

后期修图在整个商业摄影工作流程中占主要比重,具有工作量大、周期长的特点。在拍摄旺季或拍摄任务多的情况下,从拍摄获取原片到拿到最终成片的整个周期长达一个月左右。
同时,培养一名合格的修图师往往需要付出高昂的人力和物力成本,即便是熟练的修图师也需要 1-3 个月的时间熟悉和适应不同影楼的修图风格和手法。但修图师的专业水平不同,审美差异、工作状态好坏等因素都会造成修图质量波动。除此之外,修图师流动率逐年上升的趋势也成为商业摄影行业一大难题。
为解决商业摄影上述痛点,基于美图成立 12 年来在人物影像领域积累的技术优势,美图技术中枢——美图影像实验室(MTlab)推出美图云修人工智能修图解决方案,大大提升了商业摄影的后期效率。修图过程中,AI 技术在实现多场景的自适应识别调参,呈现完美光影效果的同时,还能够快速定位人像,修复人像瑕疵,实现人像的个性化修图。本文将重点分析美图云修人工智能修图解决方案的技术细节。

图 1. 美图云修人像精修对比
智能中性灰技术
在修图中经常提到中性灰修图,也称“加深减淡”操作,通过画笔来改变局部的深浅,在 PS 中需要手动建立一个观察图层,用以凸显脸部瑕疵,如斑点、毛孔、痘印等,然后在观察图层中逐一选取瑕疵区域对原人脸对应瑕疵区域进行祛除,在此之后对肤色不均匀的地方抹匀,最大限度地保留皮肤质感,但不少情况下仍需借助磨皮方法让肤色均匀,但磨皮会丢失皮肤质感。对每张人像图的皮肤区域重复该过程,可谓耗时耗力。传统 PS 中性灰的修图过程如图 2 所示。

图 2. PS 中性灰修图图层(左:原图,中:观察组,右:图层)
美图云修的智能中性灰人像精修功能,结合自注意力模块和多尺度特征聚合训练神经网络,进行极致特征细节提取,智能中性灰精修方案使没有专业修图技术的人也可以对人像进行快速精修,在速度方面远超人工修图方式,并且保持了资深人工修图在效果上自然、精细的优点,在各种复杂场景都有较强的鲁棒性,极大地提升了人像后期处理的工作效率。如图 3 所示,为智能中性灰修图效果,无需手动操作,相比于目前各个 app 上的修图效果,如图 4 所示,有着更好的祛除瑕疵效果,并保留皮肤质感,不会有假面磨皮感。
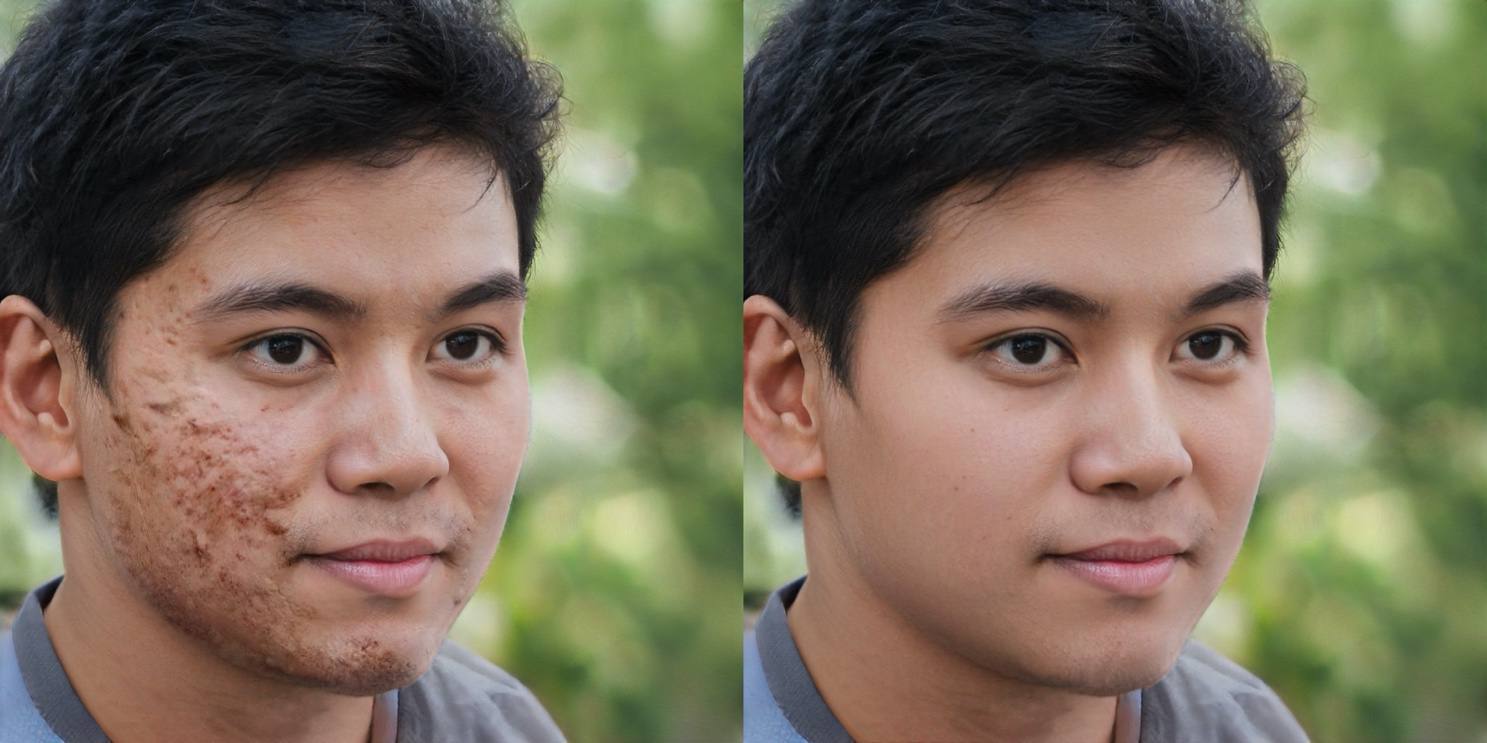
图 3. 美图云修 AI 中性灰精修效果对比

图 4. 友商祛斑祛痘及磨皮效果(左:祛斑祛痘,右:磨皮)
AI 中性灰精修功能采用创新的深度学习结构,如图 5 所示,在网络编码器到解码器的连接部分加入双重自注意力特征筛选模块和多尺度特征聚合模块,让网络可以学习丰富的多尺度上下文特征信息,并对重要信息附加权重,让图像在高分辨率的细节得以保留,同时更好地修复问题肤质。
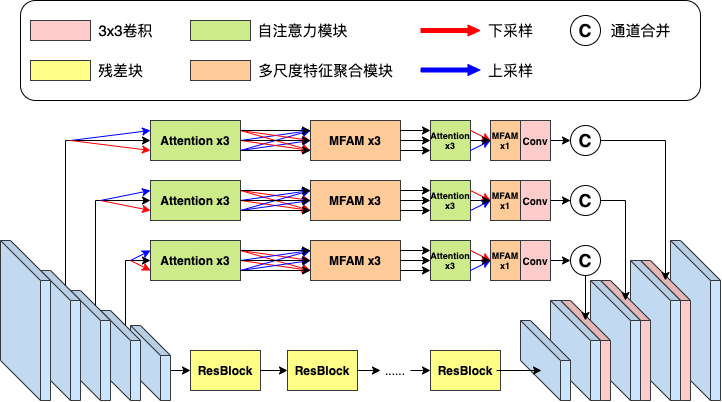
图 5. 智能中性灰精修网络结构
双重自注意力特征筛选模块:
双重自注意力特征筛选模块[1]是对特征图的空间映射和通道映射进行学习,分为基于位置的自注意力模块和基于通道的自注意力模块,最后通过整合两个模块的输出来得到更好的特征表达,如图 6 所示。
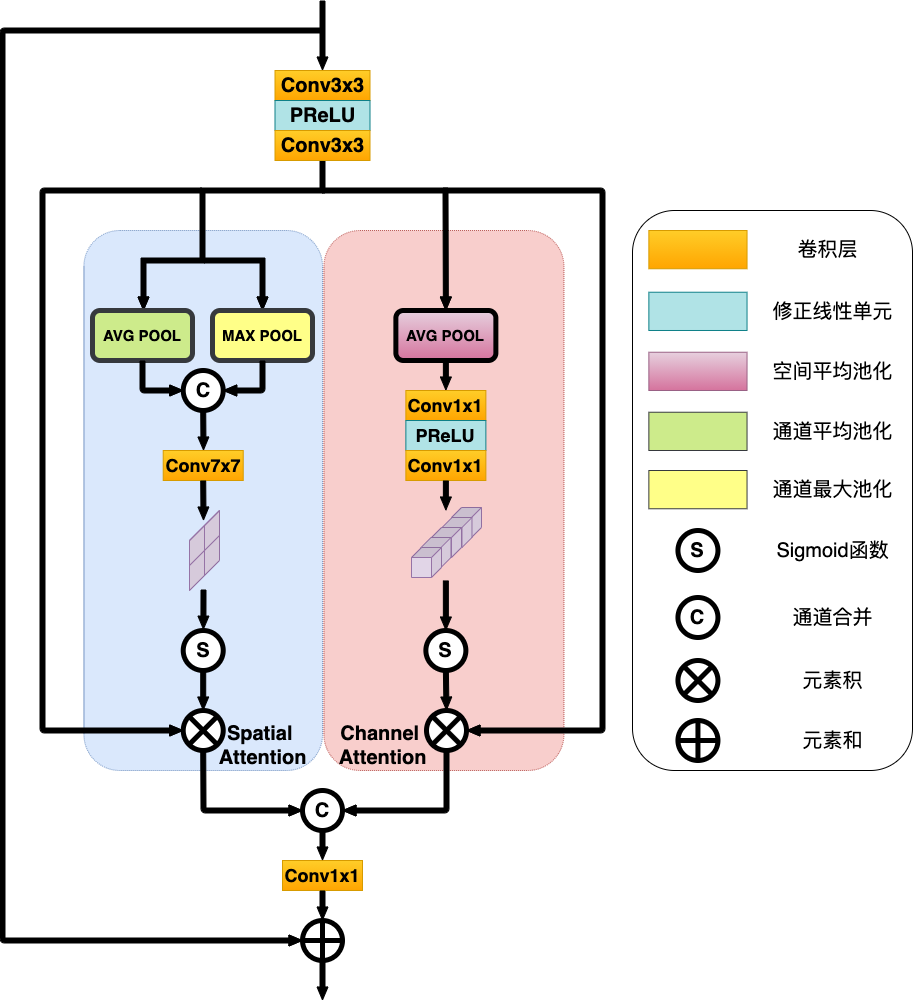
图 6. 双重自注意力模块结构
基于位置的自注意力模块用于获悉特征图中的任意两个像素的空间依赖,对于某个特殊的肤质特征,会被所有位置上的特征加权,并随着网络训练而更新权重。任意两个具有相似肤质特征的位置可以相互贡献权重,由此模块通过学习能够筛选出肤质细节变化的位置特征。如图 6 左边蓝色区域所示,输入一个特征图,首先对该特征图分别沿通道维度进行全局平均池化和全局最大池化,得到两个基于通道的描述并合并得到特征图 。再经过一个 7x7 的卷积层和 Sigmoid 激活函数,得到空间权重系数 ,可以由以下公式表示:
其中σ表示 Sigmoid 激活函数, 表示 7x7 卷积, 表示通道合并。
最后,将空间权重系数对特征图进行重新校准,即两者相乘,就可以得到空间加权后的新肤质特征图。
