

在深度学习模型发展史中,残差网络因其简单而有效的结构与异常有效的结果而占据了非常重要的位置,今天就来仔细说说它的来龙去脉。
残差网络之前的历史
残差连接的思想起源于中心化,在神经网络系统中,对输入数据等进行中心化转换,即将数据减去均值,被广泛验证有利于加快系统的学习速度。
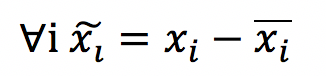
Schraudolph[1]将这样的思想拓展到了梯度的反向传播中,不仅是输入和隐藏层单元的激活值要中心化,梯度误差以及权重的更新也可以中心化,这便是通过将输入输出进行连接的 shortcut connection,也称为跳层连接技术。
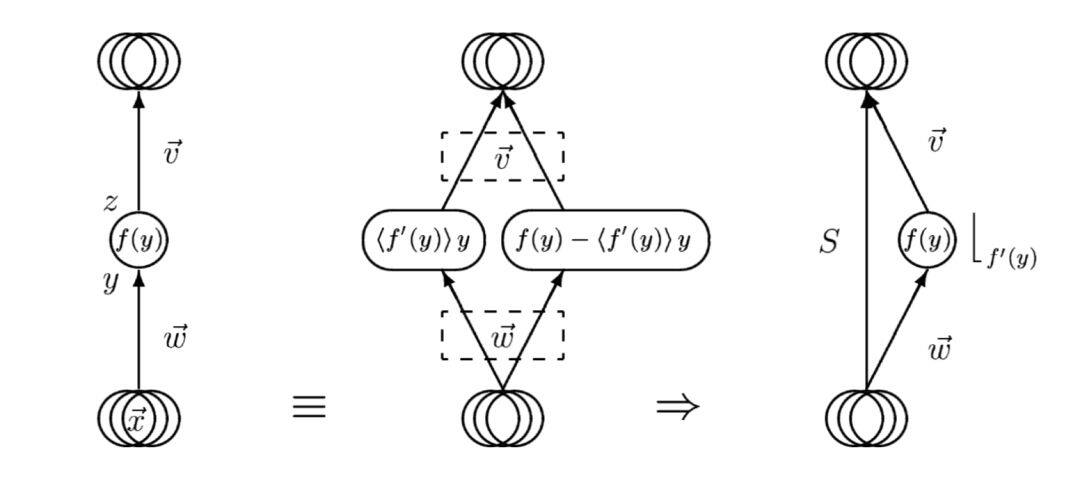
在 1998 年的时候,它们提出了将网络分解为 biased 和 centered 两个子网络的思想,通过并行训练两个子网络,分别学习线性和非线性变换部分,不仅降低了各个网络的学习难度,也大大提升了梯度下降算法的训练速度。
Raiko 等人则在论文[2]中更加细致地研究了 shortcut connections 对模型能力的影响,在网络包含 2 到 5 个隐藏层,使用与不使用正则化等各种环境配置下,MNIST 和 CIFAR 图像分类任务和 MNIST 图像重构任务的结果都表明,这样的技术提高了随机梯度下降算法的学习能力,并且提高了模型的泛化能力。
