
一、TBase 分布式数据库介绍
1. TBase 发展历程

腾讯云从 2009 年便开始在内部的业务上进行尝试,在企业分布式数据库领域的自研过程是比较有经验的。当时主要是为了满足一些较小的需求,比如引入 PostgreSQL 作为 TDW 的补充,弥补 TDW 小数据分析性能低的不足,处理的需求量也较小。
但业务慢慢的大了后,需要有一个更高效的在线交易事务的处理能力,对数据库要进行一个扩展,所以后面我们就持续的投入到数据库的开发过程中。
2014 年 TBase 发布的第一个版本开始在腾讯大数据平台内部使用;2015 年 TBase 微信支付商户集群上线,支持着每天超过 6 亿笔的交易;2018 年的时候 V2 版本对事务、查询优化以及企业级功能做了较大增强,慢慢的开始面向一些外部客户;2019 年 TBase 中标了 PICC 集团的核心业务,协助了他们在国内保险行业比较领先的核心系统,并稳定服务了很长的时间。
考虑到 TBase 整体能力的持续发展,我们是希望把 TBase 的能力贡献给开源社区,这样能更多的支持数据库国产化项目。于是在 2019 年 11 月,我们把数据库进行了开源,希望能助力数字化产业升级。
2. PostgreSQL 数据库简介
TBase 是基于单机 PostgreSQL 自研的一个分布式数据库,除了具备完善的关系型数据库能力外,还具备很多企业级的能力。同时增强了分布式事务能力,以及比较好的支持在线分析业务,提供一站式的解决方案。
在数据安全上,我们有着独特之处,包括三权分立的安全体系,数据脱敏、加密的能力。其次在数据多活、多地多中心的灵活配制上面,也提供了比较完善的能力,保障了金融行业在线交易中一些高可用的场景。为金融保险等核心业务国产化打下坚实基础。
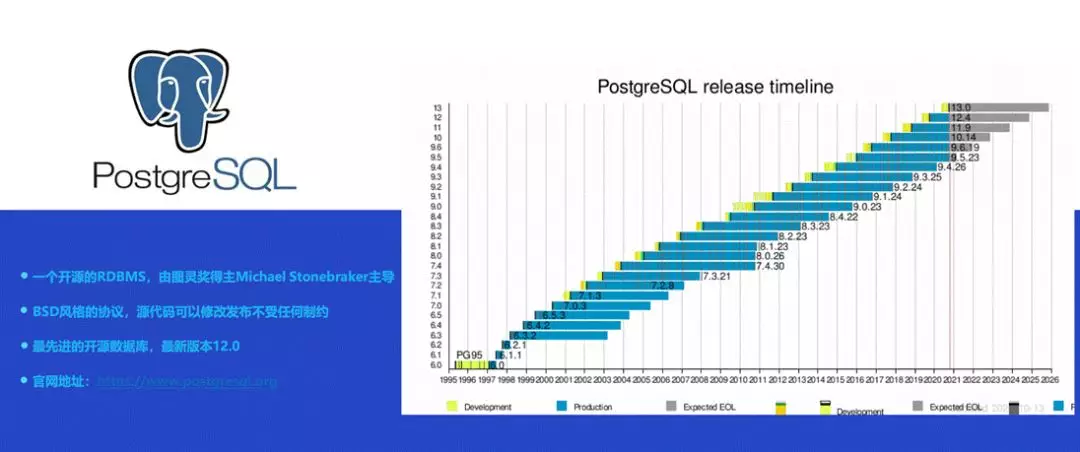
PostgreSQL 是一个开源的 RDBMS,开源协议基于 BSB 风格,所以源代码可以更加灵活的供大家修改,也可以在修改的基础上进行商业化。
PostgreSQL 是由图灵奖得主 MichaelStonebraker 主导的一个开源项目,如上图所示,它已经迭代得比较久了,到现在已经发布到 12 版本,并且一直在持续的迭代,整体处于一个比较活跃的水平。
3. PostgreSQL 发展趋势
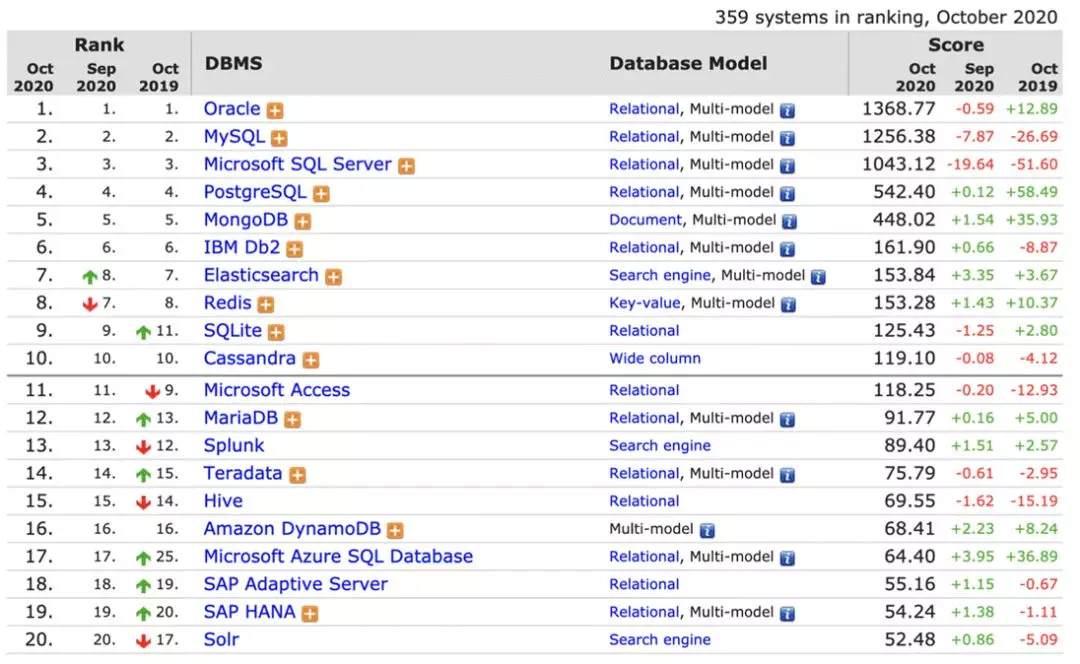
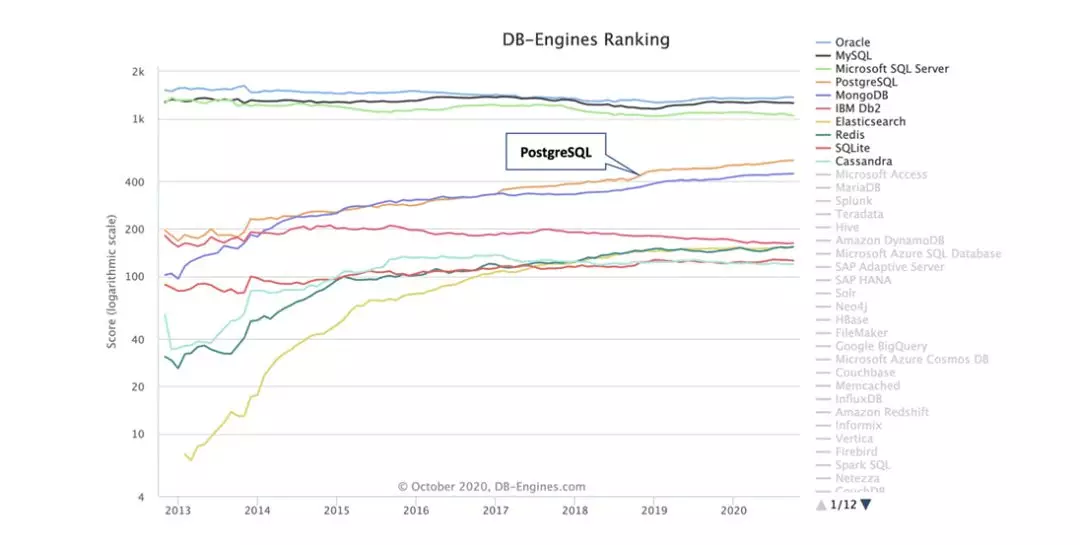
PostgreSQL 在近十年开始受到的大家的关注,首先是因为它的内核功能,包括社区的持续活跃,在过去几年获得了持续的进步。上图是来自 DB-Engines 的统计,根据数据我们可以看到在去年整体大家都有一些退步和增长不太高的情况下 PostgreSQL 的进步是比较明显的。
下图中黄色的曲线是 PostgreSQL,我们可以很直观的看到它发展趋势是比较良好的。
目前开源的 TBase 版本是基于 PostgreSQL10,我们也在持续的匹配 PostgreSQL 更多的功能,后续也会回馈到开源社区,希望和整体的 PostgreSQL 生态有一个良好的结合和互动。
二、开源 TBase 定位及整体架构
1. 开源 TBase 的定位

数据库按照业务场景主要分为:OLAP、OLTP 和 HTAP。
OLAP 的业务特点是数据量较大,一般是 10PB+,对存储成本比较敏感。它的并发相对于 OLTP 不会太高,但对复杂查询可以提供比较好的支持。
