
4 月 29 日凌晨,在一众预告和期待中,阿里巴巴终于发布并开源了新一代通义千问模型 Qwen3。
Qwen3 采用混合专家(MoE)架构,总参数量 235B,激活仅需 22B。其中参数量仅为 DeepSeek-R1 的 1/3,成本大幅下降,性能全面超越 R1、OpenAI-o1 等全球顶尖模型。
Qwen3 还是国内首个“混合推理模型”,“快思考”与“慢思考”集成进同一个模型,对简单需求可低算力“秒回”答案,对复杂问题可多步骤“深度思考”,大大节省算力消耗。
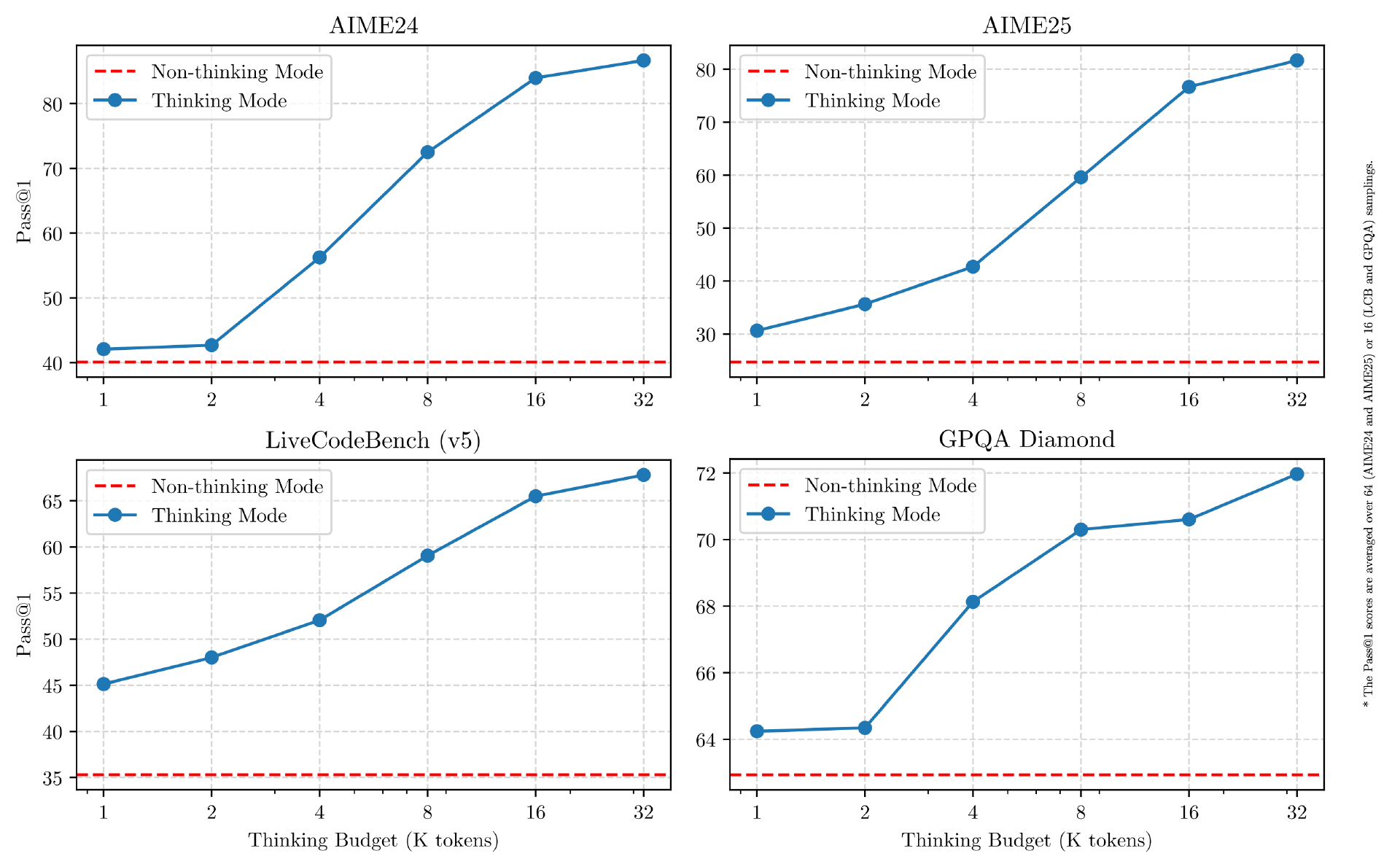
Qwen3 在推理、指令遵循、工具调用、多语言能力等方面均大幅增强。在官方的测评中,Qwen3 创下所有国产模型及全球开源模型的性能新高:在奥数水平的 AIME25 测评中,Qwen3 斩获 81.5 分,刷新开源纪录;在考察代码能力的 LiveCodeBench 评测中,Qwen3 突破 70 分大关,表现甚至超过 Grok3;在评估模型人类偏好对齐的 ArenaHard 测评中,Qwen3 以 95.6 分超越 OpenAI-o1 及 DeepSeek-R1。
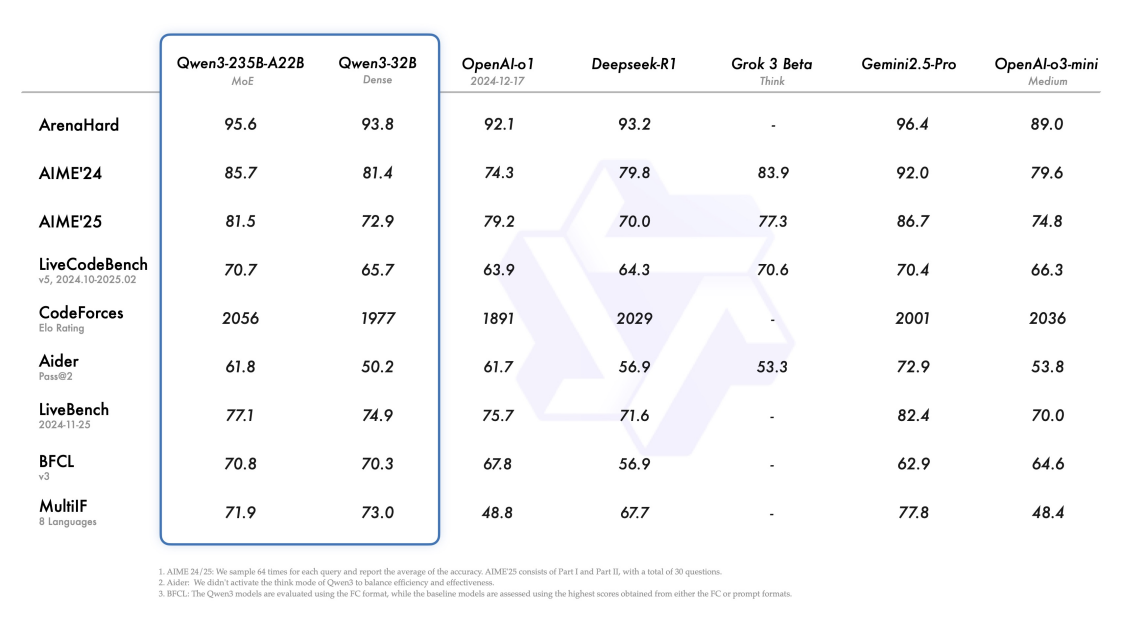