Srivastava 等人在 2015 年的文章[3]中提出了 highway network,对深层神经网络使用了跳层连接,明确提出了残差结构,借鉴了来自于 LSTM 的控制门的思想。
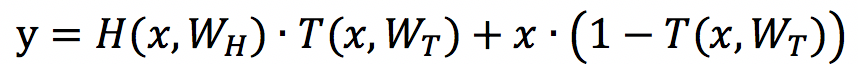
当 T(x,Wt)=0 时,y=x,T(x,Wt)=1 时,y=H(x,Wh)T(x,Wt)。在该文章中,研究者没有使用特殊的初始化方法等技巧,也能够训练上千层的网络。
从以上的发展可以看出来,跳层连接由来已久。
残差网络
何凯明等人在 2015 年的论文[4]中正式提出了 ResNet,简化了 highway network 中的形式,表达式如下:
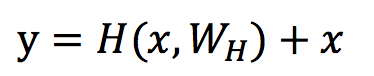
相比于之前的卷积和池化相互堆叠的网络,其基本的结构单元如下:
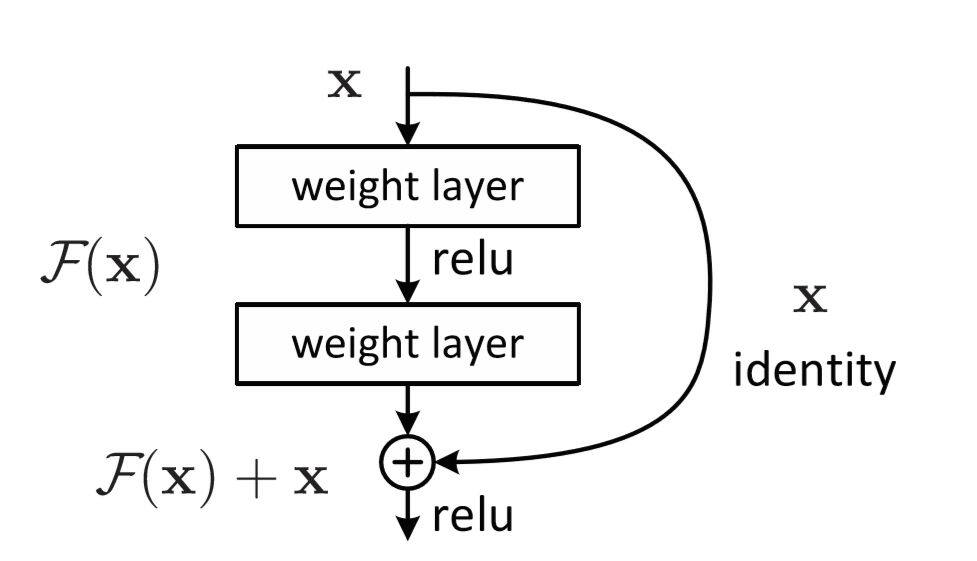