OLTP 的数据量相对较小,很多中小型的系统都不会达到 TB 级的数据量,但对事务的要求和查询请求的要求会比较高,吞吐达到百万级 TPS 以上。并且 OLTP 对于容灾能力要求较高。
国内的国产化数据库很多会从 OLAP 领域进行切入,从 OLTP 角度切入会相对比较难,目前这一块还是被 IBM 或者 Oracle 垄断的比较严重,我们希望尽快在这一块实现国产化。而 TBase 因为在保险行业有比较长时间的耕耘,在 OLTP 核心业务能力上有比较强的。
另外一个是 HTAP。在之前大部分的业务部署中,大家会把 TP 和 AP 分开,在中间可能有 ETL 或者流复式的技术将两套系统进行交互。但更理想的情况是可以在一套系统中同时完成两种业务类型的支持。
当然这个会比较复杂。首先大家可以看到他们的业务特点差别比较大,内核领域的优化方向也是完全不一样的,或者说技术上差异比较大。
TBase 推出 HTAP 也是从具体的需求出发,实际上 TBase 是更偏向于 TP,同时兼顾了比较好的 AP 的处理能力,在一套系统里尽量做到比较好的兼容。但如果要做更极致性能的话,还是要对 HTAP 进行隔离,对用户提供一种完整的服务能力。

TBase 的角度也是根据需求衍生出来的。腾讯云最早是做交易系统,后面慢慢的补充了 AP 的分析能力。
这块面临的主要的业务场景需求,首先是交易数据可能会大于 1T,分析能力大于 5T,并发能力要求达到 2000 以上,每秒的交易峰值可能会达到 1000 万。在需要扩展能力的情况下,需要对原有的事务能力、分析能力,或者数据重分布的影响降到最低。同时在事务层面做到一个完备的分布式一致性的数据库。
同时 TBase 也进行了很多企业级能力的增强,三权分立的安全保障能力、数据治理能力、冷热数据数据及大小商户数据的分离等。

前面我们介绍了 TBase 的发展过程,在这过程中我们也希望可以为开源社区进行一些贡献。
实际上在国内环境中替换核心业务还是比较难,更多的是从分析系统切入,最近几年才开始有系统切入到核心的交易事务能力上,TBase 也希望通过开源回馈社区,保证大家可以通过 TBase 的 HTAP 能力来填补一些空白,扩充生态的发展。
开源后我们也受到了比较多的关注和使用,其中还包括欧洲航天局的 Gaia Mission 在用我们的系统进行银河系恒星系统的数据分析,希望有更多的同学或者朋友加入到 TBase 的开发过程中,也希望通过本次介绍,方便大家更好的切入到 TBase 开源社区的互动中。
2. TBase 总体构架
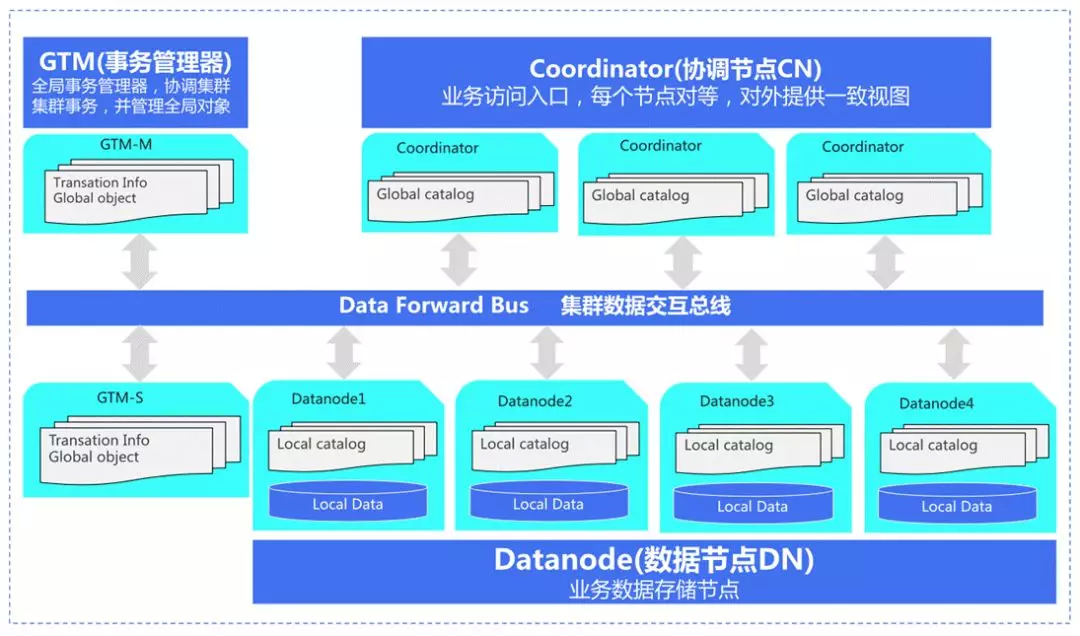
一个集群是由这几个部分组成:GTM、Coordinator 和 Datanode。其中 GTM 主要负责全局事务的管控,是提供分布式一致性协议的基石;Coordinator 是用户业务的访问入口,对用户的请求进行分析和下发,具体的计算和数据存储则是放到了 Datanode 当中。
三、HTAP 方面能力介绍
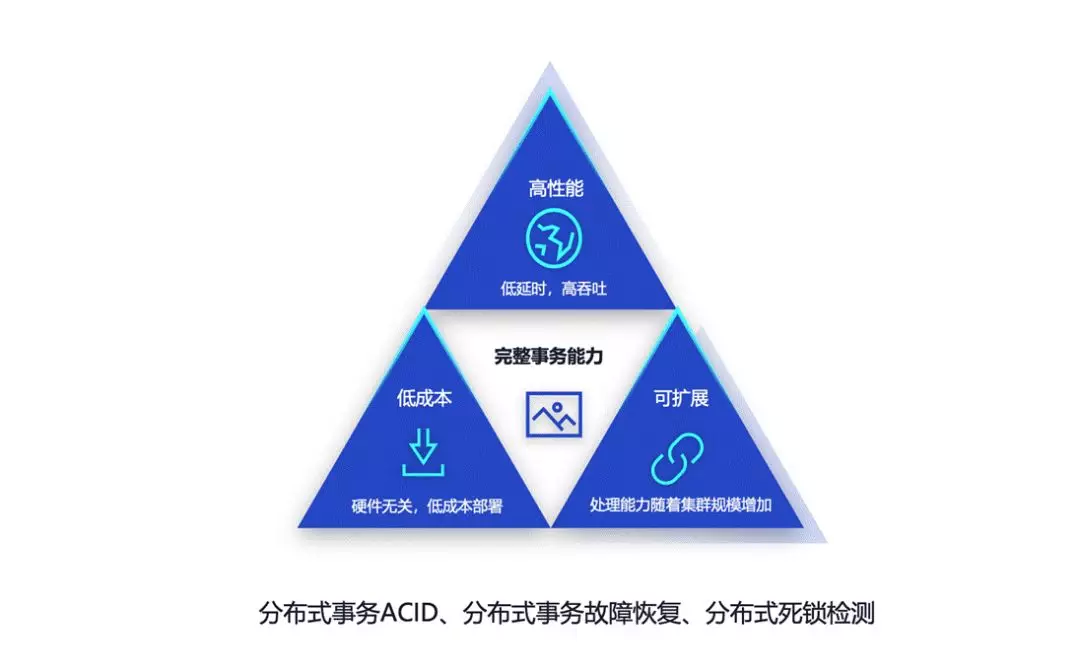
刚才我们讲的是 HTAP,下面我们先讲一下 OLTP,TBase 在这部分的能力是比较突出的。
如果用户需要在事务或者并发交易量上有要求的话,就需要一套比较好的分布式事务的系统。具体的需求包括高性能和低成本,在这部分,TBase 相较于传统的 IBM 或者国外更贵的一体机有较大的优势。
另外一个需求就是可扩展,在节点扩展的情况下去近似线性的扩展事务处理能力。那要如何达成这个目标?
