

我是来自腾讯云的黄杰,目前主要负责腾讯云上云原生可观测性的产品和内部平台的落地。我从业务转做监控至今已经有十几年,我还是开源项目的实践爱好者。今天我将为大家分享腾讯在云原生可观测性领域中的探索、实践,以及一些踩坑经历。
什么是云原生可观测性?
可观测性,也就是我们曾说的监控,其中包含 Log、tracing、Metrics 等等。我们要怎么将这些异构的数据进行关联?这些数据之间的关系是什么?我们又要如何应用好这些数据?
监控 vs. 可观测
传统意义上的监控其实是与当时的业务场景有一定关系的,监控所反映的是系统是否能正常工作的情况,关注点在于单个系统(如数据库是否可工作、服务是否可工作、主机是否在线等等),其中的 Log、Metric、Trace 概念相对独立。由此诞生了 OpenMetrics、OpenTracing 等组织,普罗米修斯、Jaeger 等开源产品。

另一方面,可观测性在回答系统是否正常工作的同时,也能给出无法工作的原因,如常见的系统故障原因和补救措施。可观测性解决的是整体的问题,这是与监控所解决的单点问题有所不同。此外,除了 Tracing、Log、Metric 等方面外,可观测性也包含 Event、Profiler 等其他数据源,且数据之间不相互独立。而只有在清楚了解这些数据间的关联,我们才能明白故障背后的原因和影响的业务。幸运的是,目前这一领域也出现了许多优秀的组织和较为活跃的项目,比如大家所熟知的 CNCF 中 OpenTelemetry 项目,以及做数据可视化出名 Grafana。Grafana 目前也在通过 Loki、tempo 布局可观测性,在收购了 K6 等公司负责压测的同时,也有涉足 Profiling、CI/CD 等方面。此外,还有国外热度较高的商业化公司 DataDog,以及国内诸多类型的公司。
服务架构在变化
监控的单点化是有原因的。传统行业的应用可能只有一台服务器和其上运行的数据库、业务代码,对监控的需求并不大,甚至只有日志输出即可。而现在的公司业务甚至可能比右图中所展示的还要错综复杂,在这种情况下,仅使用 Log、Metrics、Trace 并不能解决实际生产中的问题,服务治理的难度在增加,环境愈发复杂,对故障修复效率的要求也越来越高,短短几分钟的故障都可能造成金钱损失,服务不可用也会带来用户的流失。此外,随着公司业务扩张,角色也会随之增加,各个服务角色之间还会出现责任的推卸。

但如果我们将这个复杂的网状结构进行细分,那么其中的关系便能一目了然。服务可以运行在传统 VM 环境或 K8s 环境中,会运用一些 PaaS 类产品,如数据库、cache、消息队列等等。服务间也会存在调用关系,并因此产生 Log、Metrics、log。那么我们要如何将这些相连的关系包含在数据之中?又要如何将这些数据采集呢?