当我们直接将一个输入添加到输出的时候,输出 y 可以明确的拆分为 H(x,Wh)和 x 的线性叠加,从而让梯度多了一条恒等映射通道,这被认为对于深层网络的训练是非常重要的,一个典型的 resnet 网络结构如下:
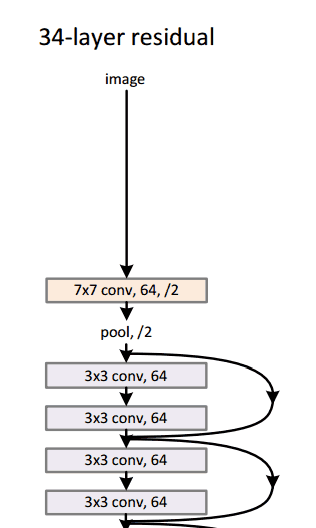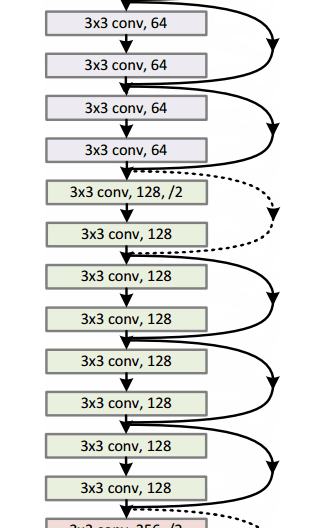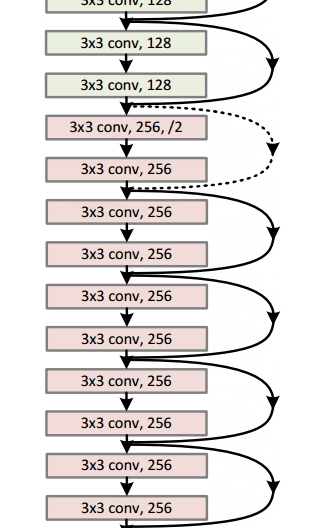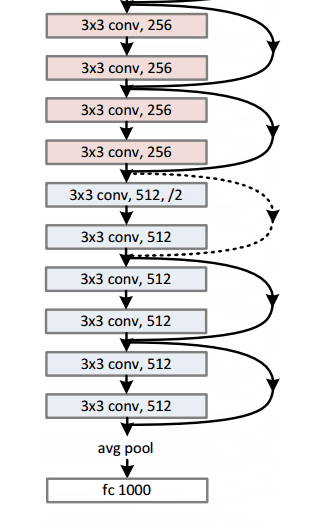
resnet 在当年的 ImageNet 的多项竞赛中取得冠军,风头一时无两,随后被广泛深扒。关于 ResNet 的详细解读,大家可以关注往期文章—《 模型解读】resnet中的残差连接,你确定真的看懂了?》
残差网络结构的发展
对于残差网络的研究,大部分集中在两个方向,第一个是结构方面的研究,另一个是残差网络原理的研究,首先说几个具有代表性的结构,不会将所有结构都包含进来,如果感兴趣大家可以关注知识星球有三 AI。
更密集的跳层连接 DenseNet
如果将 ResNet 的跳层结构发挥到极致,即每两层都相互连接,那么就成为了 DenseNet,关于 DenseNet 的详细解读,可以查看我们的往期文章—《 「模型解读」 “全连接”的卷积网络,有什么好?》
