
背景
公有云是一种为用户提供经济方便的计算资源的平台。随着云计算技术的快速发展,以及大数据查询需求的日益增加,很多公有云的云计算应用市场中,出现了越来越多云上 OLAP 引擎服务。为了能够根据自己的业务需求选择合适的 OLAP 引擎,并通过合适的配置使引擎在最佳状态运行,用户需要对当前使用的查询引擎性能进行评估。
当前 OLAP 引擎性能评估框架在云上部署使用时面临三个主要挑战:
1、对云环境适应能力弱。传统性能评估框架诞生时,尚未具备云上特有的 PaaS、IaaS、SaaS 特性,也不具备对存算分离的适配支持。使用云上 OLAP 时,需要充分利用云计算特性分析 OLAP 引擎性能。
2、不具备复杂工作负载的复现能力。工作负载由数据集、查询集、查询序列组成。传统的性能评估框架通常采用固定的数据集和查询级,查询序列也主要以线性序列为主。现代 OLAP 查询场景的复杂化,对特定场景下的数据集和查询集的特征刻画、高并发复杂场景支持等,提出了更高的要求。
3、难以全面评估查询性能与上云成本。传统评估体系(如 TPC-H、TPC-DS)不体现成本因素,而在云上资源近乎无限的大环境里,不考虑成本的评估会造成很大的偏见,甚至得出错误的结论。云计算具备自定义租用服务器规模的特性,因此云上成本是可变、可设置的,其单价也随时间波动。用户既希望 OLAP 查询能以最快的速度被执行,又希望能尽可能节省成本,因此需要性能评估框架全面评估查询性能与上云成本,根据用户需求提供最具性价比的云服务器与 OLAP 引擎搭配方式。
针对上述问题,南京大学顾荣老师、吴侗雨博士等人与 Apache Kylin 社区团队联合研究,设计开发一套云上 OLAP 引擎查询性能评估框架,名为 Raven。
Raven 被设计来帮助用户回答一些 OLAP 引擎上云面临的实际而又重要的问题:
对于一份真实生产数据中的真实工作负载(数据载入 + 查询),哪个 OLAP 引擎在云上运行的 IT 成本更低?
给定一个查询速度的目标,在能达成的速度目标的前提下,哪个 OLAP 引擎在云上能给出更低的 IT 成本?
再加上考虑数据载入速度的因素,情况又会如何?
本文将介绍本团队在设计与实现 Raven 时遇到的问题、对应的解决方案、以及当前的初步研究成果。
适应云架构的性能评估框架设计
OLAP 引擎查询性能评估框架适配云架构时,实际上是在适配云上的 PaaS、IaaS、SaaS 特性。具体而言,云服务器的很多功能都以服务的方式呈现给用户,用户只需要调用对应服务的接口,即可实现不同的目的,如云服务器创建、文件操作、性能指标获取、应用程序执行等。在文件操作中,由于云服务器采用计算存储分离的架构,一些数据可能需要通过服务从远程的云存储服务上拉取。
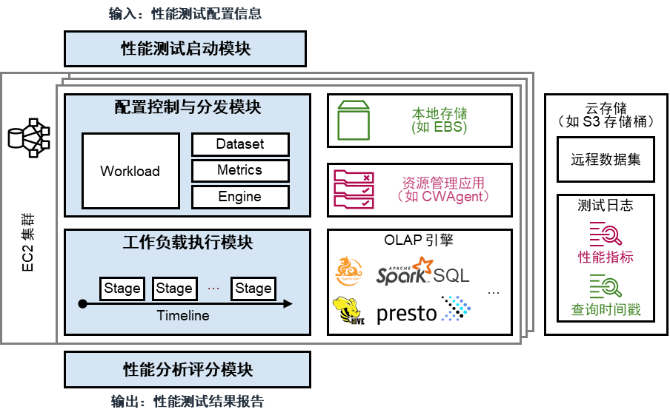
图 1:基于公有云平台的 Raven 性能评估框架
结合上述需求,Raven 的框架如图 1 所示。其执行步骤如下:
1、用户输入性能测试配置信息,触发性能测试启动模块,该模块负责根据用户配置创建启动云上 OLAP 性能测试所需的云服务器和计算环境。
2、性能测试启动模块将工作负载、数据集、性能指标、引擎参数等信息传递给配置控制与分发模块,该模块负责将上述信息分发到对应的服务接口或模块上。
3、配置控制与分发模块触发工作负载执行模块,工作负载执行模块启动配置好的 OLAP 引擎,并根据工作负载设置随时间向 OLAP 引擎发送查询请求。
4、OLAP 引擎向本地存储或云存储拉取数据集,执行查询。查询执行过程中,工作负载执行模块记录查询开始和结束的时间戳,并启动资源管理服务,监控 OLAP 引擎查询期间的性能指标。查询结束时,工作负载执行模块将时间戳和性能指标信息输出到云存储中。
