

Joshua Poduska 发布了关于 Ludwig 的深度学习指南,其主要内容包括 Ludwig 的设计原则、Ludwig 实验功能和结果的输出方式以及 Joshua Poduska 对 Ludwig 从业者新手的一些经验传授。
随着深度学习方法和理念的发展,我们将看到更多像 Ludwig 这样的工具,它们将最佳实践提取到基于深层学习框架(如 TensorFlow)的代码库中,并且可以通过 Python API 访问。这将增加跨行业深度学习方法的采用,并带来令人兴奋的新深度学习应用。
介绍
新的工具不断被添加到深度学习生态系统中。而那些不同类型的深度学习工具在创建时总有着某些规律,在寻找这些规律的过程中,总能让人感觉到非常有趣且充实的干货体验。例如,科学家们最近创建了许多有前景且具有 Python API 的新工具,它们往往基于 TensorFlow或PyTorch框架,并封装了许多深度学习最佳实践,以便数据科学家们能够提高自己的研究效率。而这其中较为显著的例子就包括 Ludwig 和 Fast.ai 。
这篇博客文章描述了 Ludwig 的设计原则且提供了相关软件包的简要概述,同时作者以从业者的角度为 Ludwig 初学者提供了相关开发经验,例如在训练或测试深度学习模型过程中,开发者应在何时使用 Ludwig 的命令行语句以及应在何时使用 Python API。此博客还提供了一个 Jupyter Notebook 的代码示例,你可以通过 Domino 提供的托管进行下载或尝试运行 Jupyter Notebook。
登录此处访问 Ludwig 项目。
Ludwig 的设计原则
我最近参加了在旧金山 Uber HQ 举行的聚会。Ludwig 的主要架构师和维护者 Piero Molino 介绍了 Ludwig 并将 Ludwig 的“魔力”归纳为三点:
基于抽象数据类型的深度学习模型设计方法;
通过模型配置文件 YAML 定义输入输出功能;
可以聪明地使用关键参数(** kwargs)。
编者注:** kwargs 是 Python 语言中的一种关键字参数,它允许将不定长度的键值对,作为参数传递给一个函数。
我将简单解释为什么 Peiro 会这么说,不过在此之前,如果你能够预先通过 Uber工程博客查看 Ludwig 设计工作流程的图解,那么在阅读接下来的说明时,你可能会理解得更快更多。
Ludwig 可以通过抽象数据类型对深度学习模型进行设计分析并制定相应策略,使得 Uber 工程团队能够更好地整合深度学习最佳实践,以便顺利进行深度学习模型的训练、验证、测试和部署。在具有常见类型的不同数据集上,Ludwig 可以利用相同的数据进行预处理和后处理。这种抽象化概念可以延伸到编码器的应用上,编码器只是简单的深度神经网络,而深度神经网络则可以包括并行 CNN、堆叠 CNN、堆叠并行 CNN、RNN 等。当为单独任务开发出编码、解码模型时,若这种编码、解码模型符合其他任务要求且具有相同功能,则可以被重复运用于其他不同任务中。
当然,不仅专家可以使用这些深度神经网络的详细信息,新手也可以利用 Ludwig 访问成熟的默认设置进行模型训练。并且通过 YAML 文件就可以轻松地插入新的编码器、解码器和组合器。专家或中级开发者也发现使用用户指南中的可选** kwargs 在调整模型行为和超参数时具有不错的适用性。
Ludwig 允许用户训练模型、加载模型、使用此模型进行预测以及运行此模型进行实验。开发者可以通过命令行或 API实现这些操作。在 Ludwig 中训练模型,只需要表格数据集文件 CSV 和模型配置文件 YAML 就足以满足条件。