DenseNet 是一个非常高效率的网络结构,以更少的通道数更低的计算代价,获得比 ResNet 更强大的性能。
更多并行的跳层连接
如果将 ResNet 和 DenseNet 分为作为两个通道并行处理,之后再将信息融合,就可以得到 Dual Path Network,网络结构如下:
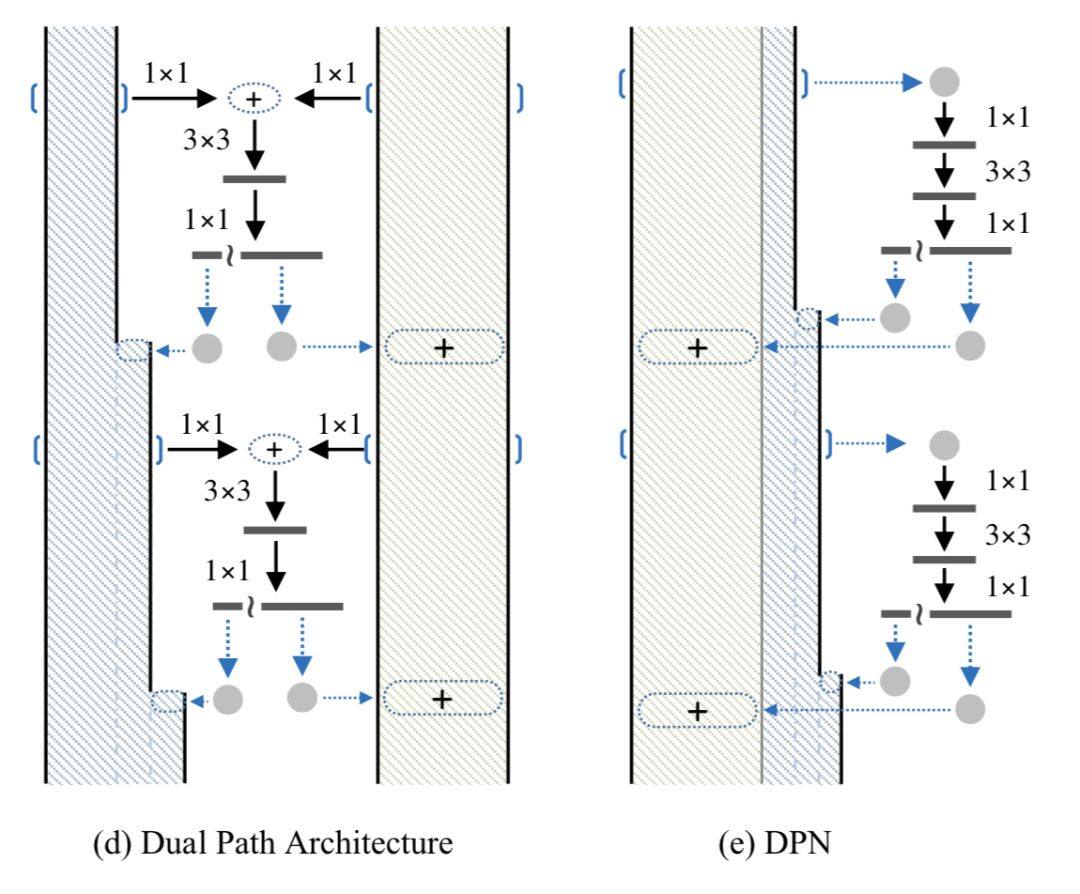
其背后的思想是 resnet 对于重用信息更有效,而 densenet 对于学习新的信息更有效,这个结构在最后一届 ImageNet 竞赛中也取得了很好的成绩,分类比赛的亚军,定位比赛的冠军。类似的结构变种还有如下的结构,不再一一赘述。
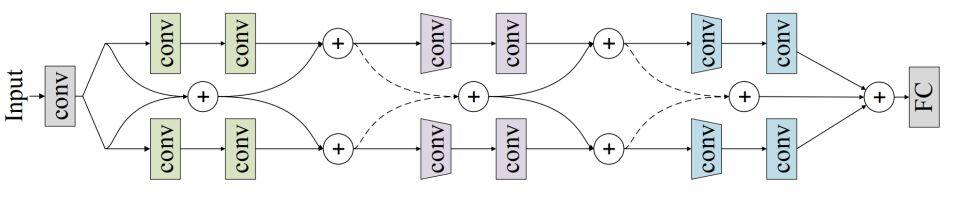
当然,还有比上面的 Dual Path Network 更加简单的并行结构,即直接使用多个完全独立且相同的分支并行处理,然后合并。
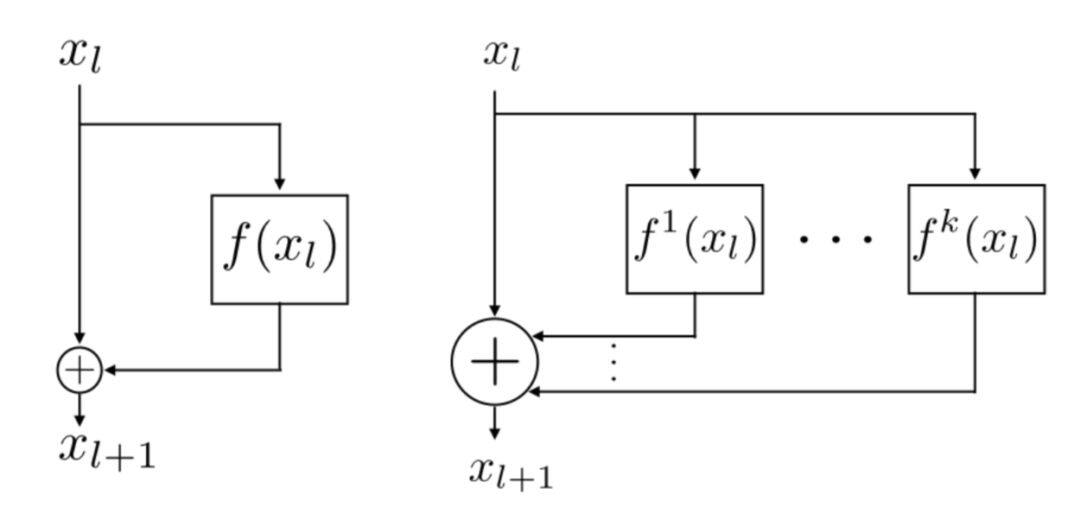
也有更加复杂的变种,即所谓的 resnet in resnet 结构,如下图。
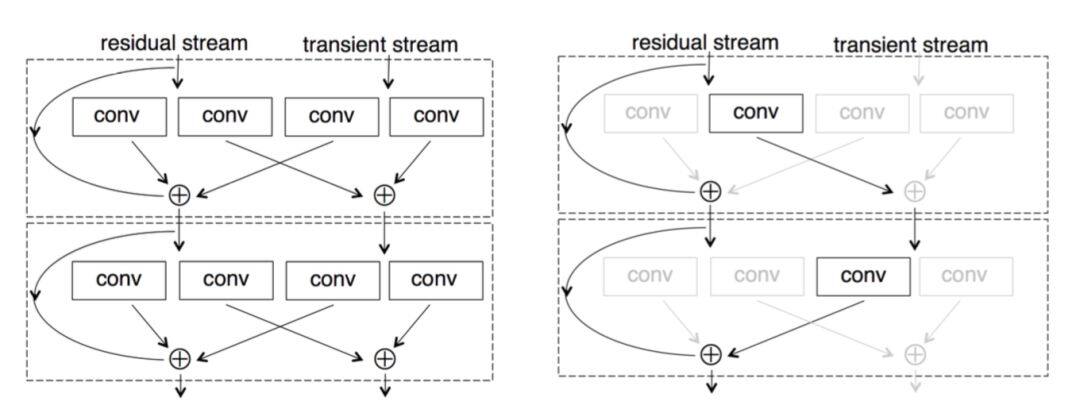
残差网络结构为什么这么好用?