5、启动性能分析评分模块,从远程云存储中拉取时间戳和性能指标信息,导入用户自定义的评分模型,得到最终的性能评估结果。
上述设计的优点在于:
1、 充分利用可自定义的云服务器数量和配置,允许用户自定义其希望创建的集群环境。
2、支持向远程的云存储服务读写数据,适应云环境的存算分离架构。
3、使用云服务提供商的资源管理服务,得以获取大量系统资源使用状况的信息。
4、支持可插拔的引擎接口,用户可任意指定其所需测试的 OLAP 引擎及其配置。
实际使用时,用户的输入以一个.yaml 文件呈现,可仿照如下格式:
engine: kylinworkload: tpc-htest_plan: one-passmetrics: all用户需要的云服务器数量、每台机器的配置、不同的引擎等,均可通过 JSON 文件配置。
传统的 OLAP 查询引擎通常采用固定的数据集和查询集,并执行一系列的查询,查看 OLAP 引擎的查询性能。然而,当前很多行业的工作负载正更加复杂。
1、越来越多的企业意识到自身数据及业务具有鲜明特征,希望能够在给定的数据特征下获得最佳的 OLAP 查询方案。
2、除了传统的 OLAP 查询外,越来越多的预计算技术,如 ETL、索引、Kylin 的 Cube 等,亟待纳入到 OLAP 引擎性能的考察中。
3、数据量的快速增长使得高并发查询、QPS 可变查询的场景越来越多,传统的线性查询方法很难上述新场景进行准确评估。
Raven 使用了一种基于时间线的事件机制描述复杂的 OLAP 工作场景。该机制下,一个工作负载由多个阶段构成,一个阶段由多个事件构成。在时间线上,一个工作负载被描述为若干个阶段的顺序执行。每个阶段分为线上阶段和线下阶段两种:线上阶段执行实际的查询请求,线下阶段执行预计算等操作。事件是对工作负载中每一个原子执行单元的抽象,可以是查询请求、shell 命令,或用 Python 等编程语言编写的脚本。
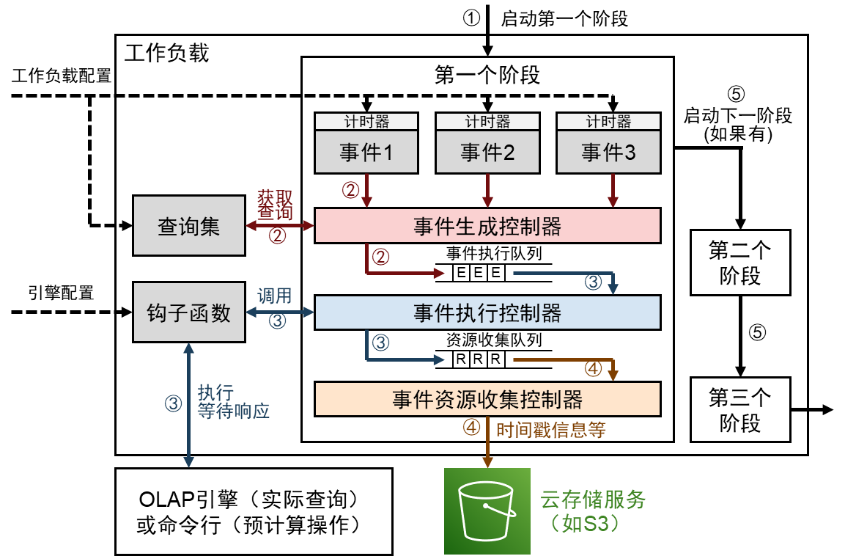
图 2:Raven 工作负载的执行过程
Raven 的工作负载如图 2 所示。其执行步骤如下:
1、启动第一个阶段,加载工作负载配置、引擎配置等;
2、当事件的计时器被触发时,将时间事件生成控制器,读取该事件对应的查询语句或脚本内容,进入事件执行队列,等待执行。
3、出事件执行队列后,进入事件执行控制器,开启线程执行钩子函数,与 OLAP 引擎或命令行执行交互操作,并等待响应,得到响应后将事件插入到资源收集队列中。
4、出资源收集队列后,进入事件资源收集控制器,将操作的时间戳信息输出到云存储服务上。
5、当该阶段内所有时间完成后,启动下一个阶段,然后按顺序执行每个阶段,直到整个工作负载结束。
上述设计的优点在于:
1、支持自定义数据集和查询集,允许用户充分利用其业务特点进行性能评估。
2、支持预计算,允许用户评估预计算和实际查询的整体性能。
3、带时间戳的执行方法和线程管理策略,支持高并发查询,允许模拟 QPS 随时间波动的工作负载。
举个例子,可以使用如下的 .yaml 配置文件,在 AWS 上启动一主四从的 EC2 集群,并部署 Presto 引擎,指定数据集为 SSB(SF=100)且工作负载满足泊松分布(λ=3.0),工作负载持续时间为 600 秒:
Cloud: Name: AWS Description: Amazon Web Service. Properties: Region: ap-southeast-1 Ec2KeyName: key_raven MasterInstaceCount: 1 MasterInstanceType: m5.xlarge CoreInstanceCount: 4 CoreInstanceType: m5.4xlargeEngine: Name: presto Description: Presto. Properties: host: localhost port: 8080 user: hive catalog: hive concurrency: 1Testplan: Name: Timeline template. Properties: Type: Timeline Path: config/testplan/template/timeline_template.yamlWorkload: Name: SSB Type: QPS Parameters: database: ssb_100 distribution: poisson duration: 600 lam: 3.0Raven 预置了一些常见工作负载供用户使用,如均匀分布、突发高并发分布等。
基于自定义多元函数的性能评估模型
在性能评估方面,云上机器的一个特点是大小、配置可自定义调节。因此,如果只考虑查询性能,理论上可以通过租用大量的高性能设备提升性能。但是,这样也会造成云上计算成本飙升。因此,需要一套机制实现性能和成本的平衡和综合考虑。
Raven 的性能评估方法是高度自定义的,允许用户根据可以获取的参数指标,使用函数表达式组合起来,得到一个评估分数。
Raven 中可获取的参数指标主要有以下几类:
1、查询质量指标:包括所有查询的总查询时间、平均查询时间、查询时间 95% 分位数、最大查询时间;
2、资源使用效率:内存和 CPU 的平均使用率、负载均衡、资源占用率超过 90% 的时间占总时间的比例;
3、云上金钱成本:可直接通过云服务商提供的应用服务获取,主要包含四个部分的开销:存储、计算、服务调用、网络传输。
Raven 给出的评分是相对的,只能在相同模型的评分之间进行比较。性能评估得分是云上成本和云上开销的乘积,评分越低,OLAP 引擎的性能越好。云上开销可使用线性模型,对上述参数赋予权重计算;也可使用非线性模型,将上述参数代入到一个函数表达式中。

实现与效果验证
我们在亚马逊 AWS 上实现了 Raven 的上述设计,并使用该性能评估框架执行 OLAP 引擎,查看不同引擎的查询效果。
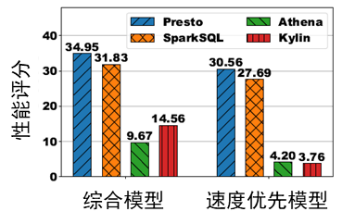
图 3:不同引擎在不同评分模型下,运行均匀查询 10 分钟的性能评分
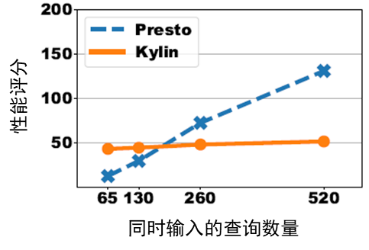
图 4:在 Presto 和 Kylin 上运行突发高并发分布的性能评分
从图 3 中可以看出,运行均匀查询时,Athena 和 Kylin 是较好的解决方案。但是,使用不同模型会得到不同的评估结论。当综合考虑查询速度的云上成本时,由于 Athena 直接通过调用服务执行查询,因此云上成本较低,评分也更低。但是,当优先考虑速度时,由于 Kylin 使用预计算技术实现了高速查询,因此使用速度优先模型时,Kylin 的评分更低。
从图 4 可以看出,运行突发高并发分布时,若采用查询阻塞模型,随着同时输入的查询数量增加,Presto 的性能评分随查询数量增加线性增长;但是,Kylin 并未受到查询数量增加的影响,性能评分保持稳定。这是因为 Kylin 的预计算技术提升了计算效率,当查询大量涌入时,Kylin 能以更高的效率处理这些查询,减少查询在队列中的阻塞,使性能评分更为出色。当然,如果用户集中的查询数量不大,Presto 的性能评分更有优势,因为其没有预计算的相关开销。
未来展望
未来的研究主要考虑以下方面:
1、应用实现更多引擎,尝试兼容云原生引擎,以进行性能评估。
2、优化工作负载的表达形式,使用户可以根据自己的业务需求,更容易地开发出多样化、具代表性的工作负载。
3、形成更多标准化的评分模型,供不同工作负载之间的横向对比。
4、结合当前评分结果,进一步分析不同 OLAP 引擎的性能优劣。