可观测性几大支柱
Metrics
常见的 Metrics 指标包含:
业务指标:订单量,用户数等
应用服务指标:延时、成功率或失败率、失败异常,常用的有谷歌的黄金指标
中间件指标:缓存命中率、消息积压等
系统基础设施指标:CPU 使用率、网络带宽等
人们通常都会在指标中添加告警。我们内部曾经为及时发现系统问题,将所有相关指标都添加了告警,但也由此引发了告警风暴,系统是否故障往往可以直接看手机消息的震动频率直观看出,这样一来,告警的意义也就不复存在了。
业务相关的核心指标则更为重要。比如,在接收到 CPU 使用率过高的告警后,我们可能会从 Dashboard 中找到眉目,但单独依靠指标我们只能得知故障的现象,对于故障的原因还是无法做出回答。
那么,我们要如何透过指标曲线,针对性地找出有问题的指标、Log,或 tracing?怎样才能发现上下文中故障的环节、异常的日志、Exception,或出现延迟的链路呢?这里就先容我先卖个关子。
Tracing
全链路 Tracing 可以通过下面这个简单的用户下单行为模拟进行分析。图中包含了网关、用户服务、订单服务。网关在接受到请求后,对用户服务进行调用,访问数据库获取到用户信息;订单服务创建订单后,将订单状态存入缓存用于后续状态的更新。
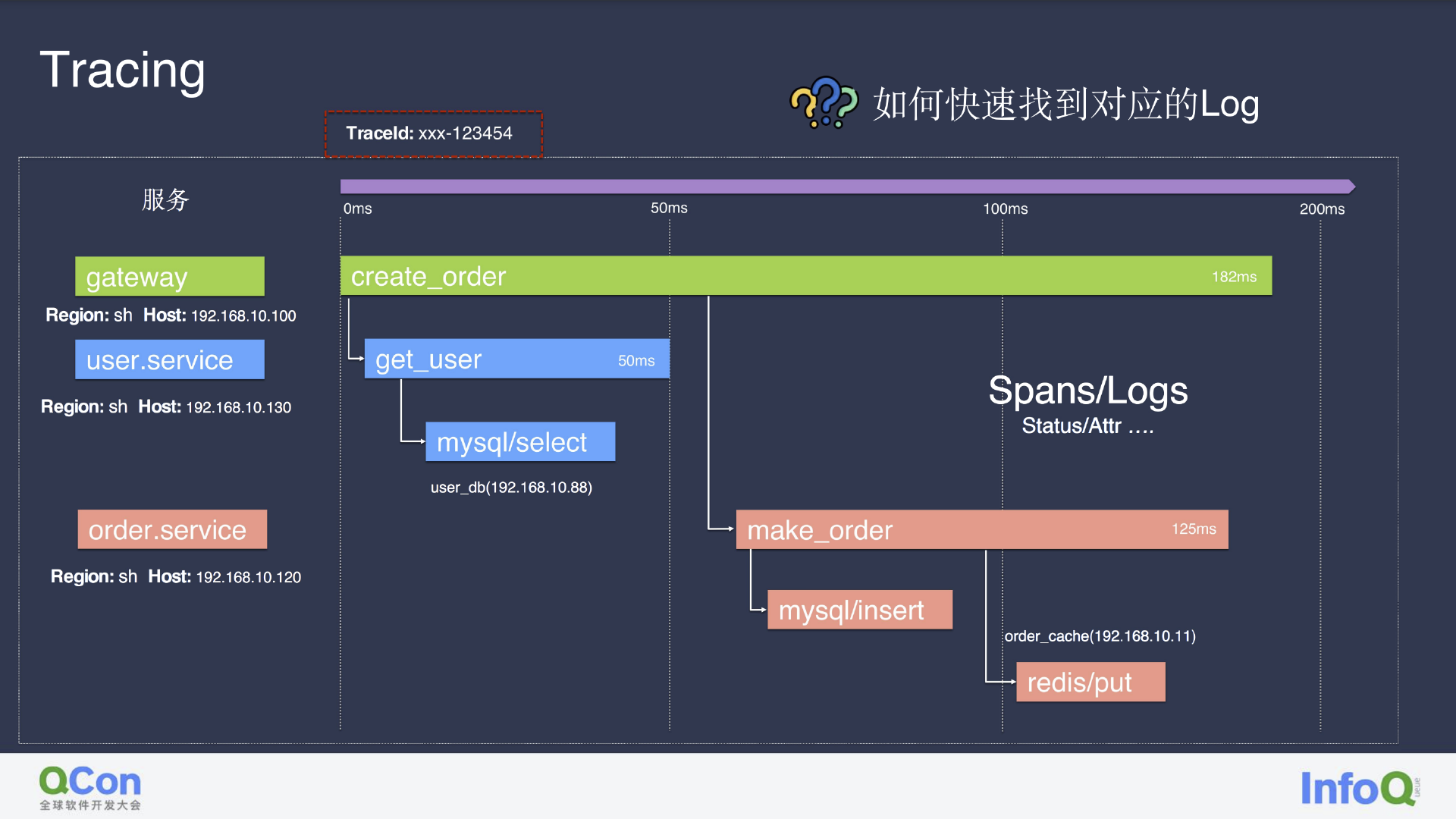
在这个过程中,我们把完成这一次操作的请求用一个叫 Trace ID 的标识出来,用于区分不同机器上、多云多机房、云上云下、多 Region 数据库 等不同场景,这其中也隐含了服务的各种信息,如服务运行的机器或 K8s 的 pod 及对应 VM、服务调用、客户端对数据库的访问、缓存访问、服务运行机、服务间关系、服务所用的 PaaS 产品等等。我们还能获取每个服务处下相应请求的时间信息(开始时间、结束时间、延时)、状态、Event,以及具体的上下文日志。
Logging
以下图的常规日志为例,我们能看到其中的时间戳、消息内容、log level、Trace ID,以及其他通用属性。OpenTelemetry 可在日志中提供标签功能,标明产生日志的用户、订单、服务及其所属组织、机器物理位置等状态信息。从中自然也隐含了日志归属服务、机器、其间关联等信息,从而将非结构化数据结构化。
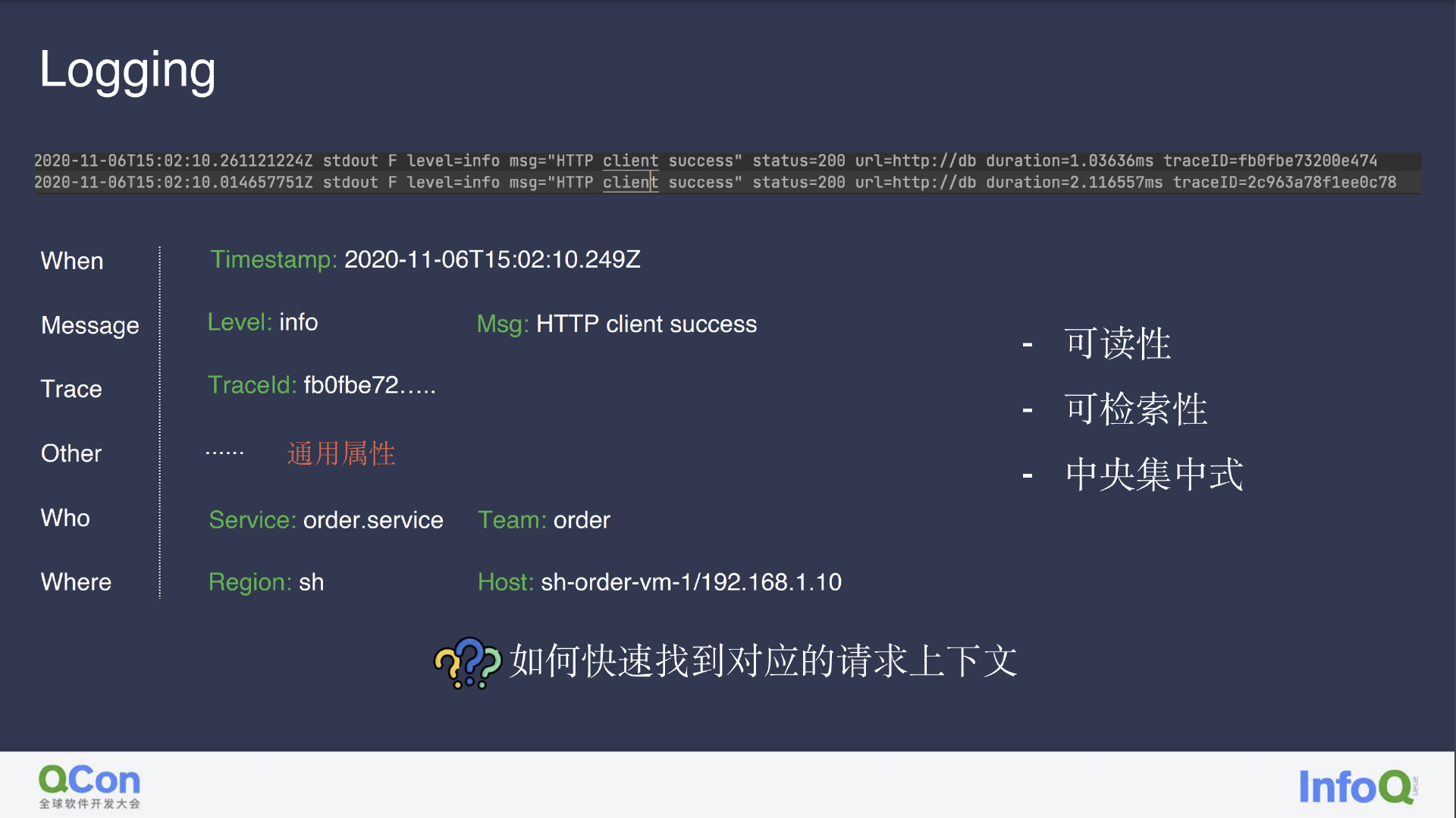
在服务繁多的场景下,我们需要保证日志采集的中央化以及日志打印的可读性,方便他人在故障发生时快速检索相关日志,从而定位故障问题,但是做到这些是不是已经足够?
