

一、疫情带来的挑战
今年疫情带来的挑战很明显,远程办公和在线教育用户暴涨,从 1 月 29 到 2 月 6 日,日均扩容 1.5w 台主机。业务 7×24 小时不间断服务,远程办公和在线教育要求不能停服,停服一分钟都会影响成百上千万人的学习和工作,所以这一块业务对于我们的要求非常高。
在线会议和远程办公都大量使用了 redis,用户暴增的腾讯会议背后也有腾讯云Redis提供支持,同时海量请求对 redis 的快速扩容能力提出了要求。我们有的业务实例,从最开始的 3 片一天之内扩容到 5 片,紧接着发现还是不够,又扩到 12 片,第二天继续扩。

二、开源 Redis 扩容方案
1. 腾讯云 Redis 的集群版架构
腾讯云 Redis 跟普遍 Redis 有差别,我们加入了 Proxy,提高了系统的易用性,这个是因为不是所有的语言都支持集群版客户端。
为了兼容这部分客户,我们做了很多的兼容性处理,能够兼容更多普通客户端使用,像做自动的路由管理,切换的时候可以自由处理 MOVE 和 ASK,增加端到端的慢查询统计等功能,Redis 默认的 slowlog 只包含命令的运算时间,不包括网络来回的时间,不包括本地物理机卡顿导致的延时,Proxy 可以做端到端的慢日志统计,更准确反应业务的真实延迟。
对于多帐户,Redis 不支持,现在把这部分功能也挪到 Proxy,还有读写分离,这个对于客户非常有帮助,客户无须敲写代码,只需要在平台点一下,我们在 Proxy 自动实现把读写派发上去。
这一块功能放到 Redis 也是可以,那为什么做到 Proxy 呢?主要是考虑安全性!因为 Redis 承载用户数据,如果在 Redis 做数据会频繁升级功能迭代,这样对于用户数据安全会产生比较大的威胁。
2. 腾讯云 Redis 如何扩容
腾讯云 Redis 怎么扩容呢?我们的扩容从三个维度出发,单个节点容量扩容, 比如说三分片,每个片 4G,我们可以每节点扩到 8G。单节点容量扩容,一般来说只要机器容量足够,就可以扩容上去。
还有副本扩容,现在客户使用的是一主一从,有的同学开读写分离,把读全部打到从机,这种情况下,增加读 qps 比较简单的方法就是增加副本的数量,还增加了数据安全性。
最近的实际业务,我们遇到的主要是扩分片。
