
10 月 30 日下午,2021 WeDataSphere 社区大会在深圳湾科技生态园创新广场顺利举行。现场,开源界大咖、WeDataSphere 社区贡献者和维护者,以及近两百位开源爱好者,大家共聚一堂,交流技术,共论开源之道。

据悉,本次大会不仅邀请到开放原子开源基金会 TOC 主席堵俊平,而且包括 WeDataSphere 社区发起人邸帅、天翼云大数据平台技术专家王小刚、萨摩耶云数据业务部总监易小华和四位微众银行大数据平台工程师均到场。作为开源大数据行业的观察者和实践者,他们纷纷发表了精彩的演讲内容。
堵俊平:Hadoop 没死,开源大数据基于技术和潮流在不断演进
堵俊平是开源大数据行业的“老兵”,他开场先带领大家回顾了开源大数据最近十几年的发展。
在 20 世纪 90 年代,随着互联网的快速发展,数据快速增长,但以前的技术手段无法解决新问题。后来,谷歌基于搜索引擎的多年实践提出“三驾马车”,即 GFS、MapReduce 和 BigTable。这“三驾马车”给 Hadoop 创始人 Doug Cutting 很大的启发,于是,他在 2006 年写出第一个 Hadoop 引擎。这算是业界开源大数据的起点。

开放原子开源基金会 TOC 主席堵俊平
Hadoop 横空出世后,被很多互联网公司和科技公司纷纷采用,因为大家的需求类似——怎么以更低成本提升硬件利用效率,从而最大化地发挥数据价值。之后,Hadoop 在 2008 年从 Apache 毕业,这成为标志性事件。再过一年,第一款大数据云服务在 AWS 上线,这意味着开源大数据走向云时代。
此后,Hadoop 生态加速发展,除了 Hadoop,又有了 Spark、Flink 等。 到 2.0 时代,Yarn 从 Hadoop 中分离, 它把资源管理跟上层的应用调度做了两层分离,这样,在 Hadoop 底层,Yarn 更像一个通用平台,上面是更多的引擎,整个体系可以不断演进。3.0 时代,Hadoop 开始与更多的技术相结合。
纵观整个开源大数据的生态系统,既有新的大数据项目在不断孵化,又有一些式微的开源项目。总体上,它根据技术和潮流的方向不断演进,而非一成不变的静态系统。
大体而言,这个领域的技术有以下趋势:一是统一的 SQL,即 Unified SQL。二是批流的统一。生态趋势上,开源大数据不断衍生和迭代,Hadoop 也没有死,但如果把 Hadoop 视为开源大数据生态体系,那么它仍在蓬勃发展,只是引擎没人在用。

除了回顾开源大数据的发展历程,堵俊平还分享了自己对开源的看法。开源项目有多个角色,包括开发者、用户、厂商和基金会等,每个角色只要持续参与进来,从中找到价值,生态就会持续演进。
邸帅:企业数据平台的建设应该量体裁衣,因地制宜
作为 WeDataSphere 社区发起人、微众银行大数据平台团队负责人,邸帅分享了 “WeDataSphere 大数据平台套件的建设思路和开源历程”。
为什么要建数据平台?邸帅认为这是由于两方面的需要:一是在机构或公司,它是商业化挑战的需要;二是技术挑战的需要。从容量、性能、效率和成本方面,企业要考虑以什么样的技术形式解决构建数据平台的问题。

WeDataSphere 社区发起人 邸帅
他表示,数据平台对于企业,犹如血液循环系统之于人体。
那么,企业如何建设数据平台?借用《平台革命》一书,平台最核心的价值是促成很多最核心的交互,即“参与者 + 价值单元 + 过滤器 =>核心交互”。而最能体现平台价值的能力是吸引、促进和匹配。在数据领域,问题在于怎样提供更好的数据工具和服务,促使数据平台完成吸引、促进和匹配。
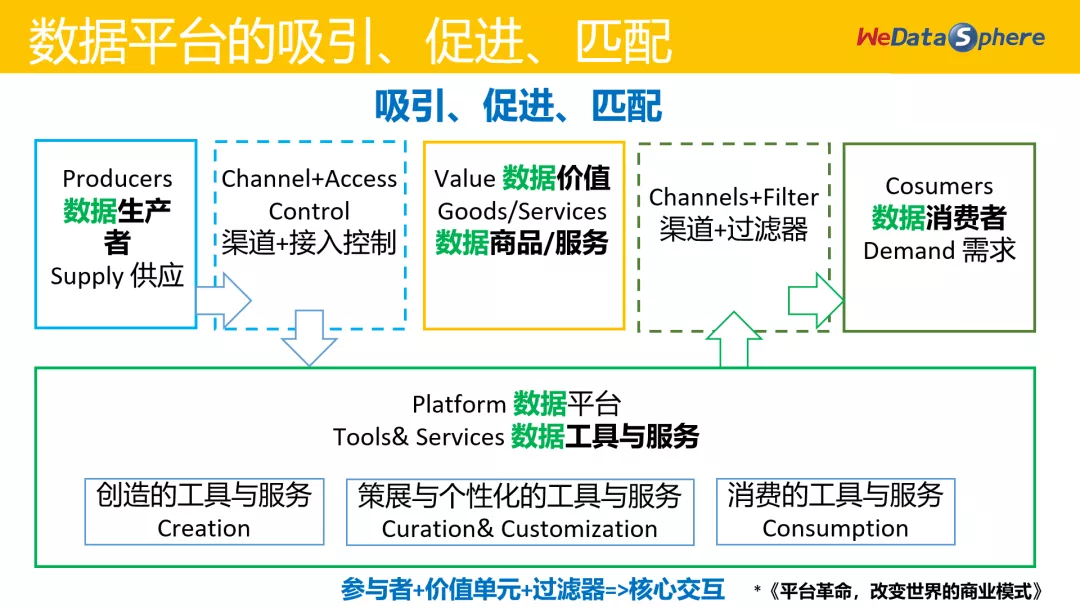
