

目标导向的视觉对话是“视觉-语言”交叉领域中一个较新的任务,它要求机器能通过多轮对话完成视觉相关的特定目标。该任务兼具研究意义与应用价值。
日前,北京邮电大学王小捷教授团队与美团 AI 平台 NLP 中心团队合作,在目标导向的视觉对话任务上的研究论文《Answer-Driven Visual State Estimator for Goal-Oriented Visual Dialogue-commentCZ》被国际多媒体领域顶级会议 ACM MM2020 录用。
该论文分享了在目标导向视觉对话中的最新进展,即提出了一种响应驱动的视觉状态估计器(Answer-Driven Visual State Estimator,ADVSE)用于融合视觉对话中的对话历史信息和图片信息,其中的聚焦注意力机制(Answer-Driven Focusing Attention,ADFA)能有效强化响应信息,条件视觉信息融合机制(Conditional Visual Information Fusion,CVIF)用于自适应选择全局和差异信息。该估计器不仅可以用于生成问题,还可以用于回答问题。在视觉对话的国际公开数据集 GuessWhat?!上的实验结果表明,该模型在问题生成和回答上都取得了当前的领先水平。
背景
一个好的视觉对话模型不仅需要理解来自视觉场景、自然语言对话两种模态的信息,还应遵循某种合理的策略,以尽快地实现目标。同时,目标导向的视觉对话任务具有较丰富的应用场景。例如智能助理、交互式拾取机器人,通过自然语言筛查大批量视觉媒体信息等。
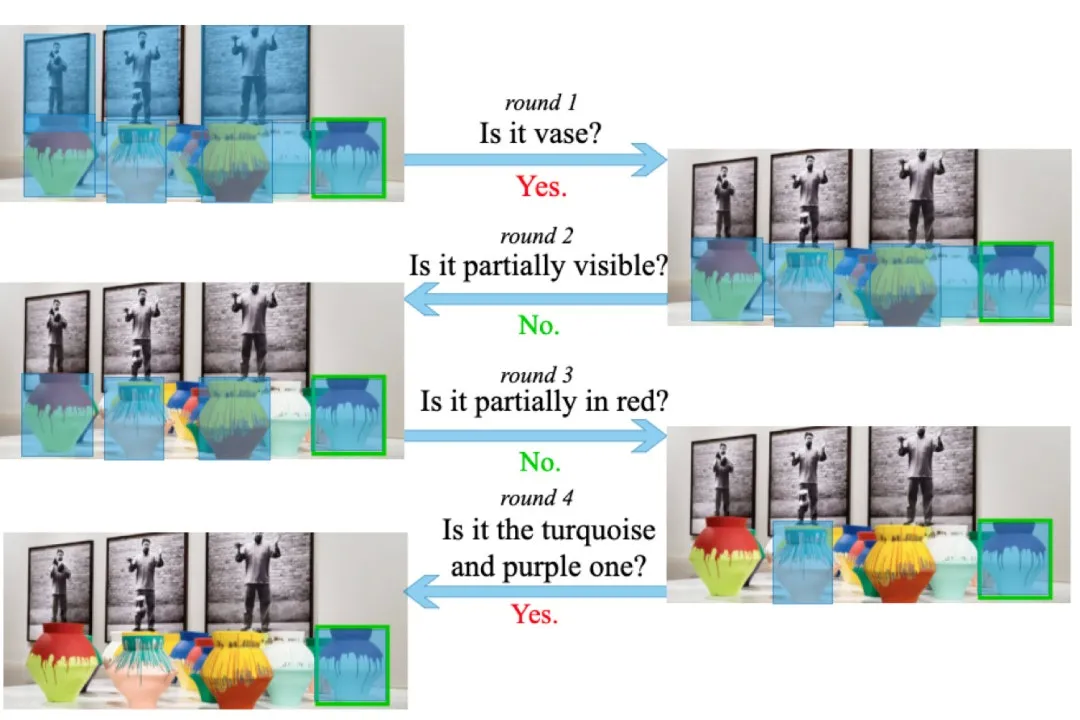
图 1 目标导向的视觉对话
研究现状及分析
