

Amazon 构建并运营了数千种微服务,为数百万客户提供服务。这些服务包括目录浏览、下单、交易处理、交付计划、视频服务和 Prime 注册。每项服务均向 Amazon 分析基础设施发布数据集,包括超过 50 PB 的数据和 75,000 个数据表,每天处理 600,000 次用户分析作业。发布数据的团队超过 1,800 个,并有超过 3,300 个数据使用者团队分析这些数据,以生成见解、发现机会、制作报告和评估业务绩效。
支持该系统的本地 Oracle 数据库基础设施无法处理 PB 级的数据,以致其生成的单一解决方案由于在功能和财务方面缺少分离而导致难以维护和操作。从操作角度来说,超过 1 亿行的数据表转换往往会失败。这就限制了业务团队生成见解或部署大规模机器学习解决方案的能力。很多用户放弃了单一的 Oracle 数据仓库,转而采用利用 Amazon Web Services (AWS) 技术的定制解决方案。
Oracle 数据仓库的数据库管理复杂、昂贵且容易出错,每个月都需要工程师花费数百小时进行软件升级、跨多个 Oracle 集群复制数据、修补操作系统和监控性能。低效的硬件配置需要投入大量工作来预测需求和规划容量。由于 Oracle 许可成本不断增加,其经济效率也很低下,无法满足峰值负载的静态大小,并且缺乏为成本优化而动态扩展硬件的能力。
Amazon 分析系统迁移
为了满足其不断增长的需求,Amazon 的消费者业务决定将 Oracle 数据仓库迁移到基于 AWS 的解决方案中。新的数据湖解决方案使用多种 AWS 服务,以极高的性能和可靠性实现 PB 级数据处理、流和分析。
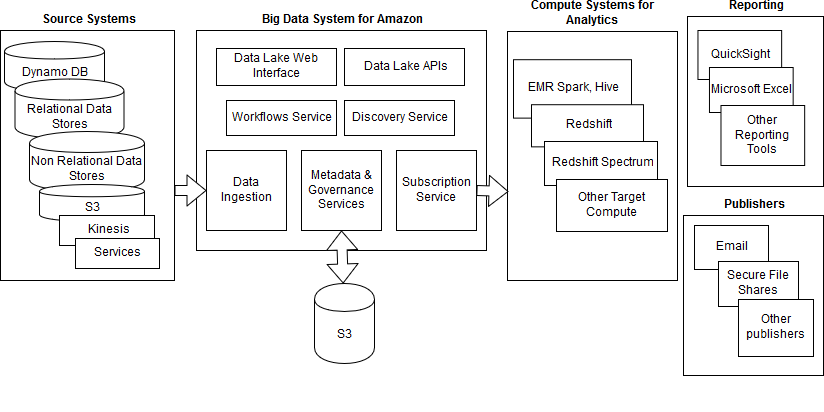
公司使用 Amazon Simple Storage Service (Amazon S3) 作为数据湖,在需要进行分析之前以原生格式保存原始数据。借助 Amazon S3,Amazon 可以大规模灵活管理各种数据,同时降低成本、改善访问控制并加强法规遵从性。除了 Amazon S3 本身支持的治理和安全功能之外,Amazon 还集成了内部服务功能,用于身份验证、授权和数据治理。并开发了一种元数据服务来简化数据集发现,使数据使用者可以轻松搜索、排序和识别数据集以进行分析。
为使最终用户实现自助分析,Amazon 专门开发了一种服务,该服务可使来自数据湖的数据与包括 Amazon Elastic MapReduce (Amazon EMR) 和 Amazon Redshift 在内的计算系统同步。Amazon EMR 提供了一个托管的 Hadoop 框架,该框架可在 Amazon Elastic Compute Cloud (Amazon EC2) 实例上运行 Apache Spark、HBase、Presto 和 Flink,并与 Amazon S3 中的数据交互。Amazon Redshift 为 AWS 数据仓库服务,其允许分析系统最终用户使用 Amazon QuickSight 等工具执行复杂查询并将结果可视化。
此外,Amazon 还将数据湖与 Amazon Redshift Spectrum 功能集成在一起,允许用户直接从 Redshift 查询数据湖中的任何数据集,而无需将数据同步到其群集。这加速了整个消费者业务的临时分析,无需存储大型数据集的本地副本便可进行容量规划分析。这实现了分析系统的联合以及分析成本的可见性,而以前的架构对此造成了严重的限制。
