

自然场景文字定位是文字识别中非常重要的一部分。与通用的物体检测相比,文字定位更具挑战性,文字在长宽比、尺度和方向上有更大范围的变化。针对这些问题,本文将介绍一种融合文字片段及金字塔网络的场景文字定位方法。该方法将特征金字塔机制应用到单步多框检测器以处理不同尺度文字,同时检测多个文字片段以及学习出文字片段之间 8-Neighbor 连接关系,最后通过 8-Neighbor 连接关系将文字片段连接起来,实现对不同方向和长宽比的文字定位。此外,针对文字通常较小特点,扩大检测网络中 BackBone 模型深层特征图,以获得更好性能。
本文提出的方法已发表在文档分析与识别国际会议 ICDAR2019 (International Conference on Document Analysis and Recognition)上,审稿人评论该方法为“As it is of more practical uses”,认可了它的实用性。
ICDAR 是由国际模式识别学会(IAPR)组织的专业会议之一,专注于文本领域的识别与应用。ICDAR 大会每两年举办一次,目前已发展成文字识别领域的旗舰学术会议。为了提高自然场景的文本检测和识别水平,国际文档分析和识别会议(ICDAR)于 2003 年设立了鲁棒文本阅读竞赛(“Robust Reading Competitions”)。至今已有来自 89 个国家的 3500 多支队伍参与。ICDAR 2019 将于今年 9 月 20-25 日在澳大利亚悉尼举办。美团今年联合国内外知名科研机构和学者,提出了“中文门脸招牌文字识别”比赛(ICDAR 2019 Robust Reading Challenge on Reading Chinese Text on Signboards)。
背景
自然场景图像中的文字识别已被广泛应用在现实生活中,例如拍照翻译,自动驾驶,图像检索和增强现实等,因此也有越来越多的专家学者对其进行研究。自然场景文字定位是指对场景图像中所有文本的精确定位,是自然场景文字识别中第一步也是最重要的一步。由于自然场景下文本颜色、大小、宽高比、字体、方向、光照条件和背景等具有较大变化(如图 1),因此它是非常具有挑战性的。

图 1 自然场景文字图片
深度学习技术在物体识别和检测等计算机视觉任务方面已经取得了很大进展。许多最先进的基于卷积神经网络(CNN)的目标检测框架,如 Faster RCNN、SSD 和 FPN[1]等,已被用来解决文本检测问题并且性能远超传统方法。
深度卷积神经网络是一个多层级网络结构,浅层特征图具有高分辨率及小感受野,深层特征图具有低分辨率及大感受野。具有小感受野的浅层特征点对于小目标比较敏感,适合于小目标检测,但是浅层特征具有较少的语义信息,与深层特征相比具有较弱的辨别力,导致小文本定位的性能较差。另一方面,场景文字总是具有夸张的长宽比(例如一个很长的英文单词或者一条中文长句)以及旋转角度(例如基于美学考虑),通用物体检测框架如 Faster RCNN 和 SSD 是无法回归较大长宽比的矩形和旋转矩形。
围绕上面描述的两个问题,本文主要做了以下事情:
为了处理不同尺度的文本,借鉴特征金字塔网络思路,将具有较强判别能力的深层特征与浅层特征相结合,实现在各个层面都具有丰富语义的特征金字塔。另外,当较深层中的小对象丢失时,特征金字塔网络仍可能无法检测到小对象,深层的上下文信息无法增强浅层特征。我们额外扩大了深层的特征图,以更准确地识别小文本。
我们不直接回归文本行,而是将文本行分解为较小的局部可检测的文字片段,并通过深度卷积网络进行学习,最后将所有文字片段连接起来生成最终的文本行。
现有方法
最新的基于深度神经网络的文本定位算法大致可以分为两大类:(1)基于分割的文本定位;(2)基于回归的文本定位。
(1) 基于分割的文本定位
当前基于分割的文本定位方法大都受到全卷积网络(FCN [2])的启发。全卷积网络(FCN, Fully Convolutional Network), 是去除了全连接(fc)层的基础网络,最初是用于实现语义分割任务。由于 FCN 网络最后一层特征图的像素分辨率较高,而图文识别任务中需要依赖清晰的文字笔画来区分不同字符(特别是汉字),所以 FCN 网络很适合用来提取文本特征。当 FCN 被用于图文识别任务时,最后一层特征图中每个像素将被分成文字行(前景)和非文字行(背景)两个类别。
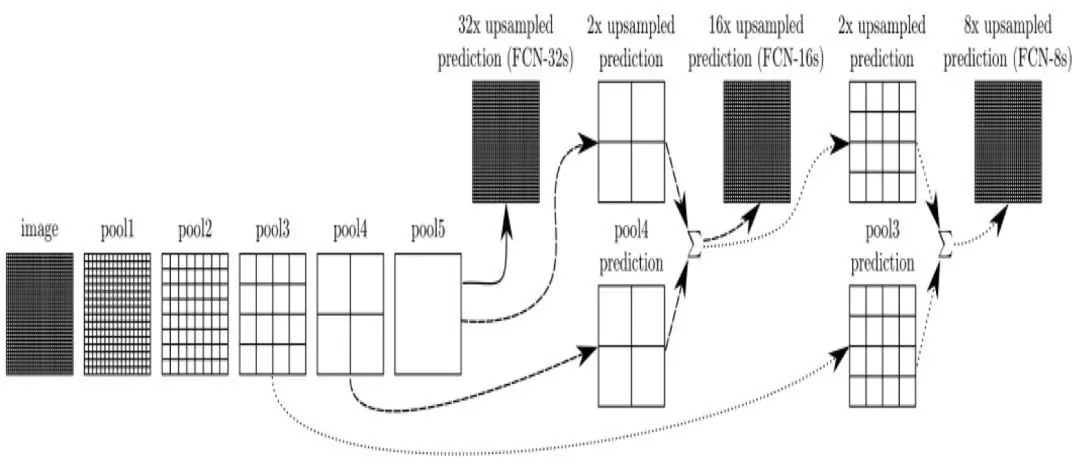
图 2 全卷积网络
(2) 基于回归的文本定位
Textboxes [3] 是经典的也是最常用的基于回归的文本定位方法,它基于 SSD 框架,训练方式是端到端,运行速度也较快。为了适应文本行细长型特点,特征层也用长条形卷积核代替了其他模型中常见的正方形卷积核。为了防止漏检文本行,还在垂直方向增加了候选框数量。为了检测大小不同的字符块,在多个尺度的特征图上并行预测文本框, 然后对预测结果做 NMS 过滤。
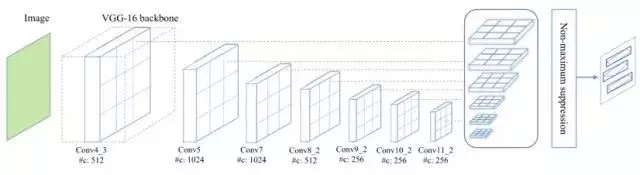
图 3 Textboxes 框架
提出方法
我们的方法也是基于 SSD,整体框架如图 4。为了应对多尺度文字尤其是小文字,对高层特征图进行间隔采样,以保持高层特征图分辨率。同时借鉴特征金字塔网络相关思路,将高层特征图上采样与底层特征叠加,构建一个新的多层级金字塔特征图(图 4 蓝色框部分)。此外,为了处理各种方向文字,在不同尺度的特征图上预测文字片段以及片段之间的连接关系,然后对预测出的文字片段和连接关系进行组合,得到最终文本框。下面将具体介绍方法。
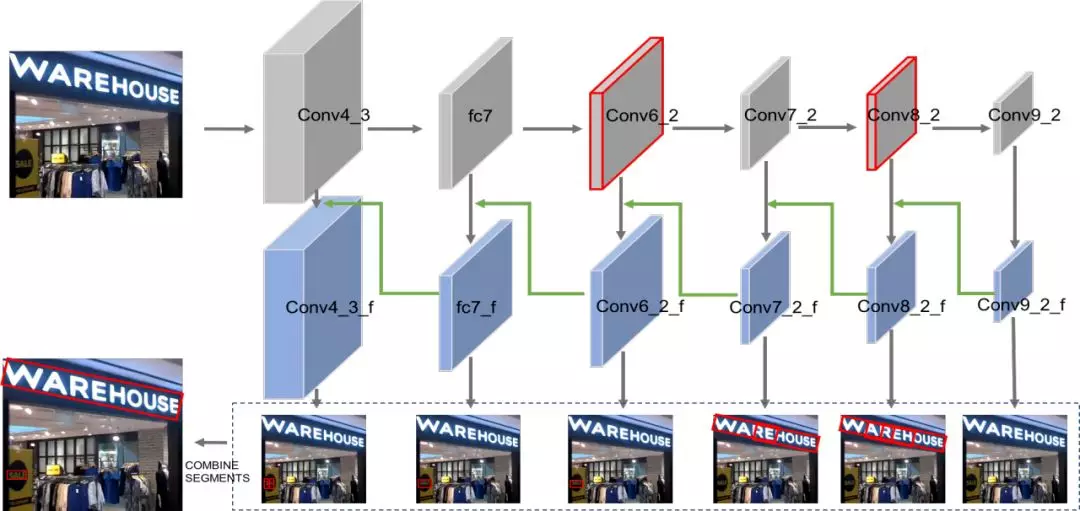
图 4 美团的方法框架
(1) 扩大高层特征图
深度卷积神经网络通常是逐层下采样,这对于物体分类来说是有效的,但是对于检测任务来说是有损害的。基于时间和性能的权衡考量,我们对卷积网络中最后几层特征进行间隔采样,如图 5,从 Conv6_2 层开始下采样,Conv7_2 层保持原分辨率,Conv8_2 层再下采样。
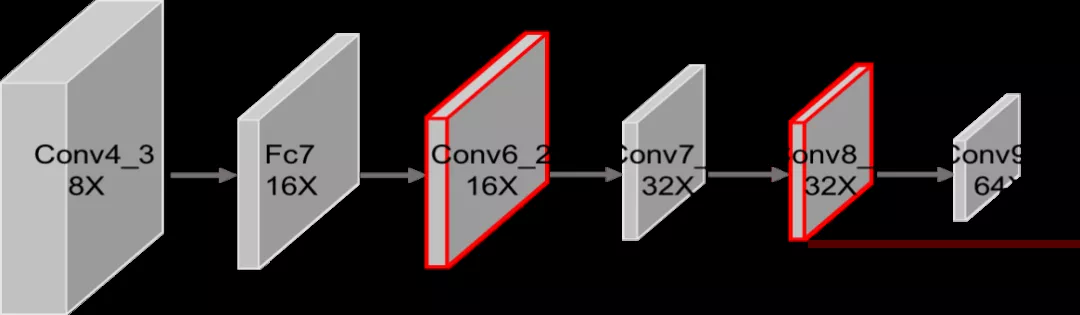
图 5 扩大特征图
(2) 构建特征金字塔
虽然通过扩大深度特征图的设计可以更好地检测小文本,但较小的文本仍然难以检测。为了更好地检测较小的文本,进一步增强较浅层(例如图 5 中 conv4_3,Fc7)的特征。我们通过融合高层和低层的特征构建了一个新的特征金字塔(图 4 中蓝色部分:conv4_3_f, fc7_f, conv6_2_f, conv7_2_f, conv8_2_f 和 conv9_2_f),新的金字塔特征具有更强辨别力和语义丰富性。
高层和低层特征融合策略如图 6 所示,高层特征图先进行上采样使之与低层特征图相同大小,然后与低层特征图进行叠加,叠加后的特征图再连接一个 3*3 卷积,获得固定维度的特征图,我们设定固定维度 d=256。
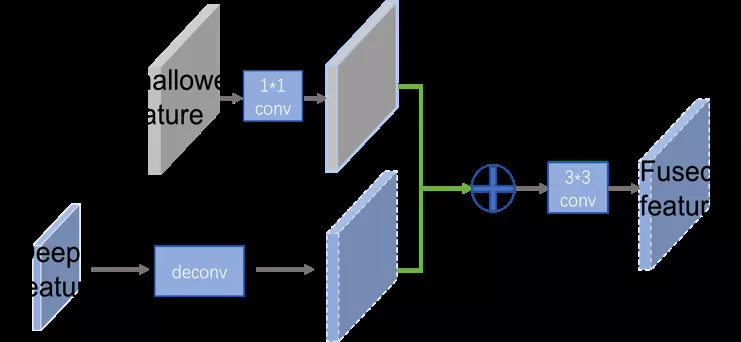
图 6 构建特征金字塔模块
(3)预测文字片段及片段之间连接关系
如图 7,先将每个文字词切割为更易检测的有方向的小文字块(Segment),然后用邻近连接(Link )将各个小文字块连接成词。这种方案方便于识别长度变化范围很大的、带方向的词和文本行,它不会象 Faster-RCNN 等方案因为候选框长宽比例原因检测不出长文本行,而且处理速度很快。

图 7 小文字块和近邻连接
基于第(2)小节构建的特征金字塔特征图,将每层特征图上特征点用于检测小文字块和文字块连接关系。如图 8,连接关系可以分为八种,上、下、左、右、左上、右上、左下、右下,同一层特征图、或者相邻层特征图上的小文字块都有可能被连接入同一个词中,换句话说,位置邻近、并且尺寸接近的文字块都有可能被预测到同一词中。
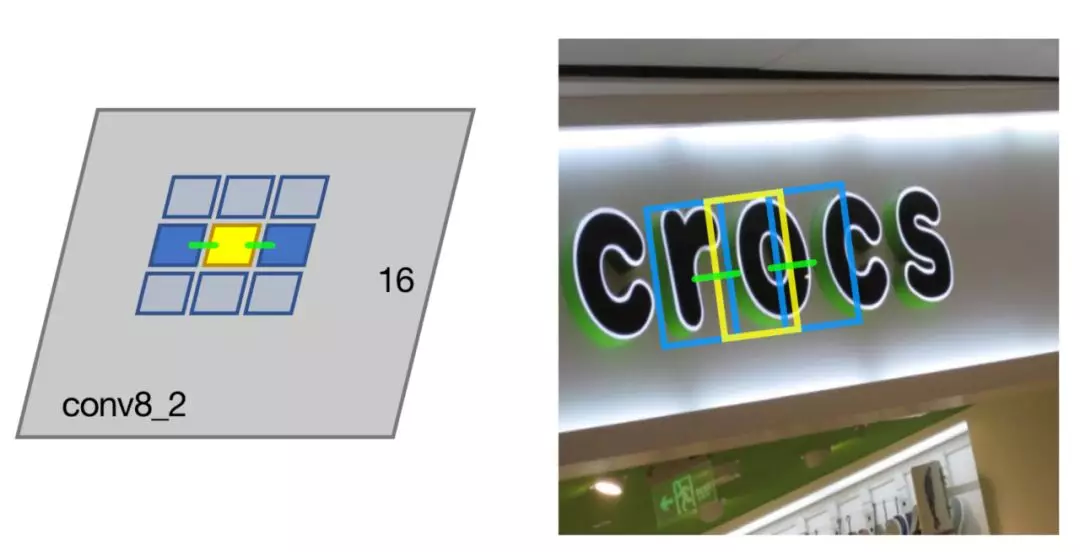
图 8 连接关系示意图
最后基于检测出的小文字块以及文字块连接,组合出文本框(如图 9),具体组合过程如下:
(a) 将所有具有连接关系的小文字块组合起来,得到若干小文字块组;
(b) 对于每组小文字块,找到一条直线能最好的拟合组内所有小文字块中心点;
(c) 将组内所有小文字块的中心点投影到该直线上,找出距离最远的两个中心点 A 和 B;
(d) 最终文字框中心点为(A+B)/2,方向为直线斜率,宽度为 A,B 两点直线距离加上 A,B 两点的平均宽度,高度为所有小文字块的平均高度。

图 9 小文字块连接示意图
实验及应用
我们在两个公开数据集上(ICDAR2013,ICDAR2015)对方法进行评测。其中 ICDAR2013 数据集,训练图片 229 张,测试图片 233 张;ICDAR2015 数据集,训练图片 1000 张,测试图片 500 张,它们都来自于自然场景下相机拍摄的图片。
(1)我们首先对比了扩大高层特征图与不扩大高层特征图的性能比较,并在基础上对比加入特征金字塔后的性能比较,在 ICDAR2015 数据集上实验,结果如表 1:
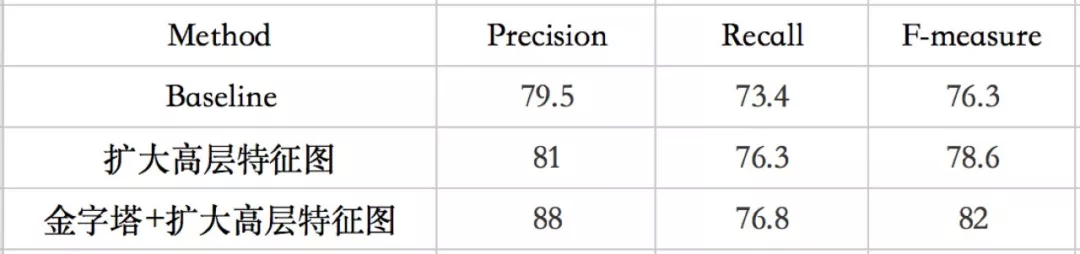
表 1 方法中不同模块有效性验证
“BaseLine”方法是 SSD 框架+预测文字片段及片段之间连接关系模块,“扩大高层特征图”是在 BaseLine 方法基础上对高层特征图进行扩大,“金字塔+扩大高层特征图”是在 BaseLine 方法基础上对高层特征图进行扩大 并且加入特征金字塔。从表 1 中不难发现,扩大高层特征图可以带来精度和召回的提升,尤其是召回有近 3 个点的提升(73.4->76.3),这很好理解,因为更大的特征图产生更多的特征点以及预测结果;在此基础上再加入金字塔机制,精度获得显著提升,说明金字塔结构极大增强低层特征判别能力。
(2)我们也和其他方法也做了比较,具体见表 2 和表 3:
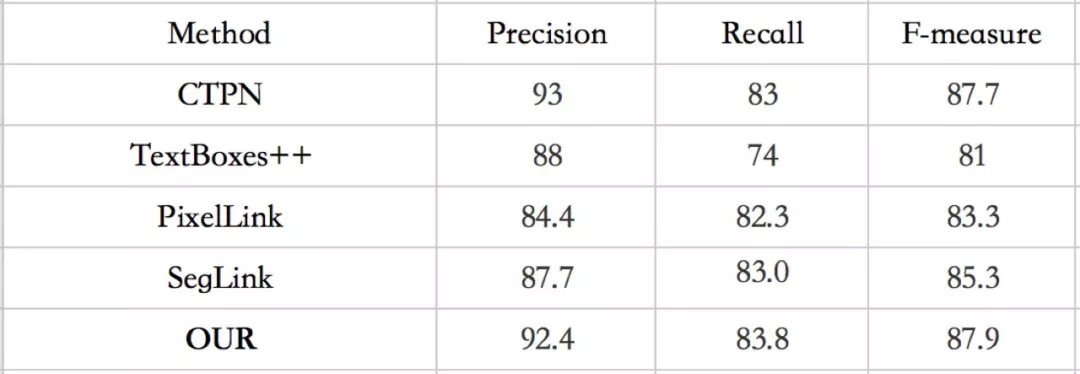
表 2. ICDAR2013 数据集与其他方法比较
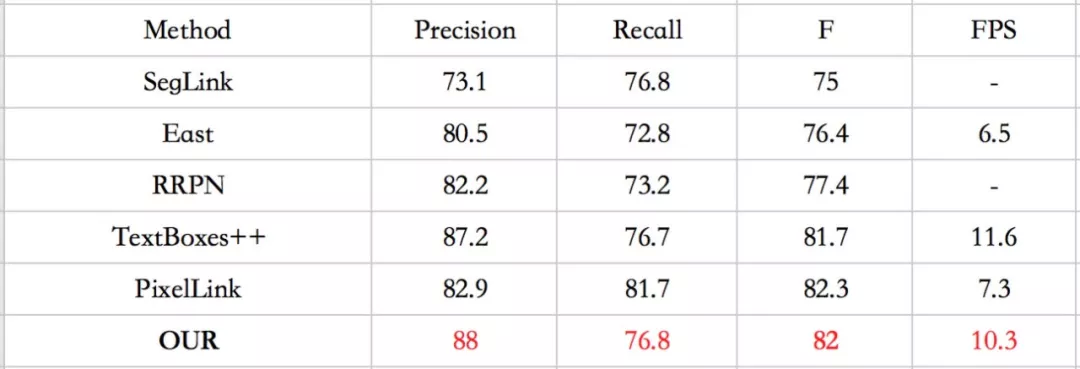
表 3. ICDAR2015 数据集与其他方法比较
从上表中可以看出,我们的方法在时间和精度上取得很好的权衡。在 ICDAR2015 数据集上,虽然性能不及 PixelLink,但是 FPS 要远高于它;而相比 TextBoxes++,虽然 FPS 略低于它,但是精度更高。图 10 给出一些文字定位结果示例。

图 10 文字定位结果示意图
(3)此外,本方法也落地应用于实际业务场景菜单识别中。菜单上文字通常较小、较密,菜名文字可长可短,以及由于拍摄角度导致文字方向倾斜等。如图 11 所示,方法能很好的解决以上问题(小文字、密集文字行、长文本、不同方向);并且在 500 张真实商家菜单图片上进行评测,相比 SegLink 方法,性能明显提升(近 5 个点提升)。

表 4 菜单测试结果
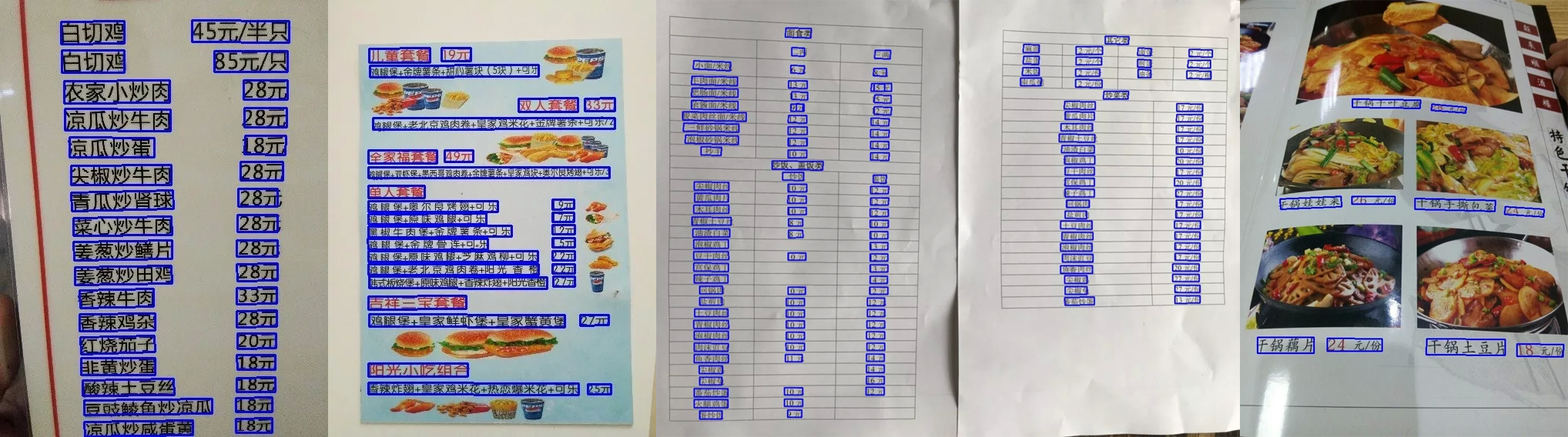
图 11 菜单文字定位结果示意图
结论
本文我们提出了一个高效的场景文本检测框架。针对文字特点,我们扩大高层特征图尺寸并构建了一个特征金字塔,以更适用于不同比例文本,同时通过检测文本片段和片段连接关系来处理长文本和定向文本。实验结果表明该框架快速且准确,在 ICDAR2013 和 ICDAR2015 数据集上获得了不错结果,同时应用到公司实际业务场景菜单识别上,获得明显性能提升。下一步,受实例分割的方法 PixelLink [4]的启发,我们也考虑将文本片段进一步细化到像素级,同时融合检测和分割方法各自优缺点,构建联合检测和分割的文字定位框架。
参考文献
Tsung-Yi Lin, Piotr Dollár, Ross Girshick, Kaiming He, Bharath Hariharan, Serge Belongie. “Feature Pyramid Networks for Object Detection.” arXiv preprint. arXiv: 1612.03144, 2017.
J. Long, E. Shelhamer, and T. Darrell. “Fully convolutional networks for semantic segmentation.” In CVPR, 2015.
M. Liao, B. Shi, and X. Bai. “Textboxes++: A single-shot oriented scene text detector.” IEEE Trans. on Image Processing, vol. 27, no. 8, 2018.
D. Deng, H. Liu, X. Li, and D. Cai. “Pixellink: Detecting scene text via instance segmentation.” In AAAI, pages 6773– 6780, 2018.
作者介绍:
刘曦,美团视觉图像中心文字识别组算法专家。
本文转载自公众号美团技术团队(ID:meituantech)。
原文链接:
https://mp.weixin.qq.com/s/l1rmGxOVrXKAaf4yYUt4kQ

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论