Qwen3 性能图
性能大幅提升的同时,Qwen3 的部署成本还大幅下降,仅需 4 张 H20 即可部署 Qwen3 满血版,显存占用仅为性能相近模型的三分之一。对于部署,官方建议使用 SGLang 和 vLLM 等框架。对于本地使用,官方强烈推荐使用 Ollama、LMStudio、MLX、llama.cpp 和 KTransformers 等工具。
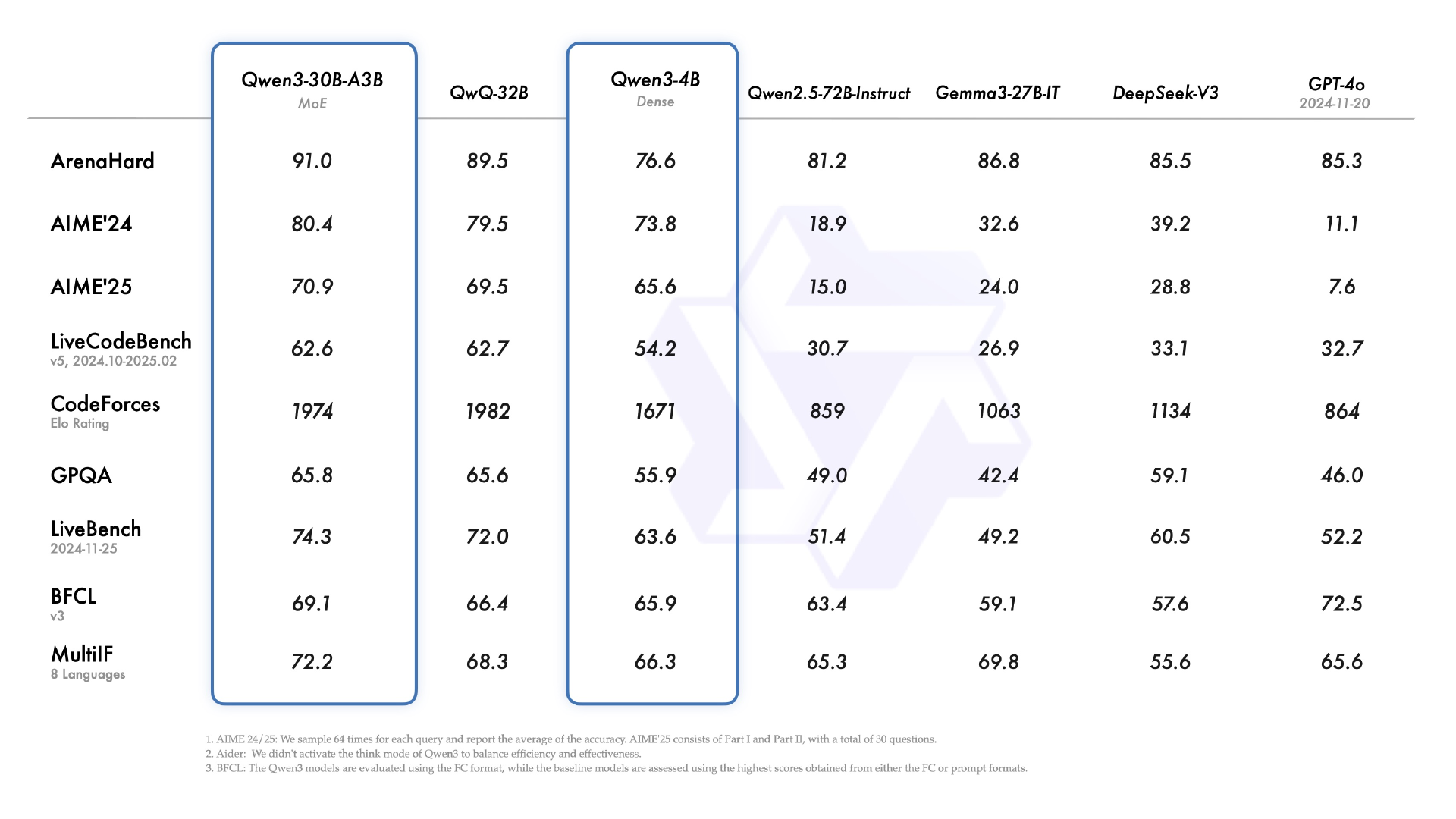
此外,Qwen3 还提供和开源了丰富的模型版本,包含 2 款 30B、235B 的 MoE 模型,以及 0.6B、1.7B、4B、8B、14B、32B 等 6 款稠密模型,每款模型均斩获同尺寸开源模型 SOTA(最佳性能):Qwen3 的 30B 参数 MoE 模型实现了 10 倍以上的模型性能杠杆提升,仅激活 3B 就能媲美上代 Qwen2.5-32B 模型性能;Qwen3 的稠密模型性能继续突破,一半的参数量可实现同样的高性能,如 32B 版本的 Qwen3 模型可跨级超越 Qwen2.5-72B 性能。
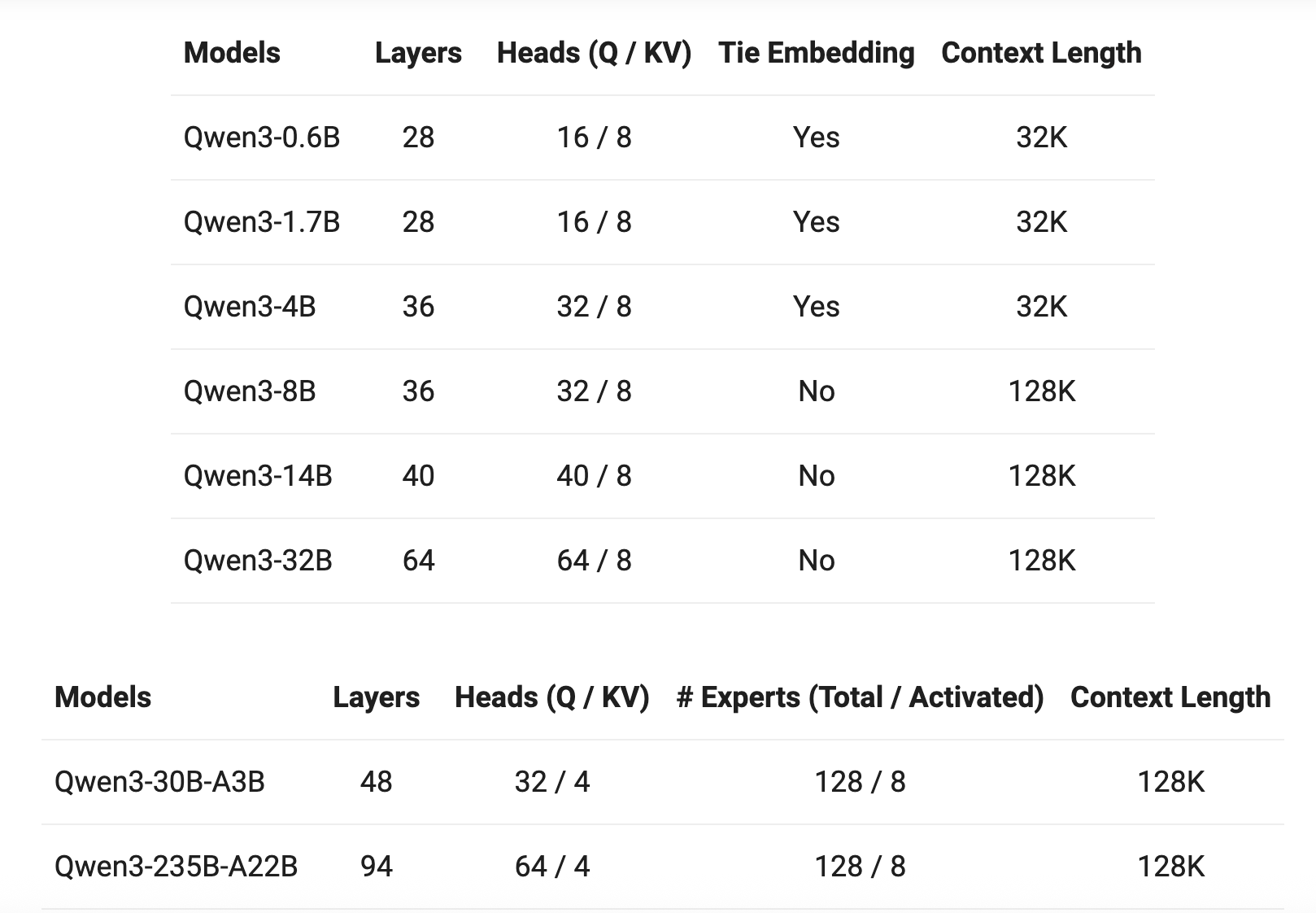