源源不断的日志采集不仅会带来高昂的成本,在问题出现后如果没有 Trace ID 或用户 ID,即使是有上下文存在,也很难对问题进行排查。
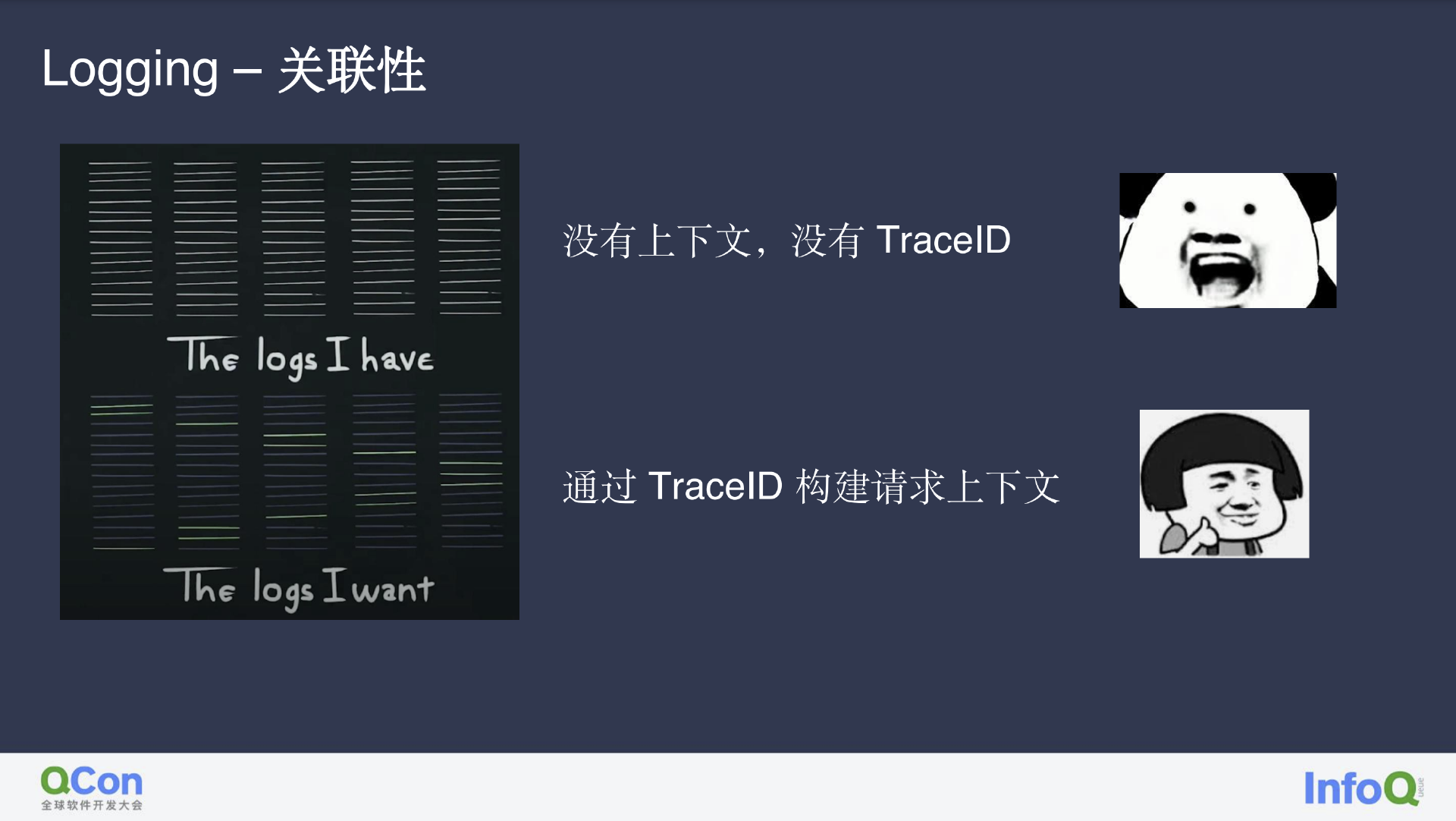
通过 Trace ID 对上下文构建,可以让我们轻松获取到发生故障机器上的请求和相关日志。进一步讲,我们也可以通过通用属性订单 ID 或交易 ID,不仅将单次请求的 Trace 相关联,还能将服务链路顺畅连接。而用户 ID 则因为用户行为的长周期性,不适用于此处的短周期事务性场景。用户维度的跟踪可以根据前端的可观测性进行串联,对用户在前端的行为进行管理,从而模仿用户的上下文。
目前,我们在告警时查找日志的思路是尽可能通过 Trace 提取计算 Metrics。业务指标场景中,可通过接口或 RPC 请求直接反应订单创建行为,免去用户自行标记指标的操作;应用服务指标中的许多都可以天然通过 Trace 进行提炼;中间件指标方面,则可以从客户端一侧实施可观测性,比如,数据库访问的库名、TP、快慢 SQL、成功与否等等,至于数据库响应,在已知 DP 和关联的情况下,client 和 server 间也可以很好地进行关联;系统基础设施指标基本属于传统监控范畴,通过主机 IP、host、标签,关联服务所在机器的 CPU 内存、网络带宽等等。
Health Check
与拨测类似,Health Check 会探测 IP 和端口是否可用,并将服务内部依赖及故障原因简单地告知可观测平台。
