

在上一篇文章中,我们了解了 Kafka 的处理层,以及 Kafka Streams 和 ksqlDB 的分布式处理架构。在这篇文章中,我们将再次探讨处理层,并深入理解 Kafka 是如何实现弹性伸缩和容错能力的。
我们先从流和表的处理容错能力开始,然后再介绍弹性。我们将会看到,它们实际上是一枚硬币的两面。
容错处理
流和表具有容错能力,因为它们的数据被可靠地存储在 Kafka 中。对于流来说,这个相对好理解,因为流是直接与主题对应起来的,如果在处理过程中出了问题,重新读取主题的数据就可以了。
这对于表来说就相对复杂了,因为表必须维护额外的信息,也就是它们的状态,这样才能进行有状态的操作,比如 COUNT()或 SUM()。在 Kafka Streams 应用程序或 ksqlDB 服务器中,为了确保在保持高性能的同时实现有状态处理,表需要被物化到本地磁盘。但是,机器或容器会宕机,本地保存的数据也会随之丢失,那么我们该如何确保表的容错能力呢?
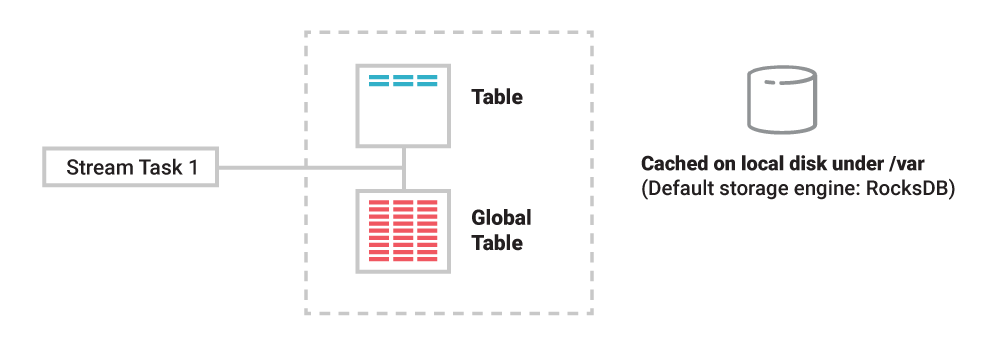
图 1. 表和状态被物化到本地磁盘
存储在表中的数据也被存储在远程的 Kafka 中。每张表都有自己的变更流,我们可以把它看成是一种内置的 CDC。假设我们有一张客户账户表,每次更新账户的余额时,都会有一个对应的变更事件被添加到这张表所对应的变更流中。
与关系型数据库的重做日志类似,变更流就是表的事实来源。变更流持续不断地被保存到 Kafka 主题中,所以这个主题也被叫作变更日志主题。所以,表的容错能力利用了流和表的二元性。在 stream 任务或运行任务的容器/虚拟机/机器发生故障时,表的数据可以通过变更流来恢复,数据的处理也因此不会被中断,不会有数据丢失或产生错误的处理结果。
如果一个容器发生故障,那么就需要在另一个容器上重建账户表,这样就不需要重新运行整个处理过程。我们可以直接从变更日志主题恢复表的状态。变更日志主题经过压缩,所以整个恢复过程非常快,稍后我们将会看到。
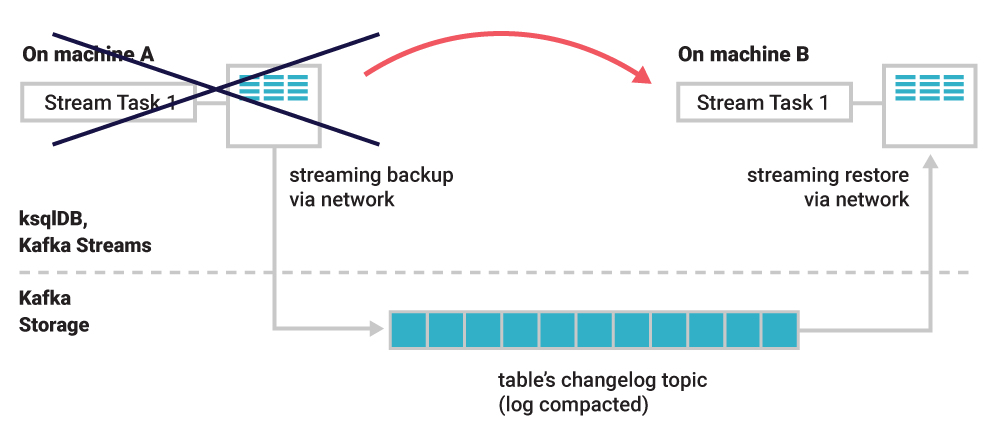
图 2. 运行在机器 A 上的一个任务。如果机器发生宕机,任务会被迁移到另一台机器上。在新机器上,表的状态被恢复到发生故障时的那个时刻,恢复完成之后,任务继续执行。
弹性处理和伸缩性
弹性与上一小节讲到的容错能力有关。分布式系统处理故障(比如容器崩溃)所需要做的与实现弹性(例如,通过增加容器或移除容器实现应用程序的伸缩)所需要做的实际上很相似。至于容器是因为有意被移除还是因为无意发生故障,这个并不重要。换句话说,弹性和容错能力是一枚硬币的两面!
假设我们有两个 Kafka Streams 应用程序实例。输入数据是一个 Kafka 主题,这个主题有 4 个分区,那么就会有 4 个 stream 任务。这 4 个任务被均匀地分配给两个应用程序实例。如果现在加入第三个和第四个应用程序实例,那么之前的任务及其表分区的一部分会被迁移到新的应用程序实例上。
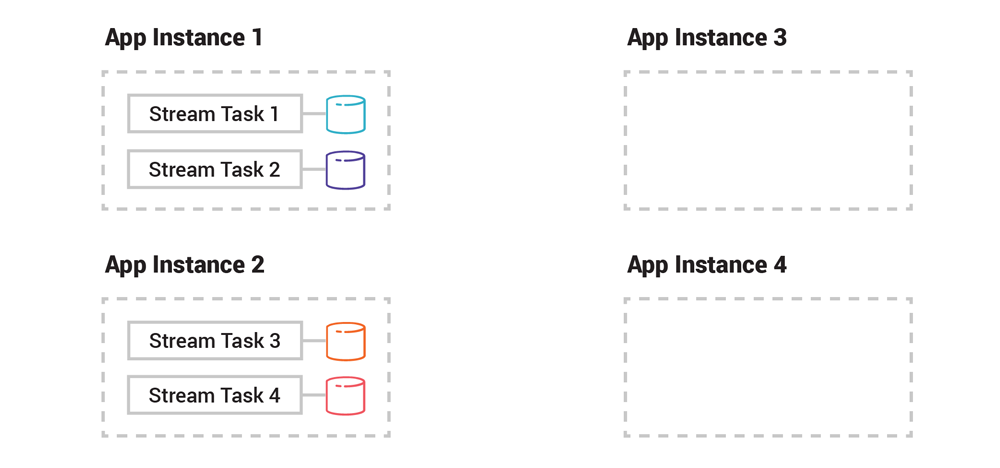
图 3. 在加入新的应用程序实例之前
处理逻辑(比如过滤、转换、连接、聚合等)不需要进行迁移,因为每个应用程序实例都已经包含了这些东西。唯一要做的事情是快速迁移数据,不管是几 KB 还是几 GB。如果我们把已有的应用程序实例移除,那么就反过来:任务和表被迁移到仍然存活的实例上。
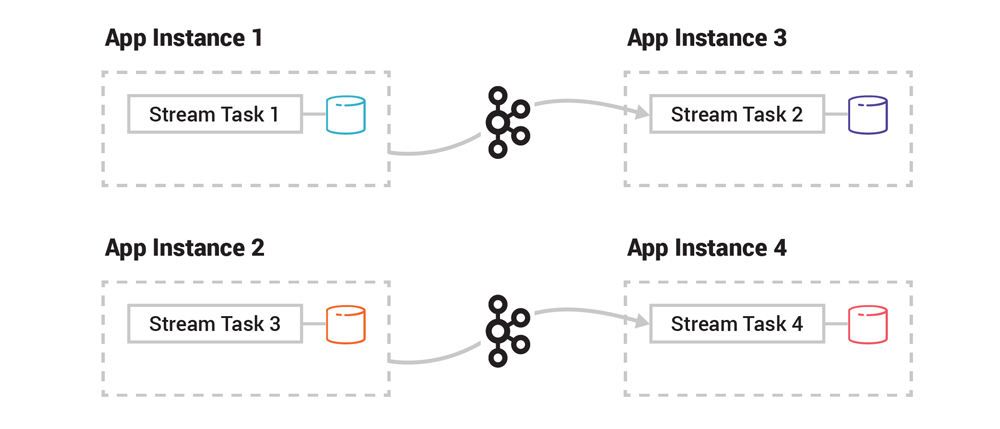
图 4. 在新增应用程序实例之后
上述的每一个迁移步骤都是自动进行的,极大减少了应用程序开发者和运维人员的负担。另外,应用程序的弹性操作可以在运行时完成,而其他流式处理框架在进行弹性操作时需要完全停止应用程序,进行重新配置和重新提交处理作业。
表和主题的压缩
一般来说,表底层的主题应该是压缩的。但有一种情况例外,比如基于一个已有的 Kafka 主题创建 ksqlDB 表,对于这种情况,与主题相关的配置都会被保留下来。压缩是 Kafka 的一个特性,确保 Kafka 对主题分区里的每一个键保留最新的事件,如图 5 所示。它会定时移除同一个键的旧事件(如图 5 示例中,Alice 之前访问过的网站),以此来减少表的变更流所占用的存储空间。
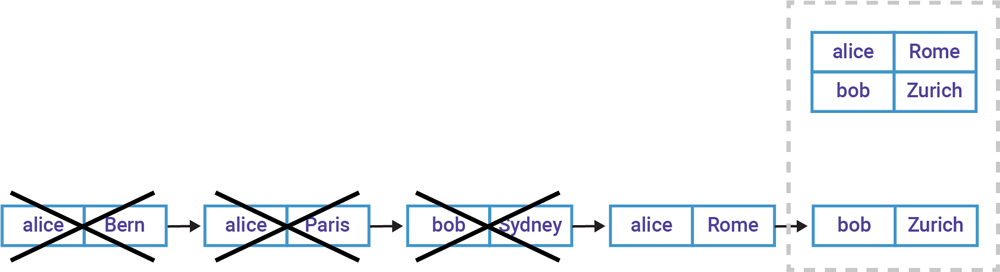
图 5. 同一个键的旧事件被定期移除
那么,压缩有哪些好处?有了压缩功能,我们可以在 Kafka 中永久地存储表数据,而不会让数据漫无边际地增长。这对于引用型数据(比如客户资料、产品目录、账户余额、维度表,等等)来说非常有好处。Kafka Connect 就使用压缩主题来保存配置信息。
压缩的第二个好处是减少了应用程序在发生再均衡时所需要的恢复时间,因为从 Kafka 代理传输给 ksqlDB 服务器或 Kafka Streams 应用程序的数据减少了,这同时也提高了弹性和故障处理能力。假设我们有一张包含一百万用户的表,每天会发生很多变更事件,到现在已经有 4 亿个事件了。在启用了压缩功能之后,恢复用户表就会快很多,因为只需要读取最新的一百万个事件,而不是所有的 4 亿个事件。
所以说,压缩是很有用的。但要注意的是,压缩会清除表的历史事件,例如图 5 中被虚线框起来的部分。如果你需要所有的历史事件,那么可以考虑禁用压缩功能。但请注意,对于流,不应该启用压缩功能,因为具有相同键的新事件不应该被认为是可以“取代”旧事件!
弹性和容错能力的背后
在故障处理和弹性的背后实际上是 Kafka 的再均衡过程。在生产环境中运行 Kafka Streams 应用程序和 ksqlDB 服务器时,我们需要明白,有那么一小段时间(通常很短),应用程序有一部分是不可用的,直到再均衡结束。在这一小段时间内,ksqlDB 或 Kafka Streams 应用程序会对受影响的任务和表或者状态进行迁移。
迁移任务涉及的数据越多,恢复所需的时间也就越长。如果需要传输的数据太多,那么客户端应用程序实例(保存表分区的地方)和服务器端的 Kafka 代理(包含主题分区,可以基于这些分区来恢复表的分区)之间的带宽就会成为瓶颈。
之前提到的压缩功能(默认是启用的)在减少数据方面非常有效。另一个可用于缩短恢复时间的功能是待命副本(standby replica),这个选项是可选的,但在生产环境中建议开启。
以 Kafka Streams 为例,应用程序实例可以被配置成其他实例的被动数据副本。在发生故障时,应用程序实例的任务被迁移到另一个已经包含了原有数据副本的实例上,这就极大地加快了恢复速度。不过,待命副本也有缺点,因为它增加了应用程序实例和 Kafka 代理之间的网络通信,而对于应用程序来说,因为增加了额外的数据副本,本地存储消费也随之增加。
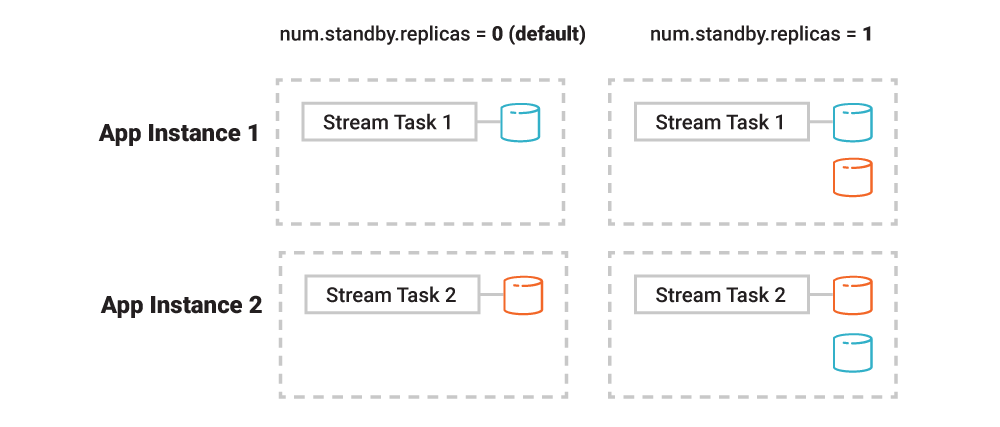
图 6. 待命副本默认是禁用的
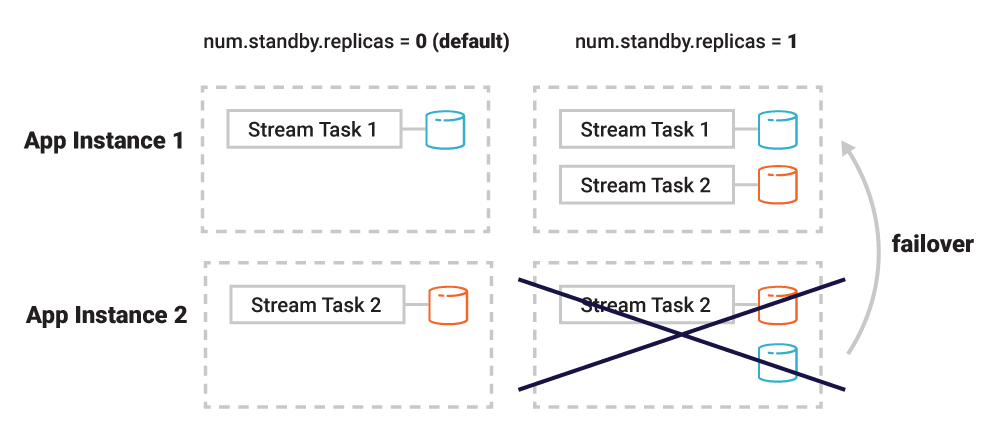
图 7. 如果启用了待命副本,当应用程序实例 2 发生宕机,应用程序实例 1 可以很快接管实例 2 的处理任务,因为它也具有所需的表数据
除了上述这些东西,Kafka 社区还在尝试其他一些改进,能够更快更有效地实现 Kafka 的弹性和容错能力。这些工作是 Kafka 2.4 和 Confluent Platform 5.4 的一部分,包括固定的消费者群组关系(为了减少因过度或不必要的再均衡导致的应用程序宕机时间)和增量式再均衡(提供更顺畅的伸缩体验,特别是如果应用程序是部署在云端或 Kubernetes 上)。
最后,我想分享一个容量规划技巧:在规划本地数据存储容量时,不要忘了考虑弹性和容错能力需要额外的空间,因为 stream 任务及其相关的表分区可能会在 Kafka Streams 应用程序实例或 ksqlDB 服务器之间移动。如果预期的本地表数据为 50GB,并且有 5 个应用程序实例,那么每个应用程序只分配 10GB 空间是不够的,如果这样的话,应用程序就没有办法在其他实例发生故障时接管它们的工作。
分区和并行处理
Kafka 的并行处理程度是由输入数据的分区数决定的,不管是流、表还是主题。如果有 20 个输入分区,那么就会有 20 个 stream 任务。也就是说,你可以运行 20 个 Kafka Streams 应用程序实例(或者一个包含 20 个服务器节点的 ksqlDB 集群),然后这些任务均匀地分配给这些实例。其他多余的应用程序实例将会空闲。
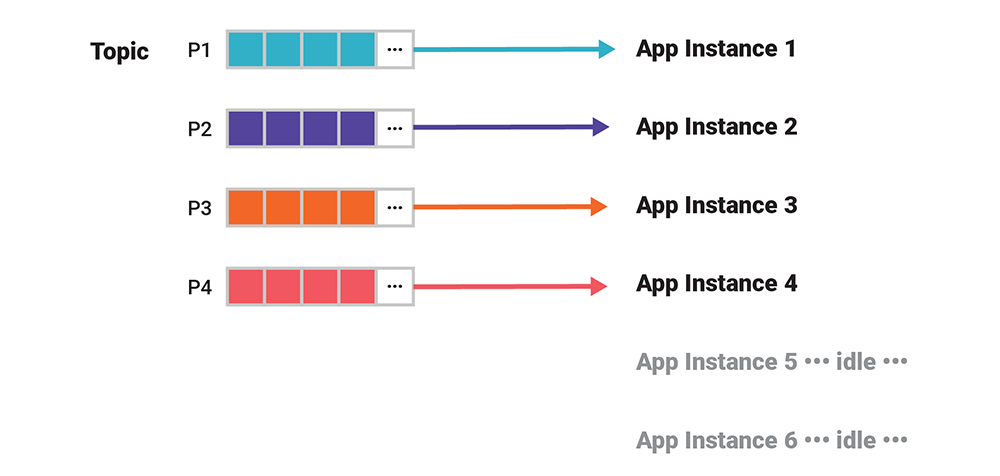
图 8. 并行处理度不会超过输入分区的数量
如果你想要提高并行处理水平该怎么办?如果你需要更高的并行处理水平,那就增加流或表的分区数。但对于已有的应用程序来说,要格外小心,因为有些事件现在被发送给了不同的分区。如果只是某个场景需要更高的处理并行度,可以考虑让原有的流或表保持不变,然后创建一新的具有更多分区的流或表。
这是 ksqlDB 的实例代码:
https://gist.github.com/confluentgist/3980184d5b45eb564aa18a1ad8dda126。
解决数据倾斜问题
在进行并行处理时,可能会遇到这种情况:有些 stream 任务需要处理的数据很多,有些则很少。我们通过监控相关的指标(例如消费延迟)就可以知道是否发生了这种情况。
图 9. Confluent Control Center 的指标监控
下面列出了两个常见的导致数据倾斜的原因及其解决办法。

图 10. 数据倾斜可能会导致出现热分区
总结
这是系列文章的最后一篇。在本系列文章中,我们先是介绍了基础元素——事件、流和表,然后了解了 Kafka 的存储层,然后是 Kafka 的处理层,还介绍了 ksqlDB 和 Kafka Streams。最后,我们探讨了这些应用程序的弹性和容错能力是如何实现的。
原文链接:
系列文章:

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论 1 条评论