基于通道的自注意力模块主要关注什么样的通道特征是有意义的,并把那些比较有意义的特征图通道通过加权进行突出体现。高层特征的通道都可以看作是特定于肤质细节信息的响应,通过学习通道之间的相互依赖关系,可以强调相互依赖的特征映射,从而丰富特定语义的特征表示。如图 6 右边红色区域所示,输入与基于位置的肤质细节筛选模块相同的特征图,对该特征图沿空间维度进行全局平均池化,得到给予空间的描述特征图,再把输入由两个 1x1 卷积层组成表示的多层感知机。为了减少参数开销,感知机隐层激活的尺寸设置为 ,其中是通道降比。这样第一层卷积层输出通道为,激活函数为 PReLU,第二层卷积层输出通道恢复为 C。再经过 Sigmoid 激活函数,得到通道权重系数 ,由以下公式表示:
其中σ表示 Sigmoid 激活函数, 和表示感知机对应的两层, 表示感知机中间的线性修正单元激活函数。
相同地,将通道权重系数和特征图相乘,就可以得到通道加权后的新特征图。将空间加权特征图和通道加权特征图进行通道合并,经过一个 1x1 卷积后与输入自注意力模块前的特征图相加,就可以得到矫正后的最终特征图。
多尺度特征聚合模块:
多尺度特征聚合模块[2]的作用是对特征感受野进行动态修正,不同尺度的前后层特征图输入模块,通过整合并赋予各自的权重,最终将这些特征进行聚合,输出更为丰富的全局特征,这些特征带有来自多个尺度的上下文信息。
如图 7 所示,以三个不同尺度输入模块为例,模块先使用 1x1 卷积和 PReLU 将上层和下层的特征通道变换为和当前层一致,再通过元素和的方式将特征聚合成,然后经过一个空间维度的全局平均池化得到基于通道的统计,之后为了降低计算量经过一个的 1x1 卷积和 PReLU 激活函数,生成一个压缩的特征表示,与自注意力特征筛选模块一致。这里让经过与尺度数量相同的平行卷积层,得到对应的特征描述向量 、和, 。将这些特征描述向量合并,再经过 Softmax 激活函数,得到各个尺度特征通道的校正系数、和, 。将特征通道系数与对应尺度的特征图相乘后再进行聚合相加,得到最终的聚合特征 ,表示为:
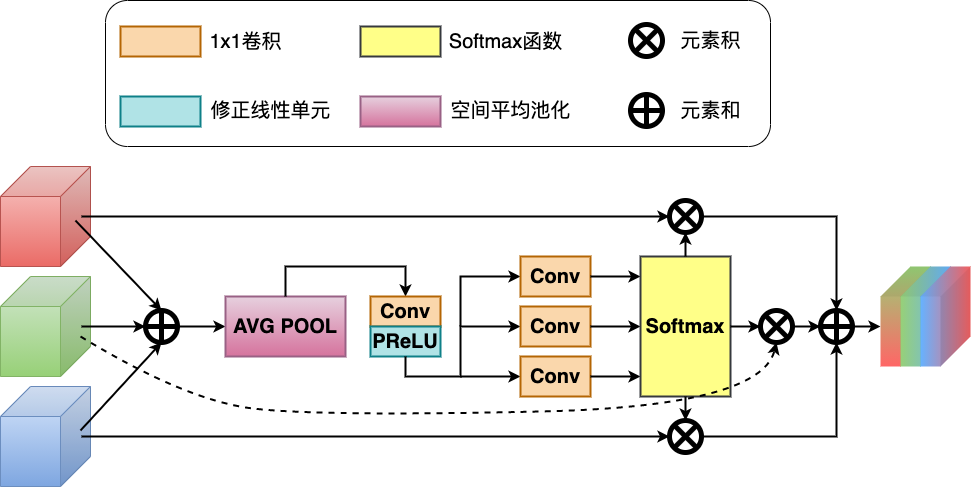
图 7. 多尺度特征聚合模块结构
MTlab 所提出的 AI 中性灰精修方案通过设计有效的网络结构以及流程,结合特殊的训练方法,能够便捷、精确地进行智能中性灰人像修图。首先,相较于磨皮等传统图像处理方法,本方案输出的智能修图结果精细、自然,能够最大程度地保留人像肤质细节,对于各类复杂场景都具有更好的鲁棒性;其次,相较于人工中性灰修图,本方法能够保证稳定的修图效果,同时极大缩短处理时间,从而提升影楼图像后期处理的效率。
智能调色技术
常见修图所涉及的调色技术主要包括去雾,光照调整和背景增强等,其中光照调整涉及过曝修复和欠曝增强。其中,去雾主要用于保持图像的清晰度和对比度,使图像从视觉感观上不会存在明显雾感;曝光主要用于改善图像的光影效果,保证成像光影质量,使得相片能够呈现完美光影效果;而智能白平衡则是能够还原图像的真实色彩,保证图像最终成像不受复杂光源影响。调色涉及的技术较多,后续以白平衡智能调整技术为例,详细介绍 AI 技术调色流程。
白平衡是还原物体固有色的一种方式,能够实现摄像机图像能精确反映被摄物的色彩状况。它在众多应用场景中具有很大的商业价值,例如移动设备获取设备的前置处理以及影楼后期的修图处理,白平衡都是获得优质图像的必要环节。许多人在使用数码摄像机拍摄的时候都会遇到这样的问题:在日光灯的房间里拍摄的影像会显得发绿,在室内钨丝灯光下拍摄出来的景物就会偏黄,而在日光阴影处拍摄到的照片则莫名其妙地偏蓝,其原因就在于白平衡的设置上。白平衡要做的,就是在不同的光线条件下,根据当时得到的物体颜色,尽量恢复物体的固有色,或者说,尽量减小光源颜色对物体颜色的影响。我们可以在色彩转换的过程中根据光源的情况指定不同的白点,从而得到相应正确的色彩转换结果。
目前常用白平衡算法进行色偏校正,存在以下难点:
(1)传统白平衡算法虽然能够校正色偏,但是鲁棒性不足,无法应对实际需求中的复杂场景,往往需要设置不同的参数进行调整,操作繁琐。
(2)目前主流的色偏校正方案大多数是基于卷积神经网络,而常规的卷积神经网络结构并不能彻底校正色偏,这些方案对于与低色温光源相近的颜色,比如木头的颜色,会存在将其误判为低色温光源的现象。
(3)大多数数码相机提供了在图像菜鸡过程中调整白平衡设置的选项。但是,一旦选择了白平衡设置并且 ISP 将图像完全处理为最终的 sRGB 编码,就很难在不访问 RAW 图像的情况下执行 WB 编辑,如果白平衡设置错误,此问题将变得更加困难,从而导致最终 sRGB 图像中出现强烈的偏色。