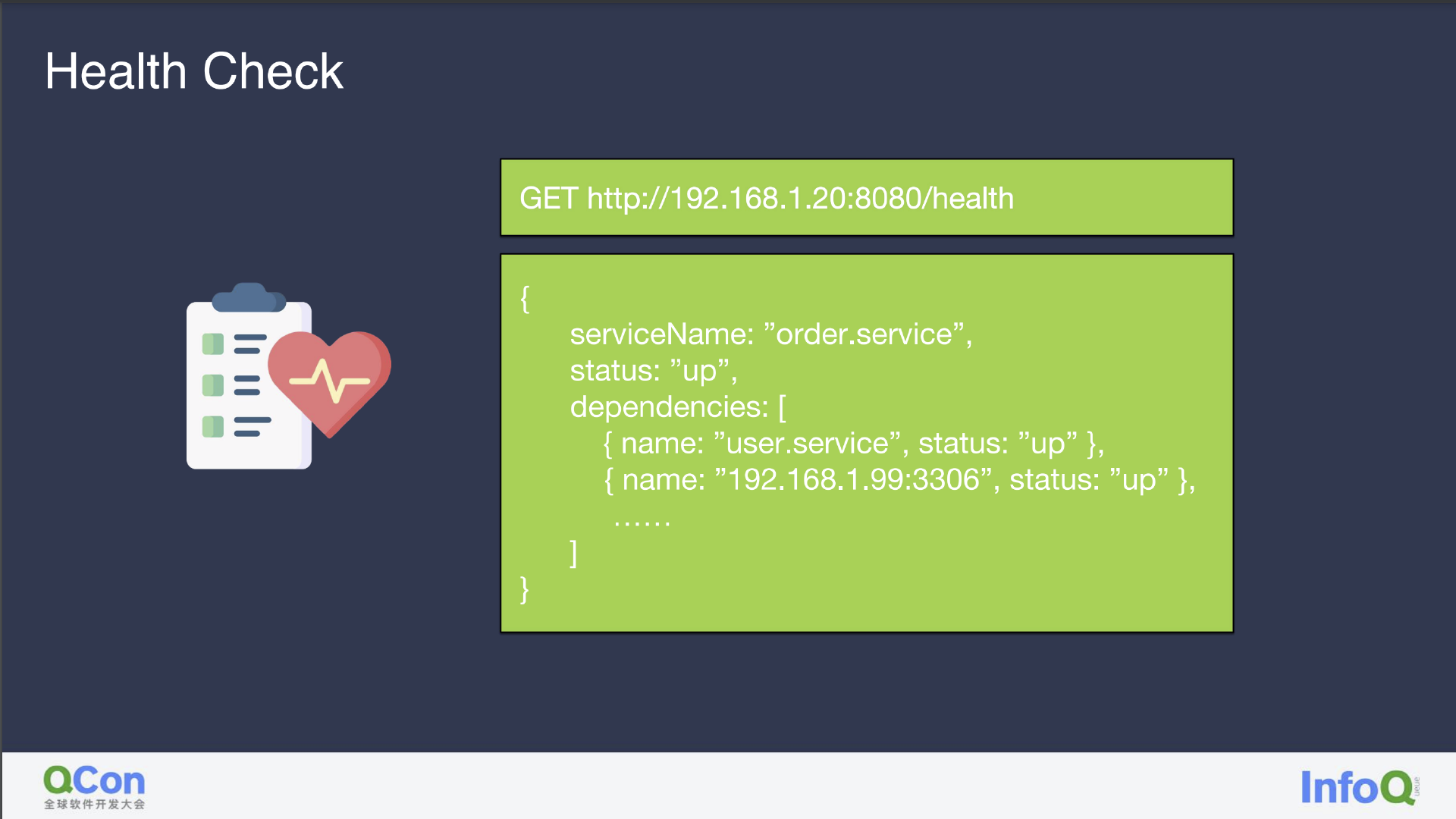
至于 Health Check 的运用,我们内部曾基于 Health Check 做过一个对 DB 的监控,通过 DB 的慢 SQL/TPS 及其他数据库行为判定数据库是否正常,Health Check 也可用于服务点火,及时地 check 发布后的服务是否成功,如果不成功则立刻回滚。此外,K8s 也提供对服务部署后的存活检测,云服务商的状态页也有状态异样的检测。
Event
除此之外,我认为变更也非常有用。据业务数据分析线上故障至少有五成左右都是直接来源于变更。下图的例子中,我们内部在每次变更都会把 commit 信息和环境信息包含在其中,让后台能立刻得知那些服务有变更,一旦出现故障便能立刻找到有问题的变更。
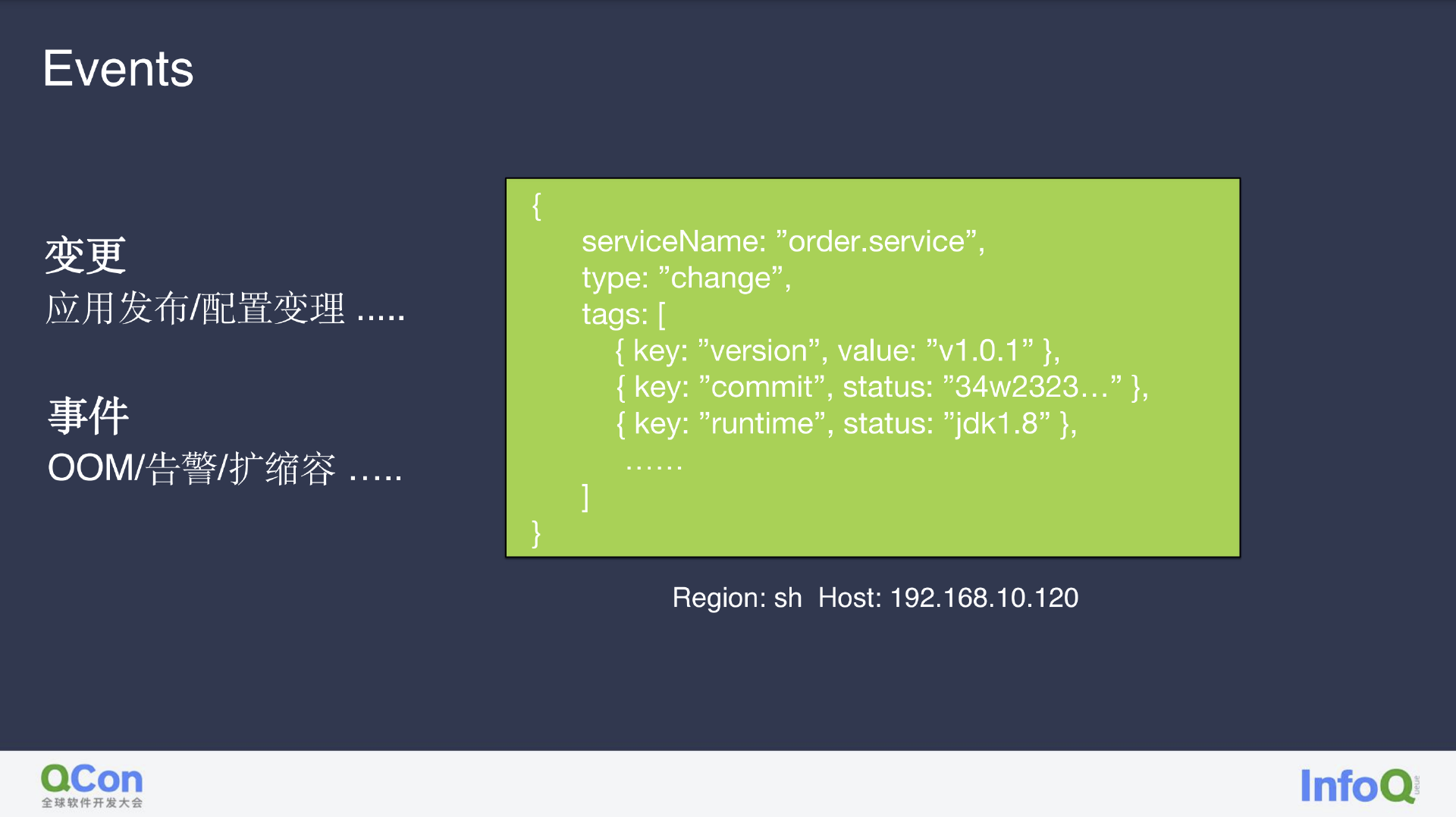
相互关联
总体来说,这些单体本身的实施并不困难,但这些数据采集如果没有运用好,也将会变为一种负担。我们的第一代系统就是具备日志打印功能的基础设施,自我感觉很好但对业务而言毫无价值,出现故障后他人很难通过搜索日志关键字找到问题原因。

为此,我们将问题根据异常类型或 Error 级别进行简单的分类统计,让 DBA 和业务关注自身类别的告警,直观地通过 Dashboard 中指标情况,找到下方 Trace 链路和环节的问题点,继而根据 Trace ID 对日志关联,查找具体日志内容。整体排查过程基本不涉及任何关键字查找,仅仅通过图示和鼠标操作上游便可轻松定位问题模块。