据了解,Qwen3 系列模型依旧采用宽松的 Apache2.0 协议开源,并首次支持 119 多种语言,全球开发者、研究机构和企业均可免费在魔搭社区、HuggingFace 等平台下载模型并商用,也可以通过阿里云百炼调用 Qwen3 的 API 服务。个人用户可通过通义 APP 直接体验 Qwen3,夸克也即将全线接入 Qwen3。
GitHub:https://qwenlm.github.io/blog/qwen3/
Hugging Face:https://huggingface.co/spaces/Qwen/Qwen3-Demo
ModelScope:https://modelscope.cn/collections/Qwen3-9743180bdc6b48
Qwen3 主要特点
混合思维模式
所有 Qwen3 模型都是混合推理模型,支持两种模式:
思考模式:在此模式下,模型会逐步推理,经过一系列思考后再给出最终答案。适用于需要深入思考的复杂问题。
非思考模式:在此模式下,模型快速响应,几乎即时给出答案,适合对速度要求高、但不需要深度推理的简单问题。
用户使用 API 可按需设置“思考预算”(即预期最大深度思考的 tokens 数量),进行不同程度的思考,灵活满足 AI 应用和不同场景对性能和成本的多样需求。比如,4B 模型是手机端的绝佳尺寸;8B 可在电脑和汽车端侧丝滑部署应用;32B 最受企业大规模部署欢迎,有条件的开发者也可轻松上手。
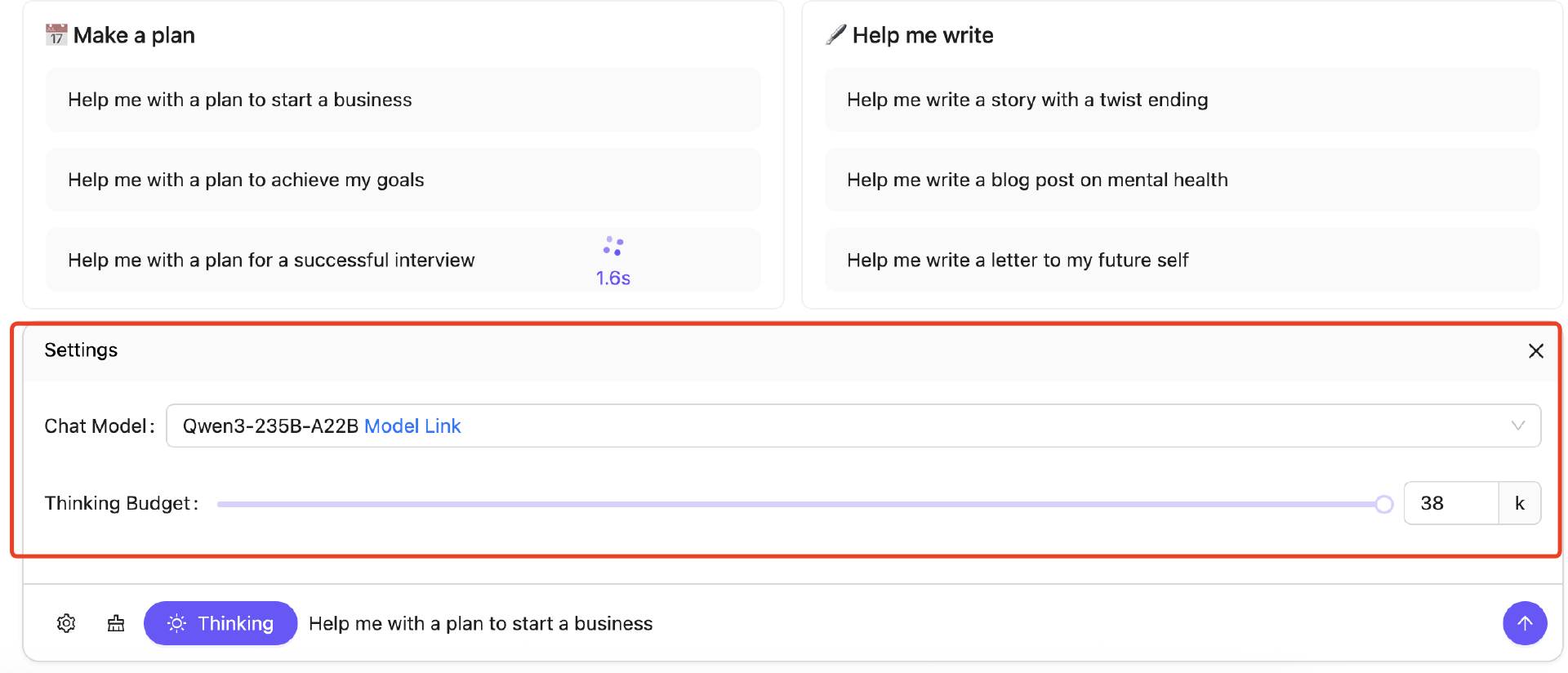
该设计使 Qwen3 展现出与推理预算成正比的、可扩展且平滑的性能提升。用户能够更轻松地根据不同任务配置推理预算,在成本效率与推理质量之间实现更优的平衡。
增强对 Agent 支持
Qwen3 为即将到来的智能体 Agent 和大模型应用爆发提供了更好的支持。团队优化了 Qwen3 模型的编码和 Agent 能力,并增强了对 MCP 的支持。以下视频展示 Qwen3 如何思考以及如何与环境交互。
在评估模型 Agent 能力的 BFCL 评测中,Qwen3 创下 70.8 的新高,超越 Gemini2.5-Pro、OpenAI-o1 等顶尖模型,将大幅降低 Agent 调用工具的门槛。同时,Qwen3 原生支持 MCP 协议,并具备强大的工具调用(function calling)能力,结合封装了工具调用模板和工具调用解析器的 Qwen-Agent 框架,将大大降低编码复杂性,实现高效的手机及电脑 Agent 操作等任务。