鉴于传统白平衡算法的不足,以及当前市场上影楼用户对于只能修图智能调色的迫切需求,美图影像实验室 MTlab 自主研发了一套专门能够适应多场景复杂光源下的智能调色技术。传统白平衡算法的核心就是通过实时统计信息,比照传感器的先验信息,计算出当前场景的光源,通过传感器先验信息做白平衡。这种方法仍然有很多局限。MTlab 提出的智能白平衡方案(AWBGAN),依靠海量场景的无色偏真实数据,能够实现自适应的光源估计,完成端到端的一站式调色服务。AWBGAN 满足以下 2 个特点:
(1)全面性:多场景多光源,涵盖常见场景进行多样化处理
(2)鲁棒性:不会存在场景以及光源误判问题,色偏校正后不会造成二次色偏
当前的主流算法主要是集中在 sRGB 颜色域上进行色偏校正,但是这样处理并不合理。因为相机传感器在获取原始的 RAW 图像再到最终输出 sRGB 图像,中间经过一系列的线性以及非线性映射处理,例如曝光校正,白平衡以及去噪等处理流程。ISP 渲染从白平衡过程开始,该过程用于消除场景照明的偏色。然后,ISP 进行了一系列的非线性颜色处理,以增强最终 sRGB 图像的视觉质量。由于 ISP 的非线性渲染,使用不正确的白平衡渲染的 sRGB 图像无法轻松校正。为此 MTlab 设计了 AWBGAN 训练学习网络来完成色偏校正。
针对一张待校正色偏的图像,首先需要使用已经训练好的场景分类模型进行场景判定,获得校正系数,该校正系数将会用于 AWBGAN 的校正结果,能在校正结果的基础上进行动态调整。对于高分辨率图像如果直接进行色偏校正处理,耗时高。为了提高计算效率,MTlab 会将待校正色偏图像采样到一定尺度再进行校正操作,最后再将结果使用金字塔操作逆向回原图尺寸。完整的校正流程如图 8 所示。
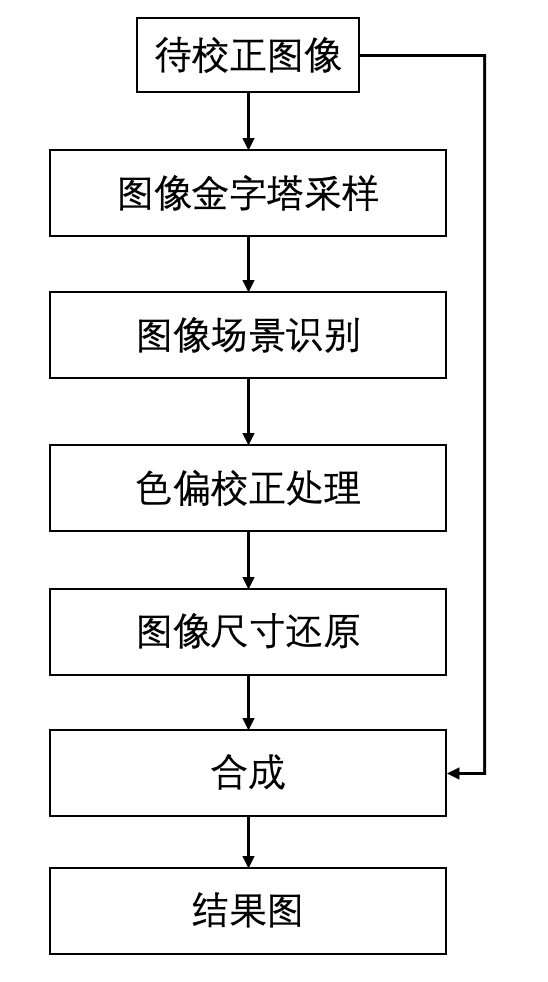
图 8. 色偏校正方案整体流程
生成网络的设计:
上文中提到在 sRGB 图像上直接进行处理并没有在 Raw 图上处理效果好,因此生成器采用类 U-Net 网络结构模拟 sRGB 到 RAW 再转换回 sRGB 的非线性映射过程,其中编码器将 sRGB 逆向还原回 RAW 图并进行 RAW 图上的色偏校正,在完成正确的白平衡设置后,解码器进行解码,生成使用了正确白平衡设置的 sRGB 图像。整个 G 网络的目的不是将图像重新渲染会原始的 sRGB 图,而是在 RAW 上使用正确的白平衡设置生成无色偏图像。鉴于直接使用原始的 U-Net 网络生成的图像会存在色彩不均匀的问题,G 网络参考 U-Net 以及自主研发的方案做了一些调整:
(1)在编码器与解码器之间加入另外一个分支,使用均值池化代替全连接网络提取图像的全局特征从而解决生成图像存在色块和颜色过度不均匀的问题;
(2)使用 range scaling layer 代替 residuals,也就是逐个元素相乘,而不是相加,学习范围缩放层(而不是残差)对于感知图像增强效果非常好;
(3)为了减少生成图像的棋盘格伪影,将解码器中的反卷积层替换为一个双线性上采样层和一个卷积层。
生成网络结构如图 9 所示,提取全局特征的网络分支具体结构如图 10 所示。
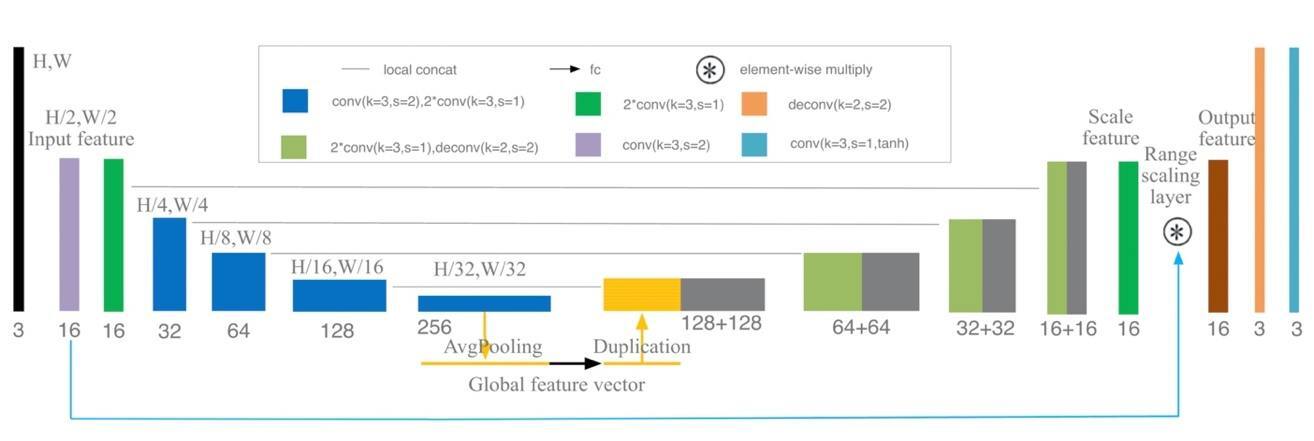
图 9. 生成网络结构图
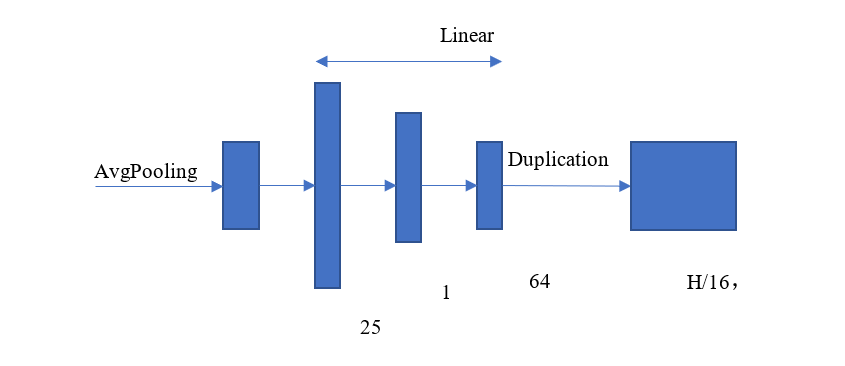
图 10. 全局分支网络结构
判别器设计:
为了能够获得更加逼近真实结果的图像,采用对抗性损失来最小化实际光分布和输出正态光分布之间的距离。但是一个图像级的鉴别器往往不能处理空间变化的图像;例如输入图像是在室内复杂光源场景下获取的,受到室内光源漫反射的影响,每个区域需要校正的程度不同,那么单独使用全局图像判别器往往无法提供所需的自适应能力。为了自适应地校正局部区域色偏,MTlab 采用文献[4]EnlightenGAN 中的 D 网络。该结构使用 PatchGAN 进行真假鉴别。判别器包含全局以及局部两个分支,全局分支判断校正图像的真实性,局部分支从输入图像随机剪裁 5 个 patch 进行判别,改善局部色偏校正效果。D 网络的输入图像与 target 图像,都会从 RGB 颜色域转换成 LAB 颜色域,Lab 是基于人对颜色的感觉来设计的,而且与设备无关,能够,使用 Lab 进行判别能够获得相对稳定的效果。全局-局部判别器网络结构如图 11 所示。