在 Tracing、Metrics、Log 这三大支柱下,目前开源社区如 OpenTelemetry 会对日志打印的标准进行定义,限定特定情况下日志打印的标签、日志内容,以及如何利用这些数据提取 Metrics 等等,将原本独立三大资源贯通,从而实现后续的 root cause 根因分析。
如何建设可观测性
搭建监控或可观测平台离不开丰富的数据采集、数据清洗和计算、数据存储及对用户展现这三个方面。

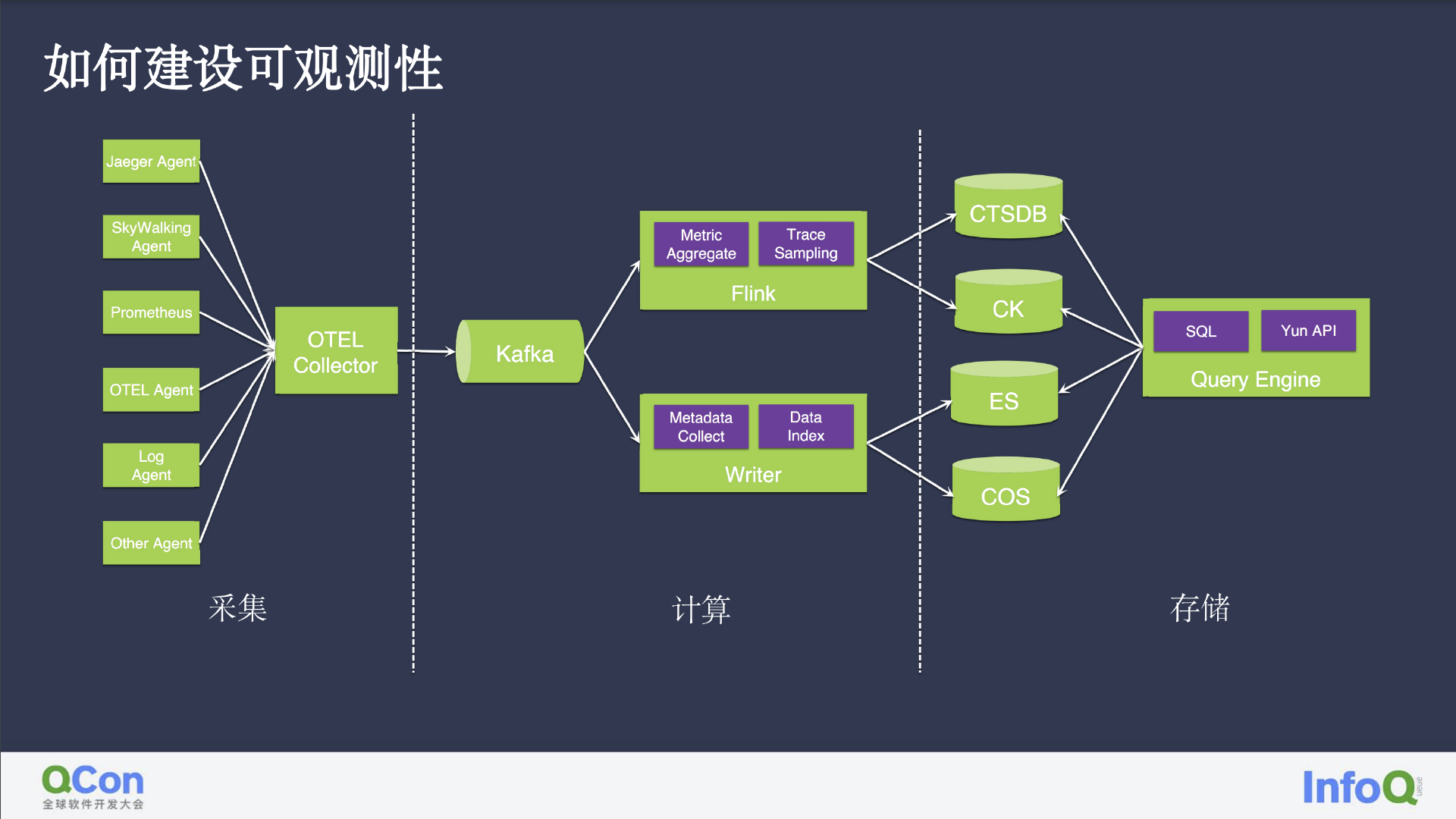
下图中整理了采集、存储、计算整体流程的简单示意图。目前许多基础设施软件都已在内部集成各式 SDK,导致传统的闭源很难继续存活,因此我们选择拥抱开源,使用 Jaeger Agent、SkyWalking、普罗米修斯、OpenTelemetry、OTEL Agent、Log Agent,以及一些内部传统 Agent 等进行数据采集,并将采集到的数据汇总到扩展性较好的 OpenTelemetry Collector 中,通过鉴权路由把数据分发到 Kafka,再兵分两路;一路用于日志分析、数据提取,将指标保存于 Clickhouse 或 CTSDB 后闭环到数据清洗和计算,从而完成其他告警和监测工作。另外一路则相对简单,将数据按照是否存在问题进行分离存储(ES、COS、或 Clickhouse),统一挂载查询引擎,允许用户使用类似 SQL 查询的形式对数据进行查找 Log、指标、Trace 等等。