支持 MCP 的功能确实让社区开发者们感到兴奋。“Qwen2.5 的工具调用行为在不同型号之间不一致,这让我抓狂。微调后的 MCP 真是太棒了。”有开发者说道。
此外,研究员 ChujieZheng 表示,Qwen3 有一些非常有趣的功能没有在模型卡上写出来。
Qwen3 的技术改进
预训练
在预训练方面,Qwen3 的数据集相比 Qwen2.5 有了显著扩展。Qwen2.5 是在 18 万亿个 token 上进行预训练的,而 Qwen3 使用了几乎两倍的数据量,约 36 万亿个 token,涵盖了 119 种语言和方言。
为了构建如此大规模的数据集,Qwen3 不仅从网页收集数据,还从类似 PDF 的文档中提取内容。团队使用 Qwen2.5-VL 从这些文档中提取文本,并用 Qwen2.5 提升提取内容的质量。为了增加数学和代码数据的比例,团队还利用 Qwen2.5-Math 和 Qwen2.5-Coder 生成了合成数据,包括教科书、问答对以及代码片段等。
预训练过程分为三个阶段。在第一阶段(S1),模型在超过 30 万亿个 token 上进行预训练,使用的上下文长度为 4K tokens。这一阶段使模型掌握了基础语言能力和通用知识。在第二阶段(S2),团队提升了数据集的质量,增加了 STEM、编程和推理等知识密集型数据的比例,并在额外的 5 万亿个 token 上进行了进一步预训练。在最后一个阶段,使用高质量的长上下文数据,将模型的上下文长度扩展到了 32K tokens,以确保模型能够有效处理更长的输入。
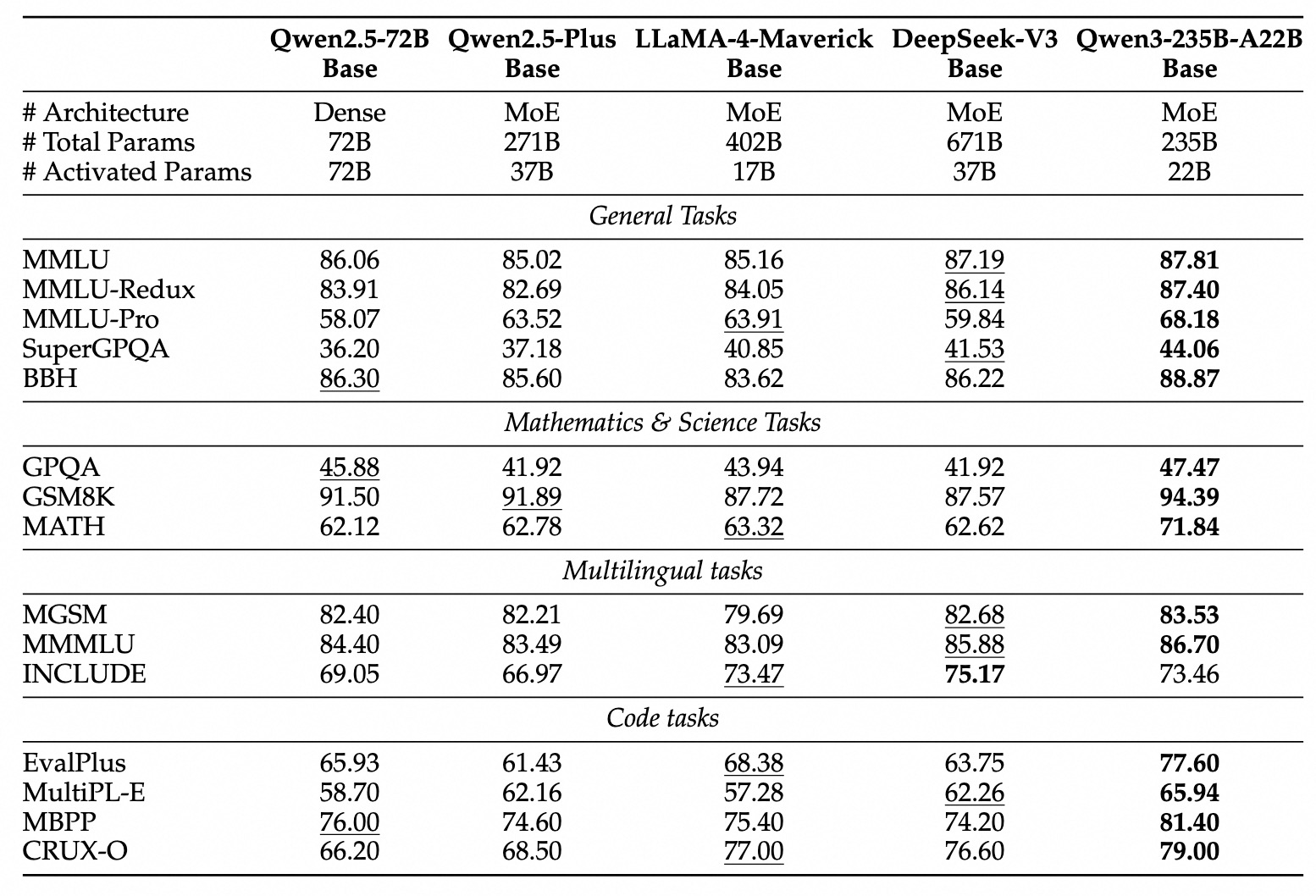
由于模型架构的进步、训练数据量的增加以及更高效的训练方法,Qwen3 的稠密基础模型整体性能已经达到了参数量更大的 Qwen2.5 基础模型的水平。
例如,Qwen3-1.7B/4B/8B/14B/32B-Base 的性能分别相当于 Qwen2.5-3B/7B/14B/32B/72B-Base。值得注意的是,在 STEM、编程和推理等领域,Qwen3 的稠密基础模型甚至超越了更大规模的 Qwen2.5 模型。对于 Qwen3-MoE 基础模型,它们仅使用 10% 的激活参数,就能达到与 Qwen2.5 稠密基础模型相近的性能,从而在训练和推理成本上实现了显著节省。
后训练
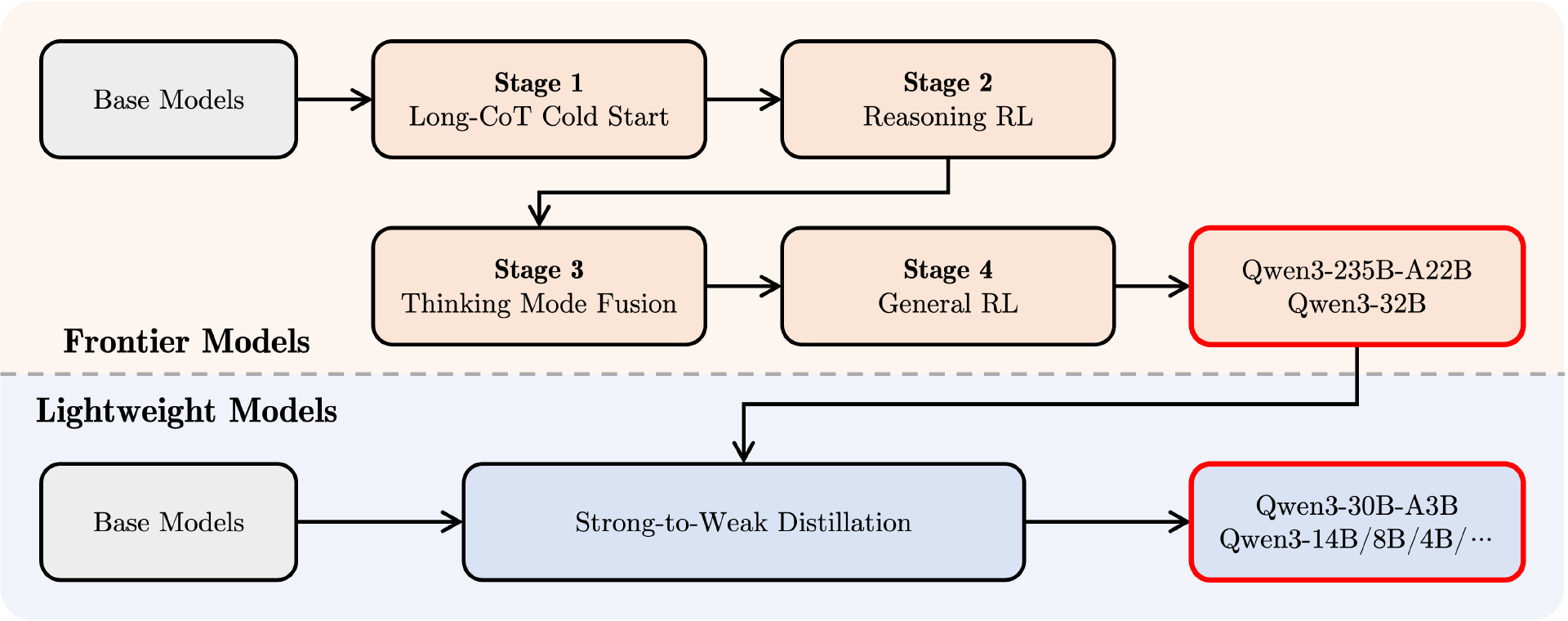