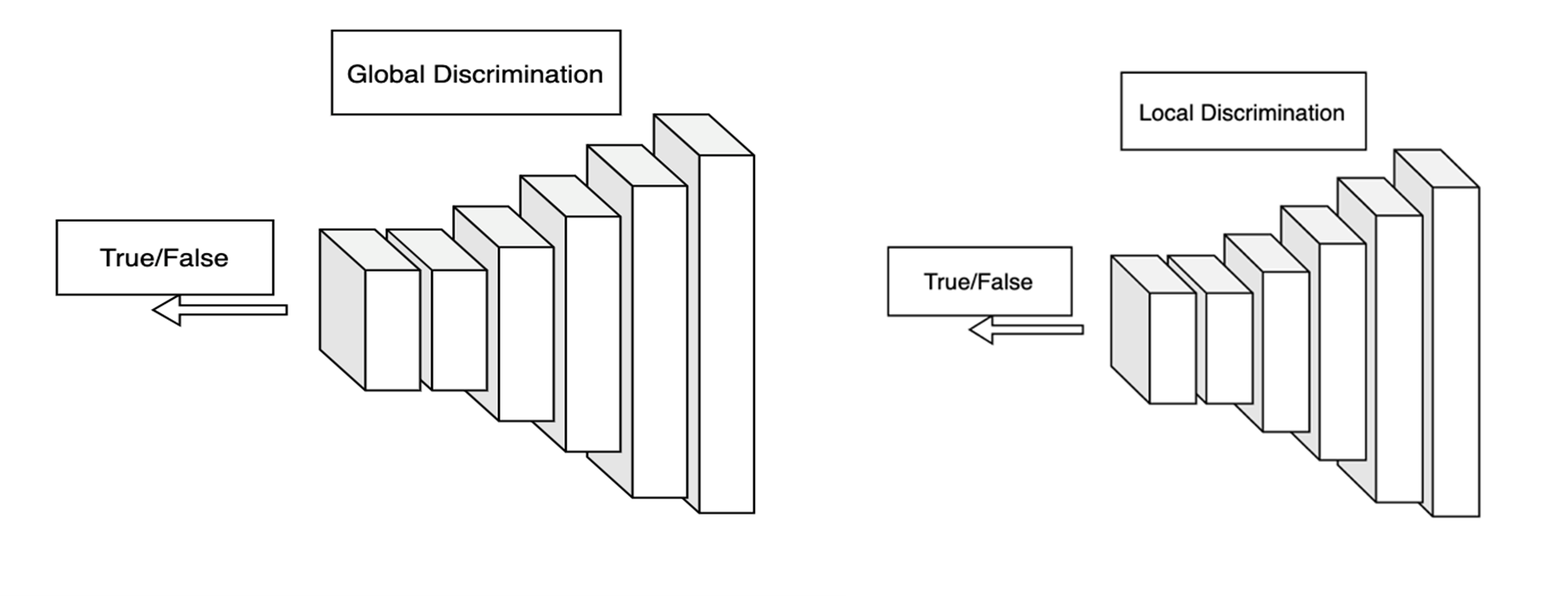
图 11. 全局-局部判别器
Loss 函数的设计包括 L1 loss, MS-SSIM loss, VGG loss, color loss and GAN loss。其中 L1 loss 保证图像的色彩亮度的真实性;MS-SSIM loss 使得生成图像不会丢失细节,保留结构性信息,VGG loss 限制图像感知相似性;color loss 分别将增强网络得到 image 与 target 先进行高斯模糊,也就是去掉部分的边缘细节纹理部分,剩下的能作为比较的就是对比度以及颜色;GAN loss 确保图像更加真实。这五个 loss 相加就构成了 AWBGAN 的损失函数。
最终色偏校正方案的校正效果如图 12 所示。
图 12. 美图云修智能白平衡结果(左:色温 6500K 情况,中:色温 2850K 情况,右:校正后图像)
智能祛除技术
修图师在修图过程中,会祛除一些皮肤本身固有的瑕疵,如皱纹、黑眼圈、泪沟等。后面以智能祛皱为例展开详细的技术说明。
对于人工智能的后期人像修图来说,皱纹检测有着重要的现实意义:一方面有助于皮肤衰老度的分析,揭示皱纹发生的区域和严重程度,成为评估肤龄的依据;另一方面,则能为图像中的自动化人脸祛皱带来更便捷的体验,即在后期修图的过程中,用户可以利用算法自动快速定位皱纹区域,从而告别繁复的手工液化摸匀的过程。
1.皱纹识别
在科研领域中,常用的皱纹检测算法主要有以下几种:
(1)基于一般边缘检测的方法:比如常见的 Canny 算子、Laplace 算子、DoG 算子,但这些算子所检出的边缘实质上是图像中两个灰度值有一定差异的平坦区域之间的分界处,而不是皱纹的凹陷处,故不利于检出具有一定宽度的皱纹;
(2)基于纹理提取的方法:有以文献[5]的 Hybrid Hessian Filter(HHF)以及文献[6]的 Hessian Line Tracking (HLT)为代表的,基于图像 Hessian 矩阵的特征值做滤波的方法,可用来提取图像中的线性结构;也有以文献[7]的 Gabor Filter Bank 为代表的,利用在提取线性纹理的 Gabor 滤波的方法。这些方法需要手工设计滤波器,带来了额外的调参代价,而且通常只能检测线状的抬头纹和眼周纹,对于沟状的法令纹的兼容较差,检测结果也容易受到其他皮肤纹理或非皮肤物体的影响;
(3)基于 3D 扫描的方法:如文献[8]提出的利用 3D 点云的深度信息映射到 2D 图像的分析方法,但该方法依赖于额外的采集设备,在算法的普适性上较弱。
在自动化人脸祛皱的需求引领下,为了摆脱传统皱纹检测算法的限制,美图影像实验室 MTlab 自主研发了一套全脸(含脖子)皱纹检测技术。该技术在覆盖全年龄段的真实人脸皱纹数据的驱动之下,发挥了深度学习表征能力强和兼容性高的优势,实现了端到端的抬头纹、框周纹、法令纹和颈纹的精准分割,成为了自动化祛皱算法的关键一环。
由于抬头纹、框周纹、法令纹和颈纹这四类皱纹的类内模式相似性较高而类间模式相似较低,MTlab 采用零件化的思想,将全脸皱纹检测任务分解成四个互相独立的子任务,分别对上述的四类皱纹进行检测。在四类皱纹的人脸区域定位上, MTlab 的人脸语义关键点检测技术发挥了重要作用。在不同拍摄场景以及人脸姿态下,该技术都能正确划分额头、眼周、脸颊和颈部区,从而为皱纹检测任务提供了稳定可靠的输入来源。MTlab 还利用眼周和脸颊区域的左右对称性,在进一步减少网络输入尺寸的同时,也让网络在模式学习上变得更简单。
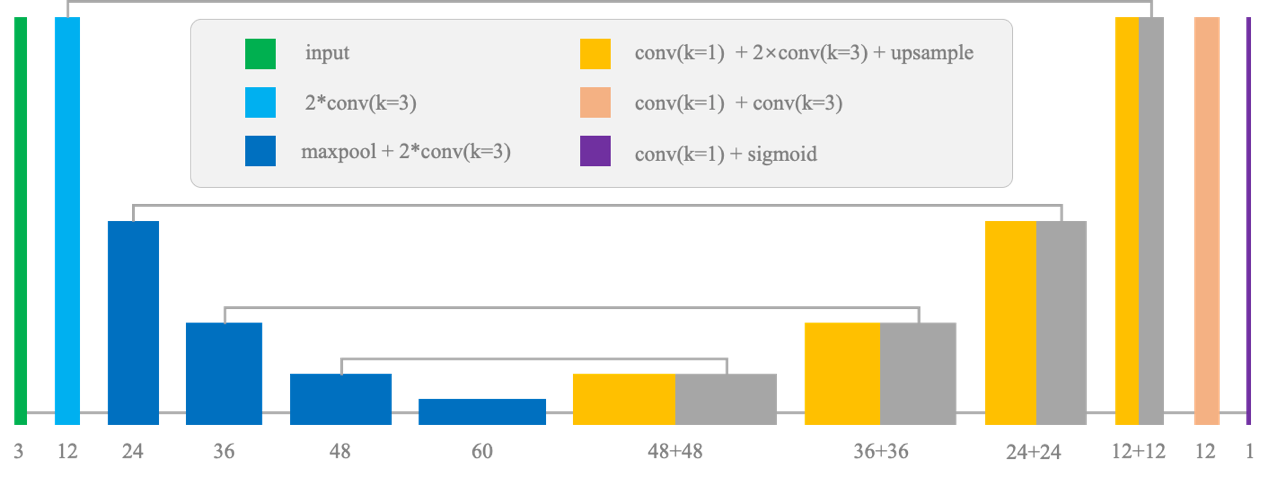
图 13. 皱纹检测网络结构图
类 U-Net 的网络结构在图像特征编码和高低层语义信息融合上有着先天的优势,故受到许多分割任务的青睐。鉴于皱纹检测本质也是分割任务,MTlab 也在 U-Net 的基础上进行网络设计,并做了以下调整:
(1)保留了编码器浅层的高分辨率特征图,并将其与解码器相同尺度的特征图进行信息融合:有助于引导解码器定位皱纹在图像中的位置,提升了宽度较细的皱纹检出率;
(2)将解码器中的反卷积层替换为一个双线性上采样层和一个卷积层:避免分割结果的格状边缘效应,让网络输出的结果更贴合皱纹的原始形状。
皱纹检测的 loss 需要能起到真正监督的作用,为此总体的 loss 由两部分组合而成:Binary Cross Entropy Loss 以及 SSIM Loss。Binary Cross Entropy Loss 是分割任务的常用 loss,主要帮助网络区分前景像素和背景像素;SSIM Loss 则更关注网络分割结果与 GT 的结构相似性,有助于网络学习一个更准确的皱纹形态。
2.皱纹自动祛除
皱纹祛除主要是基于图片补全实现,将皱纹部分作为图片中的待修复区域,借助图片补全技术重新填充对应像素。目前,图片补全技术包含传统方法和深度学习两大类:
(1)传统图片补全技术,这类方法无需数据训练,包括基于图片块(patch)[9,11]和基于像素[2]这两类补全方法。这两类方法的基本思想是根据一定的规则逐步的对图像中的受损区域进行填充。此类方法速度快,但需要人工划定待修复区域,适用于小范围的图像修复,受损区域跨度较大时容易出现模糊和填充不自然的情况。
(2)基于深度学习的 Inpainting 技术[12,13,14,15],这类方法需收集大量的图片数据进行训练。基本思想是在完整的图片上通过矩形(或不规则图形)模拟受损区域,以此训练深度学习模型。现有方法的缺陷在于所用数据集及假定的受损区域与实际应用差异较大,应用过程易出现皱纹无法修复或是纹理不清,填充不自然的情况。
鉴于影楼用户对于智能修图的迫切需求,美图影像实验室 MTlab 自主研发了一套能够适应复杂场景的的皱纹祛除方案。MTlab 提出的智能皱纹祛除方案,依靠海量场景的真实数据,在识别皱纹线的基础上借助 Inpainting 的深度学习网络予以消除,提供端到端的一键式祛除皱纹,使其具备以下 2 个效果:
(1)一致性:填充区域纹理连续,与周围皮肤衔接自然。
(2)鲁棒性:受外部环境影响小,效果稳定。
MTlab 针对该问题收集的海量数据集能够涵盖日常生活场景中的多数场景光源,赋能模型训练最大驱动力,保障模型的性能,较好的解决了上述问题,并成功落地于应用场景。
针对现有方案存在的缺陷,MTlab 根据皱纹的特点设计了皱纹祛除模型(WrinkleNet)。将原始图片和皱纹 mask 同时送入祛除模型,即可以快速的完成祛除,并且保持了资深人工修图在效果上自然、精细的优点,在各种复杂场景都有较强的鲁棒性,不仅对脸部皱纹有效,同时也可用于其他皮肤区域(如颈部)的皱纹祛除,其核心流程如图 14 所示。
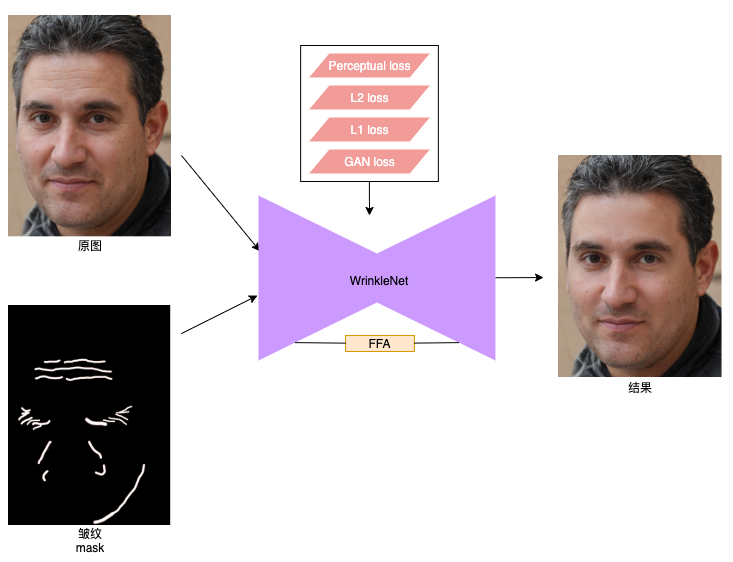
图 14. 祛皱核心流程
数据集制作:
如前所述,数据集会极大的影响深度学习模型的最终效果,目前主流的图像补全模型多采用开源数据集,使用矩形或不规则图形模拟图像中待补全的区域。针对皱纹祛除任务这么做是不合理的。一方皮肤区域在颜色和纹理上较图片其他区域差异较大,另一方面皱纹多为弧形细线条,其形状不同于已有的补齐模式(矩形、不规则图形),这也是导致现有模型效果不够理想的原因之一。因此,在数据集的准备上,MTlab 不仅收集了海量数据,对其皱纹进行标注,同时采用更贴近皱纹纹理的线状图形模拟待填充区域。
生成网络设计:
生成网络基于 Unet 设计,鉴于直接使用原始的 U-Net 网络生成的图像会存在纹理衔接不自然,纹理不清的问题,因此对其结构做了一些调整。1)解码的其输出为 4 通道,其中一个通道为 texture 回归,用于预测补齐后的图片纹理;2)在 Unet 的 concat 支路加入了多特征融合注意力模块(简称 FFA)结构,FFA 的结构如图 15 所示,该结构旨在通过多层特征融合注意力模块,如图 16 所示,提高模型对细节纹理的关注度。
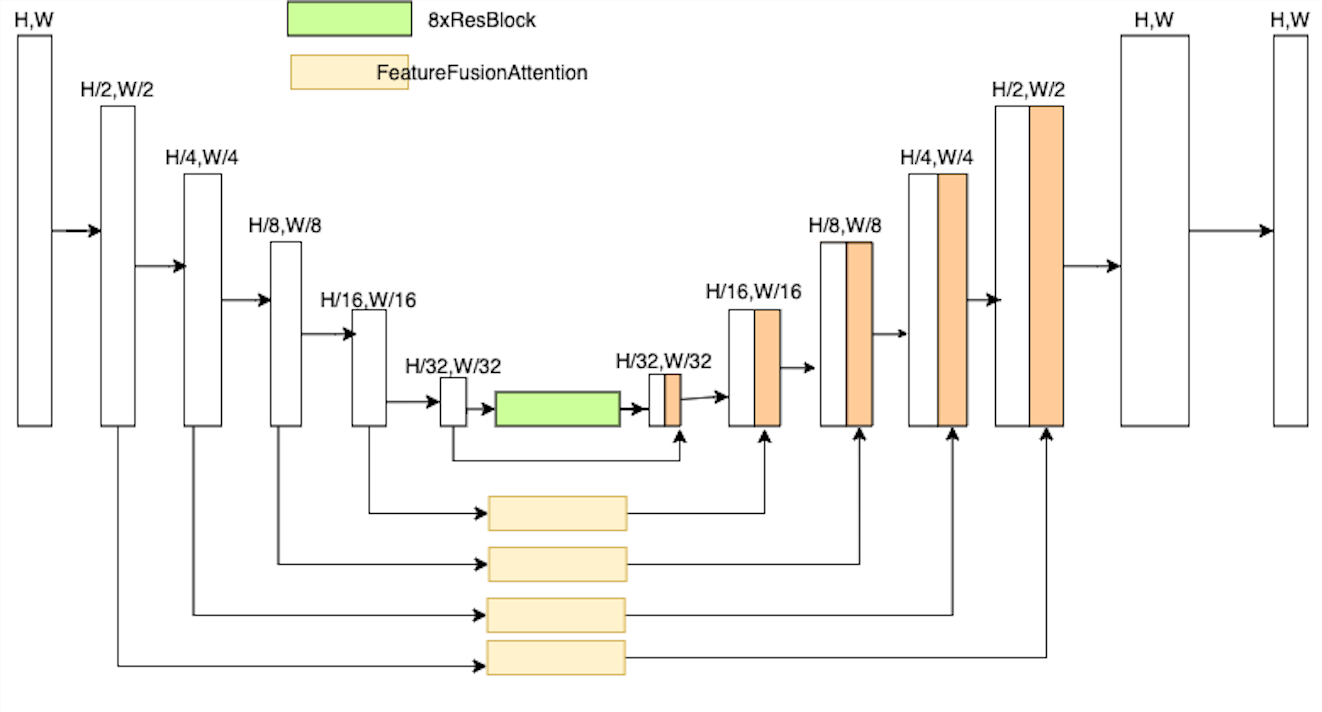
图 15. 生成网络结构图
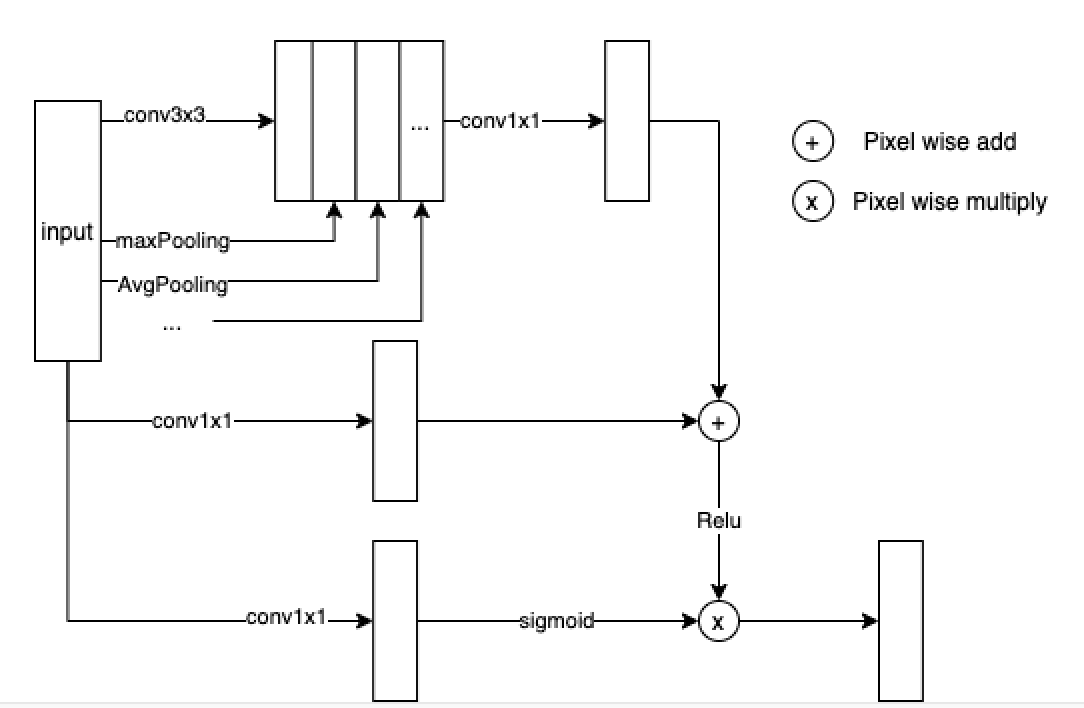
图 16. 多特征融合注意力模块
Loss 设计:
Loss 函数的设计包括 L1-loss, L2-loss, VGG-loss,以及 GAN-loss。其中 L1-loss 度量输出图像与真实图像间的像素距离;L2-Loss 用于度量输出纹理与真实纹理间的差异;VGG loss 限制图像感知相似性;GAN loss 采用 PatchGAN 结构,确保图像更加真实。这四个 loss 相加就构成了 WrinklNet 的损失函数。
最终脸部和脖子的祛皱效果分别如图 17 和图 18 所示:

图 17. 美图云修脸部祛皱效果

图 18. 美图云修脖子祛皱效果
智能修复技术
修图师在修图过程中,会修复人像不美观的地方,如牙齿、双下巴、鼻梁等,以使人像修图后更加美观。这类问题靠人工修图耗时严重,也未必能达到美观的效果。本文以牙齿修复为例,展开智能修复技术的说明,该技术亦可拓展到双下巴、鼻梁修复等。
在现实生活中,龅牙、缺牙、牙缝、牙齿畸形等等问题会让用户在拍照时不敢做过多如大笑等露出牙齿的表情,对拍摄效果有一定影响。美图云修基于 MTlab 自主研发的一个基于深度学习技术的网络架构,提出了全新的牙齿修复算法,可以对用户各类不美观的牙齿进行修复,生成整齐、美观的牙齿,修复效果如图 19 所示。

图 19. 美图云修牙齿修复效果
MTAITeeth 牙齿修复方案:
要将牙齿修复算法真正落地到产品层面需要保证以下两个方面的效果:
(1)真实性,生成的牙齿不仅要美观整齐,同时也要保证生成牙齿的立体度和光泽感,使其看起来更为自然。
(2)鲁棒性,不仅要对大多数常规表情(如微笑)下的牙齿做修复和美化,同时也要保证算法能够适应某些夸张表情(如大笑、龇牙等)。
MTlab 提出的 MTAITeeth 牙齿修复算法,较好地解决了上述两个问题,并率先将技术落地到实际产品中,其核心流程如图 20 所示。
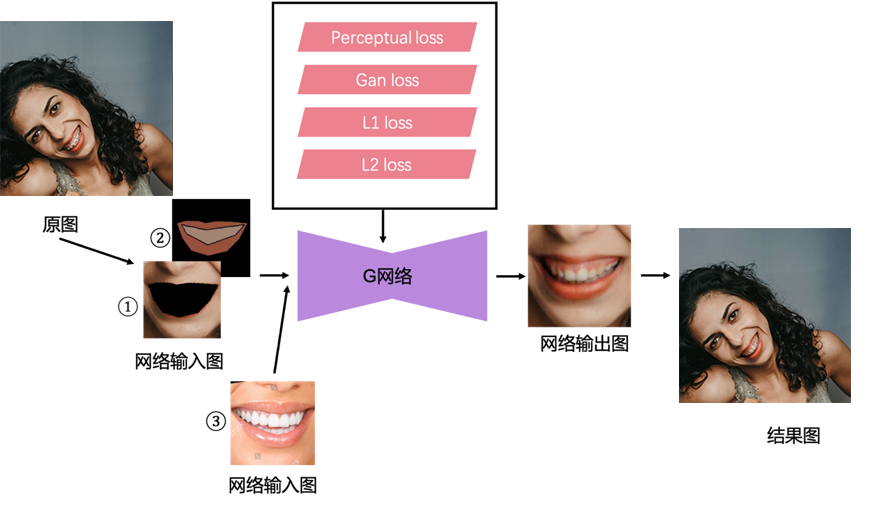
图 20. AITeeth 牙齿修复方案流程图
图中所展示的流程主要包括:G 网络模块和训练 Loss 模块,该方案的完整工作流程如下:
1、 通过 MTlab 自主研发的人脸关键点检测算法检测出人脸点,根据人脸点判断是否有张嘴;
2、 若判定为张嘴,则裁剪出嘴巴区域并旋转至水平,再根据人脸点计算出嘴唇 mask、牙齿区域 mask 以及整个嘴巴区域(包括嘴唇和牙齿)的 mask;
3、根据嘴巴区域的 mask 得到网络输入图①,根据牙齿区域和嘴唇区域的 mask,分别计算对应区域的均值,得到网络输入图②,两个输入图均为 3 通道;
4、G 网络有两个分支,训练时,将图①和图②输入 G 网络的第一个分支,再从数据集中随机挑选一张参考图(网络输入图③)输入 G 网络的第二个分支,得到网络输出的结果图,根据结果图和目标图计算 Perceptual loss、Gan loss、 L1 loss 以及 L2 loss,上述几个 loss 控制整个网络的学习和优化;
5、实际使用时,将裁剪好的嘴巴区域的图进行步骤 3 中的预处理,并输入训练好的 G 网络,就可以得到网络输出的结果图,结合图像融合算法将原图和结果图进行融合,确保结果更加真实自然,并逆回到原始尺寸的原图中,即完成全部算法过程。
GAN 网络的构建:
对于方案中的整个网络结构,以及 perceptual loss、L1 loss、L2 loss 和 Gan loss,方案参考了论文 EdgeConnect[16]中的网络结构并结合自有方案进行了调整。仅用网络输入图①和网络输入图②训练网络模型,会造成生成的牙齿并不美观甚至不符合常规,为了使网络模型可以生成既美观又符合常规逻辑的牙齿,本方案构建了一个双分支输入的全卷积网络,第二个分支输入的是一张牙齿的“参考图”,训练时,该参考图是从训练数据集中随机选择的,参考图可以对网络生成符合标准的牙齿起到正向引导的作用:
第一个分支为 6 通道输入,输入为图①和图②的 concat,并归一化到(-1,1)区间;
第二个分支为 3 通道输入,输入图像是在构建的训练数据集中随机挑选的“参考图”,同样归一化到(-1,1)区间;
G 网络是本质上是一个 AutoEncoder 的结构,解码部分的上采样采用的是双线性上采样+卷积层的结合,与论文中[16]有所不同,为了减轻生成图像的 artifacts 和稳定训练过程,本方案中的归一化层统一都采用 GroupNorm,而网络最后一层的输出层激活函数为 Tanh。
