

1、背景
2018 年底,vivo AI 研究院为了解决统一高性能训练环境、大规模分布式训练、计算资源的高效利用调度等痛点,着手建设 AI 计算平台。经过两年的持续迭代,平台建设和落地取得了很大进展,成为 vivo AI 领域的核心基础平台。平台从当初服务深度学习训练为主,到现在演进成包含 VTraining、VServing、VContainer 三大模块,对外提供模型训练、模型推理和容器化能力。VContainer 是计算平台的底座,基于 Kubernetes 构建的容器平台,具备资源调度、弹性伸缩、零一混部等核心能力。VContainer 容器集群有数千个节点,拥有超过 100PFLOPS 的 GPU 算力。集群里同时运行着上千个 VTraining 的训练任务和上百个 VServing 的推理服务以及数百个在线服务项目。本文主要分享了 VContainer 容器平台在服务弹性伸缩部署方面的实践和落地。
2、整体架构
业务容器化之后可以使用容器在服务器上高密度部署,以此提高集群整体的资源利用率。业务稳定运行一段时间之后,我们发现集群整体的资源利用率仍然存在巨大的提升空间,当前集群资源使用主要有以下问题:
(1)在线服务申请资源时考虑到突发流量和服务稳定性,预留大量的 buffer 资源,造成资源申请量普遍远超实际使用量。
(2)大部分在线服务的潮汐现象、波峰波谷特征非常明显,保留过多常态资源造成巨大浪费。
(3)开发和运维评估和配置的资源规格不合理,并且动态更新不及时。
为了进一步提升集群整体的资源利用率、降低服务器成本,我们调研了 kubernetes HPA 弹性伸缩并进行了落地实践。
kubernetes 将业务运行环境的容器组抽象为 Pod 资源对象,并提供各种各样的 workload(deployment、statefulset 等)来部署 Pod,同时也提供多种资源对象来解决 Pod 部署过程中的弹性伸缩和资源供给问题。
2.1 kubernetes autoscaling
kubernetes autoscaling 提供多种机制来满足 Pod 自动伸缩需求:
(1)Pod 级别的自动伸缩:包括Horizontal Pod Autoscaler(HPA)和Vertical Pod Autoscaler(VPA)。其中 HPA 会基于 kubernetes 集群内置资源指标或者自定义指标来计算 Pod 副本需求数并自动伸缩,VPA 会基于 Pod 在 CPU/Memory 资源历史使用详情来计算 Pod 合理的资源请求并驱逐 Pod 以更新资源配合;
(2)Node 级别的自动伸缩:Cluster Autoscaler(CA)会综合考虑 Pod 部署挂起或集群容量等信息确定集群节点资源并相应调整集群 Node 数量。
本文聚焦于 kubernetes 集群 Pod 级别的弹性伸缩实践和落地。
2.2 KEDA