Ludwig 实验和输出
因为 Ludwig 的实验功能可以将所有的设计原则统一在一起,所以我们会说它抓住了 Ludwig 包的精髓。在一项实验中,Ludwig 将会创建一个中间预处理版本,并导入带有 HDF5 扩展名的表格数据文件 CSV。这就产生了第一次同一目录下使用同名表格数据文件 CSV 的情况,随之后续的实验也会运行利用这些数据。Ludwig 能够随机分割数据,并在训练集上训练模型,直到验证集的准确性无法再继续优化。实验记录和实验输出都可以在结果目录中找到,而且其中还包含了模型超参数和模型实验过程的摘要统计信息。我发现这种自动记录的功能非常有用,因为在我的工作中,每次运行软件通常就代表着模型的调整。Ludwig 的实验输出会在目录中自动记录。你可以为自己做的每一个实验命名,也可以使用默认的名称。
在利用 Ludwig 工作时,如果你对管理它自动生成的输出方式感兴趣,那么相信这个自动记录的功能肯定会对你有所帮助。将输出目录与 Git 项目同步并添加提交注释,或使用像 Domino 提供的自动重现引擎,会在让开发者在重新创建实验时节省很多时间。更为关键的一点是,Ludwig 实验能够记录项目变化以及项目的运行方式。
Ludwig 从业者提示
无论什么工具,在找出工作中利用它的最佳方式之前,都会让人感受到成长的痛苦。在本节中,我总结了自己在使用 Ludwig 过程中所学到的以及有助于新人入门的经验教训。
从业者提示 1:命令行非常适合运行实验
Ludwig 的大多数功能都可以通过命令行或 Python API 获得,但即使一些编程 API 函数在技术上是可访问的,目前却尚未能得到完全支持,就如本讨论主题中所述。相对比而言,命令行的功能就显得更加齐全,一次简单的 Ludwig 实验就可以证实这一点。即使在使用 API 时需要逐步运行,但是当通过命令行调用时,Ludwig 会自动拆分数据并在训练集上训练模型,直到验证集的准确性无法再继续优化(对我而言,这是一个很不错的功能)。
下面是通过命令行启动实验的语法示例。
另一方面,你需要通过 Python API 训练和测试自己的模型。
从业者提示 2:在某些系统上,调用命令行实现可视化有一定难度
在实现可视化显示的实验过程中,可能会令人感到棘手和失落。例如,一些基础的代码还在改进中,就像在查看可视化显示实验的结果时,需要增加保存图片的选项,而不是只显示图片。如果从 GitHub 主服务器安装 Ludwig,你将能够通过 CLI(命令行界面)实现保存图像的功能。
请参阅此处以获取有关此主题的讨论。
从业者提示 3:通过命令行进行实验,通过 API 调用实现可视化
我喜欢将 Tip1 和 Tip2 结合起来,通过命令行运行实验,并通过 Python API 调用构建可视化图形。在尝试利用命令行显示可视化图形时,虽然系统并没有进行协同工作,但是通过 API 调用而绘制好的那些可视图形都很不错。使用以下语法和输出作为示例,可以轻松地在 Jupyter Notebook 上执行命令行以及 API 的调用。
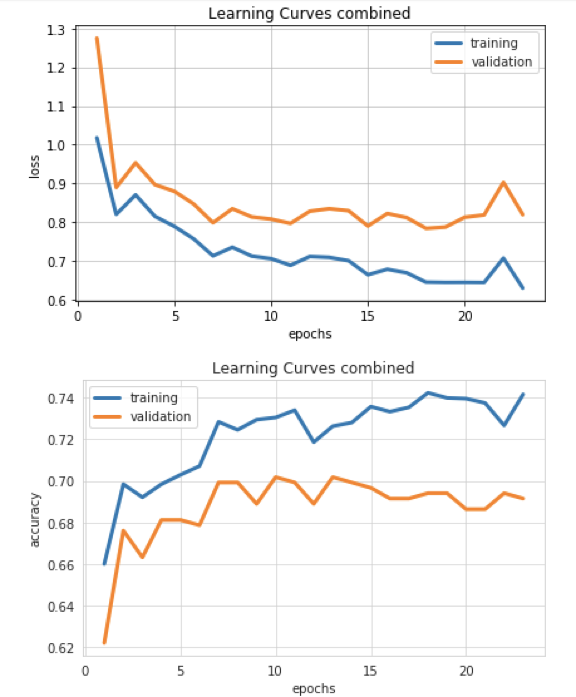
示例笔记,可以直接下载或通过由 Domino 提供的托管运行。

前InfoQ编辑

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论