判别网络部分:判别网络采用的是 multi_scale 的 Discriminator,分别判别不同分辨率下的真假图像。本方案采用 3 个尺度的判别器,判别的是 256x256,128x128,64x64 三个尺度下的图像。获得不同分辨率的图像,直接通过 Pooling 下采样即可。
Loss 函数的设计包括 L1 loss, L2 loss, Perceptual loss 和 GAN loss。其中 L1 loss 和 L2 loss 可以保证图像色彩的一致性;GAN loss 使得生成图像的细节更加真实,也使得生成的牙齿更加清晰、自然、更加具有立体度和光影信息;Perceptual loss 限制图像感知的相似性,以往的 VGG loss 往往会造成颜色失真与假性噪声的问题,本方案采用的是更加符合人类视觉感知系统的 lpips(Learned Perceptual Image Patch Similarity) loss[17],很大程度上缓解了上述问题,使生成图像具有更加自然的视觉效果;上述这几个 loss 相加就构成了 MTAITeeth 方案的损失函数。
AI 修图
影楼修图涉及众多技术,除了上述提到的特色修图功能外,还包括人脸检测、年龄检测、性别识别、五官分割、皮肤分割、人像分割、实例分割等相对成熟的技术,可见成熟的 AI 技术能够替代影楼修图费时费力且重复度高的流程,大幅节省人工修图时间,节省修图成本。在智能调色、智能中性灰、智能祛除、智能修复等 AI 技术的加持下,提高修图质量,解决手工修图存在的问题。AI 自动定位脸部瑕疵、暗沉、黑头等,在不磨皮的情况下予以祛除,实现肤色均匀,增强细节清晰度;识别皱纹、黑眼圈、泪沟等皮肤固有的缺陷,在保持纹理细节和过渡自然的前提下予以祛除;针对用户的牙齿、双下巴等影响美观的缺陷,采用 AI 技术进行自然修复,达到美观和谐的效果。
凭借在计算机视觉、深度学习、增强现实、云计算等领域的算法研究、工程开发和产品化落地的多年技术积累,MTlab 推出的的美图云修人工智能修图解决方案能为影像行业注入更多的活力,为商业摄影提供低成本、高品质、高效率的的后期修图服务。
参考文献:
[1] CBAM: Convolutional block attention module, Woo, S., Park, J., Lee, J.Y., So Kweon, ECCV (2018).
[2] Learning Enriched Features for Real Image Restoration and Enhancement, Syed Waqas Zamir, Aditya Arora, Salman Khan, Munawar Hayat, Fahad Shahbaz Khan, Ming-Hsuan Yang, and Ling Shao, ECCV (2020).
[3] Huang, Jie , et al. "Range Scaling Global U-Net for Perceptual Image Enhancement on Mobile Devices." European Conference on Computer Vision Springer, Cham, 2018.
[4] Jiang Y , Gong X , Liu D , et al. EnlightenGAN: Deep Light Enhancement without Paired Supervision[J]. 2019.
[5] Ng, Choon-Ching, et al. "Automatic wrinkle detection using hybrid hessian filter." Asian Conference on Computer Vision. Springer, Cham, 2014.
[6] Ng, Choon-Ching, et al. "Wrinkle detection using hessian line tracking." Ieee Access 3 (2015): 1079-1088.