为了开发能够兼顾逐步推理与快速响应的混合模型,团队设计并实现了一个四阶段的训练流程,该流程包括:(1) 长链式思维(CoT)冷启动,(2) 基于推理的强化学习(RL),(3) 思维模式融合,以及 (4) 通用强化学习。
第一阶段,团队使用多样化的长链式思维数据对模型进行微调,涵盖数学、编程、逻辑推理、STEM 问题等不同任务和领域。此过程旨在赋予模型基本的推理能力。
第二阶段则专注于扩大强化学习的算力规模,利用基于规则的奖励机制,提升模型的探索与利用能力。
第三阶段,通过在长链式思维数据与常规指令微调数据的组合上进行微调,将非思考型能力融入思考型模型。这些数据由第二阶段增强后的思考模型生成,从而实现推理与快速响应能力的自然融合。
第四阶段,团队在 20 多个通用领域任务上应用强化学习,进一步增强模型的通用能力并纠正不良行为。这些任务包括指令跟随、格式遵循、Agent 能力等。
对此,网友 Nathan Lambert 指出,Qwen3 的后训练堆栈与 deepseek R1 极为相似,Qwen3 提炼出了更小的模型。
网友反馈
Qwen3 发布后,一些开发者已经迫不及待使用了。
苹果机器学习研究员 Awni Hannun 使用后表示,Qwen3 235B MoE(激活参数为 22B)在搭载 mlx-lm 的 M2 Ultra 上运行非常快:4 比特量化模型占用约 132GB 内存;生成了 580 个 token,速度约为 28 token/秒。
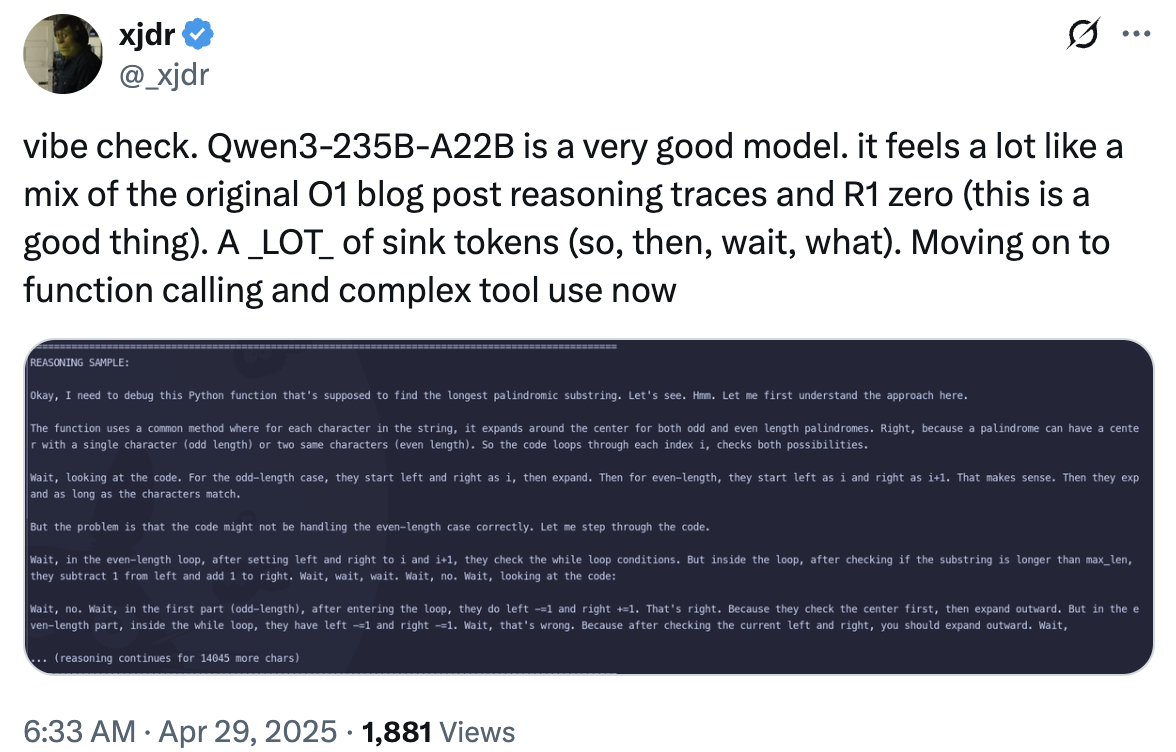
网友 xjdr 表示,Qwen3-235B-A22B 是一个非常优秀的模型。“它的感觉很像是原始 o1 博客文章中的推理轨迹和 R1 zero 的结合(这是件好事)。但模型出现了大量的“sink tokens”,比如 so、then、wait、what 等。”
编程方面,xjdr 评价为:写 JAX 的即时编译(jitted)代码,就像在用 Python 玩《黑暗之魂》。
而 T3 Chat 的首席执行官 Theo - t3.gg 指出,Qwen3 延续了 Qwen 系列在任务处理中严重过度思考的趋势,在回答问题之前会生成成千上万的思考标记(tokens),并因此耗尽上下文长度。
据悉,阿里通义已开源 200 余个模型,全球下载量超 3 亿次,Qwen 衍生模型数超 10 万个,已超越美国 Llama。
Qwen3 发布后,有网友喊话,“扎克,你最好现在就释放巨兽。”还有人开玩笑道,“扎克伯格要让他的工程师赶紧加班了。”