如何采集
我们将开源社区内的 Receive 根据业务需求进行了简单的改造和扩展,将所有 Receiver 中的异构数据转换为统一的内部 OpenTelemetry 协议进行存储。
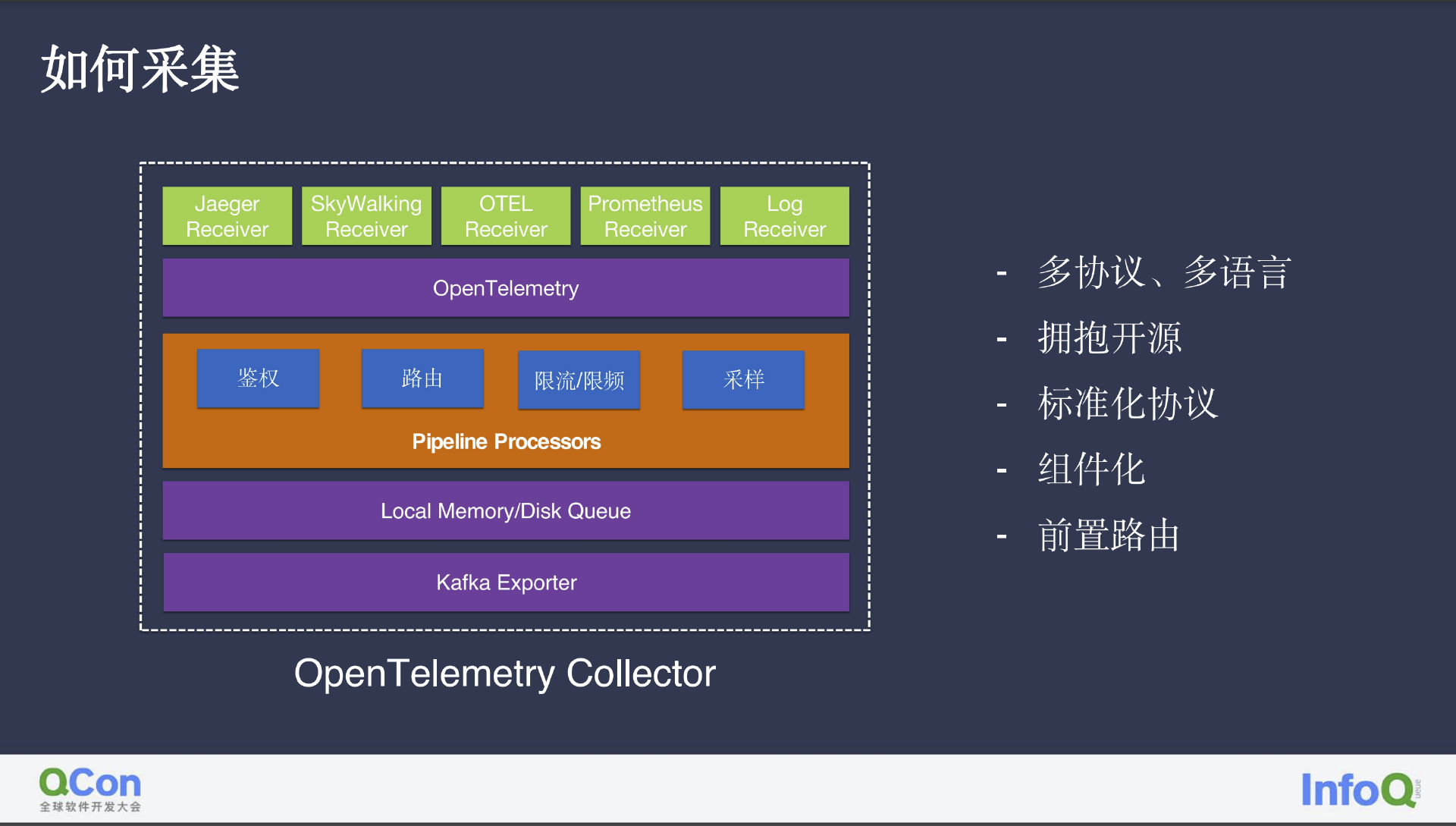
此外,云上服务中的鉴权、采样、限流/限频方面,以及我认为较重要的路由,即提前根据租户、产品类型,以及监控场景分类数据,将分类后同类型数据进行简单合并,从而方便后续操作并减轻网络传输压力。为保证监控数据的时效性,延时数据不会对后续造成影响,我们采用了本地+内存的缓存机制,一份存储数据可被多人消费,类似于一个本地的简单 Kafka;将最新的数据保存至内存,历史数据保存至本地磁盘,日志消费等则由 Kafka 负责。整体过程直接套用开源方案,我们只在其中进行了标准化的工作,确保数据的统一性。
如何计算
我们是近些年才将计算迁移至 Flink 的,其中最具特色的便是我们的视图级联运算和延时数据运算,以及其他常规的平滑重启、数据补算、动态规则加载、状态自监控(告知上一级数据路由的问题)。

为实现监控大数据量下的高吞吐,我们需要在上游做好数据分类的前提下,对监控数据进行裁剪,在 Flink 的前置 Route 中进行数据的合并压缩;废弃了过重的 Checkpoint,通过异常时间点的补算保障数据的完整性;将业务中的大任务进行拆解,便于系统整体维护;引入了迭代流,将计算结果循环利用。
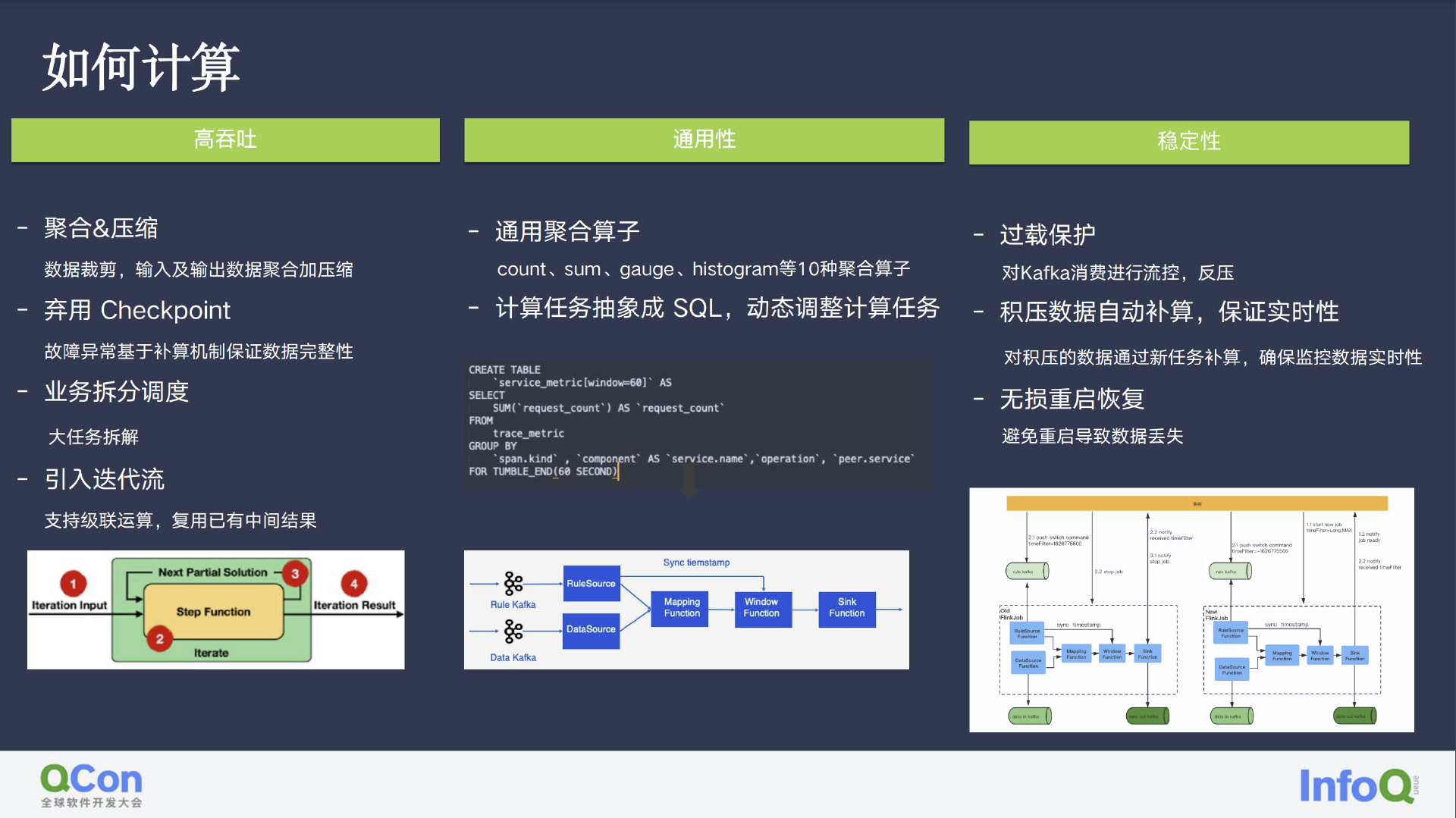
我们通过抽象十数种通用算子(如 count、gauge、采样等),将 SQL 翻译为 Flink 算子进行 pipeline 计算,从而实现系统逻辑的通用性。
在稳定性方面,我们主要关注的是积压数据的实时性,通过新任务补算,确保 delay 的数据不会影响后续计算流;无缝重启则是通过下发停止计算的时间点,让新任务在该时间点处理后续数据,为避免中间数据的重复性,我们在设计算子时也考虑到这一点,故而所有数据都是可以再计算的。
如何存储
存储主要分为三部分,Log、Trace、Metrics。通过抽象数据 ID 化,以类似数据库组件的形式,对这些数据进行打标,对于 CVM/CDB 这种云上产品而言,数据 ID 也可方便的针对不同用户的需求进行补打标和补算。
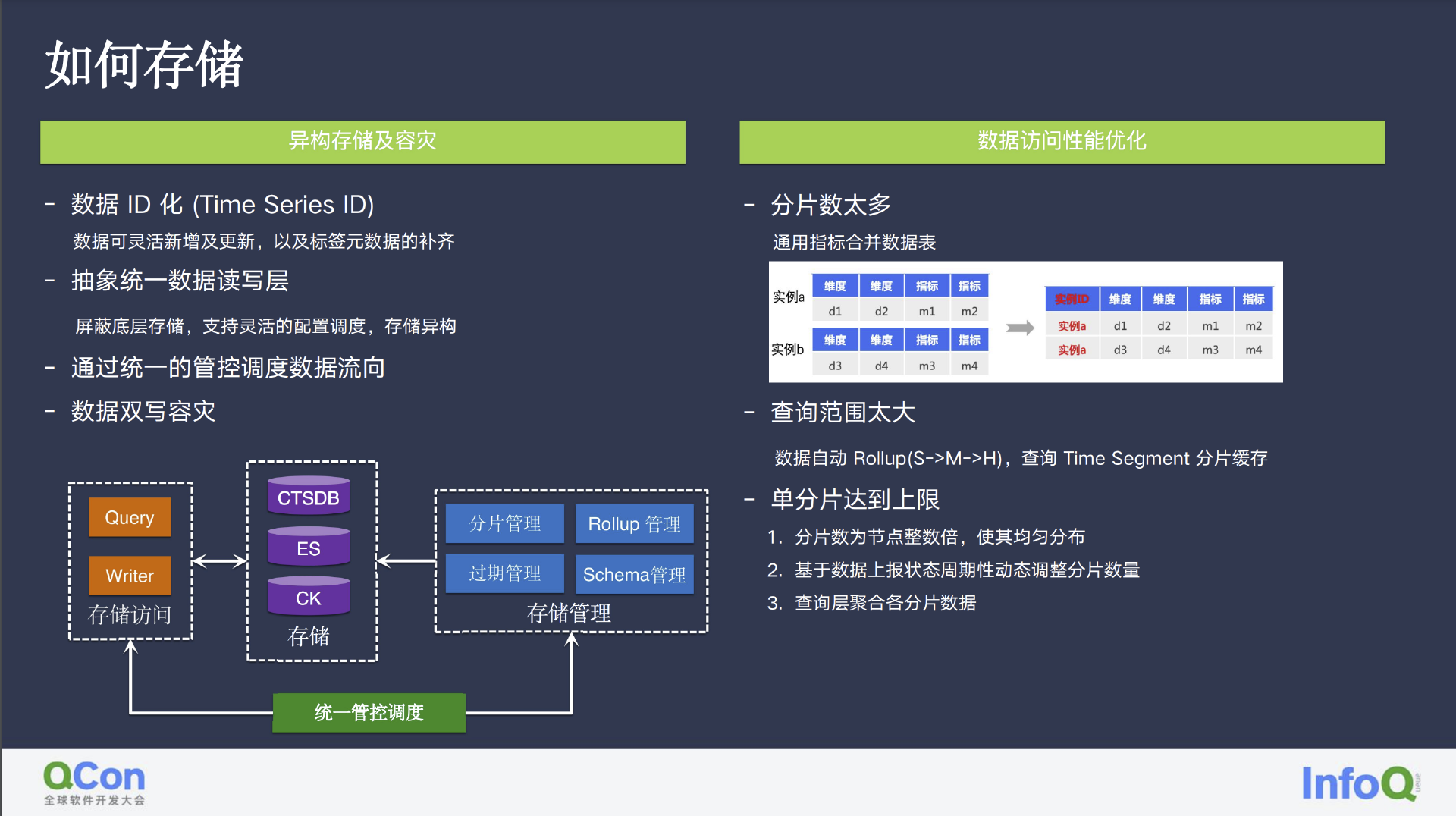
此外,我们也统一了数据查写的方式,这里就涉及到了异构存储的上层查询、ES 动态分片、监控数据 TTL 及时间的计算。我们还针对大范围数据查询的自动 Rollup,在查询时按时间分片聚合,将告警等静态数据缓存等等。沿用流处理的思路,我们限制了分片上限,并基于数据的周期性进行动态分片调整。