关于残差网络为什么有效,研究众多,这里我们就集中讲述几个主流的思路。
简化了学习过程,增强了梯度传播
相比于学习原始的信号,残差网络学习的是信号的差值,这在许多的研究中被验证是更加有效的,它简化了学习的过程。
根据我们前面的内容可知,在一定程度上,网络越深表达能力越强,性能越好。
然而随着网络深度的增加,带来了许多优化相关的问题,比如梯度消散,梯度爆炸。
在残差结构被广泛使用之前,研究人员通过研究更好的优化方法,更好的初始化策略,添加 Batch Normalization,提出 Relu 等激活函数的方法来对深层网络梯度传播面临的问题进行缓解,但是仍然不能解决根本问题。
假如我们有这样一个网络:
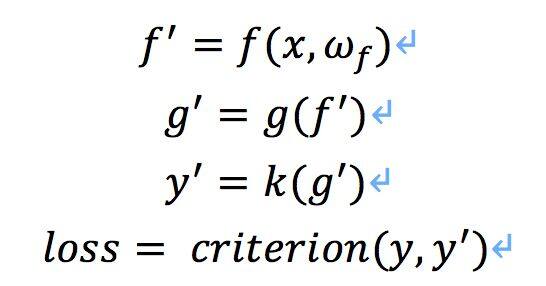
其中 f 为卷积操作,g 为非线性变换函数,k 为分类器,依靠误差的链式反向传播法则,损失 loss 对 f 的导数为:
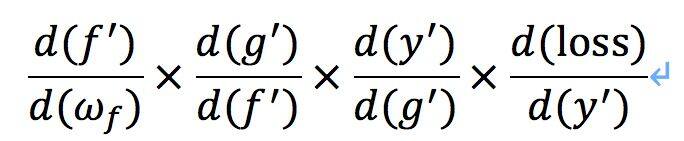
如果其中某一个导数很小,多次连乘后梯度可能越来越小,这就是常说的梯度消散,对于深层网络,从靠近输出的深层传到靠近输入的浅层时梯度值非常小,使得浅层无法有效地更新。
如果使用了残差结构,因为导数包含了恒等项,仍然能够有效的反向传播。
举一个非常直观的例子方便理解,假如有一个网络,输入 x=1,非残差网络为 G,残差网络为 H,其中 H(x)=F(x)+x,假如有这样的输入关系:
因为两者各自是对 G 的参数和 F 的参数进行更新,可以看出变化对 F 的影响远远大于 G,说明引入残差后的映射对输出的变化更敏感,这样是有利于网络进行传播的。
打破了网络的不对称性
虽然残差网络可以通过跳层连接,增强了梯度的流动,从而使得上千层网络的训练成为可能,不过相关的研究表面残差网络的有效性,更加体现在减轻了神经网络的退化。
如果在网络中每个层只有少量的隐藏单元对不同的输入改变它们的激活值,而大部分隐藏单元对不同的输入都是相同的反应,此时整个权重矩阵的秩不高。并且随着网络层数的增加,连乘后使得整个秩变的更低,这就是我们常说的网络退化问题。
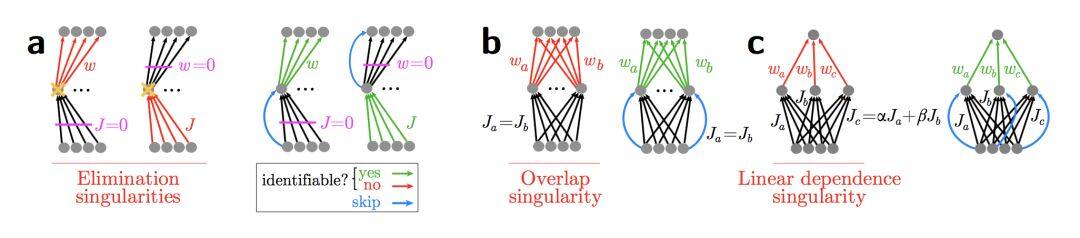
虽然权重矩阵是一个很高维的矩阵,但是大部分维度却没有信息,使得网络的表达能力没有看起来那么强大。这样的情况一定程度上来自于网络的对称性,而残差连接打破了网络的对称性。
下面展示了三种跳层连接恢复网络表达能力的案例,分别是消除输入和权重零奇点,打破对称性,线性依赖性。
增强了网络的泛化能力