为了进行目标导向的和视觉内容一致的对话,AI 智能体应该能够学习到视觉信息敏感的多模态对话表示以及对话策略。对话策略学习的相关工作有很多,如 Strub 等人[1]首先提出使用强化学习来探索对话策略,随后的工作则着重于奖励设计[2,3]或动作选择[4,5]。但是,它们中的大多数采用了一种简单的方式来表示多模态对话,分别编码两个模态信息,即由 RNN 编码的语言特征和由预训练 CNN 编码的视觉特征,并将它们拼接起来。
好的多模态对话表示是策略学习的基石。为了改进多模态对话的表示,研究者们提出了各种注意机制[6,7,8],从而增强了多模态交互。尽管已有工作取得了许多进展,但是还存在一些重要问题。
在语言编码方面,现有方法的语言编码方式都不能对不同的响应(Answer)进行区分,Answer 通常只是附在 Question 后面编码,由于 Answer 只是 Yes 或 No 一个单词,而 Question 则包含更长的词串,因此,Answer 的作用很微弱。但实际上,Answer 的回答很大程度决定了后续图像关注区域的变化方向,也决定了对话的发展方向,回答是 Yes 和 No 会导致完全不同的发展方向。例如图 1 中通过对话寻找目标物体的示例,当第一个问题的答案“是花瓶吗?”为“是”,则发问者继续关注花瓶,并询问可以最好地区分多个花瓶的特征;当第三个问题的答案“部分为红色吗?”为“否”,则发问者不再关注红色的花瓶,而是询问有关剩余候选物体的问题。
在视觉以及融合方面的情况也是类似,现有的视觉编码方式或者采用静态编码在对话过程中一直不变,直接和动态变化的语言编码拼接,或者用 QA 对编码引导对视觉内容的注意力机制。因此,也不能对不同的 Answer 进行有效区分。而如前所述,当 Answer 回答不同时,会导致图像关注区域产生非常不同的变化,一般地,当回答为“是”时,图像会聚焦于当前对象,进一步关注其特点,当回答为“否”时,可能需要再次关注图像整体区域去寻找新的可能候选对象。
响应驱动的视觉状态估计器