kubernetes HPA 原生支持依据 CPU/Memory 资源利用率弹性伸缩,并在 autoscaling/v2beta2 版本中通过custom.metrics.k8s.io API 支持基于自定义资源的弹性伸缩。在 HPA 实践落地过程中,仅仅依赖 CPU/Memory 利用率弹性伸缩无法满足业务在多指标扩缩、弹性伸缩稳定性方面的诸多需求,为此,我们重点调研了 kubernetes HPA 自定义指标弹性伸缩。开源社区主要有 2 个相关项目,一个是 prometheus-adapter,另外一个是KEDA,最终我们采用 KEDA 作为弹性伸缩系统的基座,主要考虑到如下优势点:
(1)功能丰富:内嵌 CPU/Cron/Prom 多种伸缩策略,原生支持缩容至零;
(2)扩展性好:解耦被伸缩对象(支持/scale 子资源即可)和伸缩指标,提供强大的插件机制和抽象接口(scaler + metrics adapter),增加伸缩指标非常便利;
(3)维护性好:设计简洁、功能统一、组件单一提供良好的可维护性;
(4)社区强大:CNCF 官方项目,微软和 RedHat 强力支持。
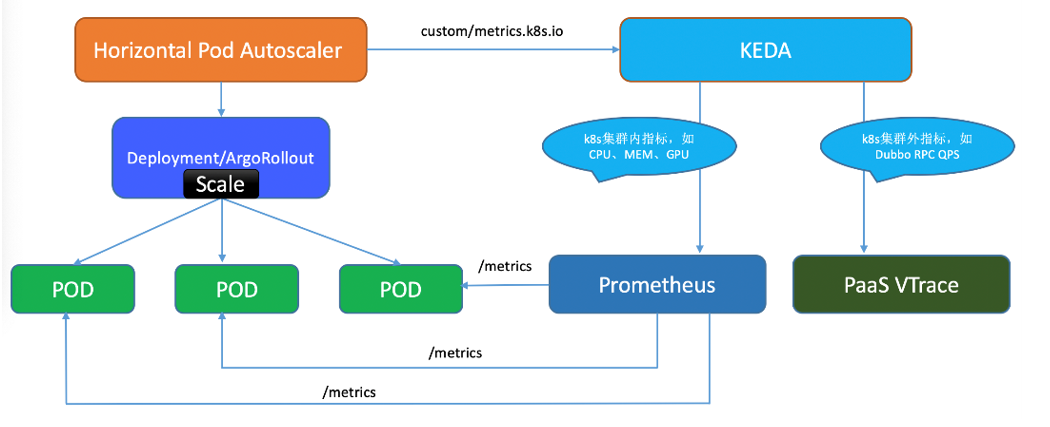
我们基于 KEDA 构建 kubernetes 集群弹性伸缩系统,整体流程图如下所示:
(1)集群 Pod 部署会采用多种 workload(deployment、argoRollout、statefulset 等),KEDA 均支持这些伸缩对象,最终实际生效对象其实是/scale 子资源;
(2)所有的弹性伸缩对象统一使用 KEDA 管理,包括 HPA 内置支持的 CPU/Memory 利用率弹性伸缩、自定义指标弹性伸缩。我们基于 KEDA 强大的插件机制扩展支持了业务亟需的 GPU 利用率弹性伸缩和 HTTP/RPC QPS 弹性伸缩;
(3)测试集群和预发集群部署业务默认开启缩容至零特性,以此自动回收长期闲置的测试服务所占用的计算资源;
(4)基于 KEDA 在自动伸缩多策略、扩缩时效性、扩缩耗时、成功率、监控告警等稳定性方面做了一系列工作
3、多指标弹性伸缩
业务方在发布平台做业务部署时,可以直接白屏化配置合适的弹性伸缩策略,整体界面如下所示:
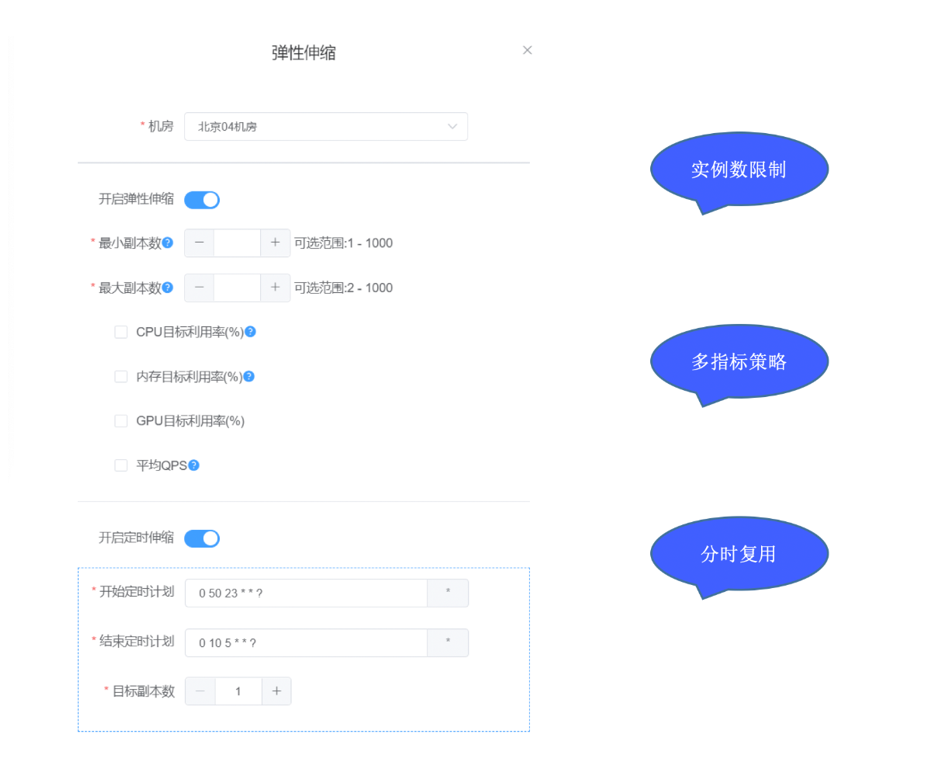
弹性伸缩策略整体分为两大部分:
(1)常规弹性伸缩:包括 CPU 利用率、内存利用率、GPU 利用率、平均 QPS,并且伸缩策略都支持配置 伸缩区间(最小副本数 <= 伸缩目标副本数 <= 最大副本数)。
(2)定时伸缩:资源使用具有强周期规律、潮汐特征明显的业务可以配置定时伸缩,应用副本数在对应时间段内保持在指定数量。
3.1 CPU/Memory 默认弹性伸缩
CPU/Memory 弹性伸缩中,我们只使用平均利用率类型的伸缩指标,整体数据流程如图所示:

3.2 Cron 定时伸缩
互联网在线业务通常都有明显的流量波峰波谷现象,潮汐特征非常明显,针对这种资源使用具有周期规律的业务,我们通常采用定时伸缩。
kubernetes HPA 计算 ExternalPerPodMetric 副本数: 当前利用率/每个 Pod 目标利用率