无论是钢铁侠的 AI、云上数仓(比如 Snowflake)或 Gartner 十大数据和分析趋势,在邸帅看来,每个公司或团队真正需要的数据平台应该要量体裁衣,因地制宜,根据自己的情况找到比较好的解决方案。
以量体为例,企业需要在数据管理能力层面、数据平台能力层面和数据应用情况方面摸清现状,从而确立自己的目标。
邸帅表示,“我最想表达的是,如何建设好数据平台,要从数据管理、数据平台、数据应用三个层面摸清现状,然后基于 WeDataSphere + 其他优秀开源项目提供的“布料”来“量体裁衣”。我们 WeDataSphere 的建设思路最核心的三点是:首先方向选择是主力投入上层功能工具系统的建设和开发,底层引擎层更多是做补充,比如 bug 修复。然后两个最核心的设计要点是“一站式”和“全连通”。“
在 WeDataSphere 建设思路上,他指出:数据平台范围庞大,团队规模资源有限,要想做出特色和优势,须从产品架构设计,和多团队共建模式上进一步优化。借用微众银行副行长兼首席信息官马智涛先生的一句话就是“小刀锯大树,必须靠方法。”具体而言,一是通过合理的构建功能工具集成开发框架和中间件层,获得更极致的连通、解耦、易扩展、高度复用能力,简化整体架构和调用关系,大幅降低新功能工具开发和平台运维成本;二是基于“开源”吸引一切可以团结的力量,多方联合共建。
在社区建设层面,微众银行、天翼云、仙翁科技、萨摩耶云、Boss 直聘的团队联合开发了 Streamis。同时,今年,微众银行与合作伙伴还构建了两个大的项目:Exchangis 1.0 和 DataModelCenter。
对于 WeDataSphere 的未来,邸帅表示,首先做得更深,其次做得更广。
尹强:Apache Linkis 是站在四个巨人肩膀上的开源工具
在 WeDataSphere 中,计算中间件 Linkis 解决前台各种工具、应用,和后台各种计算存储引擎间连接简化和复用问题,是非常重要的一环。尹强是 Apache Linkis PPMC,他分享了 Linkis 的建设及开源思路。
先说说大数据平台面临的计算治理问题。大数据平台不断发展,底层有很多的计算存储引擎,上层有很多的应用工具,包括批量计算、交互式计算、流式计算、数据分析工具、数据治理工具等。平台组件越来越多,开发维护愈加困难。这样的背景下,Linkis 诞生,主要解决上层应用工具和底层存储引擎之间关于“连通、扩展、管控、编排、复用等‘计算治理‘问题”。

微众银行大数据技术专家 尹强
针对此问题,目前主要有四个开源社区解决方案:一是 Apache Livy,通过提供 REST 服务,它能简化用户与 Spark 集群的交互。同时,它聚焦于“连接”能力。通过 Job 或代码片段,简化 Spark 任务提交。
二是 Apache Zeppelin,它是基于 Web 的交互式数据分析 Notebook,聚焦于“扩展”能力。独有的 Interpretor 架构,可快速对接新的大数据引擎。
三是 Netflix Geine,它是分布式作业编排引擎,聚焦于“管控”能力。强大的标签体系,支持按需路由作业到不同的 Hadoop 集群。
四是 openLooKeng,它是一款高性能数据虚拟化引擎,提供统一 SQL 接口,具备跨数据源 / 数据中心分析能力。聚焦于“编排”能力。通过编排 SQL,支持跨数据中心、跨云的异构数据源查询。
在尹强看来,这四个解决方案各自特点非常突出,比如 Apache Livy 在连接上做得很好。但是,它们又有不足,因此企业级大数据平台呼唤“既具备扩展又具备管控,还具有编排、连通、复用能力的中间件”。Linkis 是一款站在巨人肩膀上的开源工具,可以极大简化大数据平台的架构,降低开发和运维的复杂度。为什么这么说?