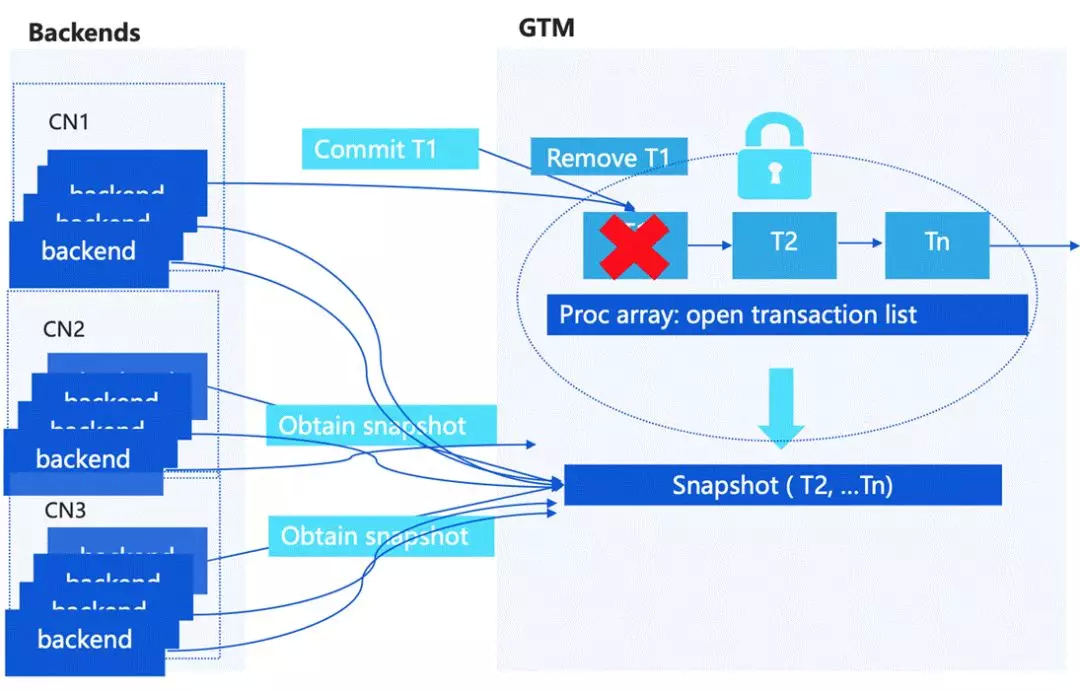
简单介绍一下事务的 MVCC 的处理,单机 PostgreSQL 主要是维护一个当前的活跃事务列表,它有一个结构叫 Proc array,相当于每一个用户的 session 有新的事务请求的话,会在事物列表里去记录当前活跃的事务,当需要判断 tuple 的可见性的话,会在活跃事务列表里拿一个 Snapshot 去跟存储上面的 tuple header 中记录的 XID 信息进行一个对比,去做 MVCC 的访问控制。
如果是扩展到分布式的情况,一个比较简单的方式是需要有一个中心节点。按之前的构架,在 GTM 上面会有一个中心化的活跃事物列表,来统一的为每一个访问的请求去分配 Snapshot。
但这个时候就有一个比较大的问题,中心节点会成为瓶颈,GTM 也会有一些问题,比如说快照的尺寸过大或者占用网络较高。
GTM 如果做一个中心化的节点的话,实际上存在一个单点瓶颈,每一个请求都要保证它拿到 snapshot 的正确性,这就需要对活跃事务列表进行上锁,这个在高并发情况下锁冲突会很大。我们是怎么解决这个问题的呢?
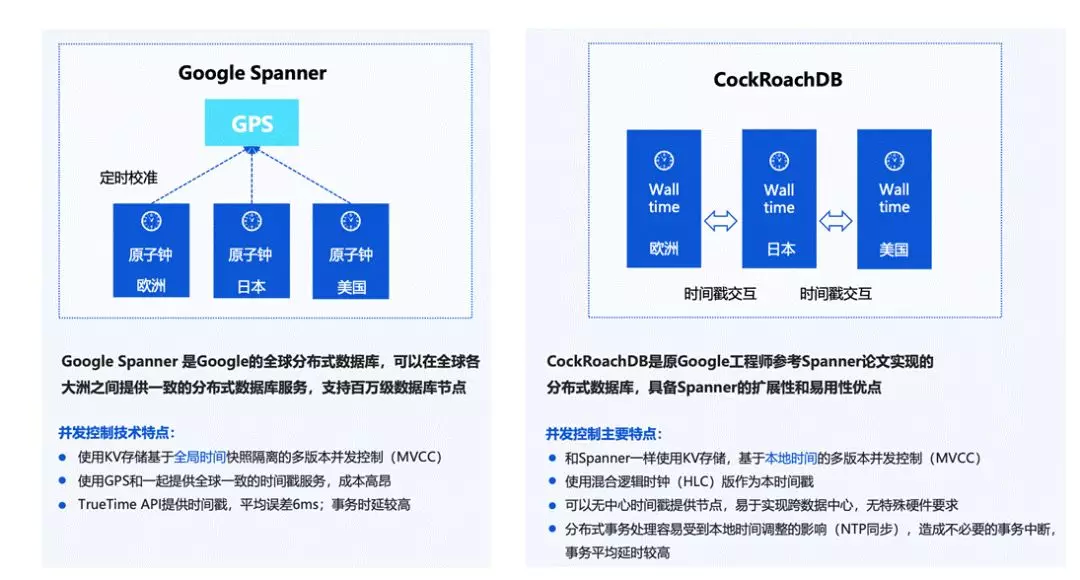
这实际上也是业界一个通用的问题。目前我们看到互联网行业的方案,是从 Google Spanner 的方向衍生出来的。
Google Spanner 是一个全球分布式数据库,可以在各大洲之间提供一致性的数据库服务能力。它的控制并发技术特点,一是通过 KV 存储基于全局时间的多版本并发控制,另外一个是它通过使用成本比较高的 GPS 和全球一致的服务时间戳机制来提供一个 TrueTime API,基于真实时间制作一套提交协议。因为它的整体全球分布式,导致平均误差会大概在 6 毫秒左右,整体的事务时延是比较高的。
另外,有较多的系统会借鉴 Google Spanner 做事务模型,CockRoachDB 也是其中之一。
另外,Percolator 也是 Google 为搜索引擎提供的一个比较有效率的数据库,使用 KV 存储,基于全局逻辑时间戳的 MVCC 进行并发控制。它的时间戳由专门的时间戳服务提供,分布式事务第一阶段需要对修改记录加锁,提交阶段结束锁定;事务提交时间复杂度为 O(N),N 是记录数,导致提交的性能会有影响,当然这样的设计也和系统需求相关。
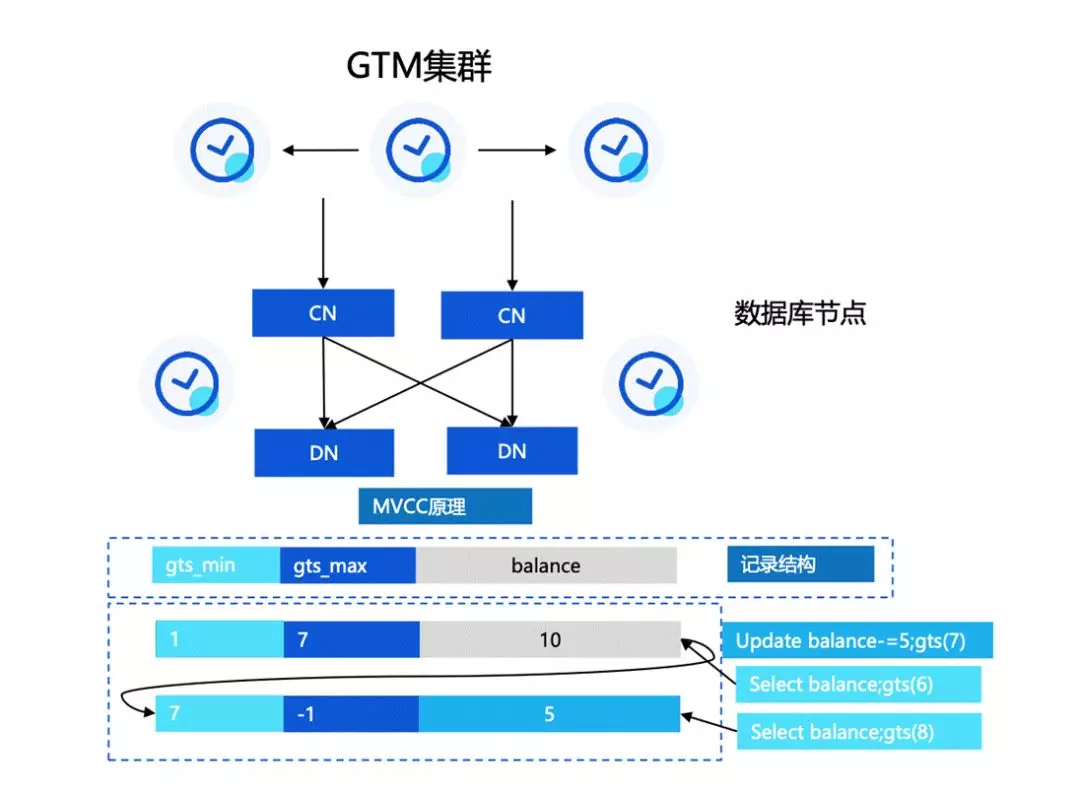
下面看一下 TBase 在分布式事务上的能力,这部分我们也是在前面的基础上做了较大改进。
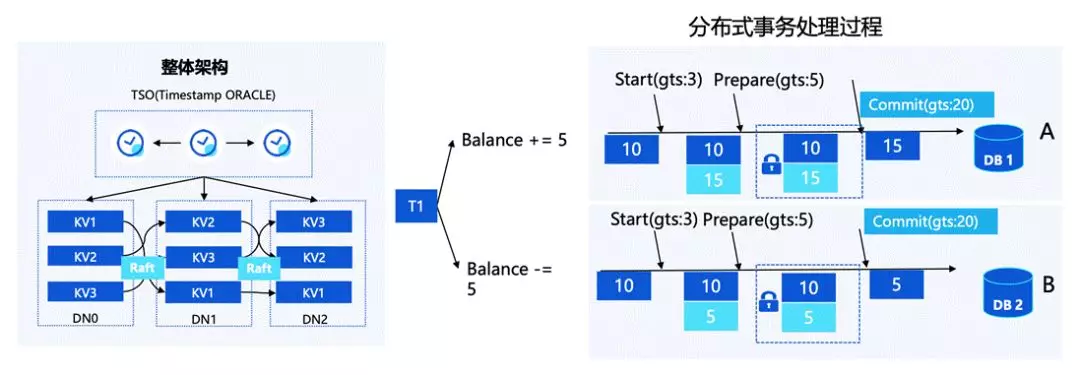
首先我们对 GTM 集群做了优化,从原始的全局 XID 改成了分配全局时间戳 GlobalTimeStamp(GTS),GTS 是单调递增的,我们基于 GTS 设计了一套全新的 MVCC 可见性判断协议,包括 vacuum 等机制。这样的设计可以把提交协议从 GTM 的单点瓶颈下放到每一个节点上,减轻压力,同时通过时间戳日志复制的方式实现 GTM 节点主备高可用。