有一些研究表明,深层的残差网络可以看做是不同深度的浅层神经网络的 ensemble,训练完一个深层网络后,在测试的时候随机去除某个网络层,并不会使得网络的性能有很大的退化,而对于 VGG 网络来说,删减任何一层都会造成模型的性能奔溃,如下图。
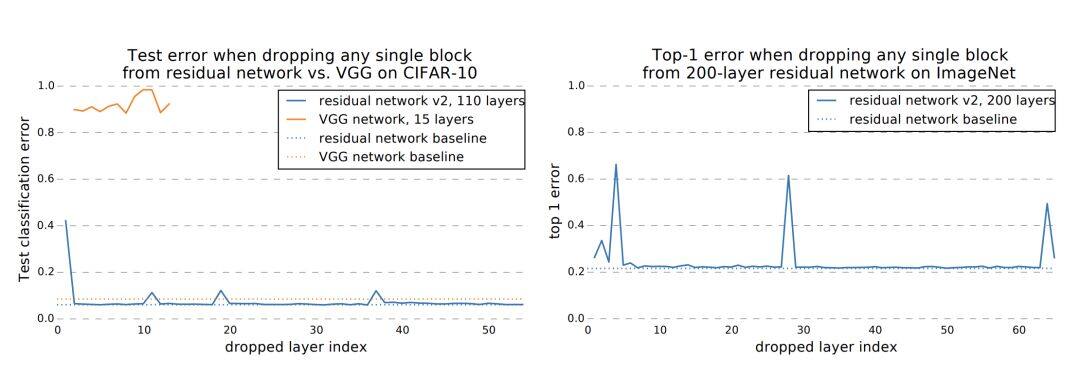
甚至去除和打乱一些网络层,性能的下降也是一个很平滑的过程。
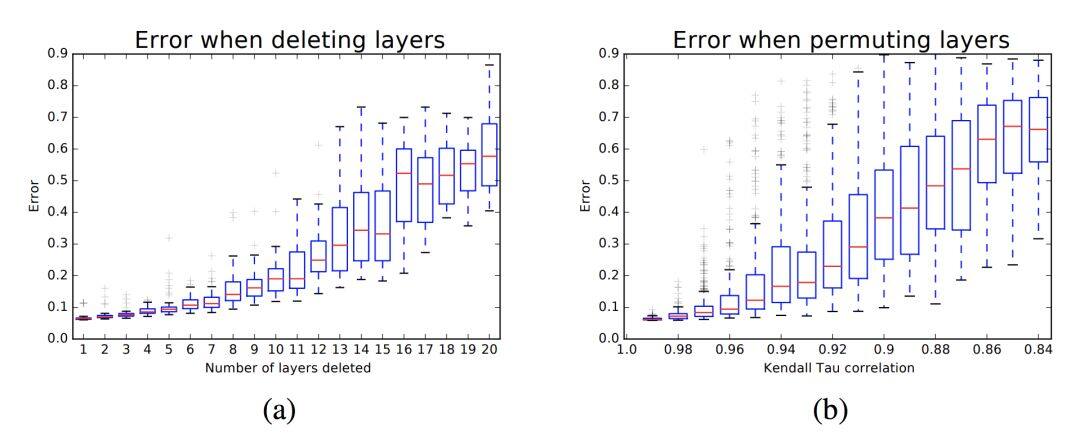
以上都证明了残差结构其实是多个更浅的网络的集成,所以它的有效深度看起来表面的那么深,因此优化自然也没有那么难了。
参考文献
[1] Schraudolph N. Accelerated gradient descent by factor-centering decomposition[J]. Technical report/IDSIA, 1998, 98.
[2] Raiko T, Valpola H, LeCun Y. Deep learning made easier by linear transformations in perceptrons[C]//Artificial intelligence and statistics. 2012: 924-932.
[3] Srivastava R K, Greff K, Schmidhuber J. Training very deep networks[C]//Advances in neural information processing systems. 2015: 2377-2385.
[4] He K, Zhang X, Ren S, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 770-778.
[5] Orhan A E, Pitkow X. Skip Connections Eliminate Singularities[J]. international conference on learning representations, 2018.
[6] Veit A, Wilber M J, Belongie S. Residual networks behave like ensembles of relatively shallow networks[C]//Advances in neural information processing systems. 2016: 550-558.

腾讯大规模云原生技术实践案例集
本案例集详细阐释了 QQ、腾讯会议、和平精英、小红书、斗鱼、微盟等十多个亿级用户产品背后的大规模云原生...










评论