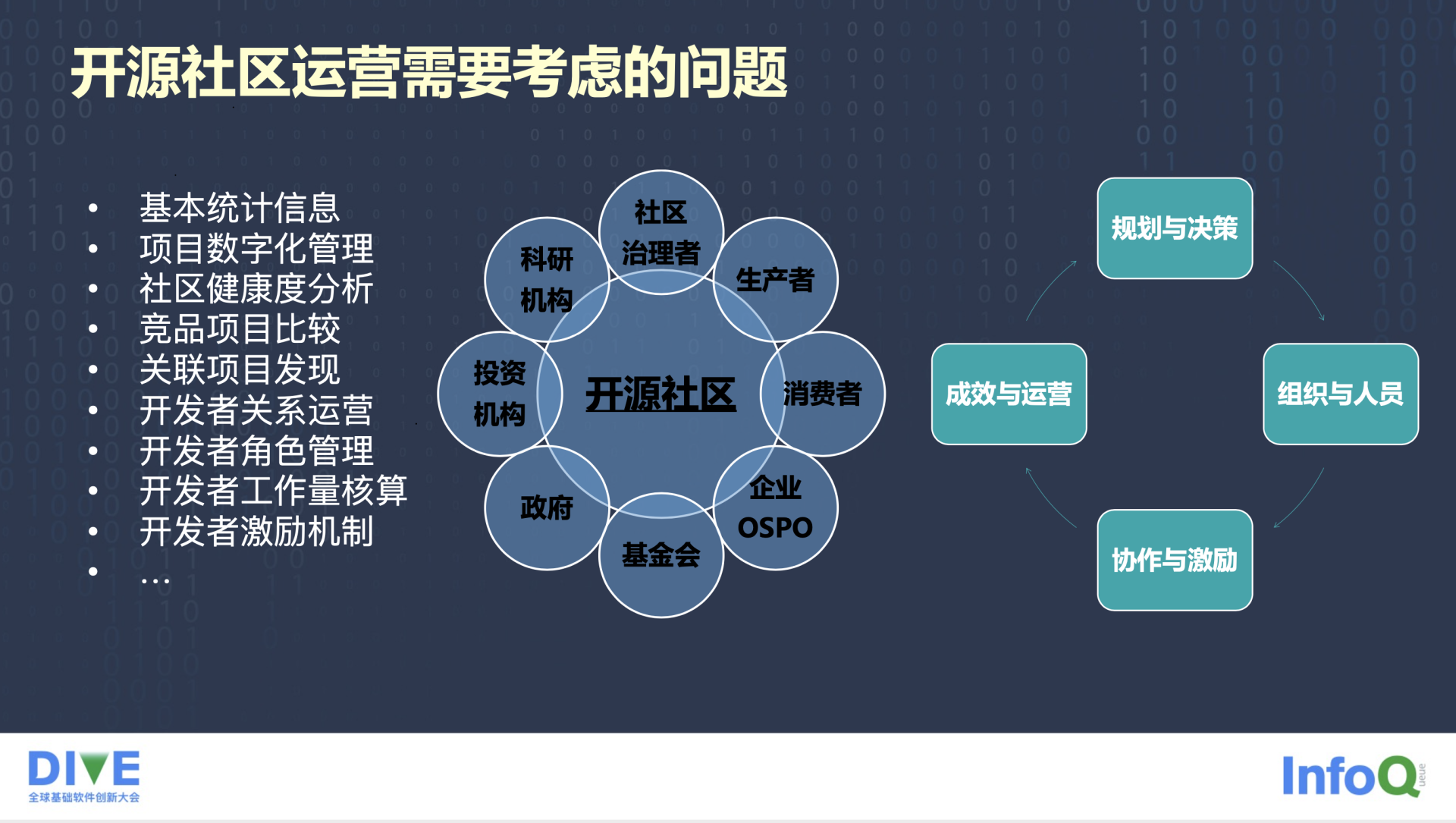
前面高琨老师重点介绍了 openEuler 在合规治理方面的一些探索与实践,我这块会围绕数字化运营来展开。社区运营是一个专门的岗位,有很多事情都会杂揉在这几个字里,很多人都会说社区运营基本上就是什么都会去做。我这里列举了一些可能会遇到的常见的运营场景,当然它们之间也未必完全正交,但可能是我们经常会听到的一些事情。
首先,数字化运营会关注一些基本的统计数据,比如说你有多少个贡献者,有多少次 Commit,从宏观上的数字化的监控和管理,确保整个社区机能都是在健康运行的。尤其是企业开源出来的一些项目,还会关注竞品分析和关联项目的推荐或者发现、比较等等。
开发者关系运营,有些地方也会叫技术运营,更多会涉及到处于不同的阶段、不同角色的开发者或者说贡献者,他们在 onboarding 和 engagement 的一些事情。此外还有计算工作量、贡献度和后续激励的问题。因为激励和 funding 是开源项目能够可持续发展的非常关键的因素,其中很关键的就是你要去能够识别、认可和量化项目中的这些贡献。用一个合理的机制,回馈到给社区做贡献的开发者中去。运营一个开源社区 - 我在思考这个问题的时候 - 对我来说比较有帮助的一个方式就是去看一看,你要去运营的这个东西里面都有谁,也就是有哪些利益相关者,从他们的视角去思考他们有哪些需求,找到问题。当然运营社区更多是站在社区负责人的视角,他可能是个 Committer,或者是个 PMC,或者是个 Community Manager。