这种协议下 GTM 只需要去分配全局的 GTS,这样的话单点压力就会被解决得比较明显。根据我们的推算, 滕叙 TS85 服务器每秒大概能处理 1200 万 TPS,基本能满足所有分布式的压力和用户场景。
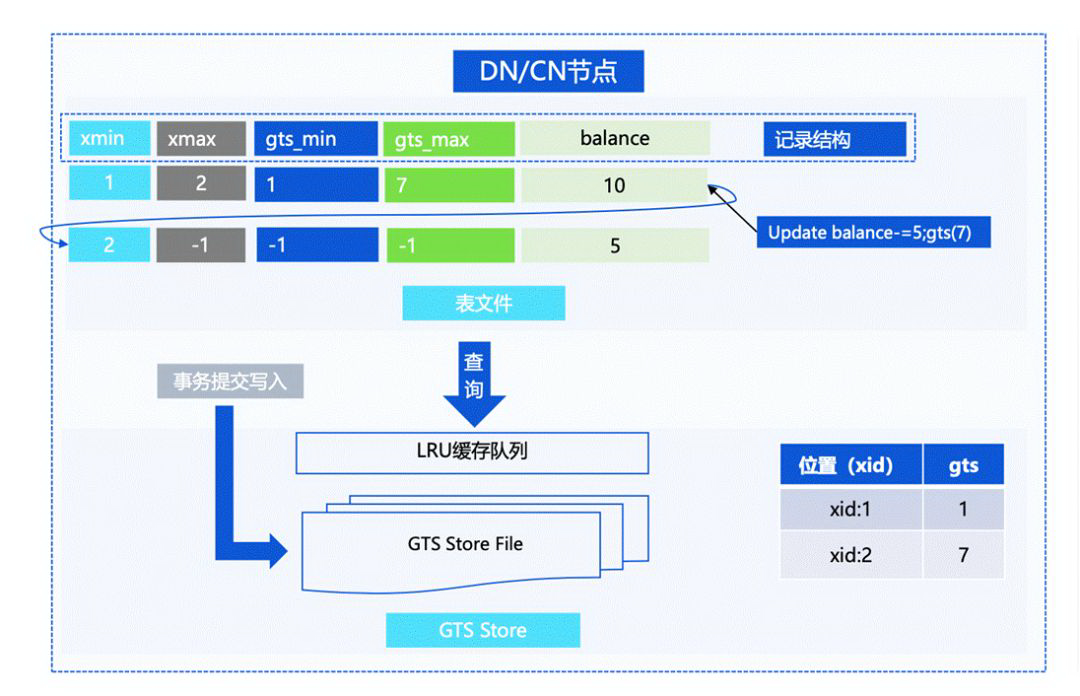
我们刚才也提到,在 Percolator 的实现下,需要对 Tuple 上锁并修改记录,这样的话性能是比较差的。而实际上我们对提交协议做了一个优化,在对 Tuple Header 的 GTS 写入做了延迟处理,事务提交的时候不需要为每一个 Tuple 修改 GTS 信息,而是把 GTS 的信息存储在相应的 GTS Store File 当中,作为事务恢复的保障。
当用户第一次扫描数据的时候,会从 GTS Store File 中取到状态,再写入到 Tuple Header 中,之后的扫描就不需要再去遍历状态文件,从而实现加速访问,做到事务处理的加速。这样在整体上,让数据库在事务层面保证了比较高效的设计。
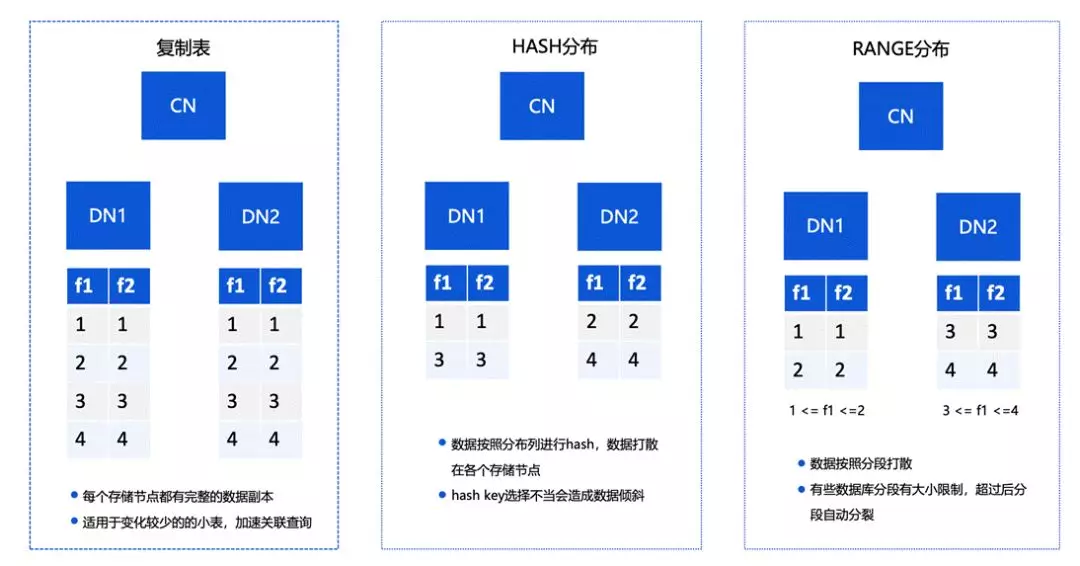
关于集中数据分布的分类情况,有以下三种。
第一种情况是复制表。复制表中的每个存储节点都有完整的数据副本,适用于变化较少的小表,可以加速关联查询。
第二种是 HASH 分布,这是比较经典的一种方式。简单来讲就是将数据按照分布列进行 hash,把数据打散在各个存储节点中,如果 hash key 选择不当,则可能造成数据倾斜的情况。
第三种是基于 RANGE 的分布。RANGE 分布会将数据按照分段打散成小的分片,和 hash 相比分布上不会特别严格,对上层的节点弹性有比较好的支持。但它在计算的时候,相对 hash 的效果不会特别好。
在整体上,TBase 选择的是复制表和增强的 hash 分布。
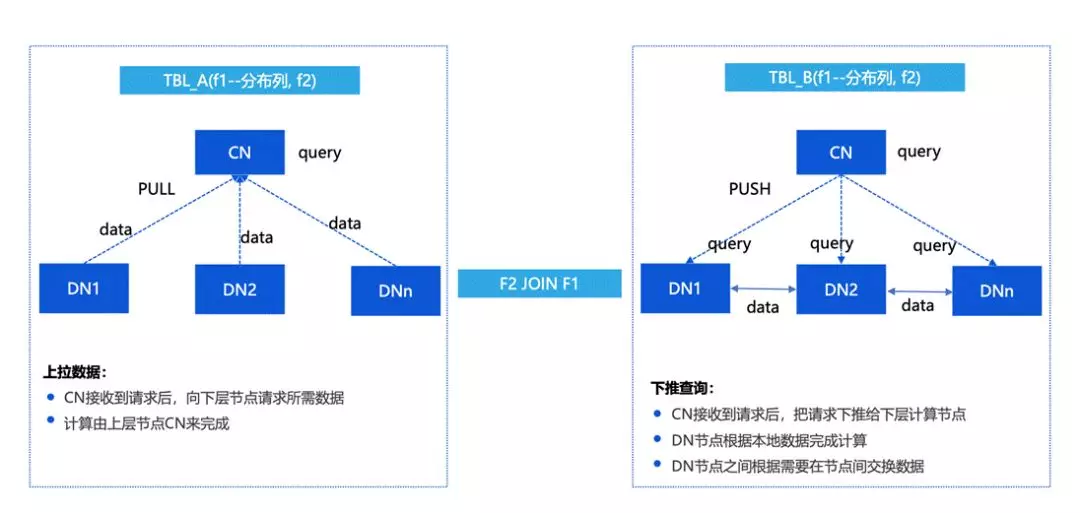
下面介绍一下如何看分布式查询,PushQuery 和 PullData。
最开始早期的一些系统可能会选择更快速的实现,比如说存储上是分成多个 DN,然后把数据拉取到 CN 进行计算。
这种情况下优缺点都比较明显,优点是更高效更快速,缺点是 CN 是一个瓶颈,在网络上压力比较大。所以我们更倾向于上图中右边的方式,把有的数据和计算下放到 DN 结点上。
最基本的情况下,希望所有的计算可以放到 DN 上来进行。DN 在做重分布的时候,需要跟 DN 间有交互的能力,这个在 TBase V2 之后做了比较多的增强,目前 TBase 可以将计算尽量的分散到 DN 结点上来进行。
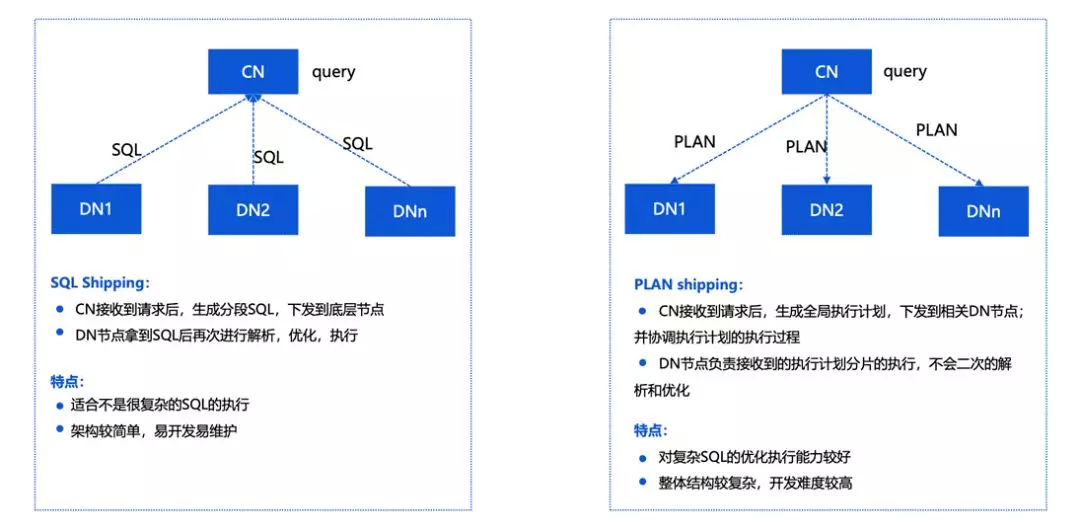
上图介绍的是 SQL Shipping 和 PlanShipping 的区别。