为帮助从 Oracle 解决方案迁移到联合数据湖架构,Amazon 使用 AWS Schema Conversion Tool (AWS SCT) 开发了批量查询迁移工具。该工具用来自动转换和验证从 Oracle SQL 到 Amazon Redshift SQL 的 200,000 条查询中的 80% 以上,节省了超过 1,000 人月的人工。对于无法自动转换的查询,工程师会记录并与最终用户分享最佳实践,以便转换这些查询。
变革文化
迁移团队通过面对面培训课程、非正式会谈、网络研讨会和文档向用户介绍迁移的愿景、使命和目标。这一行动分阶段进行,随着项目的进展,逐步改善系统、工具和流程。每个团队都提交了项目计划并分配了迁移构件所需的资源,包括 ETL 流程、业务报告、存储过程和机器学习算法。
迁移团队为数据湖植入了来自 Oracle 数据仓库的活动数据集,并构建了一个自动化系统,以使两个系统中的数据集同步更新。它提供了迁移工具,包括用于配置 AWS 资源的 AWS CloudFormation 模板。创建通道使得数据生产者和使用者能监控数据湖中的数据可用性、准确性和延迟,从而直接提出问题。中心团队与每个团队制定了每周、每月和每季度审核计划以跟踪和报告进度,并汇总了来自两个用户组的进度报告以进行计划状态报告。
此外,迁移至 AWS 重新定义了传统数据库工程师和管理人员的职业道路。他们的技能和专长有助于 Amazon Redshift 或 Amazon EMR 解决方案性能的提升,这些解决方案依赖于设计最佳查询计划和监控性能的数据库知识。中心团队通过大量的培训和教育实现了职业转型。
新的规模和敏捷性
新的分析基础设施有一个数据量超过 200 PB 的数据湖 – 几乎是以前 Oracle 数据仓库的四倍。Amazon 的业务团队现在使用 3,000 多个 Amazon Redshift 或 Amazon EMR 群集来处理来自数据湖的数据。
尽管规模较大,但业务部门发现新系统更具成本效益。这是因为迁移团队停止了 30% 不再使用的工作负载,并优化了查询以提高系统利用率。团队现在可以监控系统的使用情况并快速消除浪费,从而实现持续的成本效益。
Amazon 的消费者业务大大受益于 AWS 中数据存储与数据处理的分离。AWS 存储服务使得以任何格式安全、大规模、低成本存储数据更加方便,并能快速轻松地移动数据。数据湖架构允许每个系统独立扩展,同时降低总体成本并扩大可用技术范围。用户可以轻松发现最佳格式的高质量数据,团队报告分析结果的延迟减少了。
借助 AWS,每个 Amazon 业务团队都可以管理自己的计算实例并完全控制容量和成本,它与传统环境有所不同,后者由于基础设施集中而效率低下。团队现在将 Amazon EC2 Reserved Instances 作为其成本优化策略的一部分。中心团队持续监控 AWS 分析帐户,以评估使用情况和优化成本。
迁移到 AWS 云以后,Amazon 使工程师能够使用或构建高级分析工具,而非将时间用在保持传统系统运行上,从而专注于生成见解。最重要的是,迁移使 Amazon 消费者业务部门的工程师能够更加轻松地持续分析和改善他们为客户提供的服务。
本文转载自 AWS 技术博客。
原文链接:
https://amazonaws-china.com/cn/blogs/china/amazon-50-pb-amazon-migration-analytics/


腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论