我们列举了这么多运营相关的事情,它和传统的组织内部的管理还是有很多相似之处的。右边这张图是一个已经形成了共识的企业内部管理职能的框架,很多事情都可以映射到这四块里面:规划与决策,组织与人员,协作与激励,成效与运营。
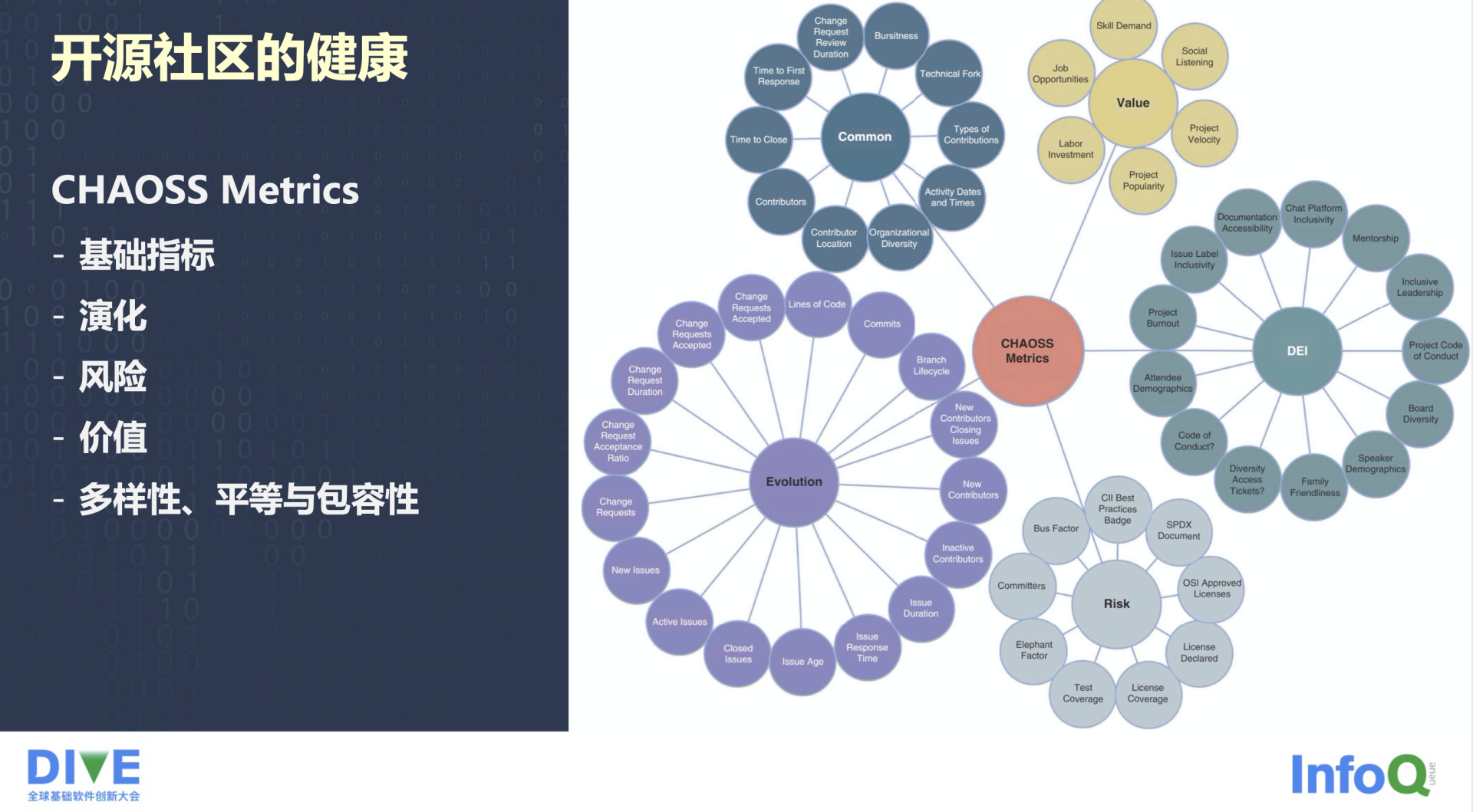
我们今天重点聊数字化运营,更多是指从可量化的指标来度量一个软件社区的性能,这里的性能远远不只是说对软件质量的度量。我想大家可能或多或少会有听说过,关注度量和开源社区健康度的一些人提出了 CHAOSS Metrics,这一套指标体系关注的是对开源社区健康度的度量,尤其是对一些平台性的项目,和使用如 JavaScript 语言这种很容易形成软件生态的一些项目,我们可以把它理解为是大型的软件生态。
仅仅关注软件仓库自身是远远不够的,这个时候我们就会经常说到 Healthy 和 Sustainability,就是我们会去关注一个软件社区是否健康、能够可持续发展。就像我们去关注气侯变化、濒危物种,我们生存的这个社会的文化、法律、秩序一样,我们也会去关注开源软件的演化、风险、它的价值以及在社区文化上是否多样、包容、平等这些方面的指标。

CHAOSS 在最新发布的 2021 年 10 月版本中一共有 70 个指标。这是指标的一个模板,它是以白皮书的形式来发布的。指标会告诉你,它描述的是什么,如何去实现,实现的过程可能会涉及到一些过滤条件,怎么去采集数据,怎么以可视化的形式来展现这个指标的特征。