Linkis 构建解耦计算中间件层,具备连通、扩展、管控,、编排和复用能力。连通上,告别应用孤岛,它可以打通用户资源 & 运行时环境。扩展上,通过实现 Linkis EngineConnPlugin,完成新引擎适配,统一解决高并发、高可用、多租户等问题。管控上,它具备基于标签的多级精细化资源控制和回收能力,可以实现多级精细化参数化配置控制。编排上,它基于 Orchestrator 服务的双活策略设计和混算策略设计。复用上,它大大降低上层应用 / 工具开发后台代码量,并基于 Linkis 快速高效打造数据平台工具套件。
最后,尹强谈到了 Apache Linkis 的开源情况和未来规划。从 2019 年 7 月,Linkis 第一个开源版本发布,去年 12 月,社区主导的第一个版本发布。此后,它不断迭代和发展,于 2021 年 7 月进入 Apache 基金会孵化器,并在 9 月荣获 2021 届开源产业大会“OSCAR 尖峰开源项目和开源社区”奖项。
至于未来,一方面是它在 Apache 基金会好好孵化;另一方面,优化社区运营,与生态相关顶级项目建立更紧密合作,同时,产品迭代加速。
王小刚:WeDataSphere 开源组件在天翼云大数据平台产品中的应用
作为天翼云大数据平台团队技术专家,王小刚分享了 WeDataSphere 开源组件在天翼云大数据平台产品中的应用。
首先谈到为什么会与 WeDataSphere 结缘?他解释:内因是电信集团进行“云改数转”战略,天翼云过去的集群存在建设分散,整体资源复用率低,以及数据加工脚本管理混乱,故障频发等问题。外因在于,CDH、HDP 合并,商业版软件订阅费用昂贵,技术绑定,同时,市场缺乏优质的同类开源产品。我们拿自己开刀花了一年多时间从 CDH 商业版升级到 Hadoop 最新版,但光去 CDH 还不够,核心是用户需要统一的大数据平台。我们同时围绕 Hadoop 最新版,拥抱开源、打造自主可控、技术领先、安全稳定的大数据平台。

天翼云大数据平台技术专家 王小刚
之所以了解 WeDataSphere,主要在于 Linkis。“当时,看到它的时候感觉很新鲜,并且和我们的思路一致,它已经开源,平台完善度高,社区也很活跃。它可封装,可水平复制,一站式,非常开放。对我们来说,改造成本适中,运维和维护成本较低。所以,我们选了 Linkis“。
在王小刚看来,Linkis 有强大的入口能力,这正是他们所需的,用它来隔离底层复杂性,保证持续智能优化的可能性。其次,Linkis 奉行开放开源的策略,亲切且先进的架构设计,有相对完善的文档,这些对于开发者来说都是非常友好的。
并且,他们展示了基于 Linkis 持续在做的一些工作,比如更完善的容器化、更大规模的验证、数据源管理、数据集成能力、实时计算能力等,以及后续希望实现跨集群作业提交、SQL 路由、安全能力等等。
在具体实践上,用他的话说:先“玩”起来,深度试用,与内部底座进行整合;然后,逐步完善,修复 bug;接着,针对遇到的一些问题进行较为深度的二次开发;最后就是拥抱开源与社区共建,现在我们已经完全深度参与社区,和社区小伙伴们分工合作,共同研发。
而说到用户体验侧,王小刚提到,随着大数据平台的不断普及,各层级的用户也日益增多,市场主流产品存在一定同质化现象,而在这其中,往往使产品能够脱颖而出的,就是用户易用性的提升。天翼云在这块也做了很多尝试,包括新手引导、产品即文档(产品内置的智能用户手册)、换肤(Dark 模式)、界面优化设计等,都是以用户体验为核心进行优化和打磨。