[7] Batool, Nazre, and Rama Chellappa. "Fast detection of facial wrinkles based on Gabor features using image morphology and geometric constraints." Pattern Recognition 48.3 (2015): 642-658.
[8] Decencière, Etienne, et al. "A 2.5 d approach to skin wrinkles segmentation." Image Analysis & Stereology 38.1 (2019): 75-81.
[9] Criminisi A , P P , Toyama K . Region filling and object removal by exemplar-based image inpainting[J]. IEEE Transactions on Image Processing, 2004, 13.
[10] Telea A. An image inpainting technique based on the fast marching method[J]. Journal of graphics tools, 2004, 9(1): 23-34.
[11] Pérez P, Gangnet M, Blake A. Poisson image editing[M]//ACM SIGGRAPH 2003 Papers. 2003: 313-318.
[12] Pathak D, Krahenbuhl P, Donahue J, et al. Context encoders: Feature learning by inpainting[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 2536-2544.
[13] Yeh R A, Chen C, Yian Lim T, et al. Semantic image inpainting with deep generative models[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 5485-5493.
[14] Liu G, Reda F A, Shih K J, et al. Image inpainting for irregular holes using partial convolutions[C]//Proceedings of the European Conference on Computer Vision (ECCV). 2018: 85-100.
[15] Hong X, Xiong P, Ji R, et al. Deep fusion network for image completion[C]//Proceedings of the 27th ACM International Conference on Multimedia. 2019: 2033-2042.
[16 EdgeConnect: Structure Guided Image Inpainting using Edge Prediction, Nazeri, Kamyar and Ng, Eric and Joseph, Tony and Qureshi, Faisal and Ebrahimi, Mehran, The IEEE International Conference on Computer Vision (ICCV) Workshops}, Oct, 2019.
[17] The Unreasonable Effectiveness of Deep Features as a Perceptual Metric, Richard Zhang, Phillip Isola, Alexei A. Efros, Eli Shechtman, Oliver Wang. In CVPR, 2018.

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论