KEDA CronHPA 中 将 "每个 Pod 目标利用率" 硬编码固定为 1,当前利用率 设置为 定时扩缩容时间段的副本数。这个巧妙的设计可以将普通的资源利用率弹性伸缩和定时伸缩统一起来,非常便利。
3.3 GPU 弹性伸缩
集群部分业务会使用 GPU 资源做 AI 模型推理计算,这种场景下业务方重点关注 GPU 利用率,希望可以基于 GPU 资源利用率做动态伸缩。我们基于 KEDA scaler 插件机制开发了 gpu-scaler,很好的满足了业务方需求。
GPU 弹性伸缩中整体数据流程如图所示:

3.4 QPS 弹性伸缩
集群部分业务方重点关注服务 QPS(HTTP/RPC),希望可以基于服务 QPS 做动态伸缩。我们基于 KEDA scaler 插件机制开发了 qps-scaler,很好的满足了业务方需求。
QPS 弹性伸缩中整体数据流程如图所示:

4、缩容到零
业务方在 CICD 发布平台进行流水线部署通常涉及多个运行环境,通常有测试环境 → 预发环境 → 生产环境,其中测试环境主要用来开发联调,预发环境主要用来小流量验证和预部署校验。
业务方在生产集群部署业务之后,测试环境和预发环境的实例副本通常会闲置,这会浪费一部分的计算资源,尤其是使用到 GPU 稀缺资源的业务。为此,我们在测试环境和预发环境默认开启了缩容到零特性,缩容规则如下:
4.1 Java 业务
当且仅当业务容器 同时满足以下条件:
a 容器创建时间点至今 大于 48 小时,即 2 天之内新部署的服务不会缩容到零;
b 基于请求数做缩容到零:PaaS 调用链查询 API 获取的 64 小时内请求总数 等于 0,即 64 小时内业务在调用链系统内无任何请求数据;
4.2 GPU 业务
当且仅当服务容器 同时满足以下条件:
a 容器创建时间点至今 大于 48 小时,即 2 天之内新部署的服务不会缩容到零;
b 基于 GPU 利用率做缩容到零:容器平台 prometheus 获取的 2 天内 GPU 利用率峰值 小于 1%,即 2 天内业务 GPU 利用率峰值小于 1%;
某些服务使用了特殊的自定义应用层协议(例如非 HTTP/Dubbo RPC 协议的 CPU 服务),这些服务暂不适合缩容至零,容器平台提供选项来关闭这个功能。
5、分时复用
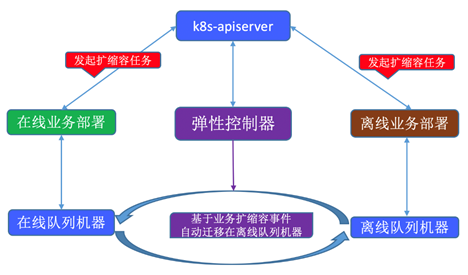
在线业务弹性缩容会提升业务维度的资源利用率,但是对于整个计算集群,由于缩容腾出的资源并没有充分利用,集群维度的资源利用率并没有得到相应的提升。基于此现状,我们开发了弹性控制器,让集群内的弹性资源充分的分时复用,整个流程如下所示:
(1)弹性控制器基于 kubernetes controller 标准范式开发,一直监听在线业务的扩缩容事件,并且自动迁移在离线资源池机器;
(2)在线业务缩容时,弹性控制器确保节点空载状态(整机部署的业务缩容之后直接空载)之后 会将在线节点自动迁移到离线任务队列,离线业务部署控制器会自动提交并运行一些训练任务;
(3)在线业务扩容时,弹性控制器会尽快供应所需的计算资源,首先会启用 buffer 资源池机器,如若不足会继续驱逐离线训练任务(综合考虑离线训练任务定义的优先级、最大可驱逐副本数、整机驱逐代价等众多因素) 然后将离线节点自动迁移到在线业务队列;
6、稳定性建设
弹性伸缩的主要目标在于提升计算资源利用率,降低服务器资源成本。同时,弹性伸缩涉及应用副本数的动态增减,系统稳定性至关重要,需要确保应用副本符合预期地动态伸缩、保障应用负载在合理范围、确保服务的 SLO 高可用性。为此,我们围绕弹性伸缩做了一系列工作。
6.1 弹性伸缩可观测(历史记录、事件通知)
容器平台基于 prometheus 指标数据实现弹性伸缩的可观测,主要包括伸缩动作的时间点、服务副本数变化详情、服务伸缩时可用性、实例伸缩的整体耗时以及结果详情,这些指标统一聚合在统一展板内,非常清晰的展现弹性伸缩详情以及高度联动的服务可用性详情。这些指标的历史数据都通过分布式存储系统管理,便于回溯历史记录。
应用实例动态伸缩的过程中,会出现一些异常情况,例如资源紧缺导致扩容长时间夯住、缺失健康检查机制导致扩容时流量有损、缩容策略不合理导致应用负载上涨影响服务可用性,针对这些异常情况,我们完善了相应的监控指标以及告警机制,异常事件实时通知到相应业务方。
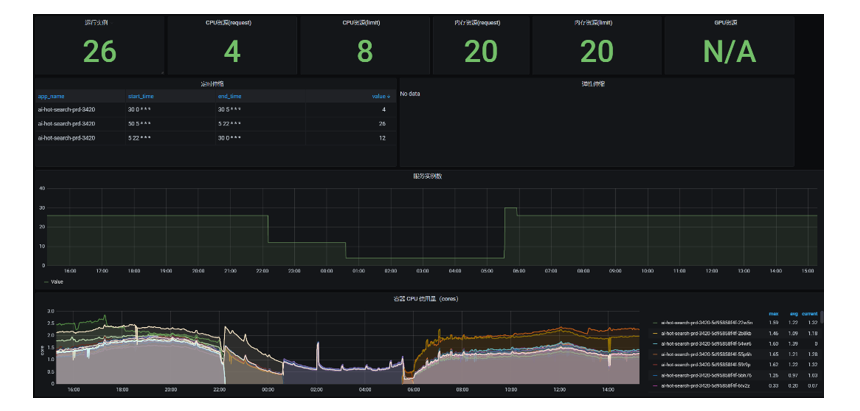
6.2 实例数上下限+多指标混合扩缩
kubernetes HPA 提供实例副本上下限选项保证弹性伸缩一直在确定范围区间内,开发运维在发布平台配置弹性伸缩策略时 会强制要求设置最小副本数和最大副本数。容器平台提供服务运行详情的历史监控图,开发运维以此可以非常便利地确定服务副本的合理区间。
部分业务方在使用弹性伸缩的过程中发现只依据单指标扩缩会不准确,针对这种场景,我们推荐业务方使用多指标混合扩缩,例如将 CPU 利用率弹性伸缩和定时伸缩混合使用,既可以满足流量请求和资源使用具有周期性规律的场景,又可以满足流量突发的场景。kubernetes HPA 针对每个伸缩策略都会计算出一个目标副本数,最终取其最大值,尽可能确保服务稳定性。
6.3 快扩慢缩防抖动
kubernetes HPA 实现细节里提供一些机制来控制扩缩容速率来尽量保证整个过程的平滑,避免实例副本的剧烈抖动:
a 扩缩决策:HPA 控制器每隔 15 秒(--horizontal-pod-autoscaler-sync-period)执行一次扩缩决策,如果当前指标数据值与前一次的变化比例小于 10%(--horizontal-pod-autoscaler-tolerance)则维持当前副本数不变,避免副本数因为指标小幅变化而剧烈震荡波动;
b 扩容:扩容逻辑原则是“快扩”,即扩容尽可能快,其中扩容逻辑的常量因子都是硬编码,无法自定义,在某些场景不符合业务需求;