实际上当处理一个 query 或者一个查询计划的时候,会有两种情况。一种是说我直接把 SQL 通过分析发到 DN 上执行,CN 只负责结果的收集。这样的优化效果会比较好,因为不需要在多个节点建立分布式一致性的提交协议,另外在计算资源上效率会更高。我们在 OLTP 领域的一些优化会采用这样的方式。
另一种情况是在 OLAP 领域,更正规的 PLAN 的分布式。在 CN 上对 query 做一个整体的 plan,按照重分布的情况把计划分解成不同的计算分片,分散到 DN 上进行处理
刚才讲到,就是如果能把对 OLTP 推到某单个 DN 上来做的话,效果会比较好。我们举个简单的例子。
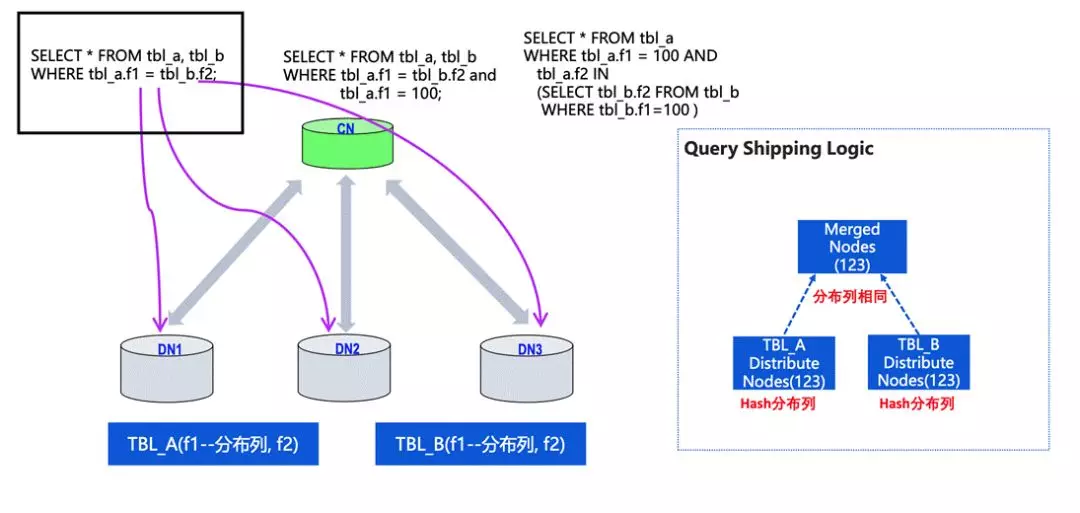
两张表的分布列是 f1,数据列是 f2,若 query 可以写成分布键的关联情况,并且采用的是 hash 分布,就可以把 query 推到不同的 DN 上来做。因为不同 DN 间的数据受到分布件的约束,不需要做交叉计算或者数据的重分布。
第二类是有分布键的等值链接,同时还有某一个分布键的具体固定值。
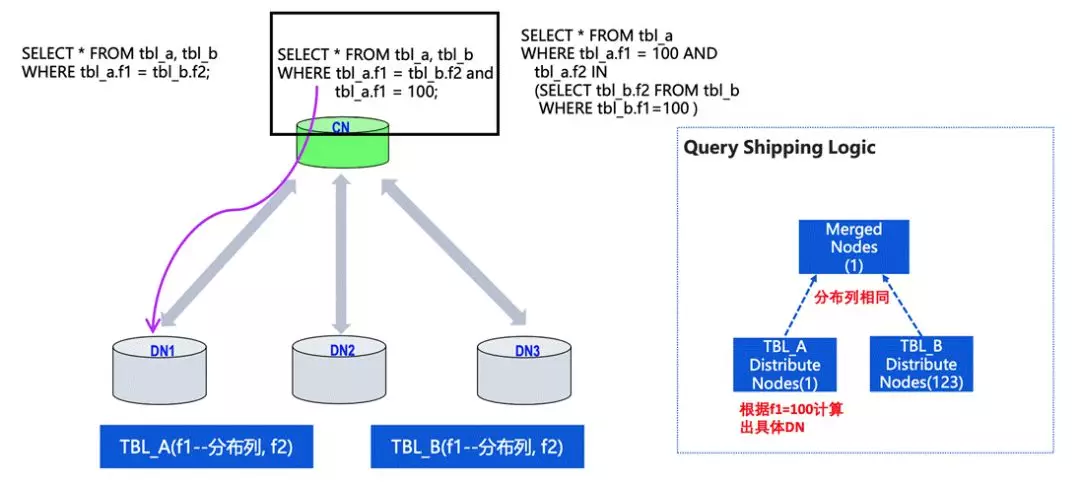
在这种情况下,CN 可以通过 f1 的值判断具体推到哪个 DN 中去做。
还有一些更复杂的查询,比如存在子查询的情况,但方式也是类似的分析方法。
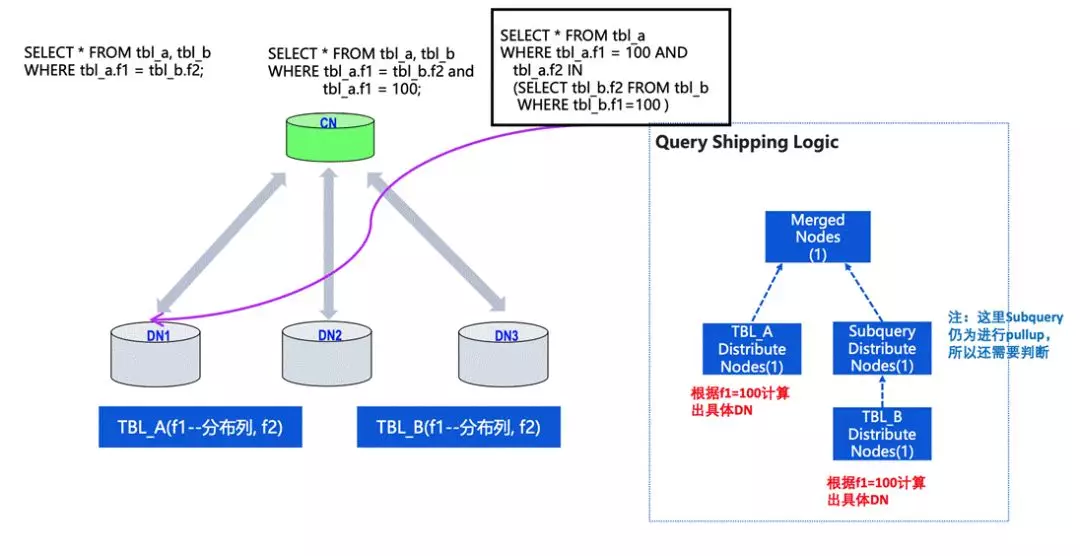
子查询可能会有一个复杂情况,如果在多层的子查询中都可以判断出来跟上层有相同的单一节点分布情况,query 也可以下发到 DN 中。这种情况下对 OLTP 性能会有比较好的影响,集群的能力会得到比较好的优化。
针对比较复杂的 query,可能就需要涉及到优化配置的调整。

方式主要分为两种:规则优化(RBO)和代价优化(CBO)。RBO 主要是通过规则来判断查询计划到底符不符合进行优化,这个是比较早期的一些实现方法,因为计算量相对较小,所以对某些场景比较高效,但明显的缺点是弹性不足,同时不能用于比较复杂的场景。
实际上更多的这种数据库使用的是 CBO 的方式。简单讲,CBO 会对所有路径的进行动态规划,选择成本最小的一条作为执行计划。这种方式的优点是有较好的适用性,能够适合复杂场景的优化,性能表现较稳定。缺点是实现复杂,需要一定的前置条件,包括统计信息、代价计算模型构建等。
但这也是不绝对的,两者没有谁可以“赢”过对方的说法,更多是需要对二者进行一个结合。TBase 主要是在 CBO 上进行优化,比如在计算一些小表的场景中,不需要进行 redistribution,直接 replication 就可以了。
关于分布式中文 distribution 的一些调整的情况,我们还是打个简单的比方。两张表,TBLA 和 TBLB。
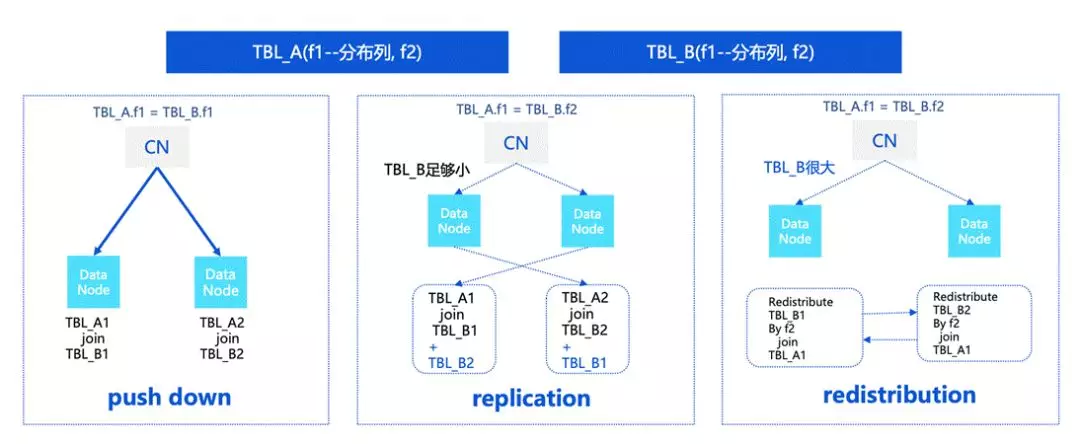