很多人在看到 CHAOSS 整个指标体系的时候,会觉得它非常丰富和全面,但可能很快就面临一个问题,就是不知道该如何使用。这一整套指标体系是一个自顶向下结构化的三级指标体系,从最外层的 Working Group,就是前面讲到的各个维度,包括风险、价值、多样性、包容性以及演化等等,再到下层的 Focus Area,再到具体的一个指标。比如说你关注的是怎么去规避风险,Risk 工作小组下面就会包含一些如许可证风险、安全合规相关的内容帮你去了解如何规避风险。如果你关注的是怎么去营造一个繁荣友好的社区氛围,就可以去看一看在 DEI Working Group 下面的一些指标。
CHAOSS 指标体系有一些特点,尤其看 Evolution 演化工作小组下的指标,你会发现它的颗粒度是很小的。一个指标可以把它想象成一个元标签,每个指标的模板是比较抽象的,需要再进一步地组合或者细化,然后把它给实例化出来。
怎么去实现是一个见仁见智的事情,因为它有很多的过滤条件,它不断发布新的指标的方式,是通过继续枚举可能的新指标,这个过程中会涉及到自顶向下或自底向上,可能同时从两个角度来进行枚举。
然后它是比较易于观测的,但可能不是很具备可解释性。什么叫做易于观测,但难以具备可解释性?可以举一些例子,比如一个仓库它有多少个 Clone 数,有多少个 Fork 数,有多少个 Issue,有多少个 PR 数,这些数据是非常好采集的。但是得到的这些数据,不知道能够拿它来做什么,它们和业务不那么强相关,也不那么易于拿来直接去指导我去做一些什么事情。如果是和业务强相关,但是实现方式可能每个人都有自己的理解的一些指标,就需要通过一些算法来实现。举个例子,比如这个社区有多流行,它具备多大的影响力,它够不够活跃,它有多成熟,它有多健康。
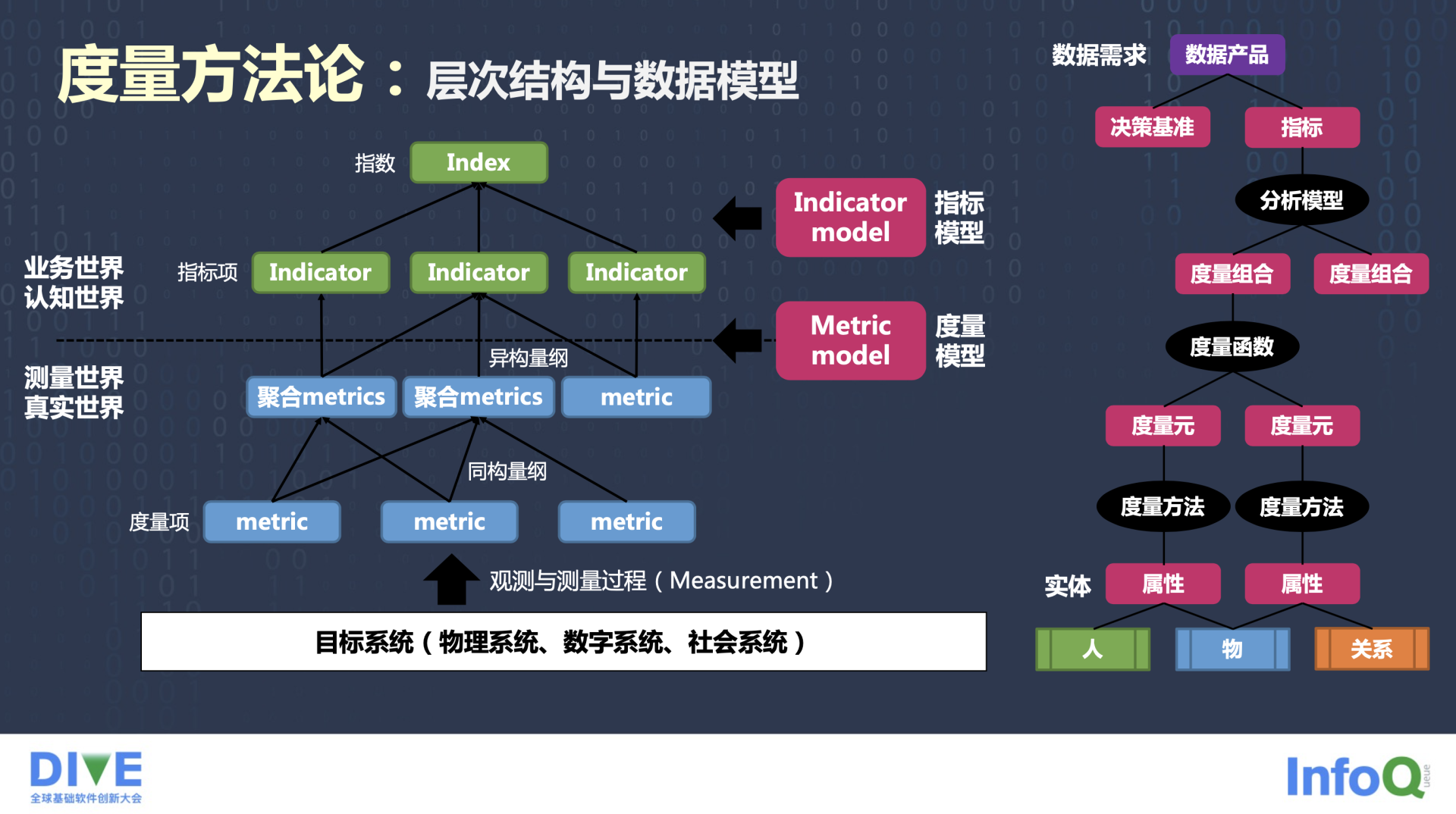
基于刚刚对指标的讨论,对于要去观测的目标系统可以得到这样一套度量的方法论。当然如果要去观测的是一个开源软件社区,它可能更多的是一个数字系统,可以直接得到一些数据,也就前面所说的,像 Commit、人数、Issue、PR 这些统计数据。可以把指标理解为这个观测对象的属性,而数据就是这些属性的值。这是比较容易得到的一些数据,可以理解为是已知的数据,但它们和业务并没有直接的关联,可以把这些在原子维度上统计数据的度量称作是度量元。这也参考了前两年非常流行的数据中台,它们会涉及到一些前台标签和后台标签的体系。与业务和场景和需求挂钩的经过一些度量函数和分析模型,得到度量组合,最终得到一个能够去辅助做业务决策的指标模型。这里只是暂时用英语做一些区分,并没有形成事实标准,还处于一个摸索的过程。但当我们在说"指标"的时候,应该学会去区分一下,测量的是真实世界更加容易得到的一些属性值 (Metris), 还是结合了业务和人的认知之后得到的一个数据产品,可以暂时把它称为 Indicator 或者 Index。
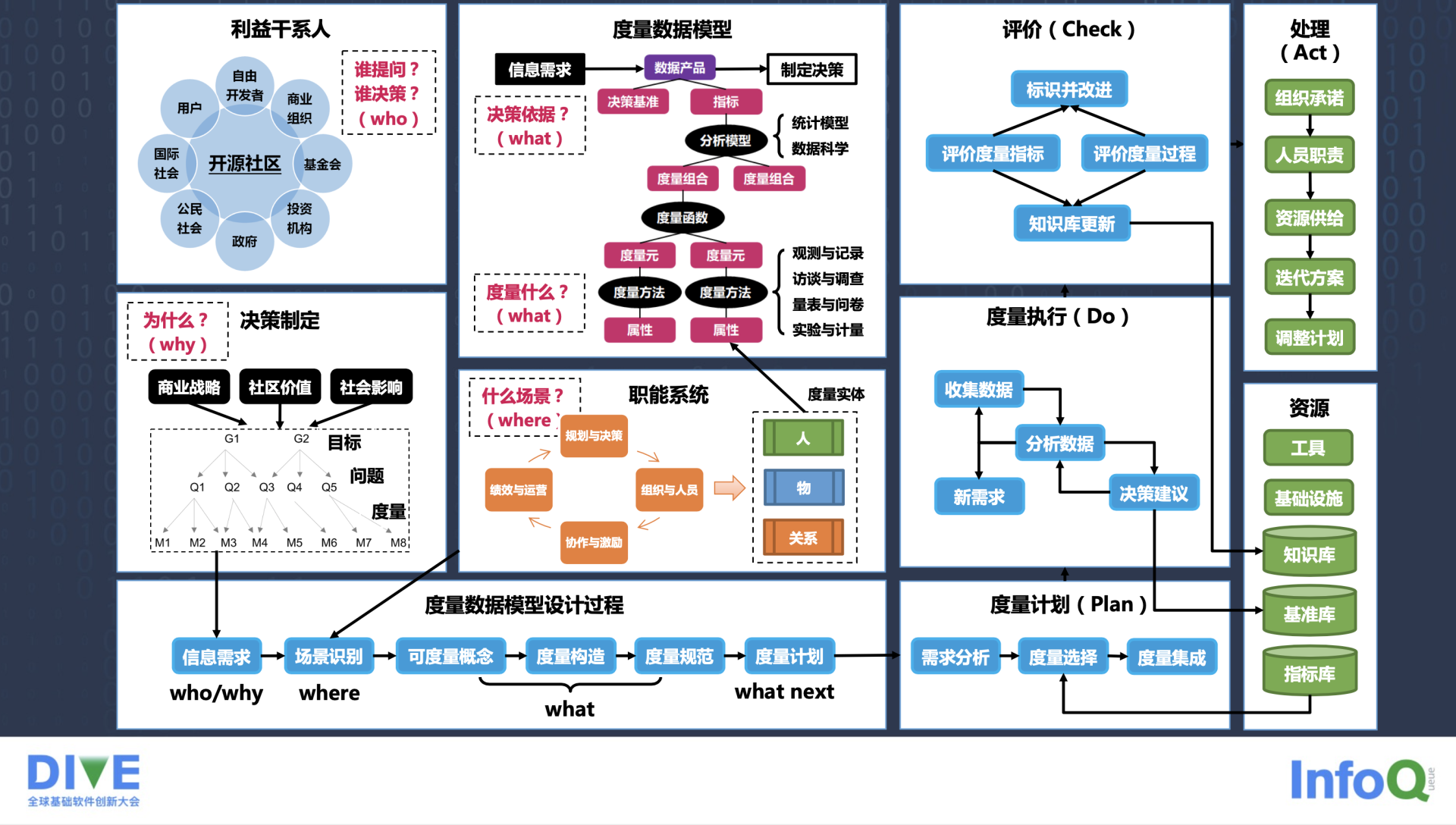
前面提出了度量数据模型,结合一开始说到的利益干系人,和一些企业内部也有异曲同工之妙的一些管理职能,可以系统地去搞清一个要度量的问题。就是从这些利益干系人,可以梳理、提出问题、决策基准,帮助我们回归到度量的第一性原理,也就是为什么要去度量一个事情。只有能够用于指导后续决策的度量才是有效的。而职能系统能帮助我们梳理出各种度量场景,它是个 Where 的问题。这个度量数据模型是决定要去度量哪些元素和信息,也就是 What。基于这些就得到了一次度量中的 Who、Why、What 和 Where 的问题。而我们去进行持续地度量与改进,就可以参考经典的戴明循环,从计划到执行,到评价,到持续的改进。
刚刚讲完了一些方法论的东西,现在来讲一下 CHAOSS 正在摸索的指标模型。
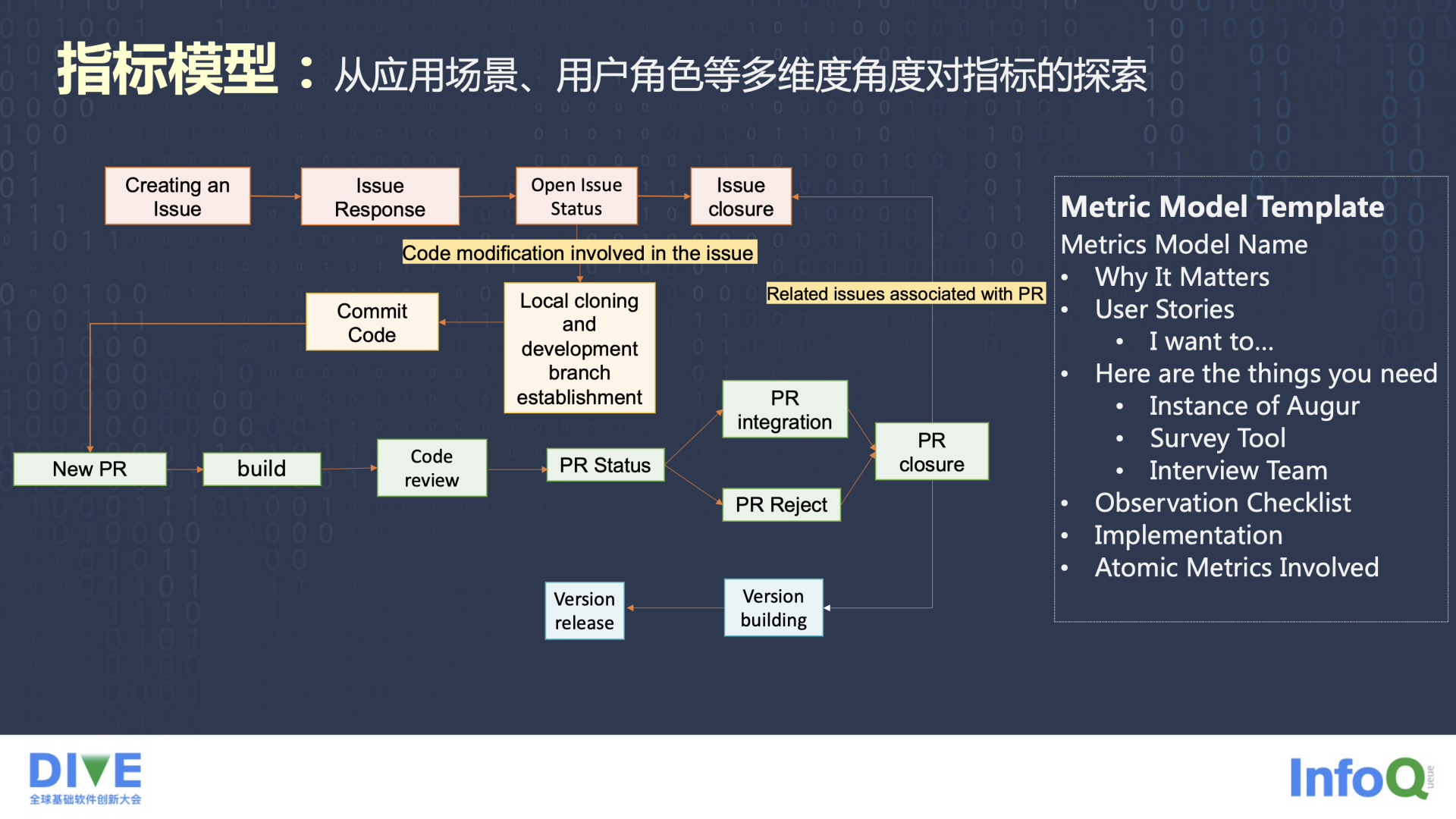
指标模型一开始也是 openEuler 社区的几位老师在 CHAOSS 中提出的,围绕它最原始形态的探索 Evolution 工作小组做了这样一件事情。大家可能会发现,有很多关于 Fork、Issue、PR 以及 Release 相关的指标,可以找到其中的联系。想象你去做贡献的一个过程,通常是先提出 Issue,里面可能有个待解决的问题或待实现的功能,当你决定通过修改代码仓库来解决这个问题,就会去提一个变更请求(PR),这个 PR 会关联到相关 Issue,PR 被合入是一个 Commit Code 的过程,与此同时 Issue 也会关闭,PR 也会关闭。累积了一定数量的被解决的 Issue 和被合入的 PR 之后,就会迎来一次版本发布,这就构成了一次次代码仓库演化的闭环。
前面说到 CHAOSS 的指标,它很多的指标是更加关注在一些度量元上,就是更加原子性的一些事情上。这些 Metrics 有点类似前面所讲的度量元之间的联系,很多 Metrics 可以一起组成一个 Metrics Model。指标模型,就是在这个基础上提出来的。可以看一下一个模板,目前包含的有哪些模块,首先我们需要解释为什么某个 Model 很重要,为什么你需要关注它。其次,用户故事是一个很重要的理念,倡导从不同的视角去使用相关的一些可能会涉及到的更加原子性的指标,去解决在特定的用户场景下重要的问题。实现方式也是一些数据采集和可视化的工具,也有一些是用 Survey 和 Interview 来做的,主要收集一些定性的数据。

可以看一个例子,是关于项目安全的,这是由微软的一位经理来主导的一个正在开发的指标模型。当然这里的安全并不是说 Security,而是 Safety,它是微软进行开源治理的时候定义的一个关键字。涉及到的五个维度更多是从 DEI 视角出发的,包括心理安全、包容性治理、包容性领导、委员会多样性和疲劳。我们可以具体举其中的一个 Focus Area,包容性治理的例子。
首先它会给出一些 Checklist,代表你达到包容性的治理需要具备哪些条件。右边这两张图是做调研和数据分析的一些方式,就是 Checklist、Survey 和数据分析等等这些,可以把它想象成一个 toolkit 工具箱来使用。指标模型有一个非常棒的点,就是它不会像指标一样,通过白皮书的形式进行半年一次定期发布,而是动态地在 Jupyter Notebook 里面更新。