5 月 5 日,阿里巴巴达摩院发布新型联邦学习框架FederatedScope,该框架支持大规模、高效率的联邦学习异步训练,能兼容不同设备运行环境,且提供丰富功能模块,大幅降低了隐私保护计算技术开发与部署难度,该框架现已面向全球开发者开源。
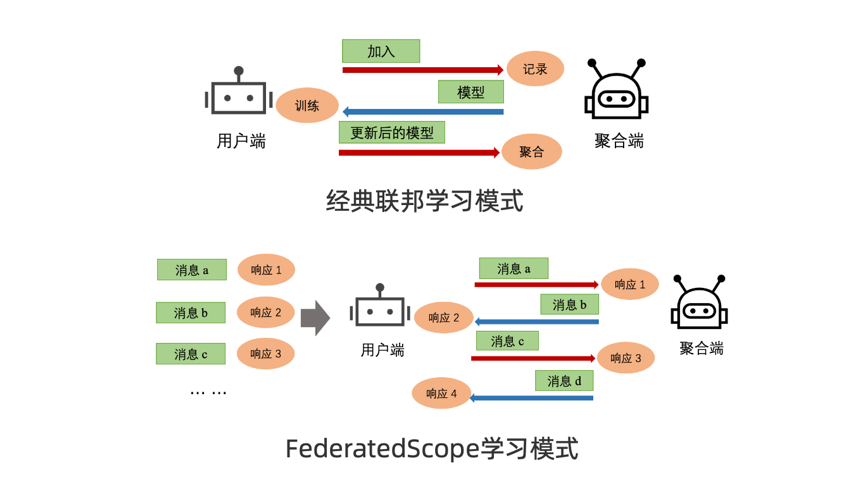
隐私保护是数字经济的安全底座,如何在保障用户数据隐私的同时提供高质量连通服务,成为数字经济时代的重要技术课题。为破解隐私保护与数据应用的两难,以“数据不动模型动”为理念的联邦学习框架应运而生,其通过用户数据不出本地的方式完成云端模型训练,实现了“数据可用不可见”。近年来,联邦学习成为隐私保护计算主流技术之一。
然而,随着需应用隐私保护计算的场景和行业日趋多元,涉及到的数据类型日趋丰富,已有联邦学习框架难以灵活高效地满足现实中越来越复杂的计算需要,需从注重“可用”到注重“好用”。
为解决上述挑战,达摩院智能计算实验室研发了新型联邦学习框架 FederatedScope,该框架使用事件驱动的编程范式来构建联邦学习,即将联邦学习看成是参与方之间收发消息的过程,通过定义消息类型以及处理消息的行为来描述联邦学习过程。通过这一方式,FederatedScope 实现了支持在丰富应用场景中进行大规模、高效率的联邦学习异步训练。
同时,达摩院团队对 FederatedScope 训练模块进行抽象,使其不依赖特定的深度学习后端,能兼容 PyTorch、Tensorflow 等不同设备运行环境,大幅降低了联邦学习在科研与实际应用中的开发难度和成本。
为进一步适应不同应用场景,FederatedScope 还集成了多种功能模块,包括自动调参、隐私保护、性能监控、端模型个性化等。FederatedScope 支持开发者通过配置文件便捷地调用集成模块,方便快速入门;也允许通过注册的方式添加新的算法实现并调用,支持定制化及深度开发。
达摩院智能计算实验室隐私保护计算团队负责人丁博麟表示,“数据已成为重要的生产要素,而隐私保护计算是保障这一要素发挥作用的关键技术。通过开源最新联邦学习框架,我们希望促进隐私保护计算在研究和生产中的广泛应用,让医药研发、政务互通、人机交互等数据密集领域更安全、更顺畅地发展。”
快速运行
如果对该框架感兴趣,可以通过以下方法快速运行,更多详细介绍请访问项目官网。
安装
首先,用户需要克隆源代码并安装所需的包(建议 python 版本> = 3.9)。
git clone https://github.com/alibaba/FederatedScope.gitcd FederatedScope
复制代码
可以从需求文件安装依赖项:
# For minimal versionconda install --file enviroment/requirements-torch1.10.txt -c pytorch -c conda-forge -c nvidia
# For application versionconda install --file enviroment/requirements-torch1.10-application.txt -c pytorch -c conda-forge -c nvidia -c pyg
复制代码
或构建 docker 映像并使用 docker env 运行:
docker build -f enviroment/docker_files/federatedscope-torch1.10.Dockerfile -t alibaba/federatedscope:base-env-torch1.10 .docker run --gpus device=all --rm --it --name "fedscope" -w $(pwd) alibaba/federatedscope:base-env-torch1.10 /bin/bash"
复制代码
注意:如果需要运行 graph FL 等下游任务,在执行上述命令时,需要修改 requirements/docker 文件名:
# enviroment/requirements-torch1.10.txt -> requirements-torch1.10-application.txt
# enviroment/docker_files/federatedscope-torch1.10.Dockerfile ->enviroment/docker_files/federatedscope-torch1.10-application.Dockerfile
复制代码
最后,在安装完所有依赖项后,运行:
准备数据集和模型
要运行 FL 课程,首先应该为 FL 准备数据集。FederatedScope 中提供的 DataZoo 可以帮助从各种 FL 应用程序中自动下载和预处理广泛使用的公共数据集,包括计算机视觉、自然语言处理、图学习、推荐等。用户可以通过cfg.data.type = DATASET_NAME配置在指定数据集上运行。同时,用户也可以采用自定义数据集,提供的数据集请参考DataZoo ,FederatedScope 中引入自定义数据集请参考Customized Datasets。
其次,应该指定将接受联邦训练的模型架构,例如 ConvNet 或 LSTM。FederatedScope 提供了 ModelZoo,其中包含用于各种 FL 应用程序的广泛使用的模型架构的实现。用户可以设置cfg.model.type = MODEL_NAME在 FL 任务中应用特定的模型架构。我们允许用户通过注册来使用定制模型,而无需关心联合过程,可以参考ModelZoo了解有关如何自定义模型的更多详细信息。
对于普通 FL 课程,所有参与者共享相同的模型架构和训练配置。并且 FederatedScope 还支持采用客户特定的模型和训练配置(称为个性化 FL)来处理实际 FL 应用中的非 IID 问题,请参阅个性化 FL了解更多详情。
使用配置运行 FL 项目
请注意,FederatedScope 为独立模拟和分布式部署提供了统一的视图,因此用户可以通过配置轻松地以独立模式或分布式模式运行 FL 课程。
独立模式
FederatedScope 中的独立模式意味着在单个设备中模拟多个参与者(服务器和客户端),而参与者的数据彼此隔离,并且他们的模型可以通过消息传递共享。
这里演示了如何使用 FederatedScope 运行 vanilla FL ,并设置cfg.data.type = 'FEMNIST'和cfg.model.type = 'ConvNet2'运行 vanilla FedAvg [1] 以完成图像分类任务。用户可以在配置(一个 .yaml 文件)中包含更多的训练配置,例如cfg.federated.total_round_num,cfg.data.batch_size和cfg.optimizer.lr, 并运行 vanilla FL 项目:
# Run with default configurationspython federatedscope/main.py --cfg federatedscope/example_configs/femnist.yaml# Or with custom configurationspython federatedscope/main.py --cfg federatedscope/example_configs/femnist.yaml federated.total_round_num 50 data.batch_size 128
复制代码
用户可以在训练过程中观察一些监控指标:
INFO: Server #0 has been set up ...INFO: Model meta-info: <class 'federatedscope.cv.model.cnn.ConvNet2'>.... ...INFO: Client has been set up ...INFO: Model meta-info: <class 'federatedscope.cv.model.cnn.ConvNet2'>.... ...INFO: {'Role': 'Client #5', 'Round': 0, 'Results_raw': {'train_loss': 207.6341676712036, 'train_acc': 0.02, 'train_total': 50, 'train_loss_regular': 0.0, 'train_avg_loss': 4.152683353424072}}INFO: {'Role': 'Client #1', 'Round': 0, 'Results_raw': {'train_loss': 209.0940284729004, 'train_acc': 0.02, 'train_total': 50, 'train_loss_regular': 0.0, 'train_avg_loss': 4.1818805694580075}}INFO: {'Role': 'Client #8', 'Round': 0, 'Results_raw': {'train_loss': 202.24929332733154, 'train_acc': 0.04, 'train_total': 50, 'train_loss_regular': 0.0, 'train_avg_loss': 4.0449858665466305}}INFO: {'Role': 'Client #6', 'Round': 0, 'Results_raw': {'train_loss': 209.43883895874023, 'train_acc': 0.06, 'train_total': 50, 'train_loss_regular': 0.0, 'train_avg_loss': 4.1887767791748045}}INFO: {'Role': 'Client #9', 'Round': 0, 'Results_raw': {'train_loss': 208.83140087127686, 'train_acc': 0.0, 'train_total': 50, 'train_loss_regular': 0.0, 'train_avg_loss': 4.1766280174255375}}INFO: ----------- Starting a new training round (Round #1) -------------... ...INFO: Server #0: Training is finished! Starting evaluation.INFO: Client #1: (Evaluation (test set) at Round #20) test_loss is 163.029045... ...INFO: Server #0: Final evaluation is finished! Starting merging results.... ...
复制代码
分布式模式
FederatedScope 中的分布式模式表示运行多个程序来构建 FL 项目,其中每个程序都充当参与者(服务器或客户端),实例化其模型并加载其数据。参与者之间的通信已经由 FederatedScope 的通信模块提供。
要以分布式模式运行,只需:
准备隔离数据文件并cfg.distribute.data_file = PATH/TO/DATA为每个参与者设置;
更改cfg.federate.model = 'distributed',并指定每个参与者的角色cfg.distributed.role = 'server'/'client'。
cfg.distribute.host = x.x.x.x通过和设置有效地址cfg.distribute.port = xxxx。(注意,服务器需要设置 server_host/server_port 监听消息,客户端需要设置 client_host/client_port 监听和 server_host/server_port 在搭建 FL 项目时发送加入申请)
我们准备了一个在分布式模式下运行的综合示例:
# For serverpython main.py --cfg federatedscope/example_configs/distributed_server.yaml data_path 'PATH/TO/DATA' distribute.server_host x.x.x.x distribute.server_port xxxx
# For clientspython main.py --cfg federatedscope/example_configs/distributed_client_1.yaml data_path 'PATH/TO/DATA' distribute.server_host x.x.x.x distribute.server_port xxxx distribute.client_host x.x.x.x distribute.client_port xxxxpython main.py --cfg federatedscope/example_configs/distributed_client_2.yaml data_path 'PATH/TO/DATA' distribute.server_host x.x.x.x distribute.server_port xxxx distribute.client_host x.x.x.x distribute.client_port xxxx
复制代码
可以观察到结果(IP 地址用“xxxx”匿名):
INFO: Server #0: Listen to x.x.x.x:xxxx...INFO: Server #0 has been set up ...Model meta-info: <class 'federatedscope.core.lr.LogisticRegression'>.... ...INFO: Client: Listen to x.x.x.x:xxxx...INFO: Client (address x.x.x.x:xxxx) has been set up ...Client (address x.x.x.x:xxxx) is assigned with #1.INFO: Model meta-info: <class 'federatedscope.core.lr.LogisticRegression'>.... ...{'Role': 'Client #2', 'Round': 0, 'Results_raw': {'train_avg_loss': 5.215108394622803, 'train_loss': 333.7669372558594, 'train_total': 64}}{'Role': 'Client #1', 'Round': 0, 'Results_raw': {'train_total': 64, 'train_loss': 290.9668884277344, 'train_avg_loss': 4.54635763168335}}----------- Starting a new training round (Round #1) -------------... ...INFO: Server #0: Training is finished! Starting evaluation.INFO: Client #1: (Evaluation (test set) at Round #20) test_loss is 30.387419... ...INFO: Server #0: Final evaluation is finished! Starting merging results.... ...
复制代码
项目官网: https://federatedscope.io/
源代码地址: https://github.com/alibaba/FederatedScope

















评论