如果 f1 是分布列,分布类等值的情况下会变成 push down,这种情况下可以在 DN 上直接进行计算。
上图中间的情况中,TBLA 是分布键,TBLB 是非分布键。在这种情况下,如果 TBLB 足够小,必须要对 TBLB 进行重分布,也就是对 TBLB 进行 replication,这时就会涉及到一些代价的估算。而如果 TBLB 比较大的话,可能需要对 TBL_B 进行 redistribution。
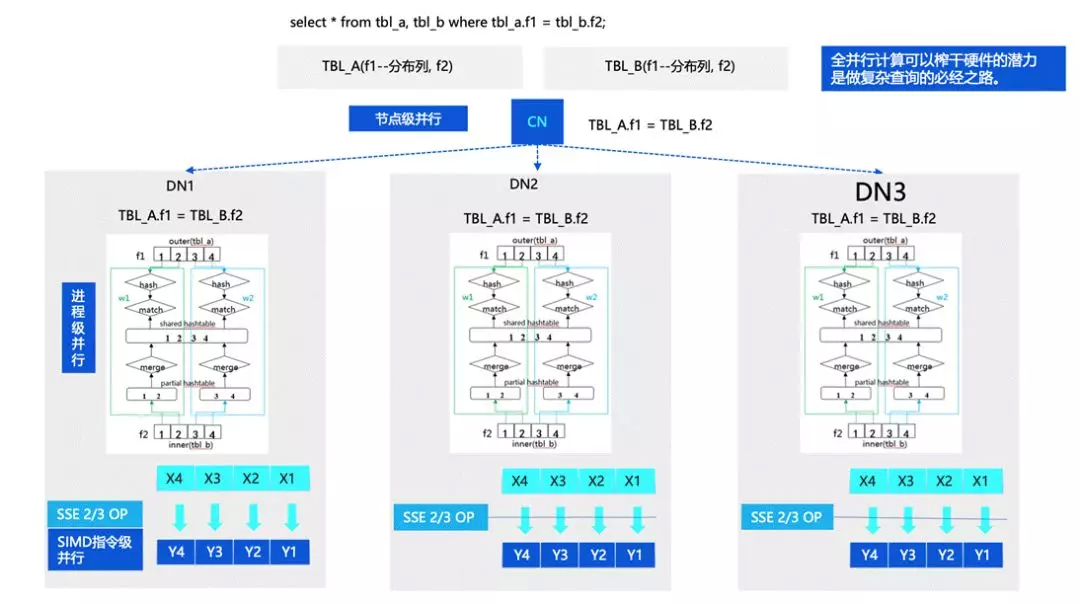
刚才我们也讲到,TBase 在 OLAP 方面也有比较强的能力,这部分的优化思路主要是借助了计算的并行。计算的全并行能力主要体现在几个方面。
首先是节点级的并行,因为我们是分布式的数据库,所以可以有多个节点或者进程进行计算;另外一层是进程级的并行,目前 TBase 没有改成线程模型,所以并行主要体现在进程级模型中,基于 PostgreSQL 进程并行的能力做了一些增强。还有一层是指令集的并行,对指令进行优化,后面也会对这部分进行持续的增强。
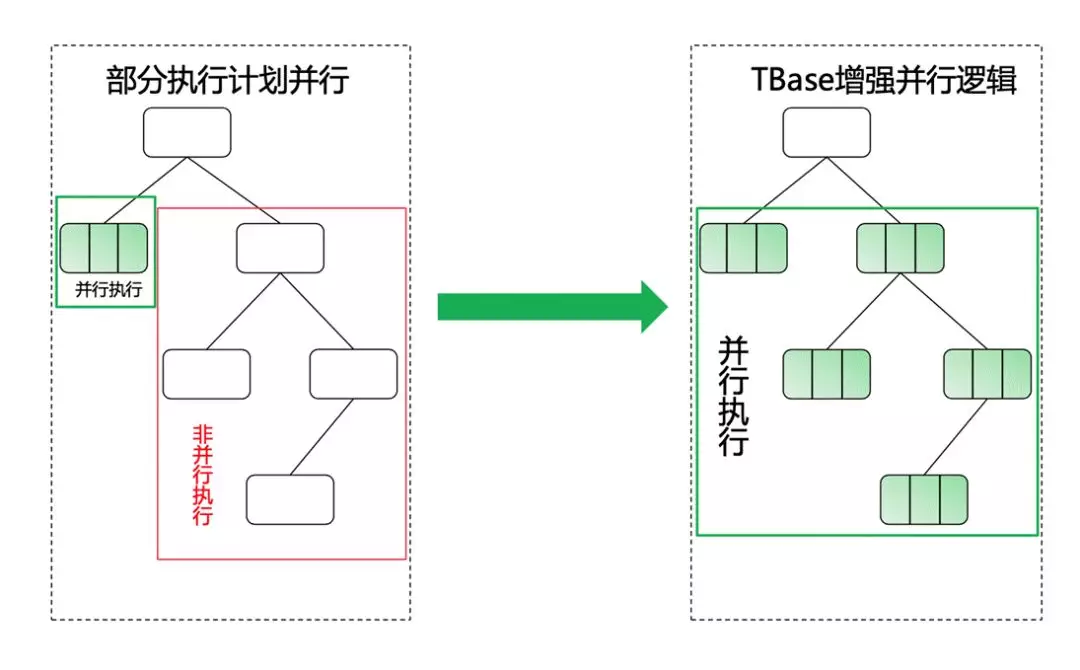
那么 Postgres 的查询计划,或者是进程并行的能力是如何实现的呢?最早期我们 follow 的是 PG10,并行能力并不是非常强,只提供了基础的框架和部分算子的优化,这是 TBase 当时进行优化的一个点。
在分布式的情况下,很多单机可以进行并行,但在分布式中就不可以进行并行,所以我们希望对这些能力进行一些增强,从而保证更大范围的一个并行能力。
并行计算其实是一种自底向上推演的方式,比如说底层的一个节点可以并行,那么如果递推向上到了某一层不能并行,就可以把下面所有可以并行的地方加一个 Gather Node,把结果从多个进程中进行收集,继续向上进行规划。这也是我们希望增强的一个点。
下面我们介绍一些具体的优化。
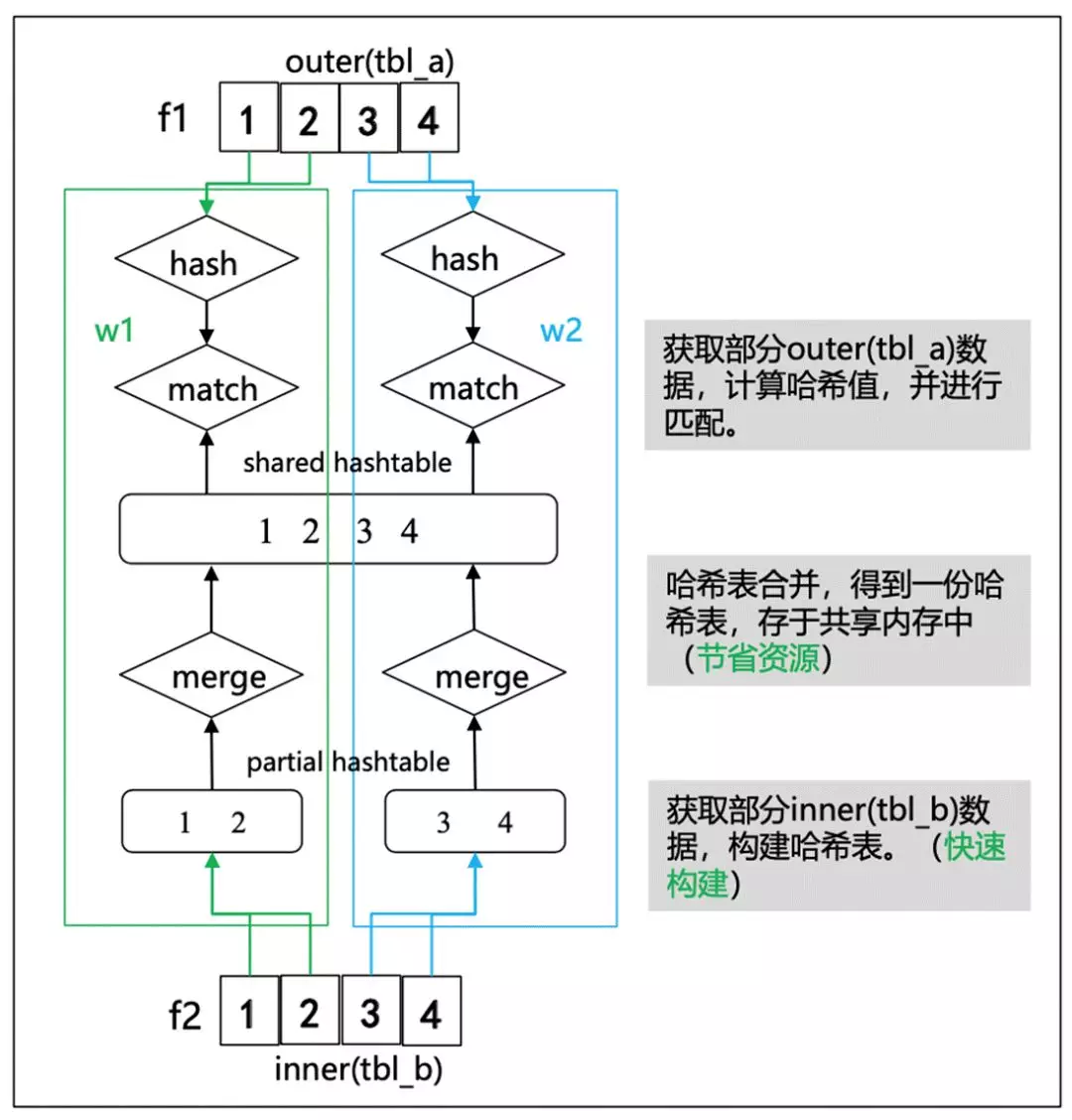
早期 PG 的 HashJoin 在 outer plan 是可以做并行的,但在 inner 构建 hash table 的情况则不能做并行的。
简单来说,hashjoin 可以分为几步。首先是 build hash table,第二步是获取部分 outer plan 数据,计算哈希值,并进行匹配。这里我们将 inner hash table 构建过程也做了并行化处理,保证 Hashjoin 的左右子树都可以进行并行,并继续向上层节点推到并行化。
另外一种情况是 AGG(Aggregation)。
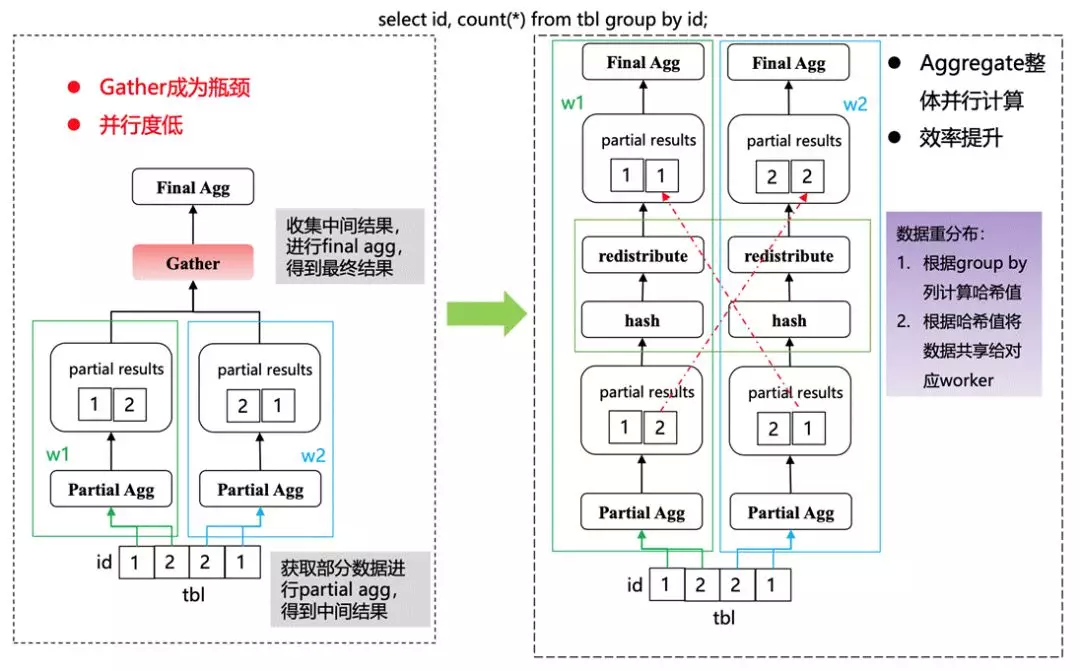
很多情况下都是一个两阶段的 Agg,需要在 DN 上做一些 partial agg,然后到上层计划分片进一步做 final agg。实际上在这种情况下,中间碰到 redistribute 需要先在 DN 进行数据的整合,然后再去做 final 的 Agg。