简而言之,我们在采集和存储阶段确保输入输出数据的标准化,计算阶段通用化,让研发和产品都可简单通过 POC 写 SQL 等等。
一体化可观测
图中所示是腾讯云目前的可观测平台,我们可以看到其中包含了拨测、用户端、web、小程序等各种语言,应用了各类协议和云产品,以及后续对数据的运用、处理数据的存储,以及产品的运用形式。

以 RUM 为例,我们可以直观地看到前端的每一次请求情况、行业数据、可观测标准、数据采集、主要请求量、环比问题等等,允许我们通过前端的监控和日志,快速对接后端的服务异常。
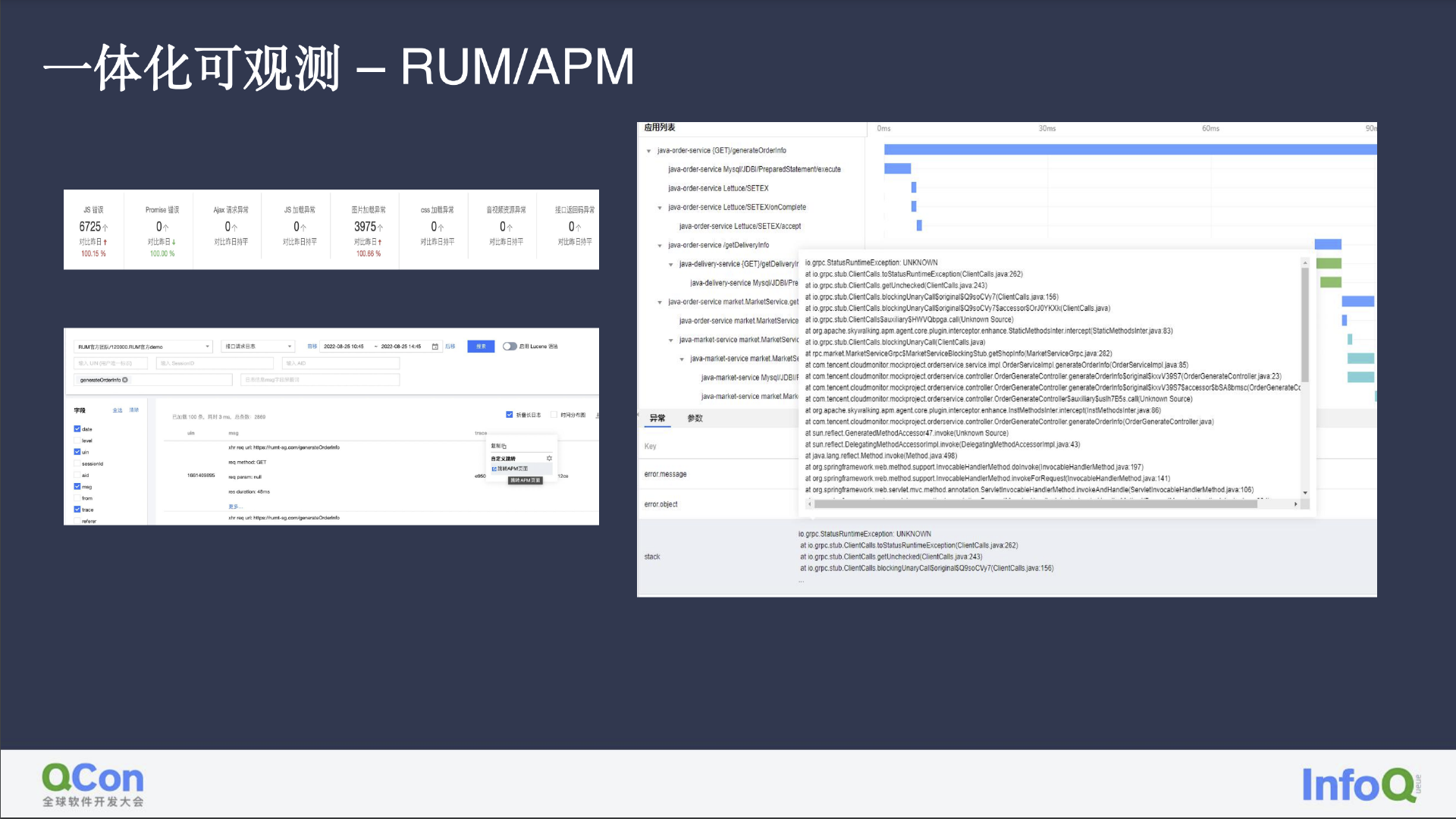

因为我们所有的数据均是由 Trace 产生,因此正如图中所示,我们能直观地看到服务的吞吐量、延时等情况,找到出现异常的链路环节及 Trace 日志,进而在告警出现后快速得出异常根因。
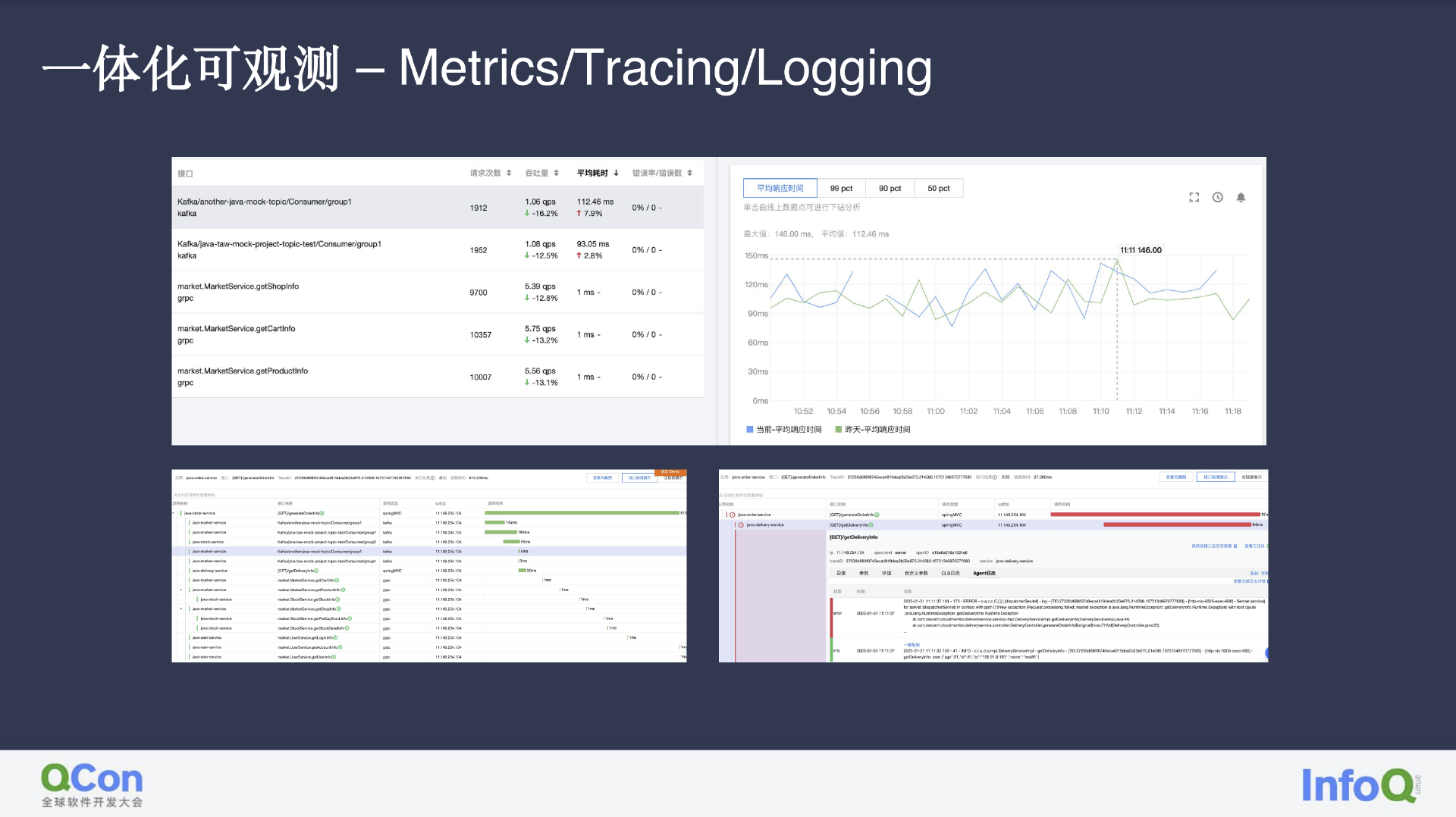
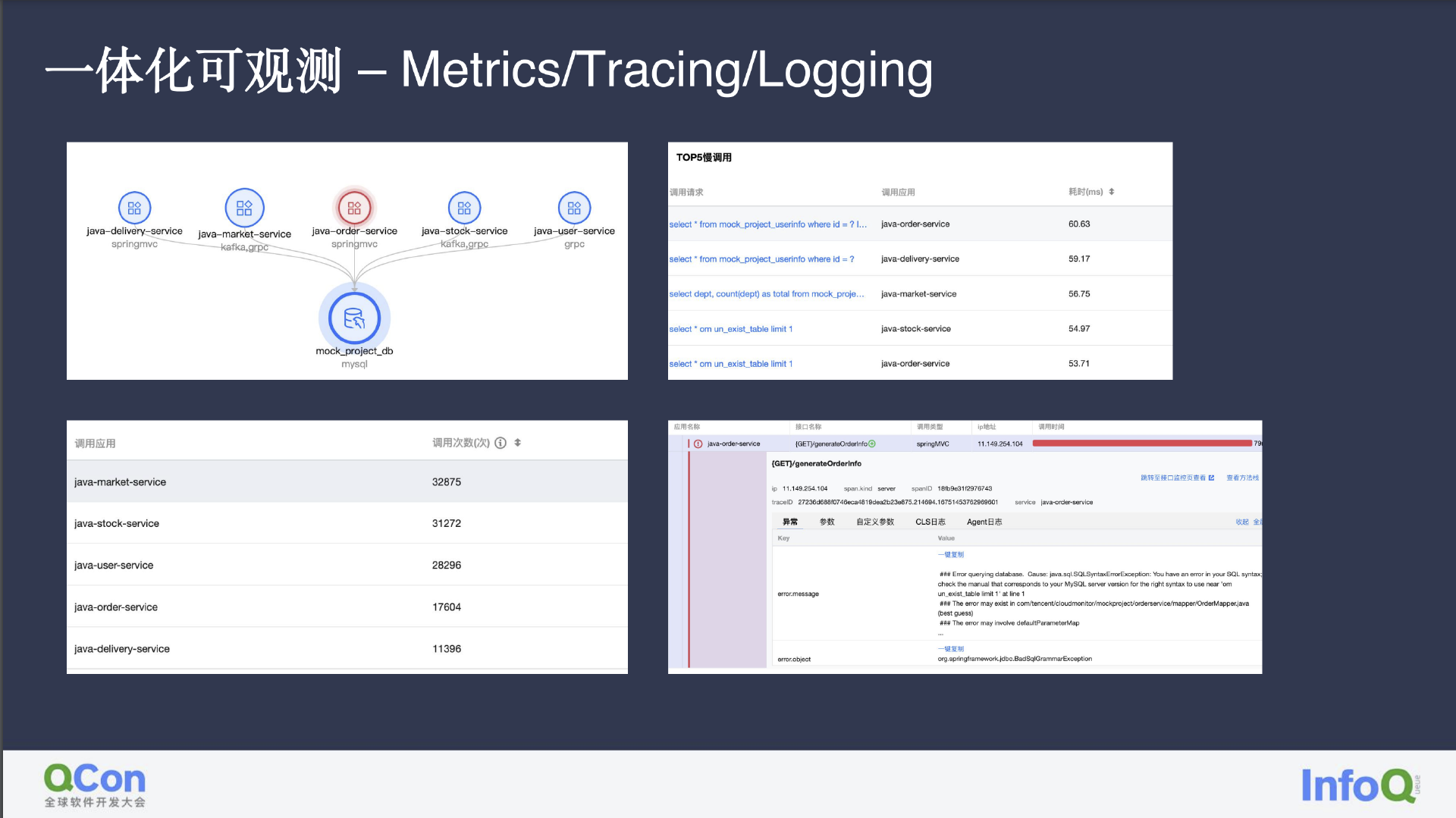
在 DBA 发现数据库出现问题后,我们也可以发现受到影响的服务,如数据库中有哪些慢 SQL 对服务造成影响、服务访问的 DB 出现异常等等。
总结展望
正是有了目前社区中数据的标准化,才能为我们的 AIOps 奠定基础,从而允许云厂商或可观测平台能将精力聚焦于产品能力和成本之上。
相关阅读:

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论