其中,新手引导主要解决用户首次进入大数据平台的操作问题,帮助用户以轻量化的形式,快速上手常用的功能按键,熟悉产品的界面操作使用。
产品即文档是内置的弹出式帮助中心,主要协助用户解决当前页面 / 功能模块的上手痛点,包括对于该模块的功能介绍,典型步骤介绍,常见问题等。该功能试图排除用户在使用中碰到的 80% 以上的问题,切实给客户提供使用帮助。
Dark 模式是针对开发人员和大数据平台使用者专门打造的护眼模式界面皮肤,基于原配色深度优化,符合开发者的使用和交互习惯,增加开发效率。
最后,随着平台已经拥有越来越多的试用和正式用户,小刚提到,持续围绕“客户成功”这一核心理念来打造产品,是我们始终贯彻的。团队坚持“用户至上、开放共赢、坦诚清晰”,将整个团队也打造成一个产品,给用户带来最好的体验。作为一只充满活力,开源开放的大数据平台团队,希望未来能继续和社区的小伙伴一起把 DataSphere Studio 打造的更友好易用。
王和平:用户需要一站式交互体验的开源数据分析工具
作为 DataSphere Studio 核心开发 ,王和平现场分享了《WeDataSphere 数据分析工场的建设和开源思路》。
他首先介绍了开源数据分析工具的选型思路。在构建数据分析时,用户面临的痛点有哪些?王和平表示,一是数据从哪来、数据安全怎么保证,二是数据怎么分析,怎样进行模型训练,三是数据质量怎么把控,四是分析出的结果如何汇报,五是数据调度怎么做。最后,这么多工具,如何给用户带来一站式的交互体验。

微众银行大数据平台工程师 王和平
对于用户面临的挑战,业界都有相应的工具去解决问题,比如数据分析工具执行交互式分析和模型训练以及任务调度,还有数据交换工具、数据治理工具等。
目前,业界有很多开源的数据交换工具,例如 DATAX、DataX Web、Dbus 和 Exchangis。在数据分析工具上,业界也有 Apache Zeppelin、Scriptis 和 Hue。同样,业界的开源数据治理工具有 pydqc、Apache Atlas、Deequ、Data Hub、GriFFin 和 Qualitis。开源调度工具,业界有 Dolphin Scheduler、XXL、Apache Airflow 和 Schedulis。
虽然工具不少,但是对一个数据分析师来说,它可能并没有真正解决问题。并且,问题还有缺乏标准规范,工程管理体系不统一,用户权限不统一,UI 不统一;应用孤岛,资源物料不互通,运行时上下文不互通。此外,重复造轮子。
为解决这些问题,DataSphere Studio 诞生,它具备一站式、全连通、全流程、可插拔和强管控特点,可以覆盖需求、设计、开发、测试到生产所有阶段,一条工作流串通所有应用工具,上层新工具只需实现 AppConn 插件,便可快速打通其他工具。并且,基于工作空间的多租户隔离,实现以租户为单位进行统一的权限管控、成员管理和协同开发等。
王和平说:“DataSphere Studio 有一个 AppConn,它去做连接,集成其他优秀的开源产品或工具。如果其他开源工具希望集成进来,有三层规范:一层是 SSO 规范,二层是工程组织结构规范(角色规范、工程规范),三层是应用开发流程规范。“
周可:数据治理的六大痛点
周可是微众银行大数据平台工程师,他分享了《WeDataShpere 数据治理工场实践之路》。
目前,企业在数据治理上遇到的痛点有:
一、主数据管理缺失。数据零散、碎片化,数据重复利用和共享存在障碍,存在冗余数据,增加数据使用成本;缺乏全生命周期的主数据管理流程和工具。
二、数据信息存在孤岛。数据分散,形成信息孤岛,共享困难;无法清楚的知道企业里面有哪些数据?无法知道数据的具体结构?存储在什么地方?数据的属主是谁?