在有多层子查询的情况下,每一层都进行计算会导致最后整体的并行计算不会很高。所以我们在 redistribution 也做了一些并行,也就是在 Partial Agg 的情况下可以按照 hash 分布去发到对应的上层 DN 节点上进行并行。
还有一些数据传输方面的优化。
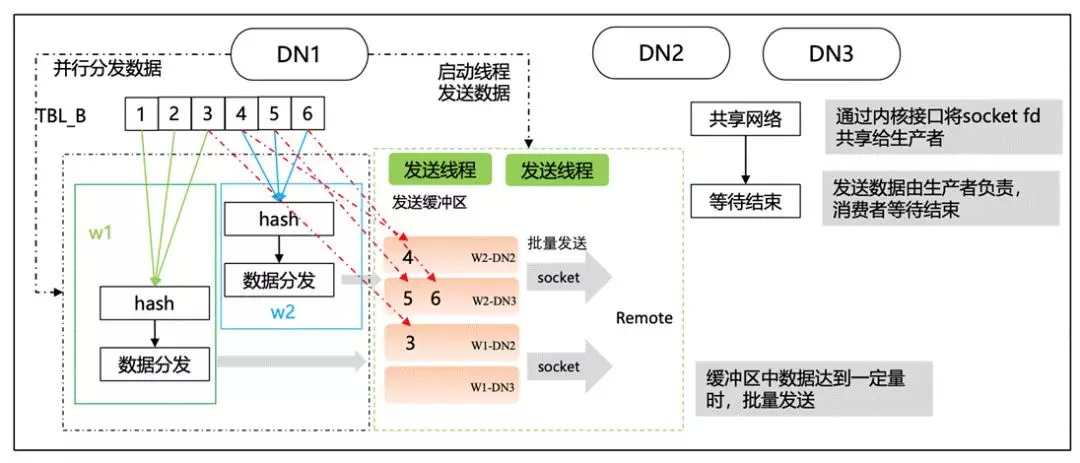
我们提到 redistributio 节点可以进行并行能力的增强,而在数据的接受和发送上也需要进行优化提升。早期的版本是单条的处理模式,网络的延迟会比较高,性能会不太好,所以我们在这部分进行了一些优化,从而实现比较好的并行执行的能力。
四、开源 TBase 企业级能力介绍
实际上 TBase 还做了一些企业级能力的增强,后面也持续的会去做一些开源贡献和优化。

目前开源 Tbase 企业级已经可以实现多地多中心,或者是多活能力的构建,包括安全、管理、审计的能力,TBase 在安全上面有比较高的要求,后面也会持续的贡献出来。
还有就是在水平扩展能力上,TBase 可以做到在用户感知比较小的情况下进行扩容。扩容在大数据量的情况下是一个普遍的痛点,我们在这方面的能力上也会有一个持续的增强。
此外,TBase 还有自研的分析表以及冷热数据的分离,也都是有比较好的效果,对于用户成本的降低,还有数据分布的灵活性都会有比较好的提升。
TBase 在今年 7 月 13 号开源发布了 v2.1.0 版本,我们也持续的在开源能力上做着建设,包括多活能力的持续增强、维护性的增强,性能安全持续的升级,包括通过一些企业客户发现的问题也都会持续的贡献出来。还包括统计信息增强以及增强对小表重分布的优化,也是希望大家可以持续关注 TBase,和我们进行更多的讨论和切磋。
五、Q&A
Q:TBase 的布置有哪些要求?
A: 大家可以访问 TBase 的开源版本,上面有具体的使用方法和基于源码的构建,还有搭建的流程,都有比较明确的文档。如果大家想尝试的话,可以使用正常的 X86 服务器或者本机的 Linux 服务器就可以做一些简单的搭建,企业级项目上大家也可以做一些尝试,保持沟通。
Q:为什么选择基于 PostgreSQL 开发呢?
A:实际上大家会面临 MySQL 和 PostgreSQL 两个方向上的选择,我主要介绍我们选择 PostgreSQL 的原因。
一是 PostgreSQL 的协议会更加友好,在协议的灵活性上会比较好一些,大家可以随意的对它的代码做改动和完整发布。
另外它的内核实现上也比较严谨,有自己的独到之处,持续的也在增强,包括它的迭代速度也是比较快。我们早期一直在跟进,持续的 merge PostgreSQL 的一些 feature,也是伴随着 PostgreSQL 的成长,我们的内核也做了一个比较快速的迭代。同时我们也在了解内核的情况下,做了一些更深入的调优。
Q:DN 节点的存储集群是基于 Raft 吗?多 Leader 还是单 Leader 呢?