c 缩容:缩容逻辑原则是“慢缩”,即缩容尽可能慢,缩容决策决定之后需要等待 5min(--horizontal-pod-autoscaler-downscale-stabilization-window)然后才执行实际的缩容操作,这个 5min 是硬编码的全局默认缩容时间窗口;
kubernetes 1.18 版本(官方文档)支持针对服务维度扩缩容的精细化控制,实现不同场景下业务所需的扩缩容灵敏度和速率。我们可以以此特性来调整扩容/缩容的时间窗口,实现不同的快扩慢缩、快扩快缩、慢扩慢缩、慢扩快缩行为。
6.4 健康检查确保流量无损
服务实例动态伸缩的过程中,需要确保流量无损。kubernetes 提供健康检查机制和优雅下线机制来提升服务的可用性。弹性伸缩落地过程中,容器平台会检查服务的健康检查配置并建议合理配置,确保新扩容实例健康检查通过之后才开始接受流量。同时容器平台也会检查服务的优雅下线配置,对于配置缺失的服务,容器平台会自动注入默认的 PreStop lifecycle 配置,确保老实例在下线过程中不会影响当前正在处理的请求
7、后续发展规划
目前容器平台弹性伸缩已经陆续在众多业务落地,正式环境大约 40%业务开启弹性伸缩,预发环境大约 97%业务开启缩容至零,集群 CPU 资源均值利用率从不到 10%提升到 20%左右,GPU 资源均值利用率从 10%左右提升到 25%左右,极大降低服务器资源成本。后续弹性伸缩平台会继续发展演进,进一步降本增效。
7.1 服务画像智能推荐
当前业务方在使用弹性伸缩需要一定的心智负担,例如弹性伸缩策略需要配置服务动态伸缩的最小副本数、最大副本数、目标利用率、定时区间段、资源请求量等,这些指标数据难以精确配置,需要开发和运维依靠历史经验去自行判断,并且时效性较差。
针对这个问题,容器平台会建立服务画像模块,结合服务资源使用详情的历史数据、CPI 指标时序数据、OOM 事件等信息,使用类似 Google Autopilot 的时间滑动窗口+半衰减指数直方图算法来自动预测和智能推荐弹性伸缩相关的诸多配置,进而便于开发运维精准配置弹性伸缩策略,进一步提升资源利用率,同时也大大减轻运维成本和心智负担。
7.2 在离线混部
当前容器平台仅支持在线业务和离线任务分时复用机器资源,运维成本高,资源提升有限,后续我们会和内核、资源调度等团队通力合作探索在离线混部方案
7.3 稳定性建设
弹性伸缩稳定性对业务高可用性至关重要,容器平台会持续建设稳定性。
(1)服务画像全方位探测和精准预测 负载异常、干扰压制、服务受损等异常,及时做出驱逐、扩容(水平扩容或垂直扩容)等决策;
(2)弹性伸缩系统和容量 Quota 系统合作,智能精细化管控业务资源容量,解决弹性扩容过程中的容量受限问题;
(3)弹性伸缩系统会推进周边系统进一步提升弹性扩容卡慢的问题,例如镜像预热和分发加速、原地发布、应用启动提速等。
作者简介:
王杰,曾就职于阿里巴巴,目前是 vivo 人工智能部门计算平台组资深工程师。关注领域:kubernetes、容器、Service Mesh 等云原生技术。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论