三、数据关系难追踪。数据是从哪里来的?数据之间有什么关系?数据是如何在企业内的各系统间传递的?
四、数据质量不高。业务理解与实际开发脱节,数据质量问题突出;缺乏有效的方法和工具提升数据质量。
五、数据安全管控不全面。数据安全等级 / 敏感数据无法自动识别;数据安全风险无法及时发现;数据安全脱敏缺少有效的审计,无法确认数据是否合规使用。
六、数据标准不统一,不规范。数据多样化,缺少统一标准,集成困难;数据里面的同一个术语存在不同的解释,理解困难。

微众银行大数据平台工程师 周可
针对这些问题,开源社区有三种解决方案:
第一种,Pull-based Architecture,特点是较少的组件依赖、一个团队可以搞定,代表性的开源产品有 Amundsen、Metacat、WhereHows。
第二种,Push-based Architecture,特点是统一接入方式、可编程,Marquez 是代表性的开源产品。
第三种,Event-sourced Architecture,特点是元数据可实时更新、元数据模型是开放的,方便拓展。其典型开源产品有 Apache Atlas、DataHub、OpenMetadata。
在数据质量方面,开源社区也有一些解决方案,主要有 Apache Griffin、Great Expectations 和 AWS Deequ。
从个人角度,周可分享了开源产品选型思路。一方面是技术特性,它是否满足场景需求、是否有完善的技术体系、技术产品的稳定性怎么样;另一方面,还需要考虑时间成本与人力成本、是否配置维护团队、新 feature 的开发模式。因此,某种意义上,需要做取舍。
回到 WeDataSphere,周可阐述了 WeDataSphere 在这方面的实践。
目前,随着互联网技术的发展,各大金融机构积累了海量丰富的数据,对数据的管理和应用能力已经成为其核心竞争力之一。同时,大数据的发展带来了企业对个人隐私信息的过度采集和使用的问题。并且,监管部门也对金融数据治理提出了更高的要求。现在,加强数据治理不仅是银行自身发展的需要,也是行业政策规范的重点。
据悉,WeDataSphere 在数据治理上经过三个阶段。
第一阶段,平台化。基于 WeDataSphere 大数据平台,提升数据处理能力和应用效率。
第二阶段,工具化。Data Governance Studio 实现数据管理线上化,并推进安全、质量、成本管控,管好数据。
第三阶段,资产化。数据中台、自动化取数服务。同时,促进数据应用,积累沉淀有价值的数据,实现数据资产化。
周可指出,治理基线在于不仅完善数据治理制度,明确数据授权管理及数据认责、数据分级体系,保护用户隐私,而且规范数据架构,明确数据生命周期管理要求,有力支撑数据应用。
具体说来,数据治理工场 (Data Governance Studio) 要解决数据标准、数据字典、数据访问控制、数据脱敏、数据血缘、数据质量六大问题,为多数据源提供端到端数据治理能力。那么,其基础是建立数据目录,指引数据的获取、访问和使用,辅助数据的有效利用,工具化落地数据管理规范。数据目录可以解决数据在哪里、数据去何处、数据谁在管和数据谁要用的问题。
为了构建好统一的数据目录,内部要先建设元数据中间件,从全局视角管理数据状况。有了元数据目录,就可以形成自动化审批流程,从而在运维里实现自动化处理。有了数据目录,可以实现数据授权统一管理,确保数据合规使用,有迹可循。
易小华:WeDataShpere 在萨摩耶云的应用
易小华是萨摩耶云数据业务部总监,他分享了《WeDataShpere 在萨摩耶云的应用》。
萨摩耶云作为中国领先的独立云服务科技解决方案供应商,以人工智能、大数据、移动互联网和云计算等核心技术能力为支持,通过深度应用 AI 决策,自主研发一系列 SaaS 产品组合及数智萨摩耶云平台,为各行各业的客户提供端到端云原生科技解决方案,包括:金融云解决方案、产业云解决方案、信用云解决方案。

萨摩耶云数据业务部总监 易小华
对萨摩耶云来说,使用 WeDataShpere 之前,流程是业务部门向大数据团队提需求,大数据团队评估需求,然后是排期开发,大数据团队交付成果,最后业务部门验收。当时,数据团队负责公司十几个部门数据分析类需求,但团队规模有限,除了数据类需求,他们还要进行大数据平台的高可用维护、数据仓库迭代开发维护等。往往存在一定的业务开发类需求需要排队等待排期,与业务要求的快速上线相违背。这是数据团队人力资源上的挑战。
其次,萨摩耶云总部位于深圳,分别在上海、长沙等城市设有职场,这让面对面沟通存在一定困难,这也是团队在沟通方面遇到的挑战。
此外,大数据组件众多,这导致形成了大量数据应用孤岛,计算和存储资源使用也不合理。
经过调研后,萨摩耶云最终选择 WeDataSphere。易小华说:“我们也看过其他的同类产品,不是付费,就是功能不完善,社区不活跃,以及国内用户少,开源版本问题较多。”
为什么选择 WeDataShpere?原因主要有五点:
第一,WeDataSphere 提供源代码,社区非常活跃,响应速度很快;
第二,它可以提供本地化部署,能满足数据安全合规需求;
第三,WeDataSphere 能进行定制化开发和功能扩展;
第四,它能解决业务数据的开发痛点;
第五,WeDataSphere 能解决业务自主上线调度的痛点。
除此之外,WeDataSphere 在国内用户较多,认可度较高;提供中文文档,还有微信群在线服务。同时,它用于微众银行内部,在不断迭代。
2020 年 5 月,萨摩耶云正式上线 WeDataSphere,包括可视化、质量监控系统、计算系统、工作流系统和开发系统以及调度。同时,让 WeDataSphere 0.9 版本分别适配内部使用的 CDH 5.14.4 和 CDH 6.3.2。
易小华表示,在使用开源版本过程中,他们发现很多 bug,各组件累计修复了 100+bug。并且,他们还修改了界面风格、图标和文字描述,方便业务人员使用,从而更适合萨摩耶云。
据易小华介绍,业务主要用到数据开发、数据工作流、数据调度和报表可视化等功能,提高数据开发效率 400%+。
萨摩耶云还与微众银行、天翼云等联合研发基于 Linkis 1.0 版本的实时开发组件 Streamis,其中,微众银行负责项目整体协调与把控,微众银行与 Boss 直聘负责 StreamPlugin 和 Stream WorkFlow 模块,天翼云则负责 Stream JobManager 前端,Stream JobManager 后端由仙翁科技负责,萨摩耶云则负责 Stream Datasource 模块。五方利用腾讯会议、企业微信和微信群每周开一次周会,同步进度,共同解决问题。比如,在开发 streamis-datasource-transfer 模块对接 linkis 数据源时,缺少 linkis-datasource 模块,无法推进开发测试,后经微众侧协调,与天翼云团队多方共同推进,解决 streamis 依赖 linkis-datasource 问题。
从 2020 年 5 月上线到现在,WeDataSphere 在萨摩耶云十几个部门得到应用,覆盖用户超 300 人,涵盖风控部门、营销获客部门和研发部门以及职能部门。
在易小华看来,虽然萨摩耶云使用 WeDataSphere 的时间不长,但是团队技能得到很大提升。以前,他们团队人员主要做业务脚本的开发,通过引入 WeDataSphere,提升了团队人员的 Java 应用开发能力。同时,团队具备一战式数据应用开发、集成和治理平台的建设能力,提升了实时计算平台建设能力,比如 Prophecis 二次开发能力。
他说:“向优秀团队学习架构设计、沟通、编码、问题定位等,这进一步提升了我们团队成员的技能。同时,积极参与开源社区,提高了团队影响力和公司口碑。”
在业务层面,通过使用 WeDataSphere,借助开源社区,帮助业务提升数据开发和模型开发效率,降低了业务成本。实时数据使用能力提升,“以前,最快的是 10 分钟才能使用数据,现在基本达到秒级”,帮助业务更快响应。
“我们做业务数据中台和 AI 中台,WeDataSphere 是我们中台重要的技术组件。“他补充道。
吴梓煜:在 WeDataSphere 中构建机器学习工场 Prophecis Studio