A: 目前我们的 DN 结点没有用到 Raft 协议,是做的主备复制。我知道有很多新的业务会基于 Raft 的提交协议,或者是用这种复制的协议去做一致性和高可用。但实际上 Raft 的多副本对提交协议还是有一些性能影响的,整体的流程相对于传统的会有更长的时延,相当于 CAP 原理,C 提高了,A 会有部分影响。
而我们更倾向于 OLTP 系统,所以在事务上的要求和时延响应的要求是比较高的,于是做了这样的选择。
Q:能详细讲讲分布式事务的实现流程吗?怎么样保证多机之间的分布式事务,两阶段提交吗?
A: 现在我们基本是 follw 两阶段提交。一个是两阶段提交的控制流程、控制协议,另一个是事务隔离的协议。刚才主要讲了 MVCC,在提交协议上基本上两阶段提交的增强版。
由于使用了 GTM,导致它和传统的单机模式不太一样,做了一些统一的协调,刚才也着重介绍了。这样的一个优势是减轻了 GTM 上的压力,另外在 prepare 阶段会有部分的阻塞情况,但在优化之后影响是非常小的,却能极大的减轻 GTM 的压力。
Q:底层的存储是怎么同时满足行存和列存的需求呢?还是按照块(Tile)连续存储?
A: 我们开源版本的底层存储主要是行存,后面会在列存和 HTAP 进行持续的增强,进一步提升 HTAP 的能力。等逐步稳定之后,会再考虑迭代开源版本。
Q:最少需要多少服务器搭建?
A: 其实单点搭建也是可以的。一个 DN、一个 CN、一个 GTM 也可以。实际上最好布成两 DN,可以体验更多的分布式搭建。实际上我们在企业服务的集群上已经超过了上千个节点,包括解决 GTM 的单点压力上,对集群整体的扩展性有比较好的提升,所以从两个节点到多节点都可以去尝试一下。
Q:GTM 的授时,有采用 batch 或者 pipeline 吗?还有现在 Tbase 支持的从库的读一致性吗?
A: 有的。GTM 的授时我们也做了更多的优化,简单说可以做一些并行的 GTS 的单调授时,根据现行的规模或者是我们对客户场景的预估,在 x86 服务器中大概可以达到 1200 万 QPS 的授时的能力。在增强服务器的情况下,整体的能力是比较强的,基本上不会在这部分产生瓶颈。
Q:tbase 有什么安全保障机制?
A: 从业务角度,我们讲到了安全隔离,以及有很强的行级安全规则、列级访问控制以及数据加密、脱敏增强,这些都可以倾向于向一个企业级的数据库去应用,现在很多企业级服务的能力也在 TBase 里面,后面我们会根据情况进行进一步的迭代。
作者介绍:
伍鑫,腾讯 TBase 专家工程师
伍鑫,腾讯 TBase 数据库专家工程师。在数据库、数据复制、大数据计算等领域有丰富经验,曾发表多篇相关论文、专利。加入腾讯前曾在 IBM 大数据分析团队工作多年,后加入 Hashdata 数据库创业公司。加入腾讯后,负责 TBase 数据库优化器、执行器、分布式事务等多项核心功能研发。
本文转载自公众号云加社区(ID:QcloudCommunity)。
原文链接:




