在前面的文章中,我们介绍过如何使用 KubeFATE 来部署一个单节点的 FATE 联邦学习集群。在真实的应用场景中,联邦学习往往需要多个参与方联合起来一起完成任务。基于此,本文将讲述如何通过 KubeFATE 和 Docker-Compose 来部署两个参与方的 FATE 集群,并在集群上运行一些简单的测试以验证其功能的完整性。
FATE 集群的组网方式
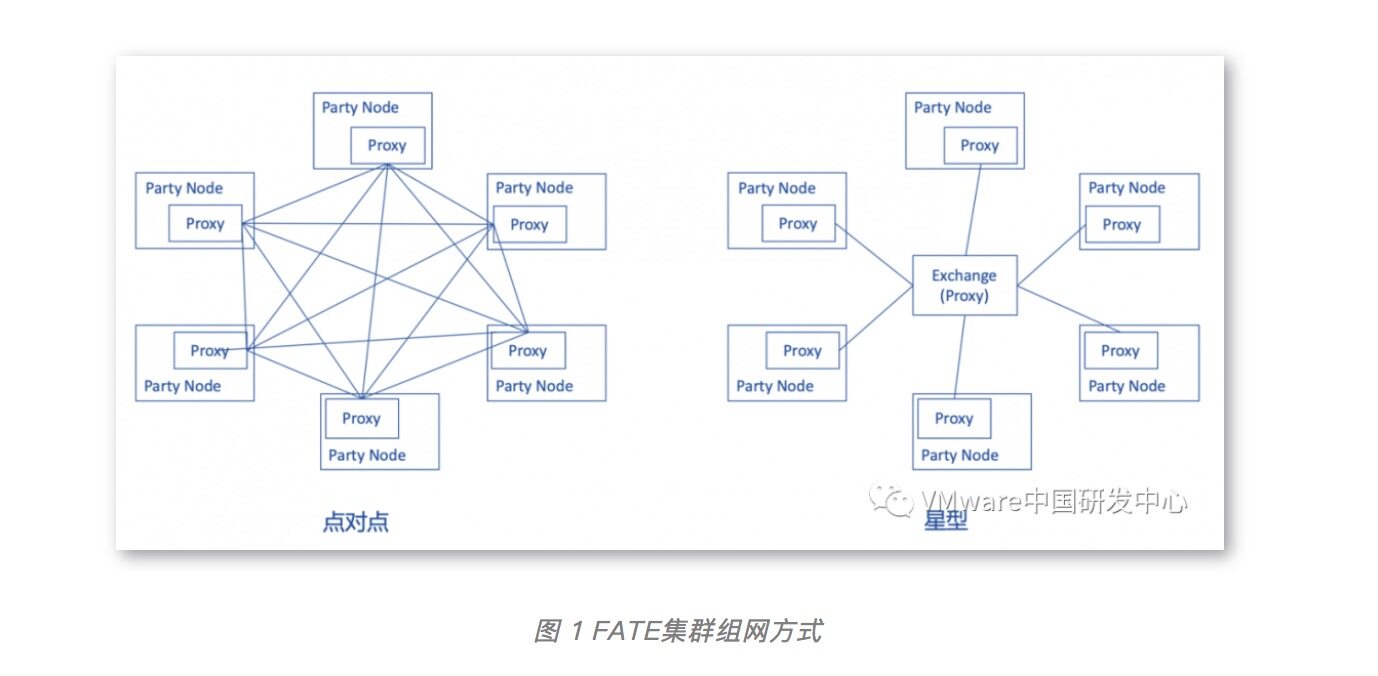
联邦学习的训练任务需要多方参与,如图 1 所示,每一个 party node 都是一方,并且每个 party node 都有各自的一套 FATE 集群。而 party node 和 party node 之间的发现方式有两种。分别是点对点和星型。默认情况下,使用 KubeFATE 部署的多方集群会通过点对点的方式组网,但 KubeFATE 也可以单独部署 Exchange 服务以支持星型组网。
部署两方训练的集群
使用 KubeFATE 和 Docker-Compose 部署两方训练的集群
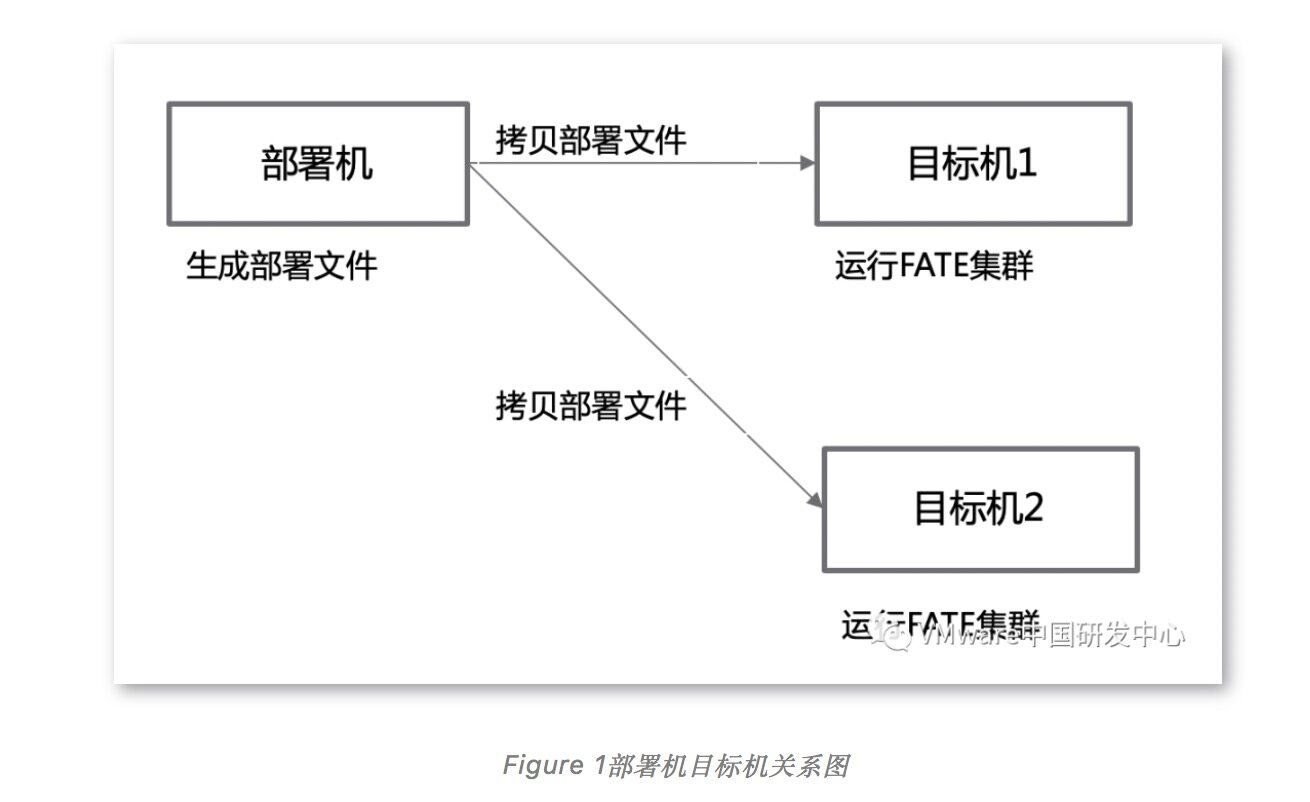
KubeFATE 的使用分成两部分,第一部分是生成 FATE 集群的启动文件(docker-compose.yaml),第二个部分是通过 docker-compose 的方式去启动 FATE 集群。从逻辑上可将进行这两部分工作的机器分别称为部署机和目标机器。
目标
两个可以互通的 FATE 实例,每个实例均包括 FATE 所有组件,实例分别部署在不同的两台机器上。
准备工作
1、两个主机(物理机或者虚拟机,Ubuntu 或 Centos7 系统,允许以 root 用户登录);
2、所有主机安装 Docker 版本 : 18+;
3、所有主机安装 Docker-Compose 版本: 1.24+;
4、部署机可以联网,所以主机相互之间可以网络互通;
5、运行机已经下载 FATE 的各组件镜像
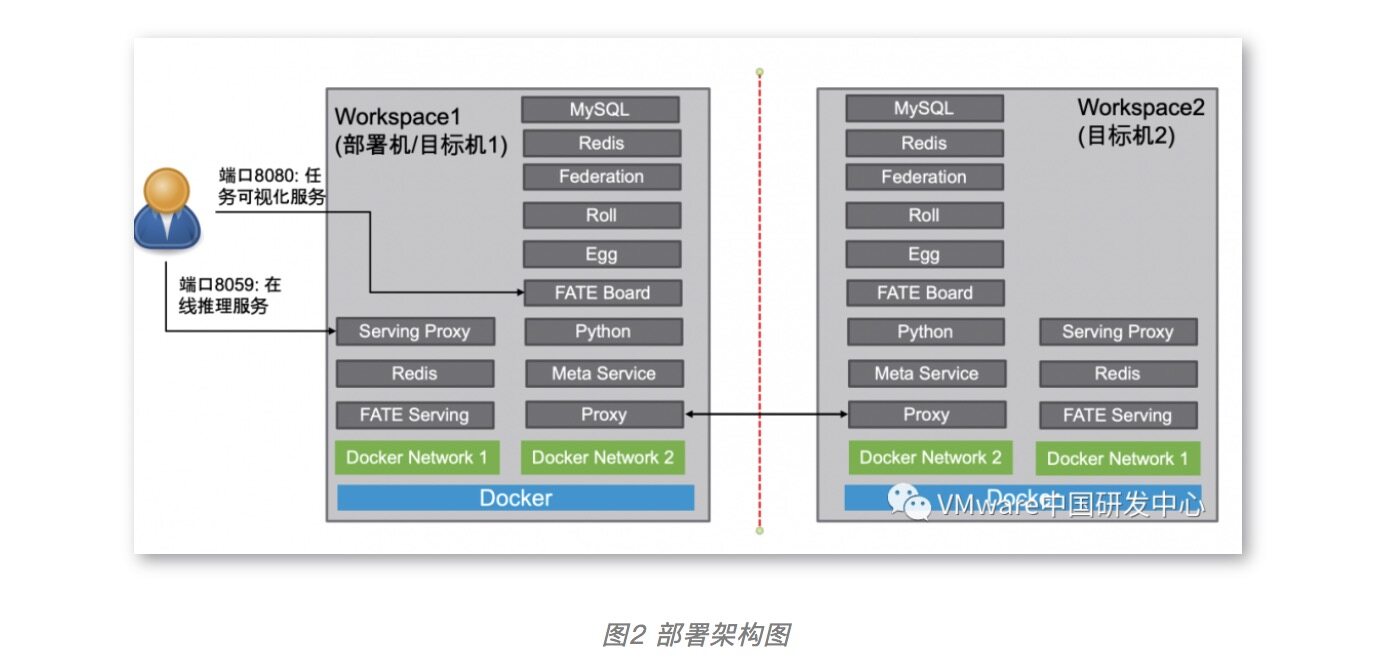
Docker 的安装以及 FATE 镜像的下载请参考前文,接下来我们将把两台主机划分为 workspace1 和 workspace2。其中 workspace1 既作为部署机也作为目标机,而 workspace2 则作为目标机,每个机器运行一个 FATE 实例。这里两台主机的 IP 分别为 192.168.7.1 和 192.168.7.2。用户需要根据实际情况做出修改。具体部署架构如图 2 所示。
以下操作需在 workspace1 上并以 root 用户进行。
下载并解压 Kubefate1.3 的 kubefate-docker-compose.tar.gz 资源包
# curl -OLhttps://github.com/FederatedAI/KubeFATE/releases/download/v1.3.0/kubefate-docker-compose.tar.gz
# tar -xzf kubefate-docker-compose.tar.gz
复制代码
定义需要部署的实例数目
进入docker-deploy目录# cd docker-deploy/
编辑parties.conf如下# vi parties.conf
user=root dir=/data/projects/fate partylist=(10000 9999) partyiplist=(192.168.7.1 192.168.7.2) servingiplist=(192.168.7.1 192.168.7.2) exchangeip=
复制代码
根据以上定义 party 10000 的集群将部署在 workspace1 上,而 party 9999 的集群将部署在 workspace2 上。
执行生成集群启动文件脚本
# bash generate_config.sh
复制代码
执行启动集群脚本
# bash docker_deploy.sh all
命令输入后需要用户输入4次root用户的密码
复制代码
验证集群基本功能
# docker exec -it confs-10000_python_1 bash
# cd /data/projects/fate/python/examples/toy_example
# python run_toy_example.py 10000 9999 1
复制代码
如果测试通过,屏幕将显示类似如下消息:
"2019-08-29 07:21:25,353 - secure_add_guest.py[line:96] - INFO: begin to init parameters of secure add example guest""2019-08-29 07:21:25,354 - secure_add_guest.py[line:99] - INFO: begin to make guest data""2019-08-29 07:21:26,225 - secure_add_guest.py[line:102] - INFO: split data into two random parts""2019-08-29 07:21:29,140 - secure_add_guest.py[line:105] - INFO: share one random part data to host""2019-08-29 07:21:29,237 - secure_add_guest.py[line:108] - INFO: get share of one random part data from host""2019-08-29 07:21:33,073 - secure_add_guest.py[line:111] - INFO: begin to get sum of guest and host""2019-08-29 07:21:33,920 - secure_add_guest.py[line:114] - INFO: receive host sum from guest""2019-08-29 07:21:34,118 - secure_add_guest.py[line:121] - INFO: success to calculate secure_sum, it is 2000.0000000000002"
复制代码
验证 Serving-Service 功能
以下内容将会对部署好的两个 FATE 集群进行简单的训练和推理测试。训练所用到的数据集是”breast”,其中”breast”按列分为”breast_a”和”breast_b”两部分,参与训练的 host 方持有”breast_a”,而 guest 方则持有”breast_b”。guest 和 host 将联合起来对数据集进行一个异构的逻辑回归训练。最后当训练完成后还会将得到的模型推送到 FATE Serving 作在线推理。
以下操作在 workspace1 上进行:
进入python容器
# docker exec -it confs-10000_python_1 bash
进入fate_flow目录
# cd fate_flow
修改examples/upload_host.json
# vi examples/upload_host.json{ "file": "examples/data/breast_a.csv", "head": 1, "partition": 10, "work_mode": 1, "namespace": "fate_flow_test_breast", "table_name": "breast"}
把“breast_a.csv”上传到系统中
# python fate_flow_client.py -f upload -c examples/upload_host.json
复制代码
以下操作在 workspace2 上进行:
进入python容器
# docker exec -it confs-9999_python_1 bash
进入fate_flow目录
# cd fate_flow
修改examples/upload_guest.json
# vi examples/upload_guest.json{ "file": "examples/data/breast_b.csv", "head": 1, "partition": 10, "work_mode": 1, "namespace": "fate_flow_test_breast", "table_name": "breast"}
把“breast_b.csv”上传到系统中
# python fate_flow_client.py -f upload -c examples/upload_guest.json
修改examples/test_hetero_lr_job_conf.json
# vi examples/test_hetero_lr_job_conf.json{ "initiator": { "role": "guest", "party_id": 9999 }, "job_parameters": { "work_mode": 1 }, "role": { "guest": [9999], "host": [10000], "arbiter": [10000] }, "role_parameters": { "guest": { "args": { "data": { "train_data": [{"name": "breast", "namespace": "fate_flow_test_breast"}] } }, "dataio_0":{ "with_label": [true], "label_name": ["y"], "label_type": ["int"], "output_format": ["dense"] } }, "host": { "args": { "data": { "train_data": [{"name": "breast", "namespace": "fate_flow_test_breast"}] } }, "dataio_0":{ "with_label": [false], "output_format": ["dense"] } } }, ....}
复制代码
提交任务对上传的数据集进行训练
# python fate_flow_client.py -f submit_job -d examples/test_hetero_lr_job_dsl.json -c examples/test_hetero_lr_job_conf.json
复制代码
输出结果:
{ "data": { "board_url": "http://fateboard:8080/index.html#/dashboard?job_id=202003060553168191842&role=guest&party_id=9999", "job_dsl_path": "/data/projects/fate/python/jobs/202003060553168191842/job_dsl.json", "job_runtime_conf_path": "/data/projects/fate/python/jobs/202003060553168191842/job_runtime_conf.json", "logs_directory": "/data/projects/fate/python/logs/202003060553168191842", "model_info": { "model_id": "arbiter-10000#guest-9999#host-10000#model", "model_version": "202003060553168191842" } }, "jobId": "202003060553168191842", "retcode": 0, "retmsg": "success"}
复制代码
训练好的模型会存储在 EGG 节点中,模型可通过在上述输出中的“model_id” 和 “model_version” 来定位。FATE Serving 的加载和绑定模型操作都需要用户提供这两个值。
查看任务状态直到”f_status”为 success,把上一步中输出的“jobId”方在“-j”后面。
# python fate_flow_client.py -f query_task -j 202003060553168191842 | grep f_status
output:
"f_status": "success", "f_status": "success",
复制代码
修改加载模型的配置,把上一步中输出的“model_id”和“model_version”与文件中的进行替换。
# vi examples/publish_load_model.json{ "initiator": { "party_id": "9999", "role": "guest" }, "role": { "guest": ["9999"], "host": ["10000"], "arbiter": ["10000"] }, "job_parameters": { "work_mode": 1, "model_id": "arbiter-10000#guest-9999#host-10000#model", "model_version": "202003060553168191842" }}
复制代码
加载模型
# python fate_flow_client.py -f load -c examples/publish_load_model.json
复制代码
修改绑定模型的配置, 替换“model_id”和“model_version”,并给“service_id”赋值“test”。其中“service_id”是推理服务的标识,该标识与一个模型关联。用户向 FATE Serving 发送请求时需要带上“service_id”,这样 FATE Serving 才会知道用哪个模型处理用户的推理请求。
# vi examples/bind_model_service.json{ "service_id": "test", "initiator": { "party_id": "9999", "role": "guest" }, "role": { "guest": ["9999"], "host": ["10000"], "arbiter": ["10000"] }, "job_parameters": { "work_mode": 1, "model_id": "arbiter-10000#guest-9999#host-10000#model", "model_version": "202003060553168191842" }}
复制代码
绑定模型
# python fate_flow_client.py -f bind -c examples/bind_model_service.json
复制代码
在线测试,通过 curl 发送以下信息到 192.168.7.2:8059/federation/v1/inference
curl -X POST -H 'Content-Type: application/json' -d ' {"head":{"serviceId":"test"},"body":{"featureData": {"x0": 0.254879,"x1": -1.046633,"x2": 0.209656,"x3": 0.074214,"x4": -0.441366,"x5": -0.377645,"x6": -0.485934,"x7": 0.347072,"x8": -0.287570,"x9": -0.733474}}' 'http://192.168.7.2:8059/federation/v1/inference'
复制代码
输出结果:
{"flag":0,"data":{"prob":0.30684422824464636,"retmsg":"success","retcode":0}
复制代码
若输出结果如上所示,则验证了 serving-service 的功能是正常的。上述结果说明有以上特征的人确诊概率为 30%左右。
删除部署
如果需要删除部署,则在部署机器上运行以下命令可以停止所有 FATE 集群:
# bash docker_deploy.sh --delete all
复制代码
如果想要彻底删除在运行机器上部署的 FATE,可以分别登录节点,然后运行命令:
# cd /data/projects/fate/confs-<id>/ # the id of party# docker-compose down# rm -rf ../confs-<id>/
复制代码
KubeFATE 开源项目:
https://github.com/FederatedAI/KubeFATE
FATE 开源项目:
https://github.com/FederatedAI/FATE
作者介绍:
陈家豪,VMware 云原生实验室工程师,FATE/KubeFATE 项目贡献者。
相关文章:
《用 FATE 进行图片识别的联邦学习实践》
《使用 KubeFATE 快速部署联邦学习实验开发环境(一)》
















评论 1 条评论