作为当天活动的最后一位分享嘉宾,微众银行大数据平台工程师吴梓煜分享了《在 WeDataSphere 中构建机器学习工场 Prophecis Studio 之旅》。
吴梓煜指出,近年来,随着企业数字化转型,金融、零售等行业积累了大量的业务数据。如何从数据中发现价值,辅助业务进行决策,这是各行各业都在探索的。在技术层面,高性能计算、智能化算法等技术的快速发展,也为企业从海量数据中低成本地发现数据价值提供了技术可行性。但是,在机器学习应用实际落地过程中,企业依然面临一系列挑战,包括数据接入难、应用碎片化、工程化复杂、模型部署复杂。

微众银行大数据平台工程师 吴梓煜
而 MLOps 是一种机器学习工程文化和手段,旨在统一机器学习系统开发 (Dev) 和机器学习系统运营 (Ops)。对企业来说,MLOps 实施意味着将在机器学习系统构建流程的所有步骤(包括集成、测试、发布、部署和基础架构管理)中实现自动化和监控。
目前,业界已经有开源的 MLOps 方案。吴梓煜介绍了三种主流的开源 MLOps 方案。第一种是 Kubeflow。它是一个基于 Kubernetes 构建的端到端生产级别机器学习平台,基于云原生的方案,覆盖了机器学习从模型训练、模型开发、模型部署等整个机器生命周期。其主要包括 Notebooks、Pipeline、AutoML、Serving、Arena 等组件。
第二种方案是 MLFlow,它是一款开源端到端机器学习生命周期管理工具,基于 Python 开发,轻量级方案,专注于解决 ML 开发中的 Tracking、工程管理、模型管理与部署等痛点,主要包含 Tracking、Projects、Models 等模块。
第三种方案是天枢人工智能开源平台,国产开源机器学习平台,提供了包括数据处理、模型开发、模型训练和模型管理等功能,方便用户一站式构建 AI 算法,底层基于 kubernetes,工作链较完善。
对此,WeDataSphere 提出 Prophecis Studio 机器学习工场,它是一站式机器学习平台,主要包含 MLLabis、Machine Learning Flow、Model Factory、Application Factory 等模块。
据悉,Prophecis Studio 集数据导入、模型开发、分布式模型训练、模型部署等功能于一体,基于 Kubernetes 提供计算集群的多租户管理能力,为用户提供机器学习应用开发的一站式体验。
它致力于打通 MLOps 与 WeDataSphere 数据组件的结合,帮助用户更快、更便捷、更智能的挖掘和提升数据价值。
具体实践中,第一个模块是机器学习开发环境,依托 Notebook Controller 管理 Notebook,同时,微众开发了 Notebook Server,各个租户的资源通过命名空间隔离,Controller 将 Notebook 创建到对应租户的命名空间中。
第二个模块是机器学习分布式建模服务,主要是打通机器学习,把数据拉取、机器学习模型训练、模型存储、模型版本管理和镜像构建以及模型部署全部打通,集合在一个模块里。
第三个模块是机器学习模型工厂。据悉,模型工厂基于开源模型部署工具 Seldon Core 进行构建,提供机器学习模型管理、模型部署测试、模型镜像打包、模型报告等功能,“我们对其做了定制和拓展”。
最后是机器学习应用工厂。吴梓煜介绍,Prophecis AF 是基于青云开源的 KubeSphere 进行构建的机器学习应用工厂,Kubersphere 是一款集分布式、多租户、多集群、企业级能力的开源容器平台。首先是监控和告警,吴梓煜表示,把它与公司内部 CMDB 系统和 IMS 系统打通,支持容器实例自动关联内部应用信息。其次,是资源管理,支持限制 Namespace GPU 资源配额。第三是持久化存储,对接内部的共享存储和 MySQL。
写在最后
因为开源,大家相识;因为 WeDataSphere,大家相聚。无论是开源大咖,还是 WeDataSphere 贡献者和维护者,亦或是广大社区参与者和开源爱好者,大家因热爱技术,践行开源之道,汇聚于此。