这也是为什么它在每个模块里面都有一个 Share how this went for you,这个模块是可以交互的,用户和贡献者可以去分享和更新他们的一些最佳实践。指标模型工作组成立到现在还不到半年,组会双周开一次,已经有很多很棒的东西出来,有很多人非常关心这个事情,会参与进来,大家感兴趣的话也可以去关注和参加。
openEuler 运营实践分享

除了指标模型以外,再分享两个 CHAOSS 即将发布的,也是基于 openEuler 社区内部数字化实践之后贡献到 CHAOSS 的两个指标。
第一个是贡献者推荐度,反应了社区的友好程度、受欢迎程度。这个指标是受启发于在做市场营销时候会用到的一个指标叫做 NPS,Net Promoter Score,在做用户调研的时候会用这个指标,根据你的推荐指数来调研用户满意度。同理,这也可以用来做开发者调研,让开发者来对这个社区打分。举个例子,如果是 0 到 6 分,他就是这个社区的批评者,他不是很喜欢这个社区的不管是氛围,还是软件质量等等。7 到 8 分可能是一个中立的态度,9 到 10 分就是 Promoter,也就是非常喜欢,已经是这个社区的一个布道者或者说是大使了,这个指标是 Value 工作小组即将发布的一个指标。

第二个指标是转化率,体现了社区留住贡献者的能力。一个好的社区应该有能力将一些偶发性的贡献者转化为长期贡献者,甚至是核心贡献者。图中是一个漏斗模型,来自电商营销中给我们的一些启发。在转化过程中,社区的治理者应该去关注贡献者有哪些需求,他的参与动机是什么。一个好的社区应该能够提供给贡献者他所需要的价值,无论是情绪价值,还是社会价值。从代码结构仓库的角度来举一个具体的例子,比如说第 0 级别可能就代表他只是 Star、Watch 或者 Fork 一个项目;第 1 级别就是他提了一个 Issue 或者评论,或者进行了一次 Review;到了第 2 级别就是他提了一个 PR,并且这个 PR 成功被合入,这个时候他可能以 GitHub 的定义来说,是一个事实意义上的代码贡献者。右边这张图就是 openEuler 社区内部的一个实现,它即将作为演化工作组的一个指标来发布。
总结

总结一下这次分享的内容,前面一块是关于合规的,合规会涉及到一系列版权专利许可证和出口管制的风险,像 openChain 和 SPDX,都是 Linux Foundation 下的两个项目,一个提供了合规标准,一个提供了一致性的数据交换格式,也是 openEuler 在使用并且在这两个项目中主导和贡献的。我们需要在各个链路上,从使用、到贡献、到主导,各个链路上去建立合规的流程。openEuler 也在自主研发一些像代码扫描分析、许可证兼容识别的合规工具。
运营这一块需要考虑到社区的角色,以及场景决策和成效等等因素。指标模型可以理解为是基于元指标来建立、用于指导后续决策的一个信息模型。
希望这次分享可以给大家带来一些启发和收获。未来 openEuler 的合规和运营的实践也会通过开源雨林的课程来输出,欢迎大家持续关注开源雨林的进展。