对于集群分片数,最主要就是 CPU 的处理能力,扩容分片就是相当于扩展 CPU,扩容处理能力也间接扩容内存。

最早腾讯云做过一个版本,利用开源的原生版的扩容方式扩容。
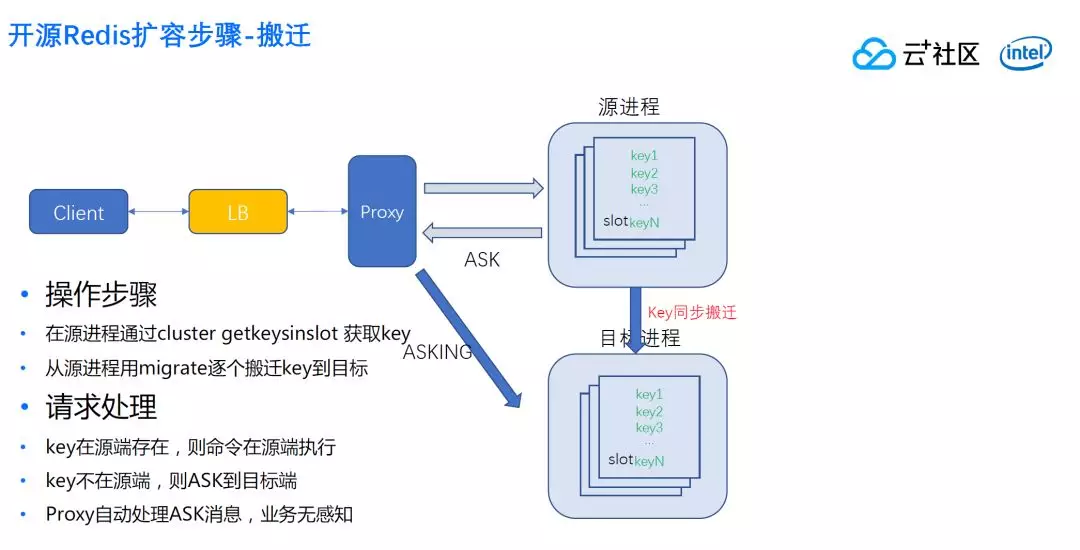
简单描述一下操作步骤:首先 Proxy 是要做 slot 容量计算,否则一旦搬迁过去,容易把新分片的内存打爆。
计算完每个 slot 内存后,按照算法分配,决定好目标分片有哪些 slot。
先设置目标节点 slot 为 importing 状态 ,再设置源节点的 slot 为 migrating 状态。
这里存在一个小坑,在正常开发中这两个设置大家感觉顺序无关紧要,但是实际上有影响。
如果先设置源节点的 slot 为 migrating,再设置目标节点的 slot 为 importing,那么在这两条命令的执行间隙,如果有对应 slot 的命令打到源节点,而 key 又恰好不存在,则会重定向到目标节点,由于目标节点此时 slot 并未来得及设置为 importing, 又会把这条命令重定向给源节点,这样就无限重定向了。
好在常见的客户端(比如 jedis)对重定向次数是有限制的, 一旦打到上限,就会抛出错误。
(1)准备

(2)搬迁
设置完了这一步,下一步就是搬迁。从源节点来获取 slot 的搬迁,从源进程慢慢逐个搬迁到目标节点。
此操作是同步的,什么意思呢?在 migrate 命令结束之前进程不能直接处理客户请求,实际上是源端临时创建一个 socket,连接目标节点,同步执行命令,确认执行成功了后,把本地的 Key 删掉,这个时候源端才可以继续处理客户新的请求。
在搬迁过程中,整个集群仍然是可以处理请求的。这一块开源 Redis 有考虑,如果这个时候有 Key 读请求,刚好这个 slot 发到源进程,进程可以判断,如果这个 Key 在本进程有数据,就会当正常的请求返回给它。
那如果不存在怎么办?就会发一个 ASK 给客户,用户收到 ASK 知道这个数据不在这个进程上,马上重新发一个 ASKING 到目标节点,紧接着把命令发到那边去。
这样会有一个什么好处呢?源端的 Key 的 slot 只会慢慢减少,不会增加,因为新增加的都发到目标节点去了。随着搬迁的持续,源端的 Key 会越来越少,目标端的 key 逐步增加,用户感知不到错误,只是多了一次转发延迟,只有零点零几毫秒,没有特别明显的感知。
(3)切换
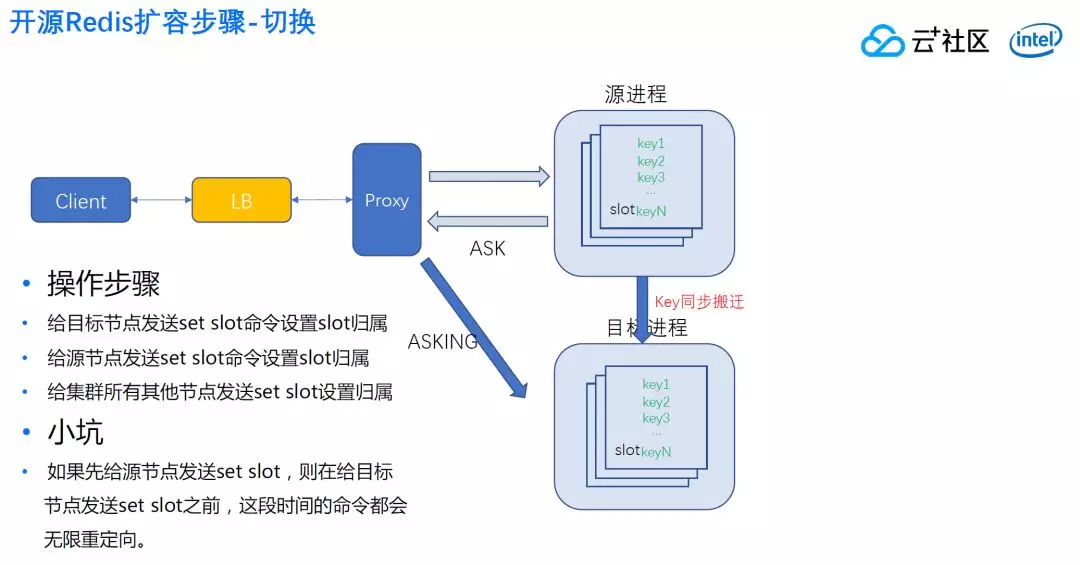
方案到什么时候切换呢?就是 slot 源进程发现这个 slot 已经不存在数据了,说明所有数据全部搬到目标进程去了。
这个时候怎么办呢?先发送 set slot 给目标,然后给源节点发送 set slot 命令,最后给集群所有其他节点发送 set slot。这是为了更快速把路由更新过去,避免通过自身集群版协议推广,降低速度。
这里跟设置迁移前的准备步骤是一样,也有一个小坑需要注意。
如果先给源节点设置 slot,源节点认为这个 slot 归属目标节点,会给客户返回 move,这个是因为源节点认为 Key 永久归属目标进程,客户端搜到 move 后,就不会发 ASKing 给目标,目标如果没有收到 ASK,就会把这个消息重新返回源进程,这样就和打乒乓球一样,来来回回无限重复,这样客户就会感觉到这里有错误。
三、 无损扩容挑战
1. 大 Key 问题
像这样迁移其实也没有问题,客户也不会感觉到正常的访问请求的问题。
但是依然会面临一些挑战,第一就是大 Key 的问题。前文提到的搬迁内部,由于这个搬迁是同步的搬迁,同步搬迁会卡住,这个卡住时间由什么决定的?
主要不是网速,而是搬迁 Key 的大小来决定的,由于搬迁是按照 key 来进行的,一个 list 也是一个 Key,一个哈希表也是 Key,一个 list 会有上千万的数据,一个哈希表也会有很多的数据。
同步搬迁容易卡非常久,同步搬迁 100 兆,打包有一两秒的情况,客户会觉得卡顿一两秒,所有访问都会超时,一般 Redis 业务设置超时大部分是 200 毫秒,有的是 100 毫秒。如果同步搬移 Key 超过一秒,就会有大量的超时出现,客户业务就会慢。
如果这个卡时超过 15 秒,这个时间包括搬迁打包时间、网络传输时间、还有 loading 时间。超过 15 秒,甚至自动触发切换,把 Master 判死,Redis 会重新选择新的 Master,由于 migrating 状态是不会同步给 slave 的,所以 slave 切换成 master 后,它身上是没有 migrating 状态的。
然后,正在搬迁的目标节点会收到新的 master 节点对这个 slot 的所有权声明, 由于这个 slot 是 importing 的,所以它会拒绝承认新 master 拥有这个 slot。从而在这个节点看来,slot 的覆盖是不全面的, 有的 slot 无节点提供服务,集群状态为 fail。
一旦出现这种情况,假如客户继续在写,由于没有 migrating 标记了,新 Key 会写到源节点上,这个 key 可能在目标节点已经有了,就算人工处理,也会出现哪一边的数据比较新, 应该用哪一边的数据, 这样的一些问题,会影响到用户的可用性和可靠性。
这是整个开源 Redis 的核心问题,就是容易卡住,不提供服务,甚至影响数据安全。
开源版如何解决这个问题呢?老规矩:惹不起就躲,如果这个 slot 有最大 Key 超过 100M 或者 200M 的阈值不搬这个 slot。
这个阈值很难设置,由于 migrate 命令一次迁移很多个 key,过小的阈值会导致大部分 slot 迁移不了,过大的阈值还是会导致卡死,所以无论如何对客户影响都非常大,而且这个影响是不能被预知的,因为这个 Key 大小可以从几 k 到几十兆,不知道什么时候搬迁到大 key 就会有影响,只要搬迁未结束,客户在相当长时间都心惊胆战。

2. Lua 问题
除了 Key 的整体搬迁有这样问题以外,我们还会有一个问题就是 Lua。
假如业务启动的时候通过 script load 加载代码,执行的时候使用 evalsha 来,扩容是新加了一个进程,对于业务是透明,所以按照 Redis 开源版的办法搬迁 Key,key 搬迁到目标节点了,但是 lua 代码没有,只要在新节点上执行 evalsha,就会出错。
这个原因挺简单,就是 Key 搬迁不会迁移代码,而且 Redis 没有命令可以把 lua 代码搬迁到另外一个进程(除了主从同步)。
这个问题在开源版是无解,最后业务怎么做才能够解决这个问题呢?
需要业务那边改一下代码,如果发现 evalsha 执行出现代码不存在的错误,业务要主动执行一个 script load,这样可以规避这个问题。
但是对很多业务是不能接受的。
因为要面临一个重新加代码然后再发布这样一个流程,业务受损时间是非常长的。

3. 多 Key 命令/Slave 读取
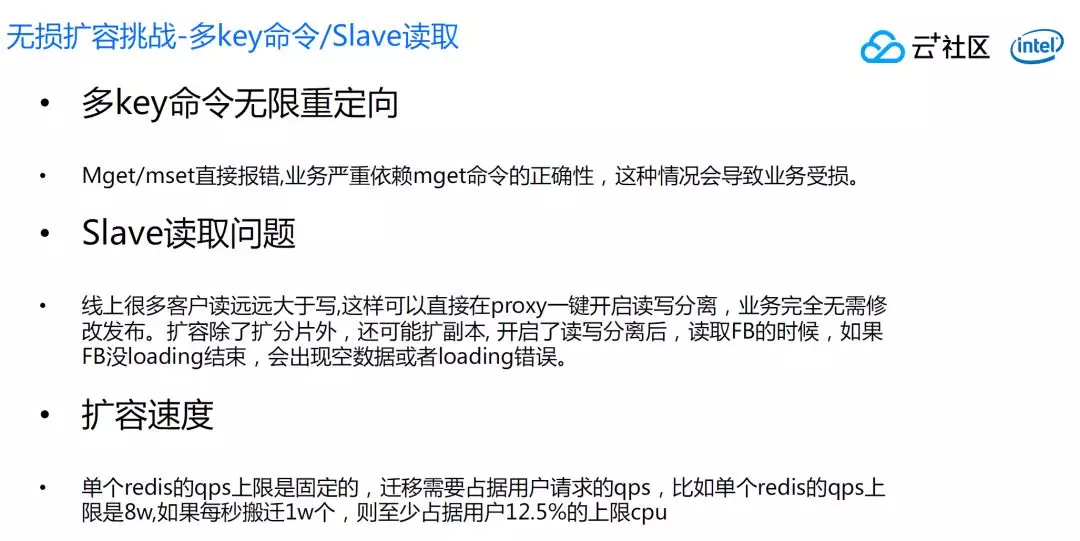
还有一个挑战,就是多 Key 命令,这个是比较严重的问题,Mget 和 mset 其中一个 Key 在源进程,另外一个 Key 根本不存在或者在目标进程,这个时候会直接报错,很多业务严重依赖于 mget 的准确性,这个时候业务是不能正常工作的。
这也是原生版 redis 没有办法解决的问题,因为只要是 Key 搬迁,很容易出现 mget 的一部分 key 在源端,一部分在目标端。
除了这个问题还有另一个问题,这个问题跟本身分片扩容无关,但是开源版本存在一个 bug,就是我们这边 Redis 是提供了一个读写分离的功能,在 Proxy 提供这个功能,把所有的命令打到 slave,这样可以降低 master 的性能压力。
这个业务用得很方便,业务想起来就可以开启,发现不行就可以马上关闭。
这里比较明显的问题是:当每个分片数据比较大的时候,举一个例子 20G、30G 的数据量的时候,我们刚开始挂 slave,slave 身份推广跟主从数据是两个机制,可能 slave 已经被集群认可了,但是还在等 master 的数据,因为 20G 数据的打包需要几分钟(和具体数据格式有关系)。
这个时候如果客户的读命令来到这个 slave, 会出现读不到数据返回错误, 如果客户端请求来到的时候 rdb 已经传到 slave 了,slave 正在 loading, 这个时候会给客户端回 loading 错误。
这两个错误都是不能接受,客户会有明显的感知,扩容副本本来为了提升性能,但是结果一扩反而持续几分种到十几分钟内出现很多业务的错误。
这个问题其实是跟 Redis 的基本机制:身份推广机制、主从数据同步机制有关,因为这两个机制是完全独立的,没有多少关系,问题的解决也需要我们修改这个状态来解决,下文会详细展开。
最后一点就是扩容速度。前文说过,Redis 通过搬 Key 的方式对业务是有影响的,由于同步操作,速度会比较慢,业务会感受到明显的延时,这样的延时业务肯定希望越快结束越好。
但是我们是搬迁 Key,严重依赖 Key 的速度。因为搬 Key 不能全速搬,Redis 是单线程,基本上线是 8 万到 10 万之间,如果搬太快,就占据用户 CPU。
用户本来因为同步搬迁卡顿导致变慢,搬迁又要占他 CPU,导致雪上加霜,所以一般这种方案是不可能做特别快的搬迁。比如说每次搬一万 Key,相当于占到 12.5%,甚至更糟,这对于用户来说是非常难以接受的。
四、行业其他方案
既然开源版有这么多问题,为什么不改呢?不改的原因这个问题比较多。可能改起来不容易,也确实不太容易。
关于搬迁分片扩容是 Redis 的难点,很多人反馈过,但是目前而言没有得到作者的反馈,也没有一个明显的解决的趋势,行业内最常见就是 DTS 方案。
DTS 方案可以通过下图来了解,首先通过 DTS 建立同步,DTS 同步跟 Redis-port 是类似,会伪装一个 slave,通过 sync 或者是 psync 命令从源端 slave 发起一次全量同步,全量之后再增量,DTS 接到这个数据把 rdb 翻译成命令再写入目标端的实例上,这样就不要求目标和源实例的分片数目一致,dts 在中间把这个活给干了。
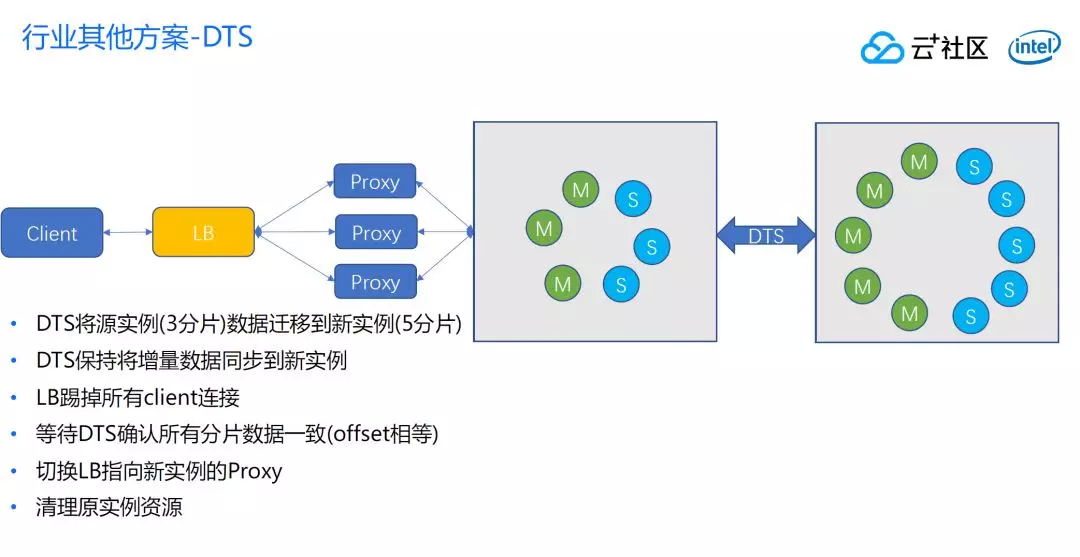
等到 DTS 完全迁移稳定之后,就可以一直同步增量数据,不停从源端 push 目标端,这时候可以考虑切换。
切换首先观察是不是所有 DTS 延迟都在阈值内,这个延迟指的是从这边 Master 到那边 Master 的中间延迟。如果小于一定的数据量,就可以断连客户端,等待一定时间,等目标实例完全追上来了,再把 LB 指向新实例,再把源实例删除了。一次扩容就完全实现了,这是行业比较常见的一种方案。
DTS 方案解决什么问题呢?大 Key 问题得到了解决。因为 DTS 是通过源进程 slave 的一个进程同步的。
Lua 问题有没有解决?这个问题也解决了,DTS 收到 RDB 的时候就有 lua 信息了,可以翻译成 script load 命令。多 Key 命令也得到了解决,正常用户访问不受影响,在切换之前对用户来说无感知。
迁移速度也能够得到比较好的改善。迁移速度本身是因为原实例通过 rdb 翻译,翻译之后并发写入目标实例,这样速度可以很快,可以全速写。
这个速度一定比开源版 key 搬迁更快,因为目标实例在切换前不对外工作,可以全速写入,迁移速度也是得到保证。
迁移中的 HA 和可用性和可靠性也都还可以。当然中间可用性要断连 30 秒到 1 分钟,这个时间用户不可用,非常小的时间影响用户的可用性。

DTS 有没有缺点?有!首先是其复杂度,这个迁移方案依赖于 DTS 组件,需要外部组件才能实现,这个组件比较复杂,容易出错。
其次是可用性,前文提到步骤里面有一个踢掉客户端的情况,30 秒到 1 分钟这是一般的经验可用性影响,完全不可访问。
还有成本问题,迁移过程中需要保证全量的 2 份资源,这个资源量保证在迁移量比较大的情况下,是非常大的。
如果所有的客户同时扩容 1 分片,需要整个仓库 2 倍的资源, 否则很多客户会失败,这个问题很致命,意味着我要理论上要空置一半的资源来保证扩容的成功, 对云服务商来说是不可接受的,基于以上原因我们最后没有采用 DTS 方案。

五、腾讯云 Redis 扩容方案
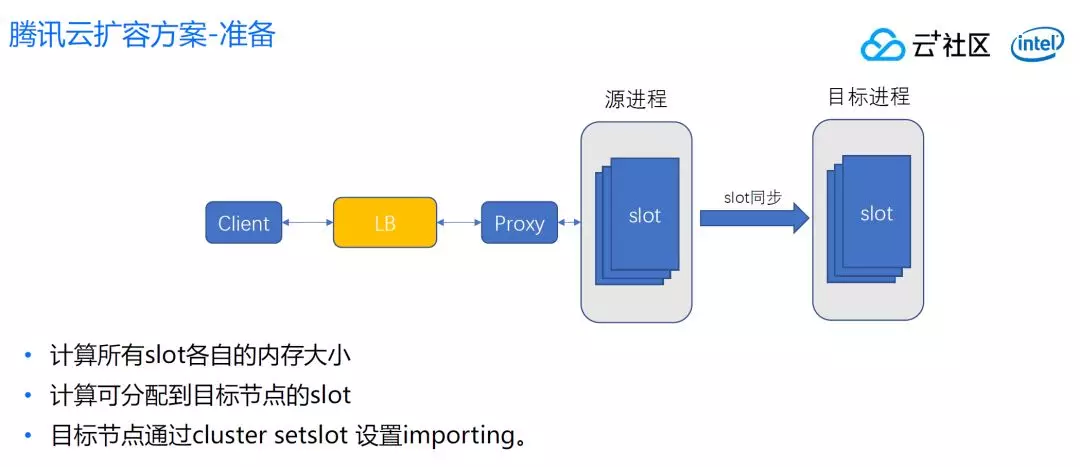
我们采用方案是这样的,我们的目标是首先不依赖第三方组件,通过命令行也可以迁。第二是我们资源不要像 DTS 那样迁移前和迁移后两份资源都要保留,这个对于我们有相当大的压力。最后用的是通过 slot 搬迁的方案。具体步骤如下:
首先还是计算各 slot 内存大小,需要计算具体搬迁多少 slot。分配完 slot 之后,还要计算可分配到目标节点的 slot。
跟开源版不一样,不需要设置源进程的 migrating 状态,源进程设置 migrating 是希望新 Key 自动写入到目标进程,但是我们这个方案是不需要这样做。
再就是在目标进程发起 slot 命令,这个命令执行后,目标节点根据 slot 区间自动找到进程,然后对它发起 sync 命令(带 slot 的 sync),源进程收到这个 sync 命令,执行一个 fork,将所有同步的 slot 区间所有的数据生成 rdb,同步给目标进程。
每一个 slot 有哪一些 Key 在源进程是有记录的,这里遍历将每一个 slot 的 key 生成 rdb 传输给目标进程,目标进程接受 rdb 开始 loading,然后接受 aof,这个 aof 也是接受跟 slot 相关的区间数据,源进程也不会把不属于这个 slot 的数据给目标进程。
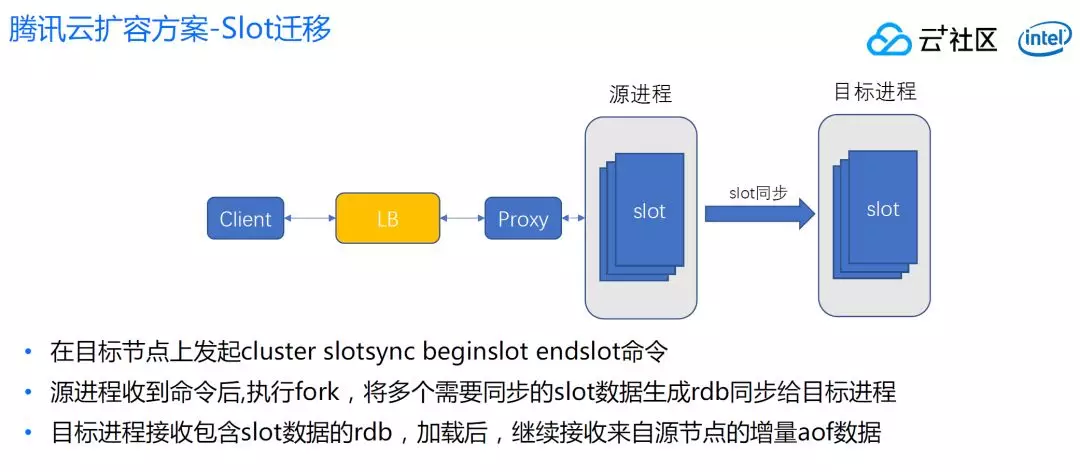
一个目标进程可以从一两个源点建立这样的连接,一旦全部建立连接,并且同步状态正常后,当 offset 足够小的时候,就可以发起 failover 操作。
和 Redis 官方主动 failover 机制一样。在 failover 之前,目标节点是不提供服务的,这个和开源版有巨大的差别。
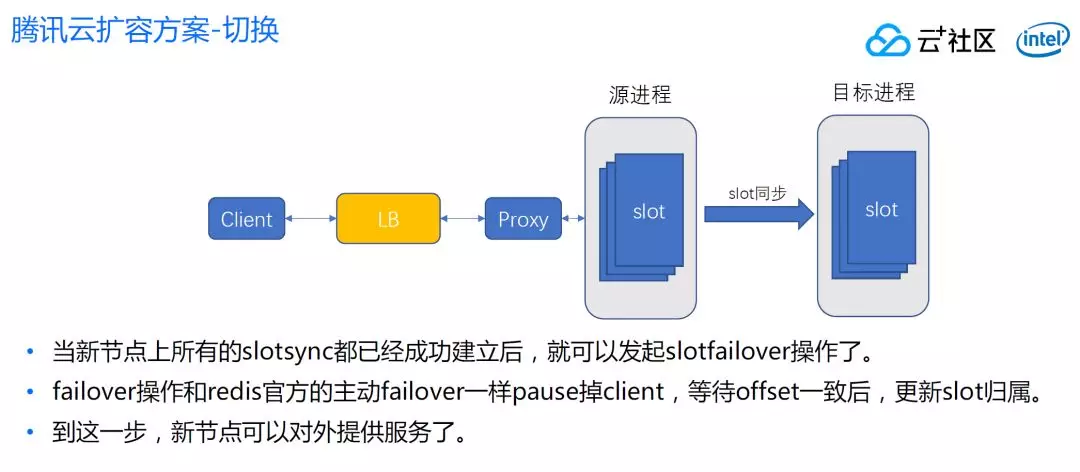
通过这个方案,大 Key 问题得到了解决。因为我们是通过 fork 进程解决的,而不是源节点搬迁 key。切换前不对外提供服务,所以 loading 一两分钟没有关系,客户感知不到这个节点在 loading。
还有就是 Lua 问题也解决了,新节点接受的是 rdb 数据,rdb 包含了 Lua 信息在里面。还有多 Key 命令也是一样,因为我们完全不影响客户正常访问,多 Key 的命令以前怎么访问现在还是怎么访问。迁移速度因为是批量 slot 打包成 rdb 方式,一定比单个 Key 传输速度快很多。
关于 HA 的影响,迁移中有一个节点挂了会不会有影响?开源版会有影响,如果 migrating 节点挂了集群会有一个节点是不能够对外提供服务。
但我们的方案不存在这个问题,切换完了依然可以提供服务。因为我们本来目标节点在切换之前就是不提供服务的。
还有可用性问题,我们方案不用断客户端连接,客户端从头到尾没有受到任何影响,只是切换瞬间有小影响,毫秒级的影响。
成本问题有没有解决?这个也得到解决,因为扩容过程中,只创建最终需要的节点,不会创建中间节点,零损耗。

作者介绍:
伍旭飞,腾讯云高级工程师,腾讯云 Redis 技术负责人,有多年和游戏和数据库开发应用实践经验, 聚焦于游戏开发和 NOSQL 数据库在各个领域的应用实践。
本文转载自公众号云加社区(ID:QcloudCommunity)。
原文链接:
https://mp.weixin.qq.com/s/nKCw_a5mU9sn7SPKmCn-OQ

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论 3 条评论