为此,本文提出一个响应驱动的视觉状态估计器,如下图 2 所示,新框架中包含响应驱动的注意力更新(ADFA-ASU)以及视觉信息的条件融合机制(CVIF)分别解决上述两个问题。
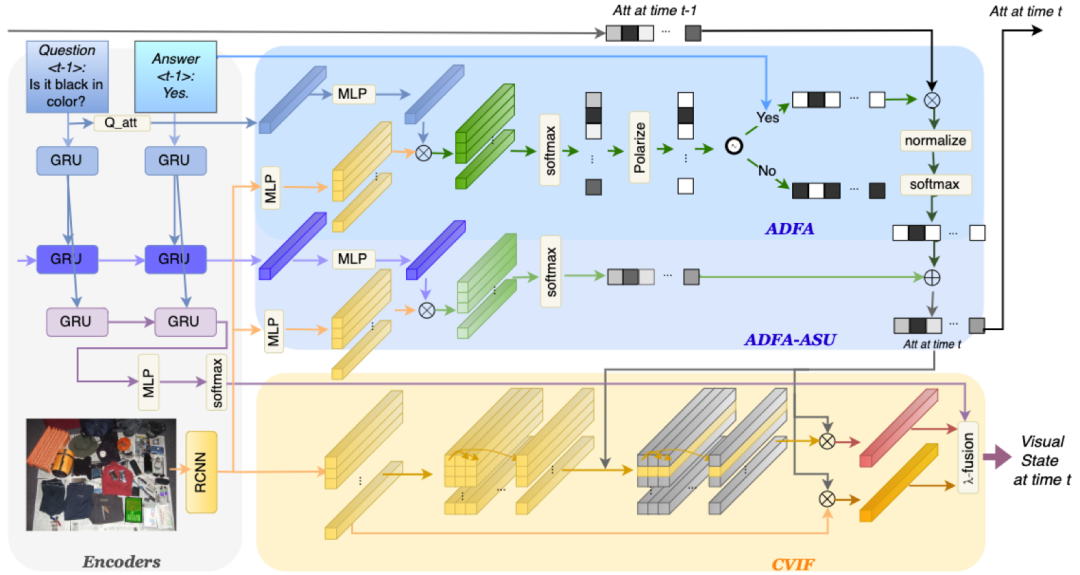
图 2 响应驱动的视觉状态估计器框架图
响应驱动的注意力更新首先采用门限函数极化当前轮次 Question 引导的注意力,随后基于对该 Question 的不同 Answer 进行注意力反转或保持,得到当前 Question-Answer 对对话状态的影响,并累积到对话状态上,这种方式有效地强调了 Answer 对对话状态的影响;CVIF 在当前 QA 的指导下融合图像的整体信息和当前候选对象的差异信息,从而获得估计的视觉状态。
答案驱动的注意力更新(ADFA-ASU)

视觉信息的条件融合机制(CVIF)

响应驱动的视觉状态估计器用于问题生成和回答
ADVSE 是面向目标的视觉对话的通用框架。因此,我们将其应用于 GuessWhat ?!中的问题生成(QGen)和回答(Guesser)建模。我们首先将 ADVSE 与经典的层级对话历史编码器结合起来以获得多模态对话表示,而后将多模态对话表示与解码器联合则可得到基于 ADVSE 的问题生成模型;将多模态对话表示与分类器联合则得到基于 ADVSE 的回答模型。
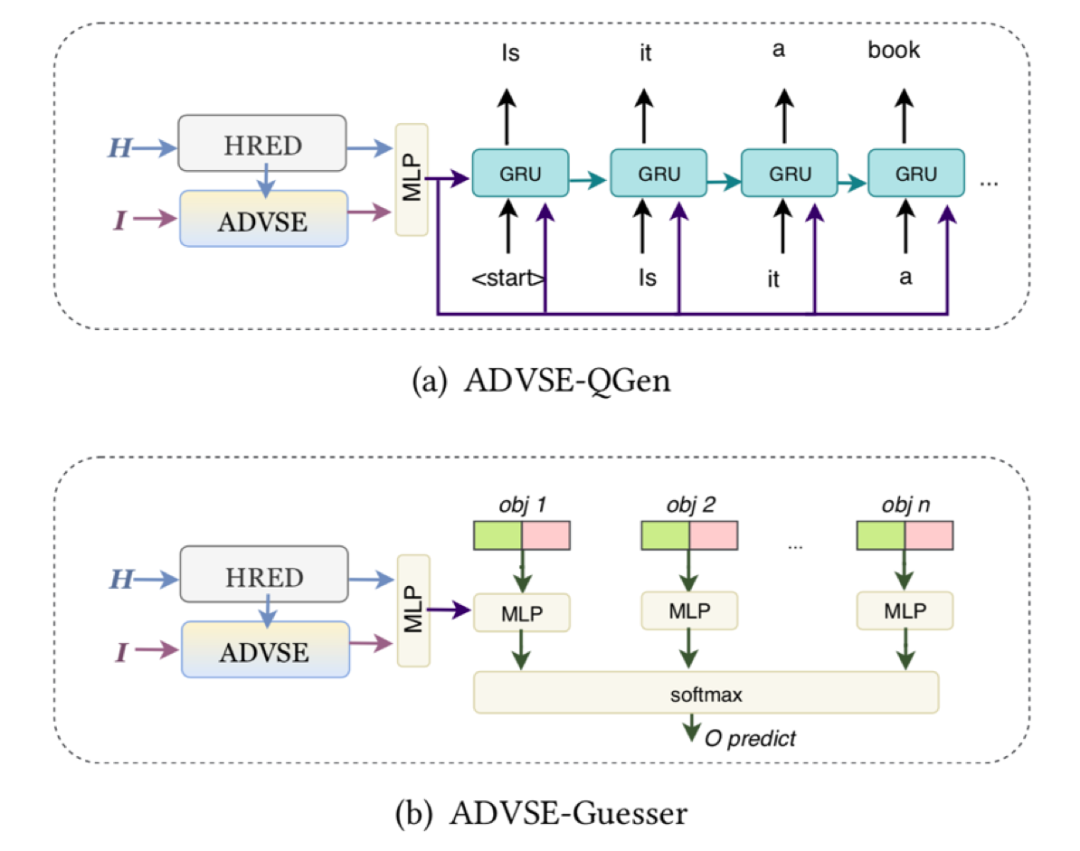
图 3 响应驱动的视觉状态估计器用于问题生成和回答示意图
在视觉对话的国际公开数据集 GuessWhat?!上的实验结果表明,该模型在问题生成和回答上都取得了当前的领先水平。我们首先给出了 ADVSE-QGen 和 ADVSE-Guesser 与最新模型对比的实验结果。
此外,我们评测了联合使用 ADVSE-QGen 和 ADVSE-Guesser 的性能。最后,我们给出了模型的定性分析内容。我们模型的代码即将可从ADVSE-GuessWhat获得。
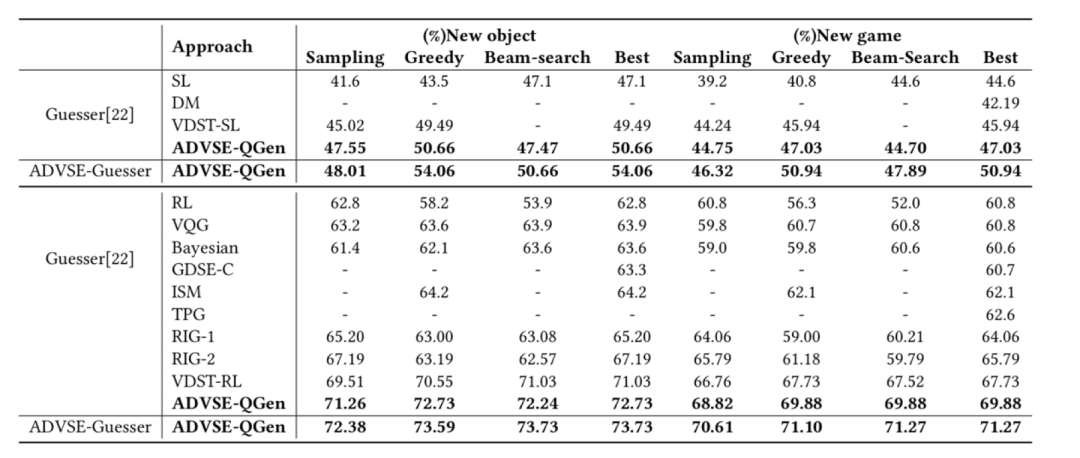
表 1 QGen 任务性能对比,评测指标为任务成功率
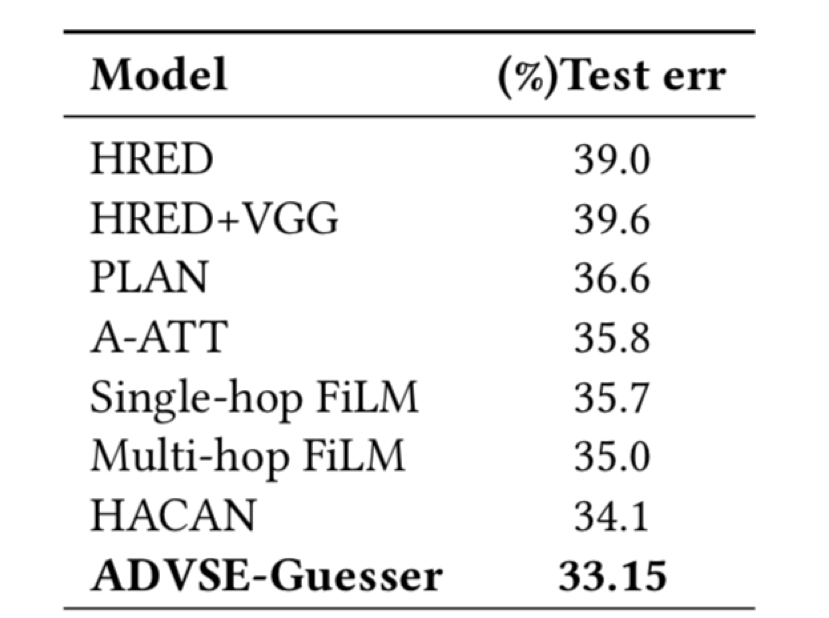
表 2 Guesser 任务性能对比,评测指标为错误率

图 4 问题生成过程中响应驱动的注意力转移样例分析

图 5 ADVSE-QGen 对话生成样例
总结
本论文提出了一种响应驱动的视觉状态估计器(ADVSE),以强调在目标导向的视觉对话中不同响应对视觉信息的重要影响。首先,我们通过响应驱动的集中注意力(ADFA)捕获响应对视觉注意力的影响,其中是保持还是移动与问题相关的视觉注意力由每个回合的不同响应决定。
此外,在视觉信息的条件融合机制(CVIF)中,我们为不同的 QA 状态提供了两种类型的视觉信息,然后依情况地将它们融合,作为视觉状态的估计。将提出的 ADVSE 应用于 Guesswhat?!中的问题生成任务和猜测任务,与这两个任务的现有最新模型相比,我们可以获得更高的准确性和定性结果。后续,我们还将进一步探讨同时使用同源的 ADVSE-QGen 和 ADVSE-Guesser 的潜在改进。
参考文献
[1] FlorianStrub,HarmdeVries,JérémieMary,BilalPiot,AaronC.Courville,and Olivier Pietquin. 2017. End-to-end optimization of goal-driven and visually grounded dialogue systems. In Joint Conference on Artificial Intelligence.
[2] Pushkar Shukla, Carlos Elmadjian, Richika Sharan, Vivek Kulkarni, Matthew Turk, and William Yang Wang. 2019. What Should I Ask? Using Conversationally Informative Rewards for Goal-oriented Visual Dialog… In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Association for ComputationalLinguistics,Florence,Italy,6442–6451. https://doi.org/10.18653/v1/P19-1646
[3] JunjieZhang,QiWu,ChunhuaShen, JianZhang, JianfengLu, andAntonvanden Hengel. 2018. Goal-Oriented Visual Question Generation via Intermediate Re- wards. In Proceedings of the European Conference on Computer Vision.
[4] Ehsan Abbasnejad, Qi Wu, Iman Abbasnejad, Javen Shi, and Anton van den Hengel. 2018. An Active Information Seeking Model for Goal-oriented Vision- and-Language Tasks. CoRR abs/1812.06398 (2018). arXiv:1812.06398 http://arxiv.org/abs/1812.06398.
[5] EhsanAbbasnejad, QiWu,JavenShi, andAntonvandenHengel. 2018. What’sto Know? Uncertainty as a Guide to Asking Goal-Oriented Questions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 4150–4159.
[6] Chaorui Deng, Qi Wu, Qingyao Wu, Fuyuan Hu, Fan Lyu, and Mingkui Tan. 2018. Visual Grounding via Accumulated Attention. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 7746–7755.
[7] Tianhao Yang, Zheng-Jun Zha, and Hanwang Zhang. 2019. Making History Matter: History-Advantage Sequence Training for Visual Dialog. In Proceedings of the IEEE International Conference on Computer Vision. 2561–2569.
[8] BohanZhuang, QiWu, ChunhuaShen,IanD. Reid,andAntonvandenHengel. 2018. Parallel Attention: A Unified Framework for Visual Object Discovery Through Dialogs and Queries. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 4252–4261.
作者简介
本文作者包括王小捷、徐子彭、冯方向、杨玉树、江会星、王仲远等等,他们来自北京邮电大学人工智能学院智能科学与技术中心与美团搜索与 NLP 中心团队。
作者介绍:
王小捷
在北京航空航天大学获得博士学位,日本奈良先端科学技术大学院大学访问学者。现为北京邮电大学人工智能学院教授,博士生导师,智能科学与技术中心主任,教育部信息网络工程研究中心副主任,北京邮电大学人工智能学科和专业负责人,中国人工智能学会自然语言理解专委会主任、教育工作委员会副主任。主要研究方向为自然语言处理与多模态计算,主持和参与国家级科研项目二十余项,发表学术论文 200 余篇,曾获中国发明协会科技发明成果一等奖。
本文转载自公众号美团技术团队(ID:meituantech)。
原文链接:

中国卓越技术团队访谈录(2022 年第二季)
本迷你书精选了微软 Edge、蚂蚁可信原生、明源云、文因互联、Babylon.js 等技术团队在技术落地、团队建...











评论